HTTP协议格式详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTTP协议格式详解相关的知识,希望对你有一定的参考价值。
参考技术A上一篇介绍了 HTTP 协议的版本迭代历史,本篇继续深入介绍一下 HTTP 协议的规范,本文主要介绍它的 URI 、 Request 、 Response 、状态码等等信息,通过了解这些具体的内容,可以更直观的理解 HTTP 的协议格式,以及工作原理。
HTTP 使用统一资源标识符( URI )来传输数据和建立连接。 URL (统一资源定位符)是一种特殊种类的 URI ,包含了用于查找的资源的足够的信息,我们一般常用的就是 URL ,而一个完整的 URL 包含下面几部分:
http://www.fishbay.cn:80/mix/76.html?name=kelvin&password=123456#first
该 URL 的协议部分为 http: ,表示网页用的是 HTTP 协议,后面的 // 为分隔符
域名是 www.fishbay.cn ,发送请求时,需要向 DNS 服务器解析 IP 。如果为了优化请求,可以直接用 IP 作为域名部分使用
域名后面的 80 表示端口,和域名之间用 : 分隔,端口不是一个 URL 的必须的部分。如果端口是 80 ,也可以省略不写
从域名的第一个 / 开始到最后一个 / 为止,是虚拟目录的部分。其中,虚拟目录也不是 URL 必须的部分,本例中的虚拟目录是 /mix/
从域名最后一个 / 开始到 ? 为止,是文件名部分;如果没有 ? ,则是从域名最后一个 / 开始到 # 为止,是文件名部分;如果没有 ? 和 # ,那么就从域名的最后一个 / 从开始到结束,都是文件名部分。本例中的文件名是 76.html ,文件名也不是一个 URL 的必须部分,如果没有文件名,则使用默认文件名
从 # 开始到最后,都是锚部分。本部分的锚部分是 first ,锚也不是一个 URL 必须的部分
从 ? 开始到 # 为止之间的部分是参数部分,又称为搜索部分、查询部分。本例中的参数是 name=kelvin&password=123456 ,如果有多个参数,各个参数之间用 & 作为分隔符。
HTTP的请求包括:请求行(request line)、请求头部(header)、空行 和 请求数据 四个部分组成。
抓包的 request 结构如下:
GET 为请求类型, /mix/76.html?name=kelvin&password=123456 为要访问的资源, HTTP/1.1 是协议版本
从第二行起为请求头部, Host 指出请求的目的地(主机域名); User-Agent 是客户端的信息,它是检测浏览器类型的重要信息,由浏览器定义,并且在每个请求中自动发送。
请求头后面必须有一个空行
请求的数据也叫请求体,可以添加任意的其它数据。这个例子的请求体为空。
一般情况下,服务器收到客户端的请求后,就会有一个 HTTP 的响应消息,HTTP响应也由 4 部分组成,分别是:状态行、响应头、空行 和 响应体。
抓包的数据如下:
状态行由协议版本号、状态码、状态消息组成
响应头是客户端可以使用的一些信息,如: Date (生成响应的日期)、 Content-Type (MIME类型及编码格式)、 Connection (默认是长连接)等等
响应头和响应体之间必须有一个空行
响应正文,本例中是键值对信息
HTTP 协议的状态码由 3 位数字组成,第一个数字定义了响应的类别,共有 5 中类别:
其中,常用的状态码如下:
如需了解更多的状态码,请参考这个网址: HTTP状态码
HTTP 定义了多种请求方法,来满足各种需求。 HTTP/1.0 定义了三种请求方法: GET 、 POST 和 HEAD ,到了 HTTP/1.1 ,新增了五种请求方法: OPTIONS 、 PUT 、 DELETE 、 TRACE 和 CONNECT 。各个请求方法的具体功能如下:
实际应用过程中, GET 和 POST 使用的比较多,下面主要介绍一下二者的区别:
GET 请求会把请求的参数拼接在 URL 后面,以 ? 分隔,多个参数之间用 & 连接;如果是英文或数字,原样发送,如果是空格或中文,则用 Base64 编码
POST 请求会把提交的数据放在请求体中,不会在 URL 中显示出来
GET : 浏览器和服务器会限制 URL 的长度,所以传输的数据有限,一般是 2K
