代码随想录算法训练营第五十六天 | 583. 两个字符串的删除操作72. 编辑距离编辑距离总结
Posted miodi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了代码随想录算法训练营第五十六天 | 583. 两个字符串的删除操作72. 编辑距离编辑距离总结相关的知识,希望对你有一定的参考价值。
583. 两个字符串的删除操作
动规五部曲
1、确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
2、确定递推公式
当word1[i - 1] 与 word2[j - 1]相同的时候,dp[i][j] = dp[i - 1][j - 1];
当word1[i - 1] 与 word2[j - 1]不相同的时候,有三种情况:
情况一:删word1[i - 1],最少操作次数为dp[i - 1][j] + 1
情况二:删word2[j - 1],最少操作次数为dp[i][j - 1] + 1
情况三:同时删word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2
当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式:dp[i][j] = min(dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1);
因为 dp[i][j - 1] + 1 = dp[i - 1][j - 1] + 2,所以递推公式可简化为:dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
当 同时删word1[i - 1]和word2[j - 1],dp[i][j-1] 本来就不考虑 word2[j - 1]了,那么在删 word1[i - 1],就达到了两个元素都删除的效果,即 dp[i][j-1] + 1
3、dp数组如何初始化
从递推公式中,可以看出来,dp[i][0] 和 dp[0][j]是一定要初始化的。
dp[i][0]:word2为空字符串,以i-1为结尾的字符串word1要删除多少个元素,才能和word2相同呢,很明显dp[i][0] = i。
4、确定遍历顺序
从递推公式 dp[i][j] = min(dp[i - 1][j - 1] + 2, min(dp[i - 1][j], dp[i][j - 1]) + 1); 和dp[i][j] = dp[i - 1][j - 1]可以看出dp[i][j]都是根据左上方、正上方、正左方推出来的。
5、举例推导dp数组
以word1:"sea",word2:"eat"为例,推导dp数组状态图如下:
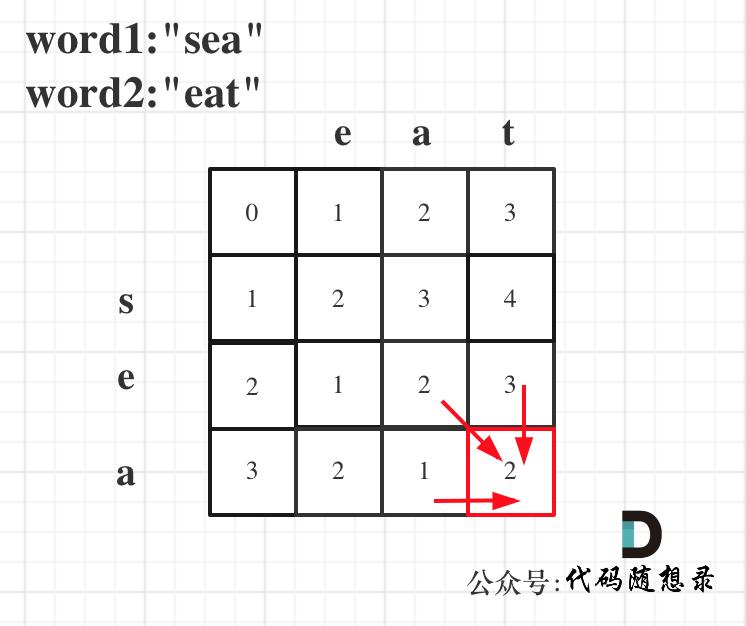
class Solution
public:
int minDistance(string word1, string word2)
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for (int i = 1; i <= word1.size(); i++)
for (int j = 1; j <= word2.size(); j++)
if (word1[i - 1] == word2[j - 1])
dp[i][j] = dp[i - 1][j - 1];
else
dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
return dp[word1.size()][word2.size()];
;思路二
只要求出两个字符串的最长公共子序列长度即可,那么除了最长公共子序列之外的字符都是必须删除的,最后用两个字符串的总长度减去两个最长公共子序列的长度就是删除的最少步数。
class Solution
public:
int minDistance(string word1, string word2)
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1, 0));
for (int i = 1; i <= word1.size(); i++)
for (int j = 1; j <= word2.size(); j++)
if (word1[i - 1] == word2[j - 1])
dp[i][j] = dp[i - 1][j - 1] + 1;
else
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
return word1.size() + word2.size() - dp[word1.size()][word2.size()] * 2;
;72. 编辑距离
动规五部曲
1、确定dp数组(dp table)以及下标的含义
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
2、确定递推公式
在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下:
if (word1[i - 1] == word2[j - 1])
不操作
if (word1[i - 1] != word2[j - 1])
增
删
换if (word1[i - 1] == word2[j - 1]) 那么说明不用任何编辑,dp[i][j] 就应该是 dp[i - 1][j - 1],即dp[i][j] = dp[i - 1][j - 1];
if (word1[i - 1] != word2[j - 1])
- 操作一:word1删除一个元素,那么就是以下标i - 2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i - 1][j] + 1;
- 操作二:word2删除一个元素,那么就是以下标i - 1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i][j - 1] + 1;
word2添加一个元素,相当于word1删除一个元素,例如 word1 = "ad" ,word2 = "a",word1删除元素'd' 和 word2添加一个元素'd',变成word1="a", word2="ad"
操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增删加元素。
当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min(dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]) + 1;
