VTM10.0帧内之MIP技术
Posted 神遁克里苏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VTM10.0帧内之MIP技术相关的知识,希望对你有一定的参考价值。
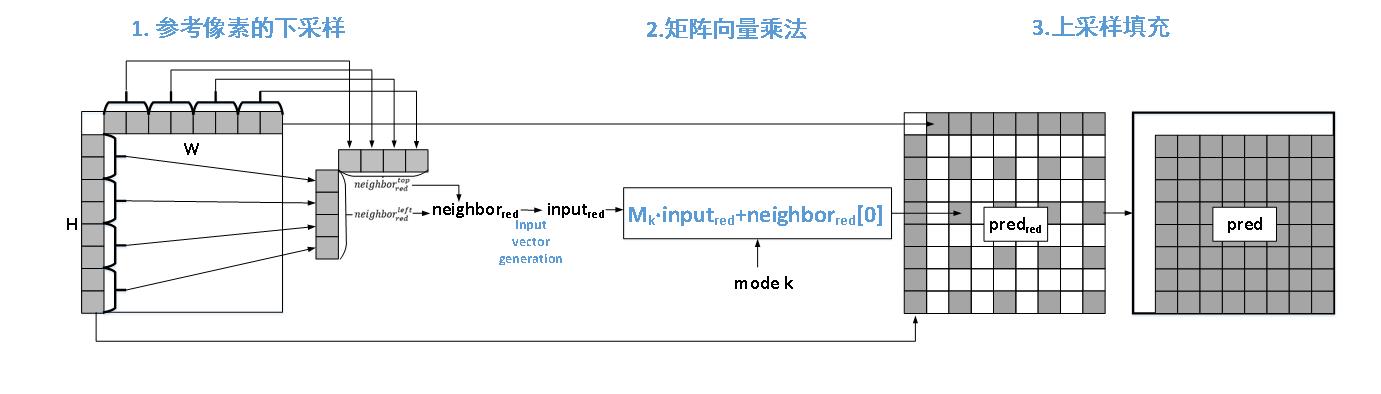
MIP (Matrix weighted Intra Prediction,基于矩阵的帧内预测 )
矩阵:根据不同块大小,分别预先训练出不同的多组矩阵,存在ROM中;
向量:将参考像素的一部分进行一些处理,排成一维向量;
通过矩阵与向量相乘进行帧内预测,得到当前块的预测值。
其预测过程可以分为三步,以大小为8 x 8的CU为例:
ROM中矩阵规模为[16 x 8],待输入向量规模为[8 x 1],经过矩阵相乘后得到16个预测值。
MIP初始化代码:
void IntraPrediction::initIntraMip( const PredictionUnit &pu, const CompArea &area )
CHECK( area.width > MIP_MAX_WIDTH || area.height > MIP_MAX_HEIGHT, "Error: block size not supported for MIP" );
// prepare input (boundary) data for prediction
CHECK( m_ipaParam.refFilterFlag, "ERROR: unfiltered refs expected for MIP" );
Pel *ptrSrc = getPredictorPtr(area.compID);
const int srcStride = m_refBufferStride[area.compID];
const int srcHStride = 2;//高度,用于下一列
m_matrixIntraPred.prepareInputForPred(CPelBuf(ptrSrc, srcStride, srcHStride), area,
pu.cu->slice->getSPS()->getBitDepth(toChannelType(area.compID)), area.compID);
函数中调用了prepareInputForPred函数。
void MatrixIntraPrediction::prepareInputForPred(const CPelBuf &pSrc, const Area &block, const int bitDepth,
const ComponentID compId)
m_component = compId;
// Step 1: Save block size and calculate dependent values
//步骤1,保存块的大小,并且计算依赖的values
//计算m_reducedBdrySize和m_reducedPredSize的大小,以及需要结束后上采样的规模
initPredBlockParams(block);
// Step 2: Get the input data (left and top reference samples)
//步骤2,获得输入的数据(上和左的参考像素)
m_refSamplesTop.resize(block.width);
for (int x = 0; x < block.width; x++)
//获得上边的参考像素
m_refSamplesTop[x] = pSrc.at(x + 1, 0);
m_refSamplesLeft.resize(block.height);
for (int y = 0; y < block.height; y++)
//获得左边的参考像素
m_refSamplesLeft[y] = pSrc.at(y + 1, 1);
// Step 3: Compute the reduced boundary via Haar-downsampling (input for the prediction)
//步骤3,计算下采样后的边界(预测,MIP的输入)
const int inputSize = 2 * m_reducedBdrySize;
m_reducedBoundary .resize( inputSize );//下采样后的参考像素存放位置
m_reducedBoundaryTransposed.resize( inputSize );//下采样后的参考像素转置的存放位置
//对上方边界进行下采样
int* const topReduced = m_reducedBoundary.data();
boundaryDownsampling1D( topReduced, m_refSamplesTop.data(), block.width, m_reducedBdrySize );
//对左边边界进行下采样
int* const leftReduced = m_reducedBoundary.data() + m_reducedBdrySize;
boundaryDownsampling1D( leftReduced, m_refSamplesLeft.data(), block.height, m_reducedBdrySize );
int* const leftReducedTransposed = m_reducedBoundaryTransposed.data();
int* const topReducedTransposed = m_reducedBoundaryTransposed.data() + m_reducedBdrySize;
for( int x = 0; x < m_reducedBdrySize; x++ )
//看着不像转置了啊?(好像转置只是对预测块内转置,参考像素不用转置,这里应该只是改了个名字)
topReducedTransposed[x] = topReduced[x];
for( int y = 0; y < m_reducedBdrySize; y++ )
leftReducedTransposed[y] = leftReduced[y];
// Step 4: Rebase the reduced boundary
//步骤4,重新基础化下采样后的边界
m_inputOffset = m_reducedBoundary[0];
m_inputOffsetTransp = m_reducedBoundaryTransposed[0];
const bool hasFirstCol = (m_sizeId < 2);
m_reducedBoundary [0] = hasFirstCol ? ((1 << (bitDepth - 1)) - m_inputOffset ) : 0; // first column of matrix not needed for large blocks
m_reducedBoundaryTransposed[0] = hasFirstCol ? ((1 << (bitDepth - 1)) - m_inputOffsetTransp) : 0;
for (int i = 1; i < inputSize; i++)
m_reducedBoundary [i] -= m_inputOffset;
m_reducedBoundaryTransposed[i] -= m_inputOffsetTransp;
Step 1中调用了initPredBlockParams函数,主要功能是计算m_reducedBdrySize和m_reducedPredSize的大小,以及需要结束后上采样的规模
