Spark基础之shuffle原理分析
Posted 常生果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark基础之shuffle原理分析相关的知识,希望对你有一定的参考价值。
一 概述
Shuffle是对数据重新组合和分配
Shuffle就是对数据进行重组,由于分布式计算的特性和要求,在实现细节上更加繁琐和复杂
在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。在整个shuffle过程中,往往伴随着大量的磁盘和网络I/O。所以shuffle性能的高低也直接决定了整个程序的性能高低,Spark也会有自己的shuffle实现过程。
hadoopMR的Shuffle过程:


在DAG调度的过程中,Stage阶段的划分是根据是否有shuffle过程,也就是存在ShuffleDependency宽依赖的时候,需要进行shuffle,这时候会将作业job划分成多个Stage;并且在划分Stage的时候,构建ShuffleDependency的时候进行shuffle注册,获取后续数据读取所需要的ShuffleHandle,最终每一个job提交后都会生成一个ResultStage和若干个ShuffleMapStage,其中ResultStage表示生成作业的最终结果所在的Stage. ResultStage与ShuffleMapStage中的task分别对应着ResultTask与ShuffleMapTask。一个作业,除了最终的ResultStage外,其他若干ShuffleMapStage中各个ShuffleMapTask都需要将最终的数据根据相应的Partitioner对数据进行分组,然后持久化分区的数据。
一 HashShuffle机制
1.1 HashShuffle概述
在spark-1.6版本之前,一直使用HashShuffle,在spark-1.6版本之后使用Sort-Base Shuffle,因为HashShuffle存在的不足所以就替换了HashShuffle.
我们知道,Spark的运行主要分为2部分:一部分是驱动程序,其核心是SparkContext;另一部分是Worker节点上Task,它是运行实际任务的。程序运行的时候,Driver和Executor进程相互交互:运行什么任务,即Driver会分配Task到Executor,Driver 跟 Executor 进行网络传输; 任务数据从哪儿获取,即Task要从 Driver 抓取其他上游的 Task 的数据结果,所以有这个过程中就不断的产生网络结果。其中,下一个 Stage 向上一个 Stage 要数据这个过程,我们就称之为 Shuffle。(简单理解)
1.2 没有优化之前的HashShuffle机制
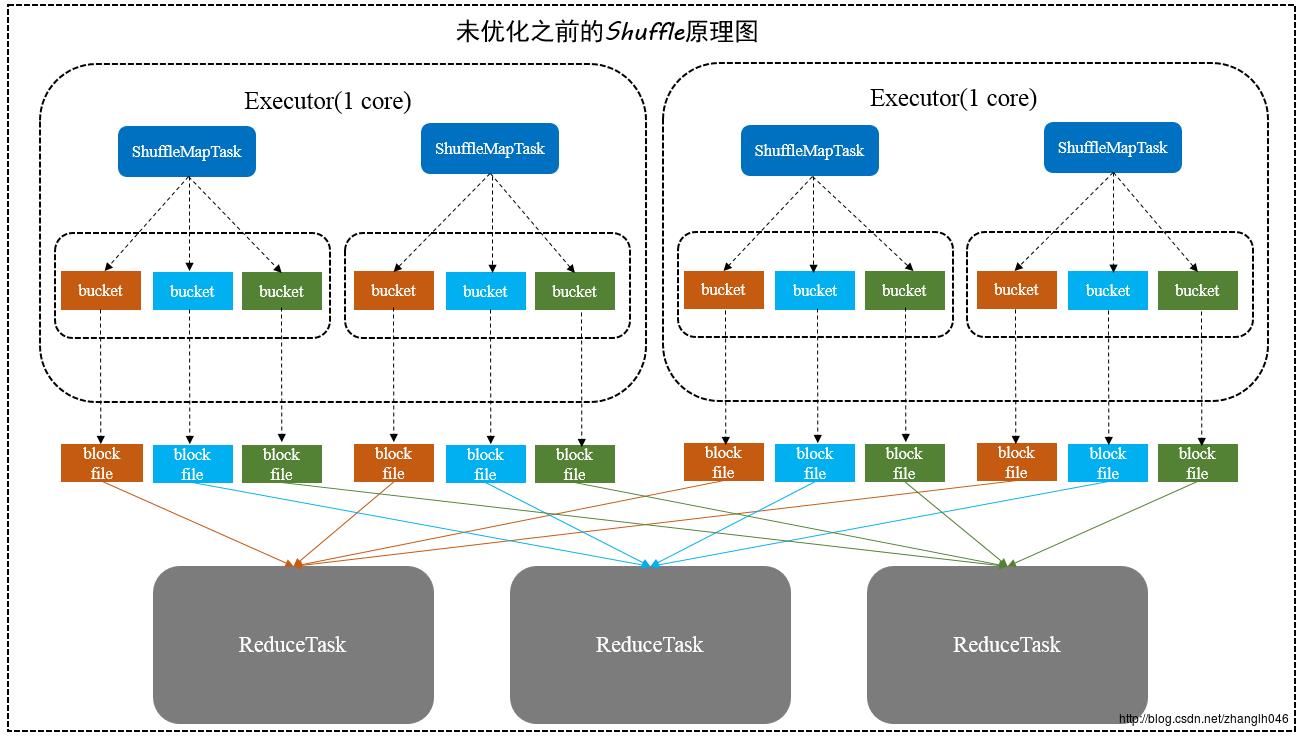
在HashShuffle没有优化之前,每一个ShufflleMapTask会为每一个ReduceTask创建一个bucket缓存,并且会为每一个bucket创建一个文件。这个bucket存放的数据就是经过Partitioner操作(默认是HashPartitioner)之后找到对应的bucket然后放进去,最后将数据刷新bucket缓存的数据到磁盘上,即对应的block file.