POST : 由于数据不是通过 URL 传递,所以一般可以传输较大量的数据
GET : 通过 Request.QueryString 获取变量的值
POST : 通过 Request.form 获取变量的值
GET : 请求参数在 URL 后面,可以直接看到,尤其是登录时,如果登录界面被浏览器缓存,其他人就可以通过查看历史记录,拿到账户和密码
POST : 请求参数在请求体里面传输,无法直接拿到,相对 GET 安全性较高;但是通过抓包工具,还是可以看到请求参数的
HTTP 协议采用请求/响应模式,客户端向服务器发送一个请求报文,然后服务器响应请求。下面介绍一下一次 HTTP 请求的过程:
HTTPS 是安全的 HTTP 通道,即在HTTP通信中加入了 SSL 层(当前版本是 TLS1.2 ),通信的数据被加密了,防止被窃取,具体的通信流程如下:
HTTPS使用的加密方式结合了对称加密和不对称加密的特点,在保证安全的情况下,又提高了传输效率。HTTP和HTTPS的区别如下:
参考资料
http://www.jianshu.com/p/a01e5b4b64ec
http://www.jianshu.com/p/a6d04501ed6d
[linux] Linux网络编程之HTTP协议详解
目录
1. 自定制协议
在上一篇socket编程中谈到了协议,程序员系的网络程序,全部都部署在应用层。
协议是一种“约定”,socket api的接口,在读写数据的时候,都是按照“字符串”的方式来进行发送和接受。那如果我们要传输的是结构化数据,怎么处理?这时候就需要我们用到自定义协议,可以自己写一套规则,服务器通过固定的方式解析数据,达到自定制协议的目的。
程序示例
// 以下是服务端部分代码
typedef struct request
int x;
int y;
char op;
request_t;
typedef struct response
int code;
int result;
response_t;
void CalResult(int sock)
// 短链接 完成对应的计算
request_t rq;
response_t rsp4, 0;
ssize_t s = recv(sock, &rq, sizeof(rq), 0);
if (s > 0)
rsp.code = 0;
switch(rq.op)
case '+':
rsp.result = rq.x + rq.y;
break;
case '-':
rsp.result = rq.x - rq.y;
break;
case '*':
rsp.result = rq.x * rq.y;
break;
case '/':
if (rq.y == 0)
rsp.code = 1;
else
rsp.result = rq.x / rq.y;
break;
case '%':
if (rq.y == 0)
rsp.code = 2;
else
rsp.result = rq.x % rq.y;
break;
default:
rsp.code = 3;
break;
std::cout << "cal success!" << std::endl;
send(sock, &rsp, sizeof(rsp), 0);
close(sock);
// 客户端部分代码
void StartClient()
struct sockaddr_in server;
server.sin_family = AF_INET;
server.sin_port = htons(port);
server.sin_addr.s_addr = inet_addr(ip.c_str()) ;
if(connect(sock, (struct sockaddr*)&server, sizeof(server)) < 0)
std::cerr << "connect err.." << std::endl;
exit(2);
request_t rq;
response_t rsp;
std::cout << "data1# ";
std::cin >> rq.x;
std::cout << "data2# ";
std::cin >> rq.y;
std::cout << "op# ";
std::cin >> rq.op;
send(sock, &rq, sizeof(rq), 0);