3、dp数组如何初始化
dp[i][0] :以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][0]。
那么dp[i][0]就应该是i,对word1里的元素全部做删除操作,即:dp[i][0] = i;
同理dp[0][j] = j;
4、确定遍历顺序
从如下四个递推公式:
dp[i][j] = dp[i - 1][j - 1]dp[i][j] = dp[i - 1][j - 1] + 1dp[i][j] = dp[i][j - 1] + 1dp[i][j] = dp[i - 1][j] + 1
可以看出dp[i][j]是依赖左方,上方和左上方元素的,如图:

所以在dp矩阵中一定是从左到右从上到下去遍历。
5、举例推导dp数组
以示例1为例,输入:word1 = "horse", word2 = "ros"为例,dp矩阵状态图如下:

class Solution
public:
int minDistance(string word1, string word2)
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for (int i = 1; i <= word1.size(); i++)
for (int j = 1; j <= word2.size(); j++)
if (word1[i - 1] == word2[j - 1])
dp[i][j] = dp[i - 1][j - 1];
else
dp[i][j] = min(dp[i - 1][j], min(dp[i][j - 1], dp[i - 1][j - 1])) + 1;
return dp[word1.size()][word2.size()];
;
编辑距离总结
编辑距离从判断子序列->判断子序列 ->不同的子序列 ->两个字符串的删除操作->编辑距离
以上四个题都是从最初子序列开始,在原本一个子序列的基础上,变成了二维,通过观察每次解题代码可以发现,其实各题在解题思路上都几乎类似,难点在于递推公式的推导与初始化,递推公式的推导要在理解各题要求的同时,思考该如何得出当前状态,时刻谨记dp数组的定义有利于递推公式推导
代码随想录算法训练营第五十八天|739.每日温度496.下一个更大元素Ⅰ
day58 2023/03/30
一、每日温度
请根据每日 气温 列表,重新生成一个列表。对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
提示:气温 列表长度的范围是 [1, 30000]。每个气温的值的均为华氏度,都是在 [30, 100] 范围内的整数。
分析如下:
要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了
单调栈的本质是空间换时间
在使用单调栈的时候首先要明确如下几点:
1.单调栈里存放的元素是什么?
单调栈里只需要存放元素的下标i就可以了,如果需要使用对应的元素,直接T[i]就可以获取。
2.单调栈里元素是递增呢? 还是递减呢?
注意以下讲解中,顺序的描述为 从栈头到栈底的顺序
使用单调栈主要有三个判断条件。
- 当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
具体分析见代码随想录,分析的好透彻,好强
代码如下:
class Solution
public:
vector<int> dailyTemperatures(vector<int>& temperatures)
stack<int> st;
vector<int> result(temperatures.size(),0);
st.push(0);
for(int i=1;i<temperatures.size();i++)
if(temperatures[i]<temperatures[st.top()])
st.push(i);
else if(temperatures[i]==temperatures[st.top()])
st.push(i);
else
while(!st.empty()&&temperatures[i]>temperatures[st.top()])
result[st.top()]=i-st.top();
st.pop();
st.push(i);
return result;
;二、下一个更大元素Ⅰ
给你两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。
请你找出 nums1 中每个元素在 nums2 中的下一个比其大的值。
nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出 -1 。
分析如下:
整体逻辑与上题相同,只是本题使用了一个map
代码如下:
class Solution
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2)
stack<int> st;
vector<int> result(nums1.size(), -1);
if (nums1.size() == 0) return result;
unordered_map<int, int> umap; // key:下标元素,value:下标
for (int i = 0; i < nums1.size(); i++)
umap[nums1[i]] = i;
st.push(0);
for (int i = 1; i < nums2.size(); i++)
if (nums2[i] < nums2[st.top()]) // 情况一
st.push(i);
else if (nums2[i] == nums2[st.top()]) // 情况二
st.push(i);
else // 情况三
while (!st.empty() && nums2[i] > nums2[st.top()])
if (umap.count(nums2[st.top()]) > 0) // 看map里是否存在这个元素
int index = umap[nums2[st.top()]]; // 根据map找到nums2[st.top()] 在 nums1中的下标
result[index] = nums2[i];
st.pop();
st.push(i);
return result;
;以上是关于代码随想录算法训练营第五十六天 | 583. 两个字符串的删除操作72. 编辑距离编辑距离总结的主要内容,如果未能解决你的问题,请参考以下文章