阿里云随笔(10)-PAI-AutoML
Posted 麦好
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云随笔(10)-PAI-AutoML相关的知识,希望对你有一定的参考价值。
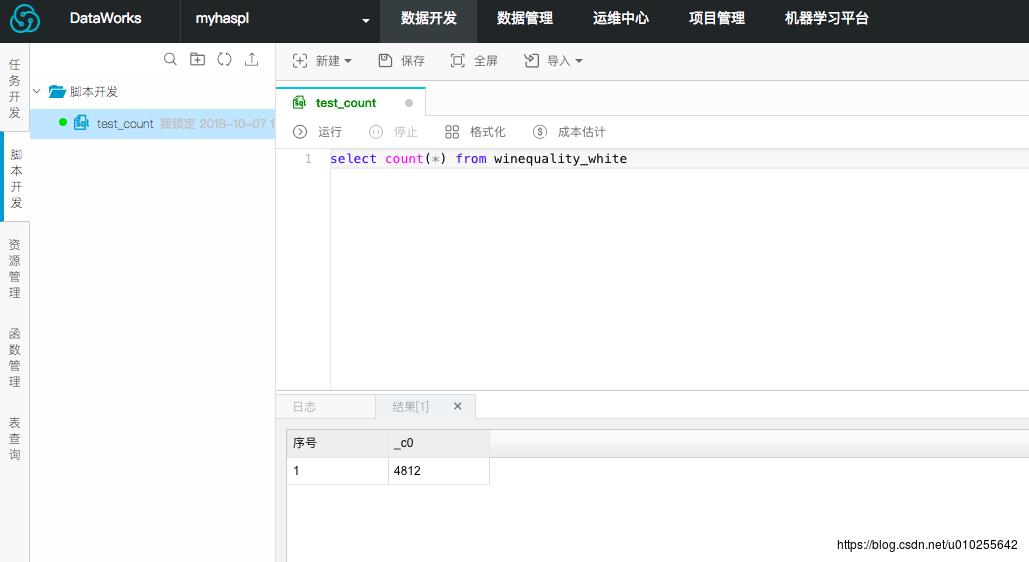
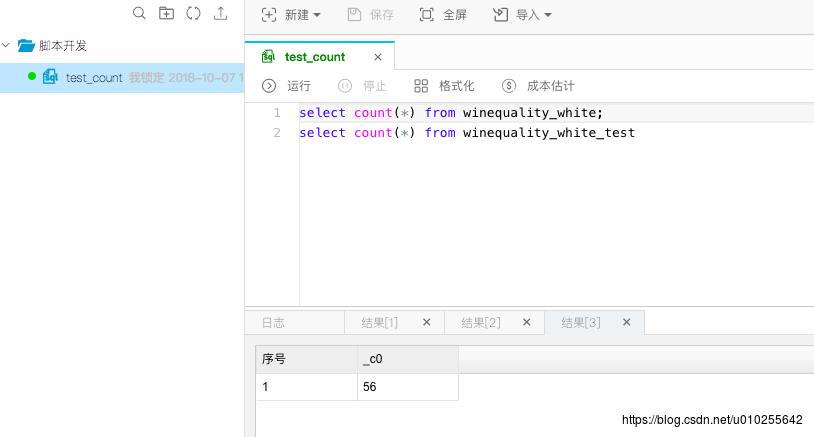
在数据管理中,重新上传完整的白葡萄酒数据。然后可以进入数据开发,写sql代码对数据表进行查询。比如统计训练样本和测试数据的大小。
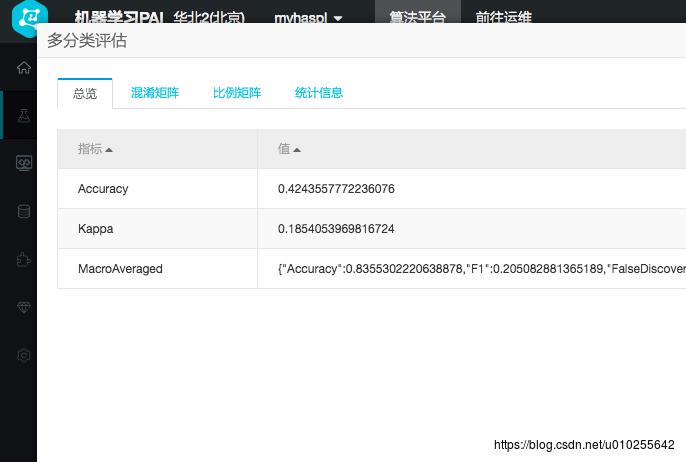
打开建立好的葡萄酒质量多分类模型
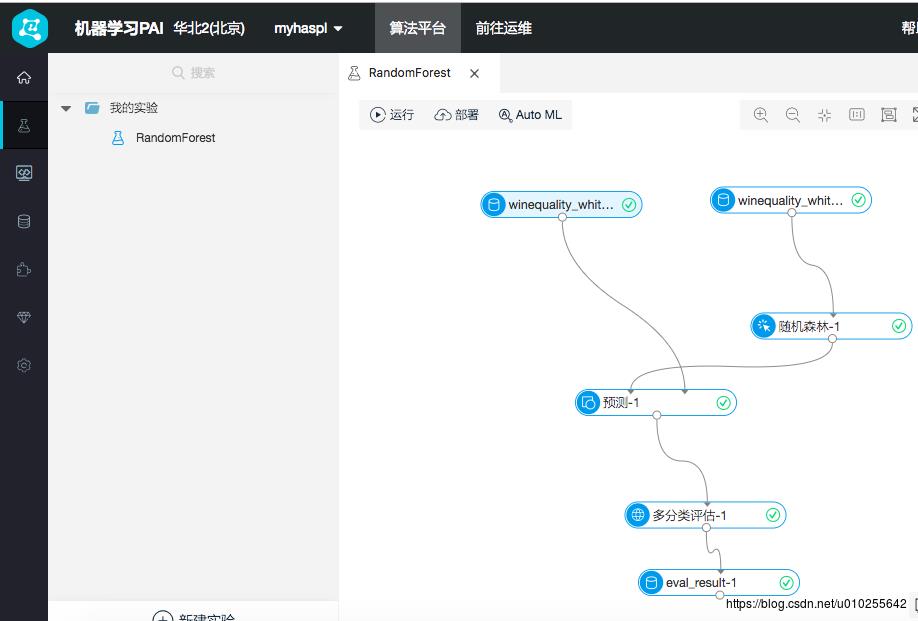
看看分类评结果。正确率83.55%
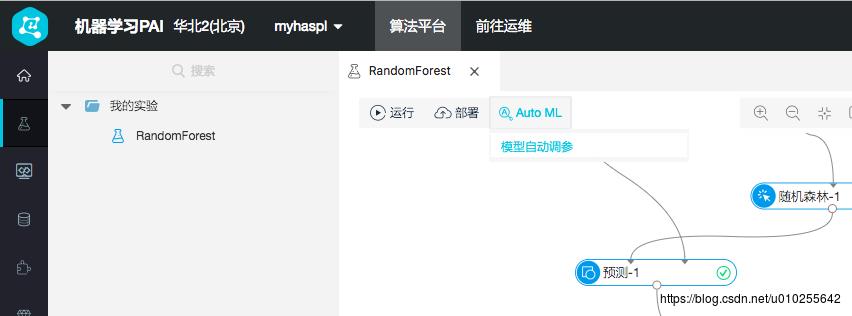
开始自动调参
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 Leo Breiman和Adele Cutler发展出推论出随机森林的算法。 而 “Random Forests” 是他们的商标。 