recv(sock, &rsp, sizeof(rsp), 0);
std::cout << "cod: " << rsp.code << std::endl;
std::cout << "result: " << rsp.result << std::endl;
2. HTTP协议
2.1 概述
HTTP协议是建立在TCP/IP协议之上的,是TCP/IP的上层协议,HTTP的数据通过TCP/IP层进行转发。
HTTP协议是无连接、无状态、工作在应用层的协议。
- 无连接
http协议本身是不建立连接的,http直接向对方发送http request即可,但是http在传输层使用的是tcp协议,tcp协议在传输数据的时候是需要建立连接,才可以通信的。- 无状态
http协议本身是对请求和响应不做保存,双方的状态是服务端实现的会话机制进行保存的。
2.2 URL统一资源定位符
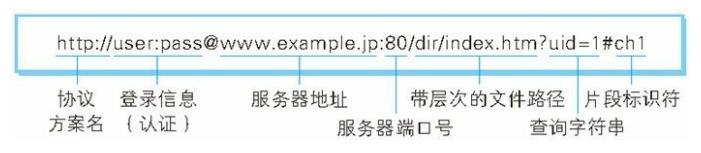
- 服务器地址: 使用绝对 URI 必须指定待访问的服务器地址。地址可以是类似hackr.jp 这种 DNS 可解析的名称,或是 192.168.1.1 这类 IPv4 地址
名,还可以是 [0:0:0:0:0:0:0:1] 这样用方括号括起来的 IPv6 地址名。- 服务器端口号: 指定服务器连接的网络端口号。此项也是可选项,若用户省略则自动使用默认端口号。
- 带层次的文件路径(http://域名/路径): 代表的是向服务器后台请求资源的路径,路径中第一个’/'代表web根目录,服务端可以指定任意一个路径作为http服务端的根目录的起始路径
- 查询字符串(key=value): 指定的是客户端向服务器提交的数据,多组时间之间用&连接。
URL中的特殊字符的转义
- urlencode:
在URL有一些特殊字符需要转义,对具有通俗意义的字符进行转码,采用16进制进行显示。例如下方字符,需要使用’%’ + urlencode,其中%是告诉服务器后面的内容是经过转义的。
- urldecode: 将特殊字符编码转化回来。

2.3 HTTP协议格式
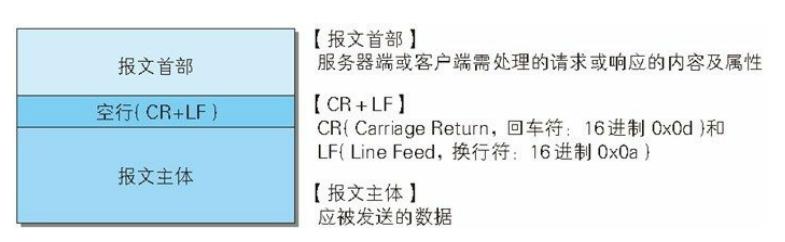
2.3.1 HTTP请求报文格式

上述就是一个请求报文的格式:
每一行都是用 \\r\\n作为改行的结束标记
- 首行: 称为请求行,用空格分为三部分
请求方法:GET… 其它方法下文介绍
url: …想要请求资源所在的路径
http版本: HTTP/1.1- 请求报头:
每一行都是一个键值对key: value\\r\\n
其中Content-Length:表示请求正文的长度,从请求报头后的多少个字节内容是请求正文。- 空行
\\r\\n用于分离请求报头与有效载荷- 请求正文(有效载荷): GET方法不需要携带正文,POST必须携带正文

请求方法
- GET: 向服务端请求某些资源,也可以给服务端提交少量的数据(url),url的长度是有限制的,提交的请求会在地址栏中显示出来。
- POST: 向服务器提交某些数据,提交的数据在请求报文中存储,提交时地址栏看不到提交内容,相对GET方法较私密。
- HEAD: 获取响应报文头部信息,并没有获取响应正文,是为了测试资源是否有效。
- DELETE:删除文件
- PUT: 传输文件
DELETE和PUT两种方法,http都没有校验,一般情况后台的服务端不支持PUT和DELETE方法- OPTIONS:询问服务端支持的方法
2.3.1 HTTP响应报文格式
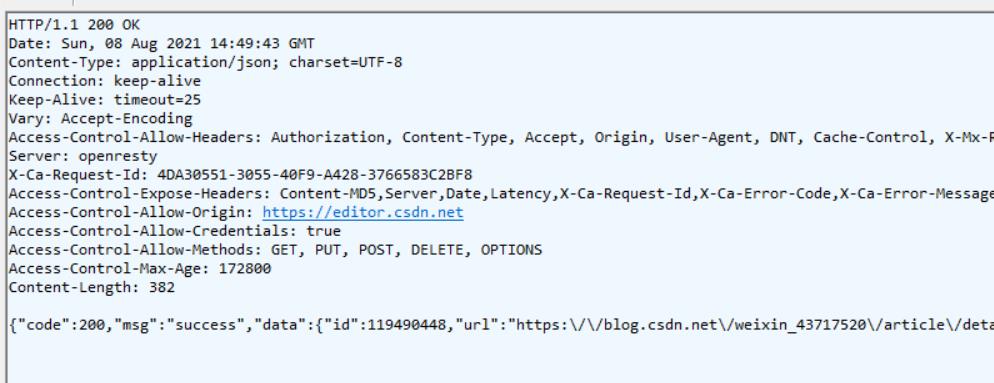
每一行都是用 \\r\\n作为改行的结束标记
- 首行: 响应行,三部分
协议版本: http/1.1
状态码: 200
状态码描述- 响应报头
由很多key/value构成- 空行
- 响应正文: 是发送请求后,服务器向客户端发送的数据

2.4 状态码及解释
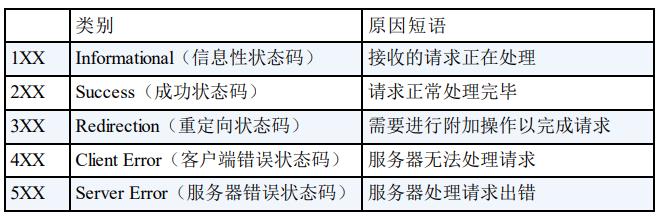
- 2XX 成功, 2XX 的响应结果表明请求被正常处理了。
200 OK表示从客户端发来的请求在服务器端被正常处理了。
204 No Content
206 Partial Content- 3XX 重定向
301 Moved Permanently 永久性重定向。
302 Found 临时性重定向
