大数据=SQL Boy,SQL Debug打破SQL Boy 的僵局
Posted 诸葛子房_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据=SQL Boy,SQL Debug打破SQL Boy 的僵局相关的知识,希望对你有一定的参考价值。
网上经常盛传 大数据=sql boy,后端开发=crud boy,算法工程师=调参boy
在大数据领域也工作了好几年了,确实大数据开发,很多工作就是写sql,hive sql、spark sql、flink sql等等sql
一、背景:
但是经常有这样一个需求,一大段sql 跑出来之后,发现不是自己想要的结果?比如:
demo 1:
select id,name from (
select id,name from table1
union all
select id,name from table2
union all
select id,name from table3
union all
select id,name from table4
)t group by id,name
demo 2:
select a.id,a.name,a.class from (select id,name from table1 where id>=10) a left join (select name,class from table2 where name is not null)
b on a.name=b.name;比如说:
demo 1 中的sql 出来这样的结果数据
| id | name |
|---|---|
| 101 | xiaolan |
| 102 | xiaobing |
| 100 | xiaohong |
但是其中id为100的这条数据从业务逻辑上来看应该是被过滤掉的,但是实际却出来了,也就是代码实际运行结果和我们预期想的不一样
其实和c语言开发和java 开发类似,就是预期结果和代码实际结果不一致,一般在java开发或者c语言开发中,我们是通过打日志(print、log.debug )或者使用idea打断点进调试模式进行调试代码,一步一步查看中间结果,也称之为debug过程。

那么因此想到sql 实际运行结果和预期不符的时候能不能进行debug 调试呢?
二、大部分人的解决方案:
大部分数据开发者遇到这个问题,都是把sql 进行拆分,比如说demo 1 的sql拆分如下4个sql,分别对每个sql 进行运行判断100这个结果到底是哪个表产出的。
select id,name from table1 where id='100'
select id,name from table2 where id='100'
select id,name from table3 where id='100'
select id,name from table4 where id='100'或者稍微修改一下
select * from (
select id,name,flag from (
select id,name,'1' as flag from table1
union all
select id,name,'2' as flag from table2
union all
select id,name,'3' as flag from table3
union all
select id,name,'4' as flag from table4
)t group by id,name,flag )t1 where id='100'
三、最终方案:
那有没有一种方法,也能做到像和java或者c语言一样进行调试中间结果呢,也就是idea debug或者通过打印日志的方式?因此称呼sql 调试的过程为sql debug。
java 或者c 语言 开启debug 模式,需要打印日志或者配合idea 进行debug,本文先讲述怎么通过打印日志进行sql debug。
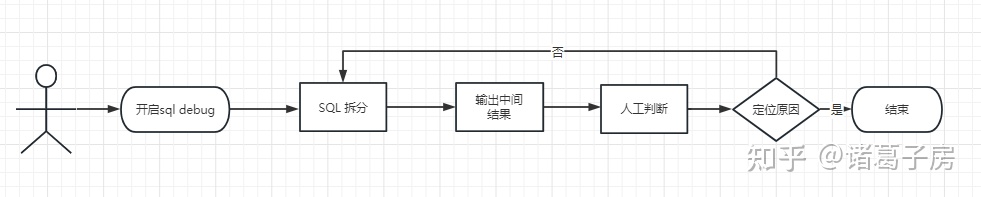
(1)开启debug 模式
(2)拆分sql
(3)输出中间结果
(4)人工判断中间结果是否正确定位原因
(5)重复2-4过程直到找到最终结果结束
举例:
select u,
max(tm),
p1
from
(
select device_id as u,unix_timestamp(dt,'yyyy-MM-dd')*1000 as tm,p1
from test.table1
where dt='2023-04-09' and length(trim(device_id))>0
union ALL
select device_id as u,unix_timestamp(dt,'yyyy-MM-dd')*1000 as tm,p1
from test.table2
where dt='2023-04-09' and length(trim(device_id))>0
union all
select device_id as u,unix_timestamp(dt,'yyyy-MM-dd')*1000 as tm,p1
from test.table3
where dt='2023-04-09' and length(trim(device_id))>0
) a
GROUP BY u,
p1(1)将这样一段sql 进行转换成语法树(如下图),这样就完成了sql解析和拆分(实际上更复杂的sql 也可进行快速拆分)
(2)将拆分出来的sql进行批量建表
(3)实际分析问题的时候,可以直接查询建的中间表数据
(4)分析完成之后需要自动删除建的中间表数据
GitHub - zhugezifang/sql-debug
大数据 SQL Boy 脱坑指南
不可否认的是 SQL 是一个伟大的发明,它让增删改查的操作更加地便捷化,而且 SQL 的学习成本相对其他编程语言来说较低,被逼到会写 SQL 的运营和产品我都见过不少。。。