然后ShuffleMapTask将输出作为MapStatus发送到DAGScheduler的MapOutputTrackerMaster,每一个MapStatus包含了每一个ResultTask要拉取的数据的位置和大小
ResultTask然后去利用BlockStoreShuffleFetcher向MapOutputTrackerMaster获取MapStatus,看哪一份数据是属于自己的,然后底层通过BlockManager将数据拉取过来
拉取过来的数据会组成一个内部的ShuffleRDD,优先放入内存,内存不够用则放入磁盘,然后ResulTask开始进行聚合,最后生成我们希望获取的那个MapPartitionRDD
缺点:
如上图所示:在这里有1个worker,2个executor,每一个executor运行2个ShuffleMapTask,有三个ReduceTask,所以总共就有4 * 3=12个bucket和12个block file。
# 如果数据量较大,将会生成M*R个小文件,比如ShuffleMapTask有100个,ResultTask有100个,这就会产生100*100=10000个小文件
# bucket缓存很重要,需要将ShuffleMapTask所有数据都写入bucket,才会刷到磁盘,那么如果Map端数据过多,这就很容易造成内存溢出,尽管后面有优化,bucket写入的数据达到刷新到磁盘的阀值之后,就会将数据一点一点的刷新到磁盘,但是这样磁盘I/O就多了
简单概括:
shuffle write:
- stage结束之后,每个task处理的数据按key进行“分类”
- 数据先写入内存缓冲区
- 缓冲区满,溢出到磁盘文件
- 最终,相同key被写入同一个磁盘文件
创建的磁盘文件数量 = 当前stagetask数量 * 下一个stage的task数量
shuffle read:
- 从上游stage的所有task节点上拉取属于自己的磁盘文件
- 每个read task会有自己的buffer缓冲,每次只能拉取与buffer缓冲相同大小的数据,然后聚合,聚合完一批后拉取下一批
- 该拉取过程,边拉取边聚合
1.3 优化后的HashShuffle
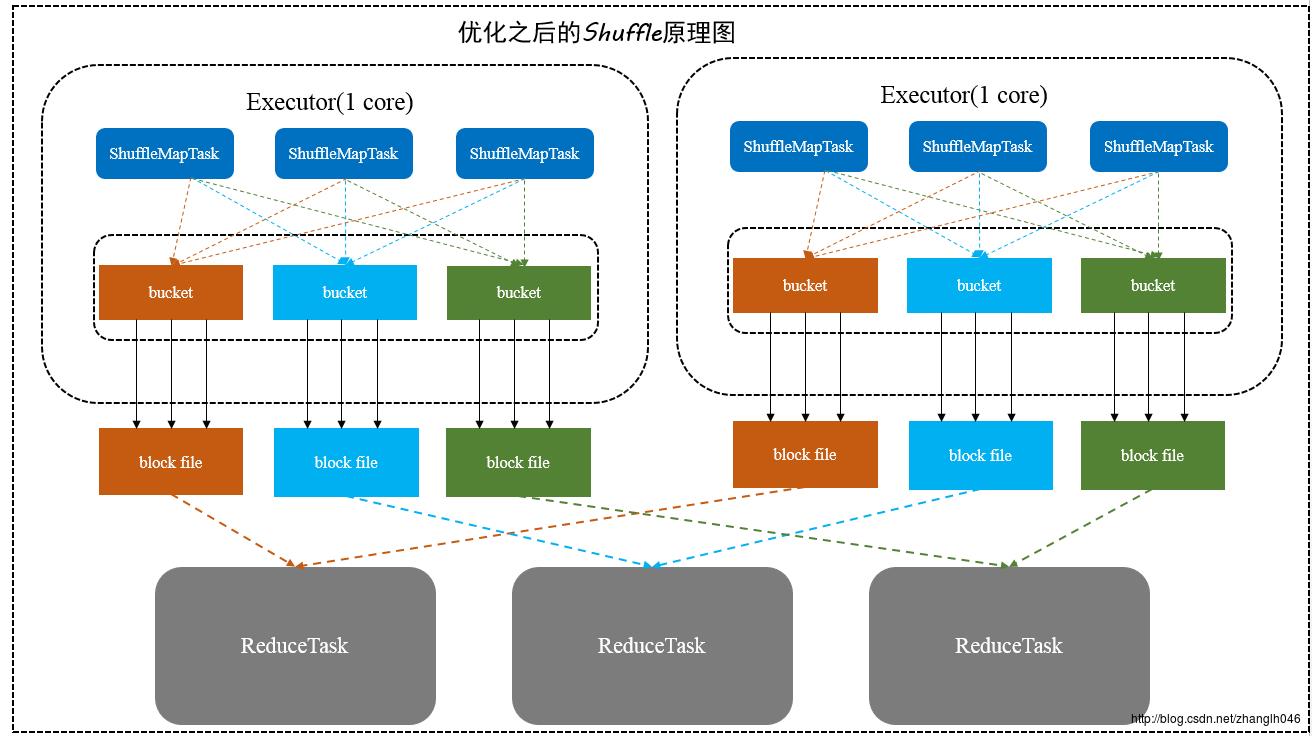
每一个Executor进程根据核数,决定Task的并发数量,比如executor核数是2,就是可以并发运行两个task,如果是一个则只能运行一个task