303 See Other
307 Temporary Redirect 临时重定向。- 4XX 客户端错误
400 Bad Request
401 Unauthorized 认证失败
403 Forbidden
404 Not Found- 5XX 服务器错误
500 Internal Server Error 该状态码表明服务器端在执⾏请求时发⽣了错误。也有可能是 Web应⽤存在的 bug 或某些临时的故障。
503 Service Unavailabl
2.5 HTTP的响应首部字段
这里只列举最常见的几种
- Content-Type: 正文类型 text、html、css、js等
- Content-Length: 正文长度
- Host: 客户端告知服务器,所请求的资源是在哪个主机的哪个端口上
- User-Agent: 声明用户的操作系统和浏览器版本信息
- Referer: 当前页面是从哪个页面跳转过来的
- Location: 搭配3xx状态码使用,告诉客户端接下来去哪访问
- Conection: keep-alive 保持长连接
- Cookie:下方详解
Cookie
1.概念
- 用于在客户端浏览器存储少量的信息,通常用于实现会话的功能,本质是浏览器中的一个文件
- cookie是服务器返回给浏览器,由浏览器进行保存cookie
- 在访问服务器的其它页面时,由浏览器自动在请求体当中加上cookie
2.作用
服务端通过cookie当中的value值,可以得到服务端生成session,通过会话id,可以在服务端查询出来是哪一个用户的session。浏览器通过请求中的cookie信息提交到服务器,服务端就可以通过cookie保存的会话信息,进行会话校验。
3. HTTP和HTTPS
3.1 HTTP
我们已了解到 HTTP 具有相当优秀和方便的一面,然而HTTP 并非只有好的一面,事物皆具两面性,它也是有不足之处的。
HTTP 主要有这些不足,例举如下。
- 通信使用明文(不加密),内容可能会被窃听
- 不验证通信方的身份,因此有可能遭遇伪装
- 无法证明报文的完整性,所以有可能已遭篡改
这些问题不仅在 HTTP 上出现,其他未加密的协议中也会存在这类问题。除此之外,HTTP 本身还有很多缺点。而且,还有像某些特定的 Web服务器和特定的 Web 浏览器在实际应用中存在的不足(也可以说成是脆弱性或安全漏洞),另外,用 Java 和 PHP 等编程语言开发的
Web 应用也可能存在安全漏洞。
3.2 HTTPS
HTTP 协议中没有加密机制,但可以通过和 SSL(Secure Socket Layer,安全套接层)或TLS(Transport Layer Security,安全层传输协议)的组合使用,加密 HTTP 的通信内容。
用 SSL建立安全通信线路之后,就可以在这条线路上进行 HTTP通信了。与 SSL组合使用的 HTTP 被称为 HTTPS(HTTPSecure,超文本传输安全协议)或 HTTP over SSL。
HTTP+ 加密 + 认证 + 完整性保护 = HTTPS
HTTPS中的认证方式
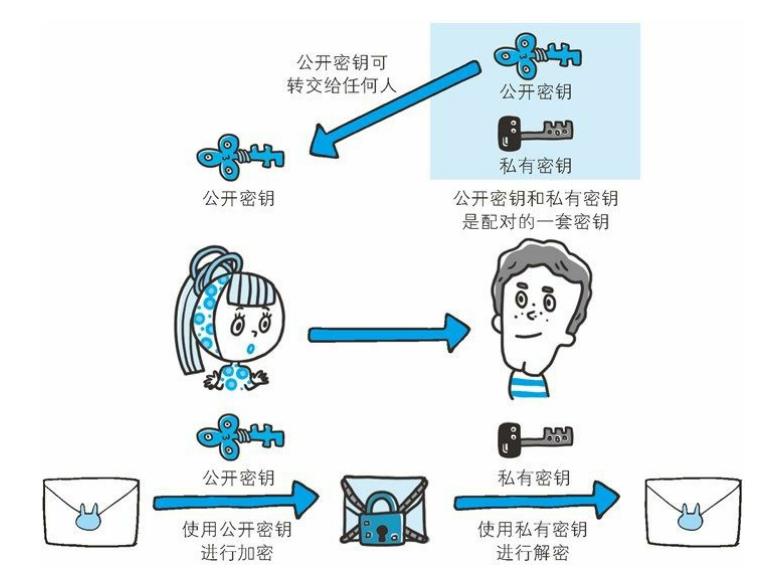
SSL采用一种叫做公开密钥加密(Public-key cryptography)的加密处理方式。近代的加密方法中加密算法是公开的,而密钥却是保密的。通过这种方式得以保持加密方法的安全性。
加密和解密都会用到密钥。没有密钥就无法对密码解密,反过来说,任何人只要持有密钥就能解密了。如果密钥被攻击者获得,那加密也就失去了意义。
加密和解密同用一个密钥的方式称为共享密钥加密(Common keycrypto system),也被叫做对称密钥加密。
以共享密钥方式加密时必须将密钥也发给对方。可究竟怎样才能安全地转交?在互联网上转发密钥时,如果通信被监听那么密钥就可会落入攻击者之手,同时也就失去了加密的意义。另外还得设法安全地保管接收到的密钥。

使用两把密钥的公开密钥加密
公开密钥加密方式很好地解决了共享密钥加密的困难。公开密钥加密使用一对非对称的密钥。一把叫做私有密钥(private key),另一把叫做公开密钥(public key)。顾名思义,私有密钥不能让其他任何人知道,而公开密钥则可以随意发布,任何人都可以获得。