大数据行业跟 SQL 更是有不解之缘,可谓“万物皆可 SQL 化”,从Hive/SparkSQL等最原始的最普及的 SQL 查询引擎,到 Impala/Presto/ClickHouse/Kylin/Phoenix 等等 OLAP 引擎,再到流式的 Structured Streaming/Flink SQL/Kafka SQL,可见想彻底摆脱 SQL 是不可能的了,相比各式各样的接口,复杂的规则,SQL 化成了一个简单化的标志,因为默认IT界人人都会 SQL,那就约等于人人都会使用这些复杂的工具,多美好。我想强调的是 SQL 是大数据从业者的必备工作技能,但是工作必须不能全是 SQL 。
1. 自动化
专职 SQL Boy 其实就像是在工厂里工作的流水线工人,需求来了,噼里啪啦一顿操作把SQL跑起来,把结果再丢给下游,再来个需求,再噼里啪啦。。。如此循环往复。不知道大家有没有感同身受,如果有的话我就问一句:工厂都知道要自动化,为什么你还不明白呢?
取数需求是永无止境的且无趣的,而且很多都是重复的,运营产品等需求方大佬们有时候要看这个产品今天的数据,就风风火火来了个紧急需求,看完之后发现哦不对,今天还没过完嘛,应该要看昨天的才对......
我:“&#@%!!”。
比这个还弱智的翻工原因估计还有很多,难道就这样任由大佬们蹂躏吗?你有没有想过这种需求其实是可以抽象的,SQL 语句写来写去就那么几个词,做这种需求就相当于是把自然语言人工翻译成SQL语言,那么这个翻译的过程是不是能够让代码来代替呢。
简单地给个建议,搞一套 OLAP 引擎,配合一个拖拽式的前端页面,就可以丢给运营们去慢慢玩了。三言两语说得很轻松,但是这其中的工作量是很大的,你需要花很多的时间在数仓的建设上,在平台的选型/搭建/测试/运维上,在接口开发/调试/对接上,最后因为自助分析不能够覆盖所有的需求,所有整个流程需要不停地优化和迭代,当然那些那些需要写几百行SQL才能解决的需求,可能还得你再想想办法。
在建设这一套自助分析系统过程中,你不可避免地会接触到更多的东西,元数据管理,数据治理,数据建模,Hadoop运维等等等等,恭喜你此刻你成功脱了SQL Boy的坑了,你需要把时间更多地花在上面说的那些事情中,虽然有点不道德但是你可以把 SQL Boy 这个荣誉称号让给新来的同事,可以把成百上千行的祖传 SQL 传递给他们了。
2. 数据驱动
这个时候应该有人会想说“老子就是那个接了祖传 SQL 的人”。。。别急,接着往下看。
如果你的 SQL 真的有成百上千行,那你应该要考虑你的数据仓库建设的合理性了,如果你也刚好是个数据仓库工程师,那应该是避免不了写 SQL 的了,但是我的理解是这里的 SQL 并不是上面提到的取数需求这种无趣无意义的 SQL,数仓的建设更多需要的是业务层面的理解,需要考虑更多的是如何能把数据的价值体现出来,很多业务方的需求其实是拍脑袋想出来的,要知道你是离数据最近的人,你也应当是对数据最熟悉的人,你应该是最能判断数据如何展示是有意义的,以及如何让自己的数据去发挥出最大的价值。
“数据驱动”是我很喜欢的一个词,如果能真正地做到数据驱动业务,那你写的SQL没白写,你是个SQL King,但真正能做到这样的人是少之又少,这其实是技术与业务的一个结合,这个方向上不仅仅对技术有要求,更重要的是需要培养对业务的理解能力。
3. 数据挖掘
其实很多的大数据开发,大数据分析,都是想往数据挖掘的方向发展的,但很多人都觉得门槛太高,被自己吓住了,不敢迈出尝试的第一步,虽然说数据挖掘入门会有一点门槛,但是其实并没有大家想象得那么难,高等数据,概率论,这些课程大家在大学应该都学过,大部分忘了没事,基本的概念记得即可,但是重点是你得耐得住漫长学习过程的寂寞。
另外,算法的工程落地是需要做很多开发类工作的,数据准备,接口开发等等,据我所知很多公司这些活都还是由数据挖掘的人来做的,所以也许数据挖掘师在算法上很强,但是你在工程上是有优势的,前两天看了木东居士老师的一篇文章,印象最深刻的一句话是“错位竞争”,转行做数据挖掘的想在学术上和别人硬碰硬是很难的,但是你有你的长处,你要把它发挥出来。
4. 结语
脱坑的方式其实有很多种,但是重点还是要看个人的自驱力,自己是不是真的在推动自己去脱坑了,还是只是停留在口头的抱怨。
另外,之前有几个童鞋问过我有没有数据挖掘入门的视频课程,不知道还有没有需要的童鞋,有的话就关注下公众号【大叔据】呗,人数的多话我去帮大家找找,找个高质量的过几天发出来。
觉得有价值请关注 :公众号「大叔据」

以上是关于大数据=SQL Boy,SQL Debug打破SQL Boy 的僵局的主要内容,如果未能解决你的问题,请参考以下文章