深度学习 Day 30——YOLOv5-C3模块实现
Posted -北天-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习 Day 30——YOLOv5-C3模块实现相关的知识,希望对你有一定的参考价值。
深度学习 Day 30——YOLOv5-C3模块实现
文章目录
一、前言

本期博客我们将利用YOLOv5算法中的C3模块搭建网络,了解学习一下C3的结构,方便后续我们的YOLOv5算法的学习,并在最后我们尝试增加C3模块来进行训练模型,看看准确率是否增加了。
二、我的环境
print("============查看GPU信息================")
# 查看GPU信息
!/opt/bin/nvidia-smi
print("==============查看pytorch版本==============")
# 查看pytorch版本
import torch
print(torch.__version__)
print("============查看虚拟机硬盘容量================")
# 查看虚拟机硬盘容量
!df -lh
print("============查看cpu配置================")
# 查看cpu配置
!cat /proc/cpuinfo | grep model\\ name
print("=============查看内存容量===============")
# 查看内存容量
!cat /proc/meminfo | grep MemTotal
============查看GPU信息================
Tue Apr 4 07:08:04 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 43C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
==============查看pytorch版本==============
2.0.0+cu118
============查看虚拟机硬盘容量================
Filesystem Size Used Avail Use% Mounted on
overlay 79G 27G 53G 34% /
tmpfs 64M 0 64M 0% /dev
shm 5.7G 0 5.7G 0% /dev/shm
/dev/root 2.0G 1.1G 841M 58% /usr/sbin/docker-init
tmpfs 6.4G 88K 6.4G 1% /var/colab
/dev/sda1 78G 46G 32G 59% /opt/bin/.nvidia
tmpfs 6.4G 0 6.4G 0% /proc/acpi
tmpfs 6.4G 0 6.4G 0% /proc/scsi
tmpfs 6.4G 0 6.4G 0% /sys/firmware
drive 15G 0 15G 0% /content/drive
============查看cpu配置================
model name : Intel(R) Xeon(R) CPU @ 2.00GHz
model name : Intel(R) Xeon(R) CPU @ 2.00GHz
=============查看内存容量===============
MemTotal: 13297200 kB
三、数据处理
1、导入依赖项设置GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warnings
import random
warnings.filterwarnings('ignore')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
device(type='cuda')
2、导入数据
这里我们导入的是之前天气识别的数据集。
data_dir = '/content/drive/Othercomputers/我的笔记本电脑/深度学习/data/weather_photos'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split('/')[8] for path in data_paths]