使用公开密钥加密方式,发送密文的一方使用对方的公开密钥进行加密处理,对方收到被加密的信息后,再使用自己的私有密钥进行解密。利用这种方式,不需要发送用来解密的私有密钥,也不必担心密钥被攻击者窃听而盗走。
4. HTTP代码示例

http 服务端
#include <iostream>
#include <cstring>
#include <string>
#include <cstdlib>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/stat.h>
#include <fcntl.h>
#define READFILESIZE 4096
class HttpServer
private:
int port;
int lsock;
public:
HttpServer(int _port)
: port(_port)
, lsock(-1)
void InitServer()
signal(SIGCHLD, SIG_IGN);
lsock = socket(AF_INET, SOCK_STREAM, 0);
if (lsock < 0)
std::cerr << "socket err..." << std::endl;
exit(2);
struct sockaddr_in local;
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = INADDR_ANY;
if (bind(lsock, (struct sockaddr*)&local, sizeof(local)) < 0)
std::cerr << "bind err..." << std::endl;
exit(3);
if (listen(lsock, 5) < 0)
std::cerr << "listen err..." << std::endl;
exit(4);
// 设置端口复用,断开连接可以立即使用该端口,跳过TIME_WAIT
int opt = 1;
setsockopt(lsock, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
// 读取所请求的资源,将资源内容添加到响应报文中
std::string ReadHTMLfile(std::string file)
std::string path = "./WEB";
path += file;
int fd = open(path.c_str(), O_RDONLY);
if (fd < 0)
std::cerr << "open err..." << std::endl;
exit(6);
char buf[READFILESIZE];
std::string res;
size_t rlen;
while (true)
rlen = read(fd, buf, sizeof(buf) - 1);
res += buf;
// 清空buf缓冲区 很重要
memset(buf, '\\0', sizeof(buf));
if (rlen < READFILESIZE - 1)
break;
return res;
// 提取请求中的资源的后缀
std::string ExtractSuffix(std::string filepath)
std::string suffix;
size_t pos = filepath.find_last_of(".");
if (pos != std::string::npos)
suffix = filepath.substr(pos + 1, filepath.size() - (filepath.size() - pos));
else
suffix = "/";
return suffix;
std::string ResponseHead(std::string suffix)
// 添加响应报头
std::string response;
response += "HTTP/1.1 200 OK\\r\\n";
if (suffix == "/" || suffix == "html")
response += "Content-type: text/html\\r\\n";
else if (suffix == "css")
response += "Content-type: text/css\\r\\n";
else if (suffix == "js")