这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合 Breimans 的 “Bootstrap aggregating” 想法和 Ho 的"random subspace method"以建造决策树的集合。
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。
根据下列算法而建造每棵树 [1] :
用N来表示训练用例(样本)的个数,M表示特征数目。
输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这m个特征,计算其最佳的分裂方式。
每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用)。
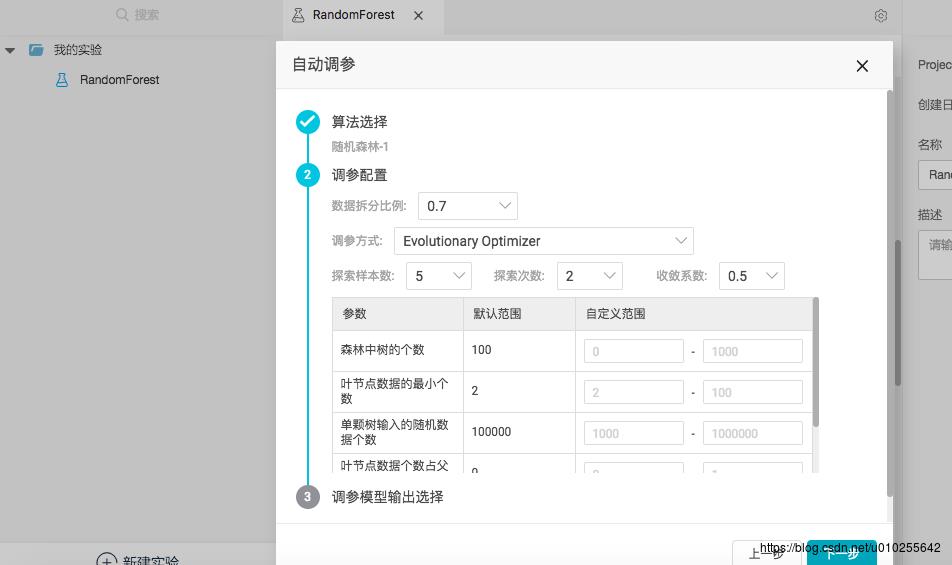

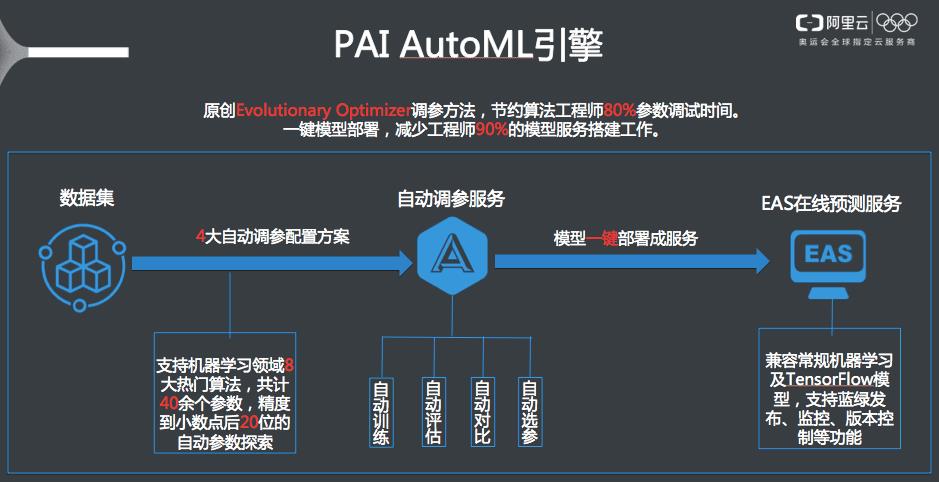
Evolutionary Optimizer
原理:
随机选定a个参数候选集(探索样本数a)。
取其中评估指标较高的n个参数候选集,作为下一轮迭代的参数候选集。
继续在这些参数周边的r倍(收敛系数r)标准差范围探索,以探索出新的参数集,来替代上一轮中评估指标靠后的那些a-n个参数集。
根据以上逻辑,迭代m轮(探索次数m),直到找到最优的参数集合。