classeNames
['cloudy', 'rain', 'shine', 'sunrise']
3、数据转换
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(data_dir, transform=train_transforms)
total_data
Dataset ImageFolder
Number of datapoints: 1125
Root location: /content/drive/Othercomputers/我的笔记本电脑/深度学习/data/weather_photos
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=warn)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
total_data.class_to_idx
'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3
4、划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
(<torch.utils.data.dataset.Subset at 0x7f93a0387fa0>,
<torch.utils.data.dataset.Subset at 0x7f93a0387d00>)
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=1)
5、查看数据信息
for x, y in test_dl:
print("Shape of x [N, C, H, W]:", x.shape)
print("Shape of y:", y.shape, y.dtype)
break
Shape of x [N, C, H, W]: torch.Size([4, 3, 224, 224])
Shape of y: torch.Size([4]) torch.int64
四、搭建包含YOLOv5-C3模块的模型
1、搭建模型
import torch.nn.functional as F
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch深度学习与图神经网络核心技术实践应用高级研修班-Day3强化学习(Reinforcemen learning)
强化学习(Reinforcemen learning)

强化学习简介
强化学习:强调如何基于环境而行动,以取得最大化的预期利益。
在强化学习的世界里, 算法称之为Agent, 它与环境发生交互,Agent从环境中获取状态(state),并决定自己要做出的动作(action),环境会根据自身的逻辑给Agent予以奖励(reward)。奖励有正向和反向之分。比如在游戏中,每击中一个敌人就是正向的奖励,掉血或者游戏结束就是反向的奖励。
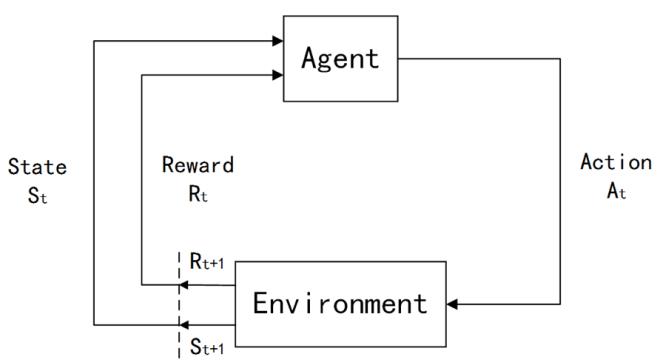
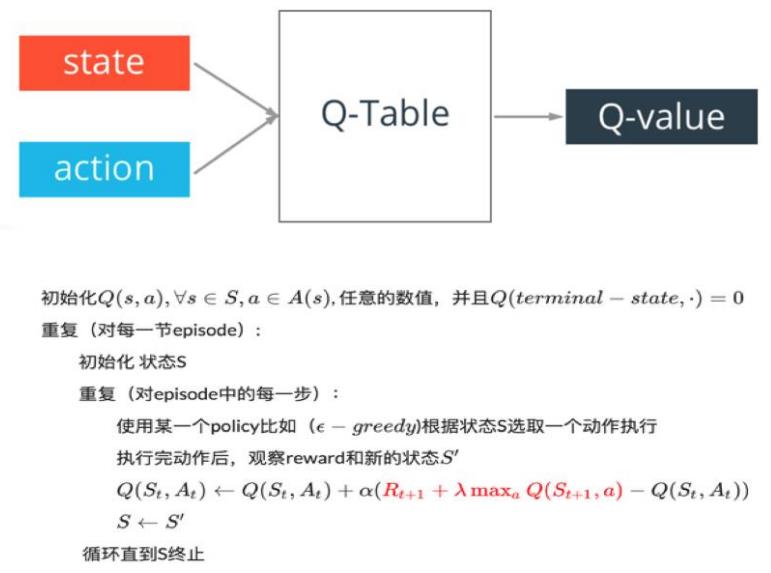
经典模型DQN
DQN—Markov Decision Process
马尔科夫决策过程一般包含如下五个元素:
- 状态集S。比如,物体的空间坐标
- 动作集A。比如,向上下左右移动
- 状态转移概率
{
P
s
s
′
a
}
\\left\\{P_{s s^{\\prime}}^{a}\\right\\}
{Pss′a}。
{
P
s
s
′
a
}
\\left\\{P_{s s^{\\prime}}^{a}\\right\\}
{Pss′a}表示在状态𝑠 ∈ 𝑆下执行动作𝑎 ∈ 𝐴后,转移到下一个状态𝑠′的概率分布,也可表示为
T
(
𝑠
,
𝑎
,
𝑠
′
)
T(𝑠, 𝑎, 𝑠′)
T(s,a,s′), 𝑠′便是在状态𝑠下执行动作𝑎后的状态.
- 阻尼系数𝛾,或者称为折扣因子(discount factor)
- 回报函数R,R:(𝑠, 𝑎) → 𝑅,表示当下状态下执行某个动作能得到的回报值.