假设executor核数是1,ShuffleMapTask数量是M,那么它依然会根据ResultTask的数量R,创建R个bucket缓存,然后对key进行hash,数据进入不同的bucket中,每一个bucket对应着一个block file,用于刷新bucket缓存里的数据
然后下一个task运行的时候,那么不会再创建新的bucket和block file,而是复用之前的task已经创建好的bucket和block file。即所谓同一个Executor进程里所有Task都会把相同的key放入相同的bucket缓冲区中
这样的话,生成文件的数量就是(本地worker的executor数量*executor的cores*ResultTask数量)如上图所示,即2 * 1* 3 = 6个文件,每一个Executor的shuffleMapTask数量100,ReduceTask数量为100,那么
未优化的HashShuffle的文件数是2 *1* 100*100 =20000,优化之后的数量是2*1*100 = 200文件,相当于少了100倍
缺点:如果 Reducer 端的并行任务或者是数据分片过多的话则 Core * Reducer Task 依旧过大,也会产生很多小文件。
简单概括:
spark.shuffle.consolidateFiles设置为true可开启优化机制(consolidate机制)
- 一个Executor上有多少个core,就可并行执行多少个task
- 第一批并行执行的每个task会创建shuffleFileGroup,数据写入对应磁盘文件中
- 第一批task执行完后,下一批task复用已有的shuffleFileGroup
磁盘文件数量 = core数量 * 下一个stage的task数量
二 Sort-Based Shuffle
2.1 Sort-Based Shuffle概述
HashShuffle回顾
HashShuffle写数据的时候,内存有一个bucket缓冲区,同时在本地磁盘有对应的本地文件,如果本地有文件,那么在内存应该也有文件句柄也是需要耗费内存的。也就是说,从内存的角度考虑,即有一部分存储数据,一部分管理文件句柄。如果Mapper分片数量为1000,Reduce分片数量为1000,那么总共就需要1000000个小文件。所以就会有很多内存消耗,频繁IO以及GC频繁或者出现内存溢出。
而且Reducer端读取Map端数据时,Mapper有这么多小文件,就需要打开很多网络通道读取,很容易造成Reducer(下一个stage)通过driver去拉取上一个stage数据的时候,说文件找不到,其实不是文件找不到而是程序不响应,因为正在GC.
