cblas_sgemm和cublasSgemm参数详解
Posted yutianzuijin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cblas_sgemm和cublasSgemm参数详解相关的知识,希望对你有一定的参考价值。
机器学习最核心的底层运算肯定是矩阵乘法无疑了,为了让矩阵乘法执行更快,大家也是绞尽脑汁。从算法层面,stranssen算法将矩阵乘法复杂度由 O ( n 3 ) O(n^3) O(n3)降到 O ( n 2.81 ) O(n^2.81) O(n2.81),最新的算法好像已经降到 O ( n 2.37 ) O(n^2.37) O(n2.37)左右了(Coppersmith–Winograd algorithm),但这只是理论复杂度,只有在矩阵超大的情况下才能体现出优势。从并行角度,我们可以从很多层面对矩阵乘法进行加速:1. 指令集并行,现在的CPU都会有很多并行指令可以一次完成多个乘法运算,Intel下有mmx指令集,arm下有neon指令集;2. 多核并行,除了指令集并行,我们还可以将矩阵分块,放在不同的核上进行数据层面的并行;3. GPU加速,利用GPU上的众核完成并行;4. 多机并行,针对超大矩阵或者众多矩阵乘法还可以采用多机并行。
在实际中,我们往往会采用指令集并行和GPU对矩阵乘法进行加速。用指令集优化矩阵乘法难度比较大,非专业人士不建议采用,而且幸运的是我们现在有很多开源矩阵运算库,性能大概率超过手写的矩阵乘法。CPU下的矩阵运算库有openblas和mkl等,GPU下有cublas,它们都是对fortran blas接口的实现。在上述加速库的基础上,我们可以再对矩阵进行分割实现多核或者多机的并行。在目前情况下,要实现快速的矩阵乘法,最便捷快速的方法就是用好openblas和cublas。openblas下的矩阵乘法函数为:cblas_sgemm,cublas中为cubalsSgemm。两个函数的参数基本一致,不过一个是行主序一个是列主序(cblas下一般用行主序,虽然它支持列主序),导致传递参数的时候差别很大。本博客希望能给大家一个详细明白的解释。
矩阵乘法原理
在线性代数中我们都学习过矩阵乘法,简单描述就是A矩阵的一行乘以B矩阵的一列,如图1所示。如果A矩阵大小为m*k,B矩阵为k*n,则生成的C矩阵大小为m*n,形象地描述就是中间的维度被吃掉了。A矩阵的一行固定之后乘以B的所有列填充C矩阵的一行。这看似简单的矩阵乘法有很多奥妙在里面。

在实际中,为了避免cache缺失,B矩阵往往会事先做转置,之前B矩阵按列访问元素,转置之后就和A矩阵一样按行访问,如图2所示,这个操作带来的速度提升是很明显的。

在示意图中,矩阵都是二维形式展示的,但是在内存中它们实际上是以一维数组形式存在的(暂时不考虑padding问题)。A矩阵大小为m*k,在内存中A矩阵的存在形式不过是一个m*k的一维数组而已。针对这块空间我们有很多解释:它既可以表示一个一维数组,也可以表示以能整除m*k的整数为宽的二维数组(也即矩阵)。但是具体宽度是多少选择很多,至少宽度既可以是m也可以是k,所以我们需要知道矩阵的宽度。似乎指定m、n和k之后矩阵的长和宽就定了,绝大多数情况下确实如此,不过也有例外。如图3,比如要进行计算的矩阵是一个大矩阵的一部分,此时为了正确访问矩阵的一行,我们需要跳过的元素就不是k了,而是原始大矩阵的宽度K。这也是库函数中lda、ldb和ldc存在的原因,它表示leading dimension,在行主序中为访问矩阵的一行需要跨过的列元素个数,在列主序中为访问矩阵的一列需要跨过的行元素个数。