决策过程如下:

回报值计算公式如下(仅与状态有关):
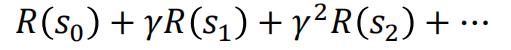
回报值计算公式如下(与状态、动作都有关):
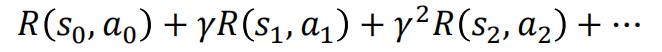
定义动作值函数(action-value funciotn)Q为在当前状态
s
0
s_0
s0下执行策略𝜋能得到累计折扣回报的期望:
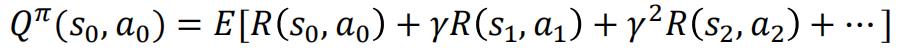
将上式表示为当前回报和后续回报的形式 :
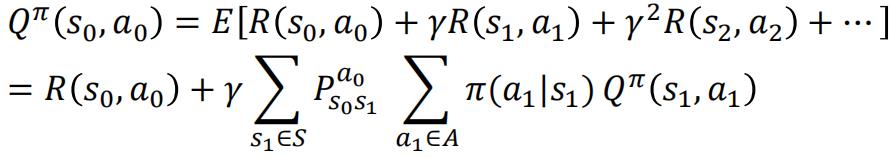
假设有一个最优策略𝜋,据此得到一个最优的值函数:
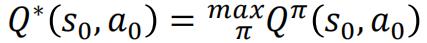
即Bellman equation的形式
目标:复制监督学习的成功到强化学习,用深度学习优化Q learning
方案:通过优化一个深度网络来近似函数𝑄∗
损失函数:求目标值(固定的)和𝑄𝜋当前估计值的MSE
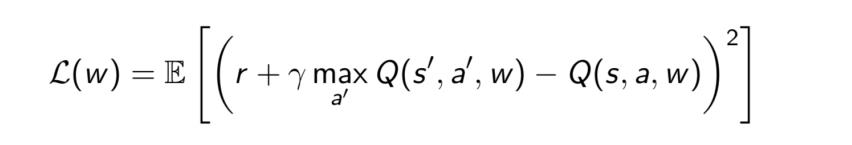
梯度更新:
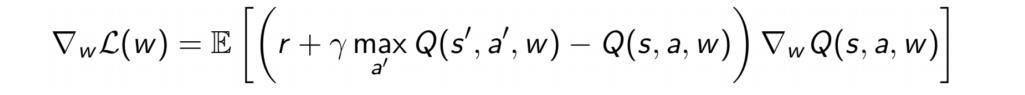
DL与RL结合的问题:
- DL需要大量带标签的样本进行监督学习;RL只有reward返回值,而且伴随着噪声,延迟(过了几十毫秒才返回),稀疏(很多State的reward是0)等问题;
- DL的样本独立;RL前后state状态相关;
- DL目标分布固定;RL的分布一直变化,比如你玩一个游戏,一个关卡和下一个关卡的状态分布是不同的,所以训练好了前一个关卡,下一个关卡又要重新训练;
- 过往的研究表明,使用非线性网络表示值函数时出现不稳定等问题。
DQN解决问题方法:
- 通过Q-Learning使用reward来构造标签(对应问题1)
- 通过experience replay(经验池)的方法来解决相关性及非静态分布问题(对应问题2、 3)
- 使用一个CNN(MainNet)产生当前Q值,使用另外一个CNN(Target)产生Target Q值(对应问题4)

AlphaGo原理