根据以上原理,最终产生的模型数目为 a+(a-n)*m 。
数据拆分比例:将输入数据源分为训练集以及评估集,0.7 表示 70% 的数据用于训练模型,30% 用于评估。
探索样本数:每轮迭代的参数集个数,个数越多越准,计算量越大,取值为 5~30(正整数)。
探索次数:迭代轮数,轮数越多探索越准,计算量越大,取值 1~10(正整数)。
收敛系数:用来调节探索范围(上文提到的 r 倍标准差范围搜索),越小收敛越快,但是可能会错过好的参数,取值0.1~1(小数点后一位浮点数)。
需要输入每个参数的调节范围,如果未改变当前参数范围,则此参数按照默认值代入,并不参与自动调参。
在调参模型输出选择模块,配置模型输出参数,完成后单击下一步。
模型评估:可选择 AUC、F1-score、PRECISION、RECALL 四个维度中的一个作为评估标准。
模型保存:保存模型可以选择 1~5 个。根据您所选择的评估标准,对模型进行排名,最终保存排名靠前的几个模型,数量对应您所选择的保存模型数量。
模型是否向下传导:开关默认打开。如果开关关闭,将将当前组件的默认参数生成的模型,向下传导至后续组件节点。如果开关打开,则将自动调参生成的最优模型,向下传导至后续组件节点。

以上是关于阿里云随笔(10)-PAI-AutoML的主要内容,如果未能解决你的问题,请参考以下文章