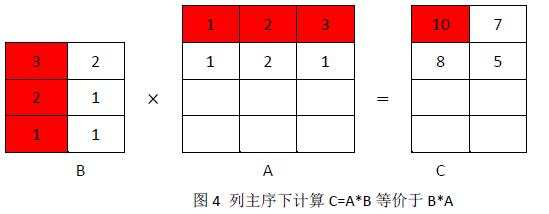
在行主序下,矩阵乘法是A的一行乘以B的一列,为了保证正确性在列主序下就变成了B的一列乘以A的一行。B矩阵的一列固定之后乘以A的所有行填充C的一列,如图4。这样我们就可以和行主序下计算的结果一致。所以在列主序下,A*B变成了B*A。
cblas_sgemm参数详解
函数原型如下:
void cblas_sgemm(
const enum CBLAS_ORDER Order,
const enum CBLAS_TRANSPOSE TransA,
const enum CBLAS_TRANSPOSE TransB,
const int M,
const int N,
const int K,
const float alpha,
const float *A,
const int lda,
const float *B,
const int ldb,
const float beta,
float *C,
const int ldc);
- 参数Order:表示计算在行主序下(CblasRowMajor)还是列主序下(CblasColMajor)完成,相信大家更熟悉行主序,所以CPU下我们就填CblasRowMajor;
- 参数TransA:表示第一个矩阵A是否做了转置,转置就填CblasTrans,否则就填CblasNoTrans,在行主序下第一个矩阵往往不做转置,所以一般填CblasNoTrans;
- 参数TransB:表示第二个矩阵B是否做了转置,在行主序下为了避免cache缺失,第二个矩阵通常会做转置;
- 参数M:表示 A或C的行数。如果A转置,则表示转置后的列数(A的大小为M*K,则为M,转置之后为K*M,也为M);
- 参数N:表示 B或C的列数。如果B转置,则表示转置后的行数(B的大小为K*N,则为N,转置之后为N*K,也为N);
- 参数K:表示 A的列数或B的行数(A的列数=B的行数),即为被吃掉的维度;
- 参数alpha和beta:计算公式C = alpha*op( A )*op( B ) + beta*C中的两个参数值;
- 参数lda:表示矩阵A的leading dimension,在行主序下,A转置表示A的行否则为A的列,值均为K,和参数M相反(注意:当运算的矩阵是大矩阵中的小矩阵时不再是K);
- 参数ldb:表示矩阵B的leading dimension,在行主序下,B转置表示B的列否则为B的行,值均为K,和参数N相反(注意:当运算的矩阵是大矩阵中的小矩阵时不再是K);
- 参数ldc:表示矩阵C的leading dimension,在行主序下始终为N,表示C的列。
上面特别容易出错的几个参数是M、N、K和lda、ldb、ldc,在填这几个参数的时候要相当小心。
cublasSgemm参数详解
函数原型如下:
cublasStatus_t cublasSgemm (
cublasHandle_t handle,
cublasOperation_t transA,
cublasOperation_t transB,
int M,
int N,
int K,
const float *alpha,
const float *A,
int lda,
const float *B,
int ldb,
const float *beta,
float *C,
int ldc);
- 参数handle:cublas的句柄,通过cublasCreate创建;
- 参数transA:矩阵B是否转置,转置填CUBLAS_OP_T,否则填CUBLAS_OP_N;
- 参数transB:矩阵A是否转置;
- 参数M:表示矩阵B的列数,若转置则为B的行数(B大小为K*N,则为N,转置之后为N*K,也为N);
- 参数N:表示矩阵A的行数,若转置则为A的列数(A大小为M*K,则为M,转置之后为K*M,也为M);
- 参数K:表示 B的行数或A的列数(A的列数=B的行数),即为被吃掉的维度;
- 参数alpha和beta:计算公式C = alpha*op( A )*op( B ) + beta*C中的两个参数的引用;
- 参数lda:表示矩阵B的leading dimension,在列主序下,B转置表示B的列否则为B的行,值均为K,和参数M相反(注意:当运算的矩阵是大矩阵中的小矩阵时不再是K);
- 参数ldb:表示矩阵A的leading dimension,在列主序下,A转置表示A的行否则为A的列,值均为K,和参数N相反(注意:当运算的矩阵是大矩阵中的小矩阵时不再是K);
- 参数ldc:表示矩阵C的leading dimension,在列主序下始终为N,表示C的列(此处和行主序一样,本人略微不解)。
在填入cublasSgemm的参数时,首先要记得交换矩阵A和B,然后根据列主序的要求填入相关参数。在cuda samples/0_Simple中有一个cublas调用示例matrixMulCUBLAS,大家可以参考里面的调用来进一步学习cublasSgemm。
以上是关于cblas_sgemm和cublasSgemm参数详解的主要内容,如果未能解决你的问题,请参考以下文章