由于海量搜索空间、评估棋局和落子行为的难度,围棋长期以来被视为人工智能领域最具挑战的经典游戏。
DeepMind公司结合深度学习革命、古老的蒙特卡洛树搜索和强化学习开发出AlphaGo围棋程序,攻克了AI领域最耀眼的明珠,先后击败了李世石、柯洁等世界冠军,而以前这被认为是需要至少十年以上才能实现的伟业。
AlphaGo使用“价值网络”评估棋局、“策略网络”选择落子。这些深层神经网络,是由人类专家博弈训练的监督学习和电脑自我博弈训练的强化学习,共同构成的一种新型组合。
没有任何预先搜索的情境下,这些神经网络能与顶尖水平的、模拟了千万次随机自我博弈的蒙特卡洛树搜索程序下围棋。同时还引入了新的搜索算法:结合了估值和策略网络的蒙特卡洛模拟算法。
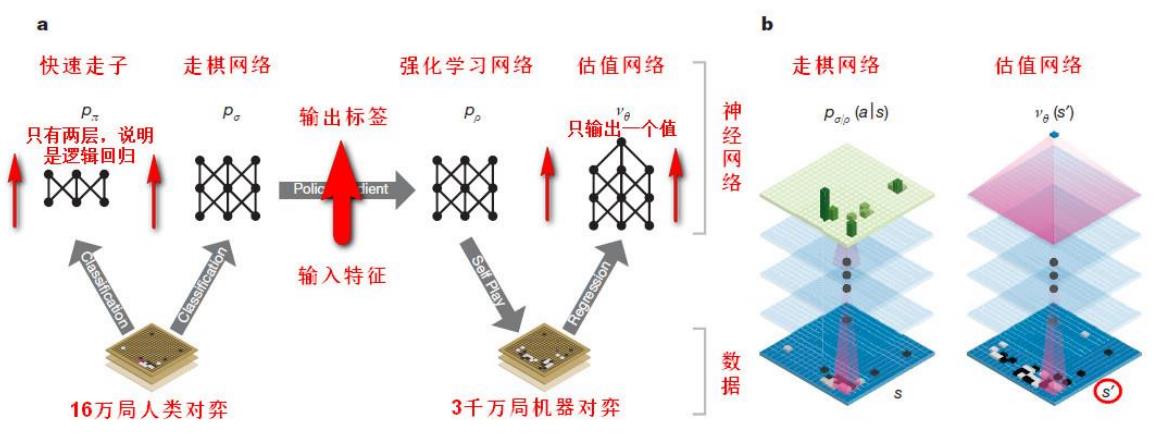
AlphaGo原理-网络结构
AlphaGo原理-训练过程
第一阶段:直接使用人类高手的落子弈法训练一种有监督学习(SL)型走棋策略网络,此阶段提供快速、高效的带有即时反馈和高品质梯度的机器学习更新数据。同时也训练了一个快速走棋策略𝑝𝜋,能对走子时的弈快速采样。
第二阶段:训练一种强化学习(RL)型的走棋策略网络𝑝_𝜌,通过优化那些自我博弈的最终结果,来提高前面的SL策略网络。此阶段是将该策略调校到赢取比赛的正确目标上,而非最大程度的预测准确性。
第三阶段:训练一种估值网络𝑉𝜃,来预测那些采用RL走棋策略网络自我博弈的赢家。最终AlphaGo用MCTS有效结合了策略和估值网络。
RL实际应用:Flappy Bird-深度卷积神经网络
第一阶段:应用深度卷积神经网络提取特征
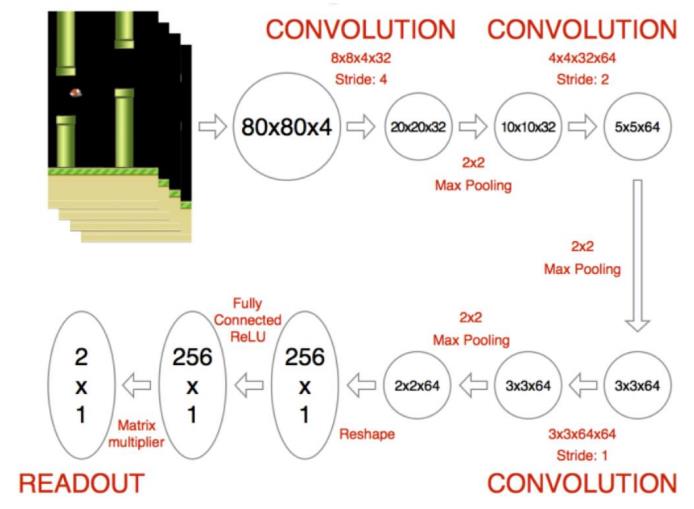
训练注意事项:
- 将图片背景去掉
- 除了卷积层,注意使用池化层
- 训练前先让游戏运行一会,让Bird做一些探索,帮助之后进行experience replay
RL实际应用:Flappy Bird-DQN算法应用
第二阶段:将深度卷积网络提取的特征作为训练数据执行DQN算法

RL实际应用:Flappy Bird-实验结果展示

以上是关于深度学习 Day 30——YOLOv5-C3模块实现的主要内容,如果未能解决你的问题,请参考以下文章