2.2 Sorted-Based Shuffle介绍
为了缓解Shuffle过程产生文件数过多和Writer缓存开销过大的问题,spark引入了类似于hadoop Map-Reduce的shuffle机制。该机制每一个ShuffleMapTask不会为后续的任务创建单独的文件,而是会将所有的Task结果写入同一个文件,并且对应生成一个索引文件。以前的数据是放在内存缓存中,等到数据完了再刷到磁盘,现在为了减少内存的使用,在内存不够用的时候,可以将输出溢写到磁盘,结束的时候,再将这些不同的文件联合内存的数据一起进行归并,从而减少内存的使用量。一方面文件数量显著减少,另一方面减少Writer缓存所占用的内存大小,而且同时避免GC的风险和频率。
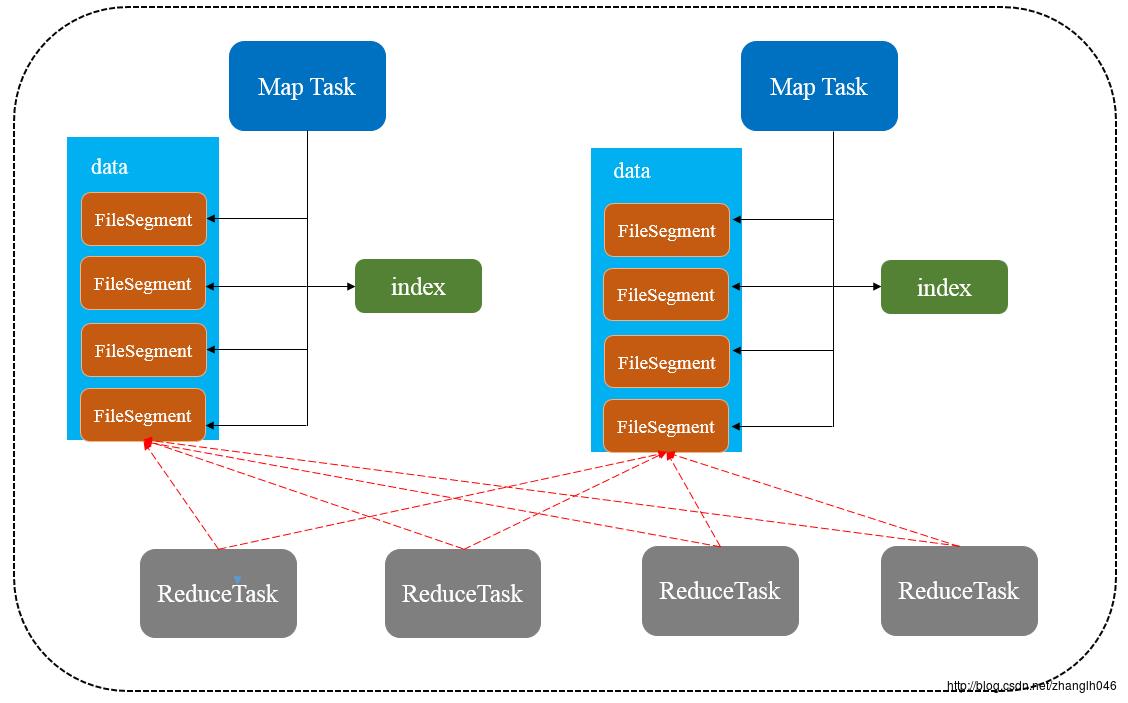
Sort-Based Shuffle有几种不同的策略:BypassMergeSortShuffleWriter、SortShuffleWriter和UnasfeSortShuffleWriter。
SortShuffleManager运行原理
普通运行机制
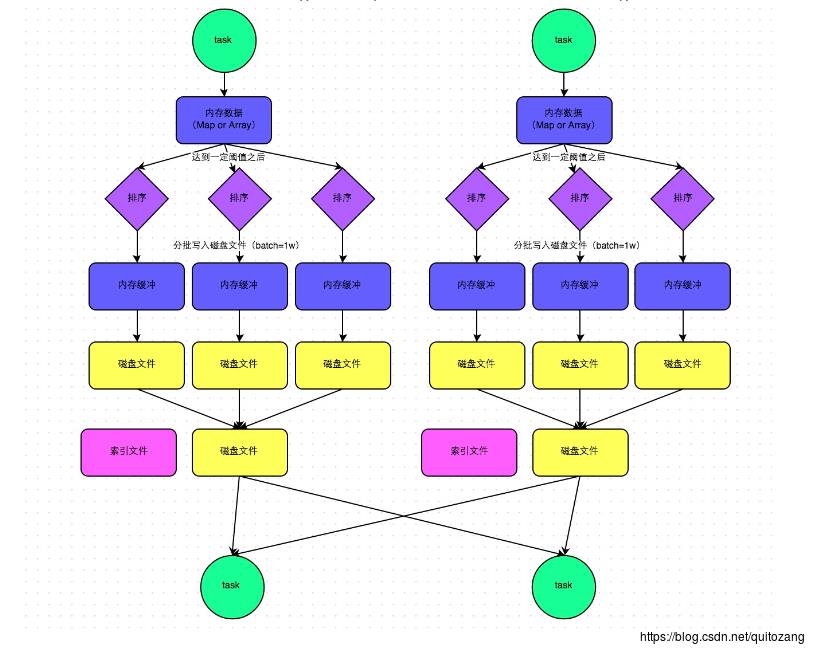
- 数据先写入内存数据结构(reduceByKey—Map)
- 每写一条数据,判断是否达到某个临界值,达到则根据key对数据排序,再溢出到磁盘
- 写入磁盘通过java的BufferedOutputStream实现,先缓存到内存,满后一次写入磁盘文件
- 合并所有临时磁盘文件(merge),归并排序,依次写入同一个磁盘文件
- 单独写一份索引文件,标识下游各个task的数据在文件中的start and end
磁盘文件数量 = 上游stage的task数量
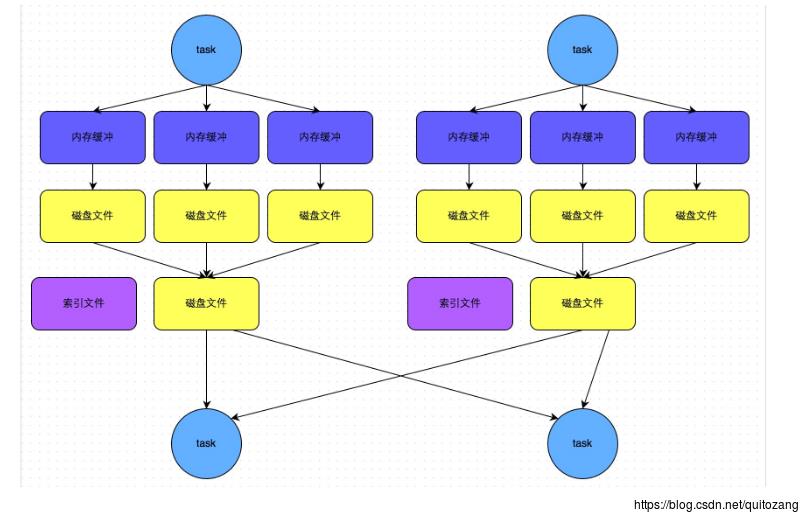
