selenium框架介绍及安装
Posted Lefdr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了selenium框架介绍及安装相关的知识,希望对你有一定的参考价值。
1、selenium框架详解
1.1 什么是selenium
selenium是一个用于web应用程序测试的工具,可以直接在浏览器中运行,通过驱动浏览器代替人工完成兼容性测试和功能回归测试,支持多浏览器(IE、Chrome、Firefox、Safari)、多语言开发(Java,C,Python,javascript,Ruby,php)
1.2 selenium工作原理
selenium主要分为:脚本文件、webdriver、浏览器。脚本文件用于启动webdriver,发出请求,webdriver解析请求信息,启动浏览器,执行用户请求。

webdriver简述一下:
- webdriver是按照client-server的经典模式设计的
- server端就是remoteserver,脚本启动的浏览器,它的职责就是等待client发送请求并做出响应
- client端就是我们写的测试代码,操作命令以http请求的方式发送,server接受请求,执行相应操作,并在response中返回执行状态、返回值等信息
2、selenium环境
2.1 selenium安装
- 有两种方式:
1)打开cmd,进入python安装目录下,使用pip命令安装或者pycharm的命令行安装

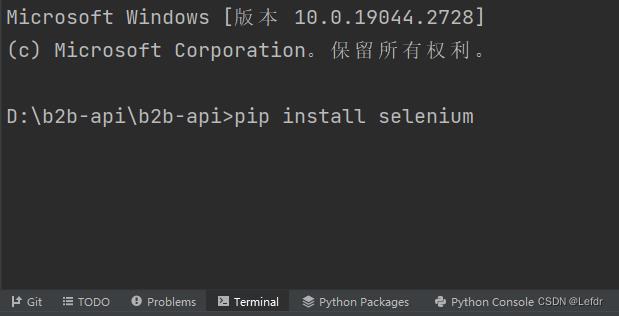
也可指定版本号安装

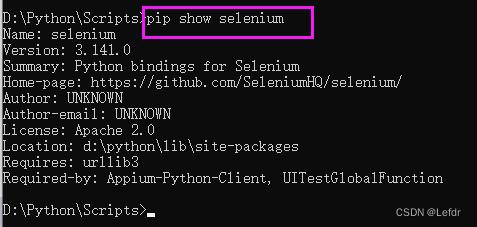
安装成功后查看安装信息
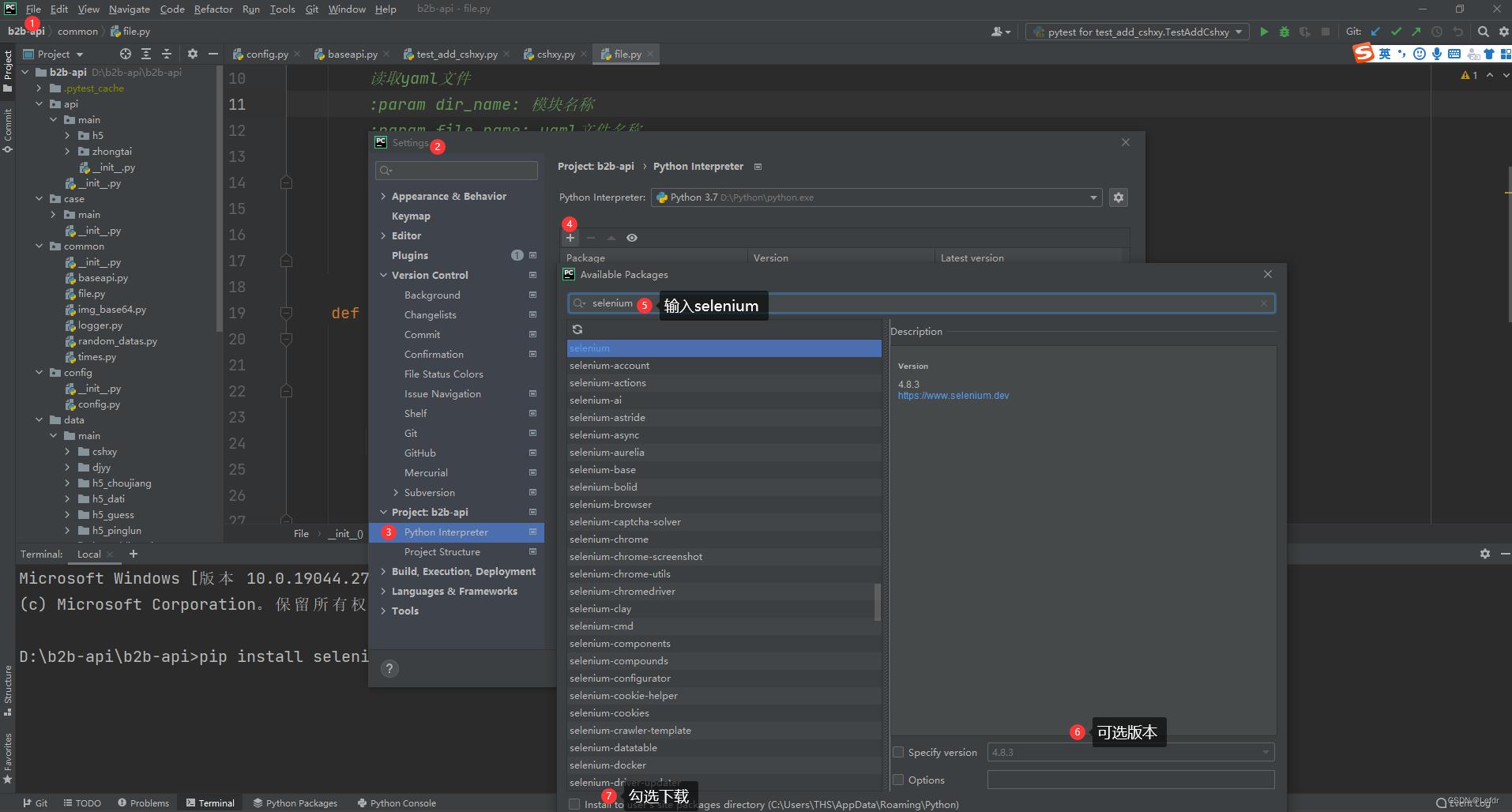
2)打开pycharm-File-Setting-Python Interpreter下载
2.2 驱动安装
Chrome驱动下载地址:http://chromedriver.storage.googleapis.com/index.html
火狐驱动下载地址为:https://github.com/mozilla/geckodriver/releases/
IE驱动的下载地址:https://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
不同浏览器需要安装的驱动不同,这里以Chrome浏览器为例
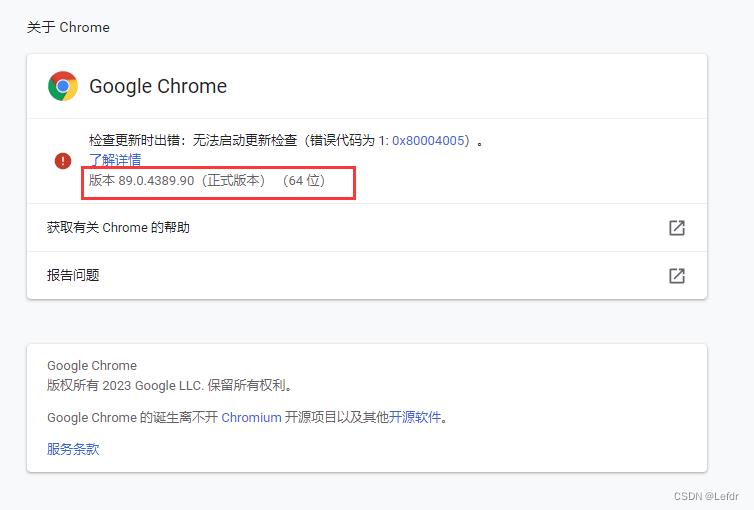
2.2.1 查看浏览器版本
设置-关于Google Chrome
2.2.2 下载对应版本的驱动
找到和浏览器版本最近的驱动下载
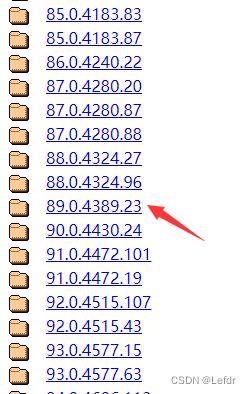
选择32位Windows系统下载
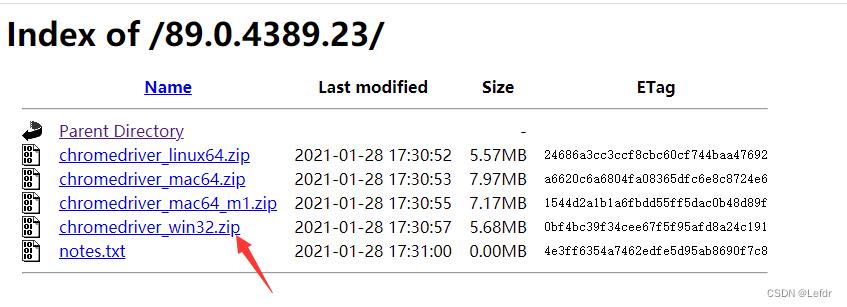
2.2.3 移动chromedriver路径