response += "Content-type: text/javascript\\r\\n";
// 图片不能正常的读取
else if (suffix == "jpg")
response += "Accept-Ranges: bytes\\r\\n";
response += "Content-Type: image/jpeg\\r\\n";
else if (suffix == "png")
response += "Accept-Ranges: bytes\\r\\n";
response += "Content-Type: image/png\\r\\n";
return response;
// 组装响应报文
std::string ResponseContent(std::string filepath)
// 查找文件 条件响应信息
std::string responseContent;
responseContent.clear();
// 从文件中读取数据,添加至response报头
if (filepath == "/")
// 读取login.js 末尾会出现问题
responseContent += ReadHTMLfile("/login.html");
else
responseContent += ReadHTMLfile(filepath);
// 查找后缀
std::string suffix = ExtractSuffix(filepath);
std::string response;
response += ResponseHead(suffix);
//response += "Content-Length: " + std::to_string(responseContent.size());
response += "\\r\\n";
response += responseContent;
return response;
// 资源提取
std::string ExtractPath(char* request)
// 提取报头信息中请求文件路径
int posl = strcspn(request, " ");
int posr = strcspn(request + posl + 1, " ");
char buf[64];
memset(buf, '\\0', sizeof(buf));
strncpy(buf, request + posl + 1, posr);
std::string filepath = buf;
return filepath;
void EchoHttp(int sock)
char request[2048];
size_t s = recv(sock, request, sizeof(request), 0);
if (s > 0)
request[s] = 0;
std::cout << request << std::endl;
std::string filepath = ExtractPath(request);
// 向客户端相应
std::string response = ResponseContent(filepath);
send(sock, response.c_str(), response.size(), 0);
close(sock);
void StartServer()
struct sockaddr_in peer;
while (true)
socklen_t len = sizeof(peer);
int sock = accept(lsock, (struct sockaddr*)&peer, &len);
if (sock < 0)
std::cerr << "accept err..." << std::endl;
continue;
std::cout << "get a new connect ... done" << std::endl;
if (fork() == 0)
// child
close(lsock);
EchoHttp(sock);
exit(0);
close(sock);
~HttpServer()
if (lsock != -1)
close(lsock);
;
以上是关于HTTP协议格式详解的主要内容,如果未能解决你的问题,请参考以下文章