当reducer的task数量 < spark.sort.bypassMergeThreshold(200),shuffle write过程不排序,按未经优化的HashShuffleManager的方式write,最后将所有临时磁盘文件合并成一个,并创建索引文件
对于BypassMergeSortShuffleWriter,使用这个模式特点:
# 主要用于处理不需要排序和聚合的Shuffle操作,所以数据是直接写入文件,数据量较大的时候,网络I/O和内存负担较重
# 主要适合处理Reducer任务数量比较少的情况下
# 将每一个分区写入一个单独的文件,最后将这些文件合并,减少文件数量;但是这种方式需要并发打开多个文件,对内存消耗比较大
因为BypassMergeSortShuffleWriter这种方式比SortShuffleWriter更快,所以如果在Reducer数量不大,又不需要在map端聚合和排序,而且
Reducer的数目 < spark.shuffle.sort.bypassMergeThrshold指定的阀值,就是用的是这种方式。
对于SortShuffleWriter,使用这个模式特点:
# 比较适合数据量很大的场景或者集群规模很大
# 引入了外部外部排序器,可以支持在Map端进行本地聚合或者不聚合
# 如果外部排序器enable了spill功能,如果内存不够,可以先将输出溢写到本地磁盘,最后将内存结果和本地磁盘的溢写文件进行合并
对于UnsafeShuffleWriter由于需要谨慎使用,我们暂不做分析。
另外这个Sort-Based Shuffle跟Executor核数没有关系,即跟并发度没有关系,它是每一个ShuffleMapTask都会产生一个data文件和index文件,所谓合并也只是将该ShuffleMapTask的各个partition对应的分区文件合并到data文件而已。所以这个就需要个Hash-BasedShuffle的consolidation机制区别开来。
以上是关于Spark基础之shuffle原理分析的主要内容,如果未能解决你的问题,请参考以下文章