将Chromedriver放在Chrome安装路径相同的目录下(放在python安装目录下也可,亲测正常)

2.2.4 配置环境变量
打开电脑属性-高级设置-环境变量-系统变量path,添加Chromedriver的路径
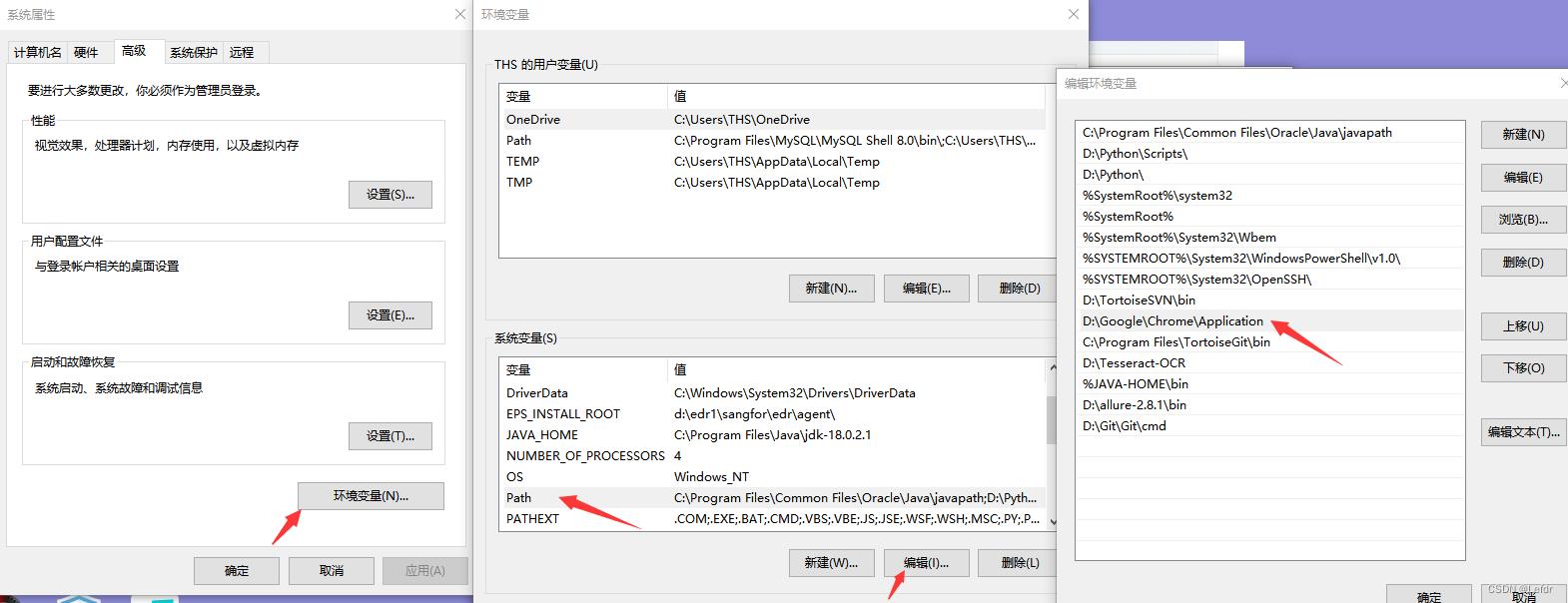
安装已完成!!!
2.2.5 测试安装是否成功
直接上代码~~
import time
from selenium import webdriver
browser = webdriver.Chrome() # 实例化对象
browser.get('https://www.baidu.com') # 必须是绝对路径
browser.find_element_by_id('kw').clear()
browser.find_element_by_id('kw').send_keys('杭州')
browser.find_element_by_id('su').click()
time.sleep(10)
browser.quit()
运行后能直接驱动打开浏览器就可以了!
Python Selenium框架
目录
1、selenium介绍
2、selenium安装
3、selenium常用操作
4、QQ空间模拟登陆
5、图片懒加载1. selenium介绍
# 介绍:
1.selenium是一个web自动化测试用的框架. 程序员可以通过代码实现对浏览器的控制, 比如打开网页, 点 击网页中的元素, 实现鼠标滚动等操作.
