苹果的 Metal 工程
Posted huahuahu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了苹果的 Metal 工程相关的知识,希望对你有一定的参考价值。
Basic Buffers
当向顶点着色器传递数据过多(大于 4096 字节)时, setVertexBytes:length:atIndex: 方法不允许使用,应该使用 setVertexBytes:length:atIndex: 方法提高性能。
这时,参数应该是 MTLBuffer类型,可以被 GPU 访问的内存。
_vertexBuffer.contents 方法返回可以被 CPU 访问的内存接口,即这块儿内存被 CPU 和 GPU 共享。
Basic Texturing
MTLPixelFormatBGRA8Unorm 的像素格式。
 

2D 纹理的坐标

Reading a texel is also known as sampling
Hello Compute
data-parallel computations using the GPU.
在 GPU 发展历史中,并行处理的架构一直没有变化,而处理核心的可编程特性越来越强。这使得 GPU 从 fixed-function pipeline 转向 programmable pipeline,也使得通用 GPU 编程 (GPGPU) 变得可行。
一个 MTLComputePipelineState 对象可以直接由一个 kernel function 生成。
// Create a compute kernel function
id <MTLFunction> kernelFunction = [defaultLibrary newFunctionWithName:@"grayscaleKernel"];
// Create a compute kernel
_computePipelineState = [_device newComputePipelineStateWithFunction:kernelFunction
把图像分块并行处理
// Set the compute kernel\'s thread group size of 16x16
_threadgroupSize = MTLSizeMake(16, 16, 1);
// Calculate the number of rows and columsn of thread groups given the width of our input image.
// Ensure we cover the entire image (or more) so we process every pixel.
_threadgroupCount.width = (_inputTexture.width + _threadgroupSize.width - 1) / _threadgroupSize.width;
_threadgroupCount.height = (_inputTexture.height + _threadgroupSize.height - 1) / _threadgroupSize.height;
// Since we\'re only dealing with a 2D data set, set depth to 1
_threadgroupCount.depth = 1;
[computeEncoder dispatchThreadgroups:_threadgroupCount
threadsPerThreadgroup:_threadgroupSize];
CPU and GPU Synchronization
CPU 和 GPU 是两个异步的处理器,但是它们共享缓存,因此需要在并行的同时避免同时读写数据。
 

在上图中,每一帧中,CPU 和 GPU 不会同时工作,虽然避免了同时读写数据,但是降低了性能。
 

在上图中,CPU 和 GPU 会同时读写相同的数据,引起竞争。
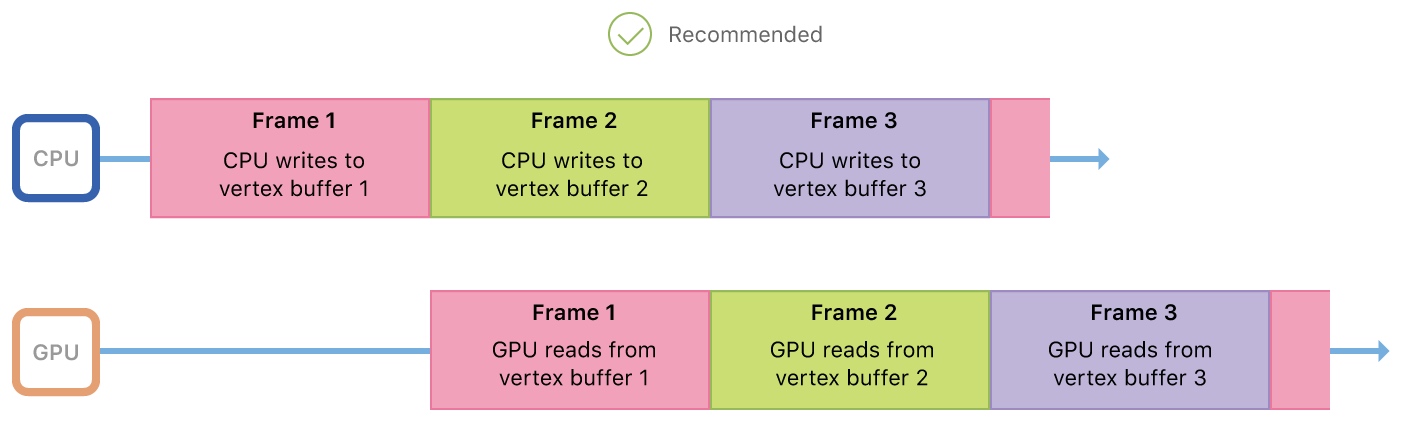 

可以用多个缓冲区来达到提高性能和避免数据同时读写的问题。CPU 和 GPU 不同时读写相同的缓冲区。
当 GPU 执行完 command buffer 后,会调用这个 handler。
[commandBuffer addCompletedHandler:^(id<MTLCommandBuffer> buffer)
{
dispatch_semaphore_signal(block_sema);
}];
LOD with Function Specialization
level of detail (LOD)
细节越逼真,消耗的资源越多。因此要在性能和细节的丰富度之间做权衡。
if(highLOD)
{
// Render high-quality model
}
else if(mediumLOD)
{
// Render medium-quality model
}
else if(lowLOD)
{
// Render low-quality model
}
但是使用 GPU 写出上面的代码的话,性能不高。GPU 可以并行的指令数依赖于为函数分配的寄存器数目。GPU 编译器需要为函数分配可能用到的最大数目寄存器,即使有些分支永远不可能执行。因此,分支语句显著增加了需要的寄存器数目,并显著降低了 GPU 的并行数目。
以上是关于苹果的 Metal 工程的主要内容,如果未能解决你的问题,请参考以下文章