void MatrixIntraPrediction::initPredBlockParams(const Size& block)
m_blockSize = block;
// init size index
m_sizeId = getMipSizeId( m_blockSize );
// init reduced boundary size
//根据块的大小,获得边界需要的像素点个数
m_reducedBdrySize = (m_sizeId == 0) ? 2 : 4;
// init reduced prediction size
//根据块的大小,获得预测块需要的像素点个数
m_reducedPredSize = ( m_sizeId < 2 ) ? 4 : 8;
// init upsampling factors
//获取上采样的规模
m_upsmpFactorHor = m_blockSize.width / m_reducedPredSize;
m_upsmpFactorVer = m_blockSize.height / m_reducedPredSize;
CHECKD( (m_upsmpFactorHor < 1) || ((m_upsmpFactorHor & (m_upsmpFactorHor - 1)) != 0), "Need power of two horizontal upsampling factor." );
CHECKD( (m_upsmpFactorVer < 1) || ((m_upsmpFactorVer & (m_upsmpFactorVer - 1)) != 0), "Need power of two vertical upsampling factor." );
然后在predIntraMip中进行了MIP块内预测值的计算
void IntraPrediction::predIntraMip( const ComponentID compId, PelBuf &piPred, const PredictionUnit &pu )
CHECK( piPred.width > MIP_MAX_WIDTH || piPred.height > MIP_MAX_HEIGHT, "Error: block size not supported for MIP" );
CHECK( piPred.width != (1 << floorLog2(piPred.width)) || piPred.height != (1 << floorLog2(piPred.height)), "Error: expecting blocks of size 2^M x 2^N" );
// generate mode-specific prediction
uint32_t modeIdx = MAX_NUM_MIP_MODE;
bool transposeFlag = false;
if (compId == COMPONENT_Y)
//如果当前是亮度模式
modeIdx = pu.intraDir[CHANNEL_TYPE_LUMA];//modeIdx不是为MIP吗??
transposeFlag = pu.mipTransposedFlag;
else
//如果不是亮度模式,但是这一段代码好像没有用上(色度没有MIP模式)
const PredictionUnit &coLocatedLumaPU = PU::getCoLocatedLumaPU(pu);
CHECK(pu.intraDir[CHANNEL_TYPE_CHROMA] != DM_CHROMA_IDX, "Error: MIP is only supported for chroma with DM_CHROMA.");
CHECK(!coLocatedLumaPU.cu->mipFlag, "Error: Co-located luma CU should use MIP.");
modeIdx = coLocatedLumaPU.intraDir[CHANNEL_TYPE_LUMA];
transposeFlag = coLocatedLumaPU.mipTransposedFlag;
const int bitDepth = pu.cu->slice->getSPS()->getBitDepth(toChannelType(compId));
CHECK(modeIdx >= getNumModesMip(piPred), "Error: Wrong MIP mode index");
static_vector<int, MIP_MAX_WIDTH* MIP_MAX_HEIGHT> predMip( piPred.width * piPred.height );
m_matrixIntraPred.predBlock(predMip.data(), modeIdx, transposeFlag, bitDepth, compId);//调用predBlock进行MIP预测,结果放到predMip中
//将predMip中的结果转到piPred中
for( int y = 0; y < piPred.height; y++ )
for( int x = 0; x < piPred.width; x++ )
piPred.at( x, y ) = Pel(predMip[y * piPred.width + x]);
predBlock函数进行MIP主要计算的计算部分
void MatrixIntraPrediction::predBlock(int *const result, const int modeIdx, const bool transpose, const int bitDepth,
const ComponentID compId)
//
CHECK(m_component != compId, "Boundary has not been prepared for this component.");
//是否需要上采样
const bool needUpsampling = ( m_upsmpFactorHor > 1 ) || ( m_upsmpFactorVer > 1 );
//获取MIP矩阵
const uint8_t* matrix = getMatrixData(modeIdx);
static_vector<int, MIP_MAX_REDUCED_OUTPUT_SAMPLES> bufReducedPred( m_reducedPredSize * m_reducedPredSize );
int* const reducedPred = needUpsampling ? bufReducedPred.data() : result;
const int* const reducedBoundary = transpose ? m_reducedBoundaryTransposed.data() : m_reducedBoundary.data();
//计算MIP后的结果
computeReducedPred(reducedPred, reducedBoundary, matrix, transpose, bitDepth);
if( needUpsampling )
//进行上采样
predictionUpsampling( result, reducedPred );
以上是关于VTM10.0帧内之MIP技术的主要内容,如果未能解决你的问题,请参考以下文章