2.它支持多款浏览器, 如谷歌浏览器, 火狐浏览器等等, 当然也支持无头浏览器.
# 目的:
在爬取数据的过程中, 经常遇到动态数据加载, 一般动态数据加载有两种, 一种通过ajax请求加载数据, 另 一种通过js代码加载动态数据. selenium可以模拟人操作真实浏览器, 获取加载完成的页面数据
ajax:
url有规律且未加密, 直接构建url连接请求
url加密过无法破解规律 --> selenium
js动态数据加载 --> selenium2. selenium安装
三要素: 浏览器, 驱动程序, selenium框架
浏览器: 推荐谷歌浏览器, 标准稳定版本 驱动程序:http://chromedriver.storage.googleapis.com/index.html pip install selenium
# 测试:
from selenium import webdriver
browser = webdriver.Chrome('./chromedriver.exe') # 将驱动放在脚本所在的文件夹
browser.get('https://www.baidu.com')3. selenium常用操作
# 实例化浏览器对象:
from selenium import webdriver
browser = webdriver.Chrome('driverpath')
# 发送get请求:
browser.get('https://www.baidu.com')
browser.get('https://image.baidu.com')
# 获取网页的数据: browser.page_source ---> str类型
# 获取页面元素:
find_element_by_id:根据元素的id
find_element_by_name:根据元素的name属性 find_element_by_xpath:根据xpath表达式 find_element_by_class_name:根据class的值 find_element_by_css_selector:根据css选择器
# 节点交互操作:
click(): 点击
send_keys(): 输入内容
clear(): 清空操作
execute_script(js): 执行指定的js代码
# JS代码: window.scrollTo(0, document.body.scrollHeight)可以模拟鼠标滚动一屏高度
quit(): 退出浏览器
# frame
# 若爬取一个页面,需观察如果有两个HTML(一个父HTML,一个子HTML),所需内容在子HTML中,则需要switch_to.frame('frameid') 转至子页面继续操作
switch_to.frame('frameid') 4. QQ空间模拟登陆
from selenium import webdriver
import time
# 实例化浏览器对象
browser = webdriver.Chrome('./chromedriver.exe')
# 打开qq空间登陆页面
browser.get('https://qzone.qq.com/')
time.sleep(1)
# 转至frame子页面
browser.switch_to.frame('login_frame')
# 获取密码登陆选项并点击
a_tag = browser.find_element_by_id('switcher_plogin')
a_tag.click()
time.sleep(1)
# 获取账号输入框并输入账号
browser.find_element_by_id('u').clear()
user = browser.find_element_by_id('u')
user.send_keys('1816668038')
time.sleep(1)
# 获取密码输入框并输入密码
browser.find_element_by_id('p').clear()
pwd = browser.find_element_by_id('p')
pwd.send_keys('1971628197192liu')
time.sleep(1)
# 获取登陆按钮并单击
button = browser.find_element_by_id('login_button')
button.click()
'''
微博模拟登陆
'''''
# import requests,time
# from selenium import webdriver
# broeser = webdriver.Chrome('./chromedriver.exe')
# broeser.get('https://weibo.com/login.php')
#
# input_tag = broeser.find_element_by_id('loginname')
# input_tag.clear()
# input_tag.send_keys('15135544556')
# time.sleep(3)
# input_tag_pwd = broeser.find_element_by_xpath('//div[@class="info_list password"]/div[@class="input_wrap"]/input')
# input_tag_pwd.clear()
# input_tag_pwd.send_keys('123456789liu')
# time.sleep(3)
# button_tag = broeser.find_element_by_xpath('//div[@class="W_login_form"]/div[@class="info_list login_btn"]/a')
# button_tag.click()5. 图片懒加载
'''
网址 http://sc.chinaz.com/tupian/ 站长素材
图片懒加载
'''''
import requests
from lxml import etree
url = 'http://sc.chinaz.com/tupian/bingxueshijie.html'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
res = requests.get(url=url,headers=headers)
tree = etree.HTML(res.text)
#src2的位置,在必要的时候可以把值赋给src----懒加载核心
ret = tree.xpath('//div[@id="container"]/div/div/a/img/@src2')
for i in ret:
comment = requests.get(url=i,headers=headers).content
name = i.split('/')[-1]
with open('./image/%s'% name,'wb') as f:
f.write(comment)以上是关于selenium框架介绍及安装的主要内容,如果未能解决你的问题,请参考以下文章