RFM模型学习
Posted 21座的胖子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RFM模型学习相关的知识,希望对你有一定的参考价值。
RFM模型
R:最近一次消费 (Recency)
F:消费频率 (Frequency)
M:消费金额 (Monetary)
简单的理解就是针对客户不同的RFM值进行不同的营销策略。
整个过程分为几个步骤:
数据提取→用户RFM打分→根据打分给用户分类→针对不同的分类提供不同的营销方案
针对业务主要有两个难点,分别在第二个步骤和第四个步骤。
用户RFM打分,需要对业务理解深刻,对R值,F值和M值分区间打分,区间的划分需要针对不同业务去指定不同的指标。
提供营销方案,需要针对业务和实际策略有了解,才能针对性地产出。
具体代码实现:
import pandas as pd
import numpy as np
data = pd.read_excel("rfm.xlsx",dtype="a":np.int32,"b":str)
# print("判断数据是否有缺失值:",data.info())
# print("每个字段中是否含有空值:\\n",data.isna().any())
# 把支付时间字段的类型变成时间类型
data["paytime"] = pd.to_datetime(data["paytime"])
# print(data.dtypes)
# 通过dt属性返回对象中可以获得datetime中的年与日等数据
data["paytime-year"] = data["paytime"].dt.year
data["paytime-month"] = data["paytime"].dt.month
data["paytime-quarter"] = data["paytime"].dt.to_period("Q")
result = data[["paytime","paytime-year","paytime-month","paytime-quarter"]].head()
# 1、获取所需要的数据
# 获取2020年的数据
data_2020 = data[data["paytime-year"]==2020]
# 获取RFM模型所需的三列数据:用户uid、支付时间、金额
data_2020 = data_2020[["uid","paytime","amount"]]
data_2020["amount"] = data_2020["amount"].astype(int)
# 2、将数据uid分组
def order_sort(group):
return group.sort_values(by="paytime")[-1:]
data_2020_group = data_2020.groupby(by="uid",as_index=False)
data_2020_maxtime = data_2020_group.apply(order_sort)
# 3、为数据添加R(最近一次交易时间的间隔)、F(购买次数)、M(销售额总数)值
# 确定统计日期
end_data= pd.to_datetime("2020-12-31")
# 计算最近一次交易时间的间隔
r_data = end_data - data_2020_maxtime["paytime"]
# 为数据添加R值
data_2020_maxtime["R"] = r_data.values
# 为数据添加F值
data_2020_maxtime["F"] = data_2020_group.size()["size"].values
# 为数据添加M值
data_2020_maxtime["M"] = data_2020_group.sum()["amount"].values
# 4、根据RFM三列设置相应的分值
# 设置R维度的评分,基于业务特性设置参数
import datetime
section_list_R = [datetime.timedelta(days=i) for i in [-1,15,75,180,270,365]]
grade_R = pd.cut(data_2020_maxtime["R"],bins=section_list_R,labels=[5,4,3,2,1])
# 添加R_S评分列
data_2020_maxtime["R_S"]=grade_R.values
# 设置F维度的评分,基于业务特性设置参数
section_list_F = [0,1,3,5,10,15]
grade_F= pd.cut(data_2020_maxtime["F"],bins=section_list_F,labels=[1,2,3,4,5])
# 添加F_S评分列
data_2020_maxtime["F_S"]=grade_F.values
# 设置M维度的评分,基于业务特性设置参数
section_list_M = [1000,1500,15000,50000,150000,300000]
grade_M = pd.cut(data_2020_maxtime["M"],bins=section_list_M,labels=[1,2,3,4,5])
# 添加M_S评分列
data_2020_maxtime["M_S"]=grade_M.values
# 5、计算出每一个维度的平均分,用对应的分数与平均分进行对比,大于平均分的值标为1,小于平均分的值标成0
# 设置R维度的高低值
data_2020_maxtime["R_S"] = data_2020_maxtime["R_S"].values.astype(int)
# 根据平均分设置判断高低
grade_R_avg = data_2020_maxtime["R_S"].values.sum()/data_2020_maxtime["R_S"].count()
# 将高对应为1 ,低的对应为0
print(grade_R_avg)
data_R_S = data_2020_maxtime["R_S"].where(data_2020_maxtime["R_S"]<grade_R_avg,1)
data_2020_maxtime["R_high_low"] = data_R_S.where(data_2020_maxtime["R_S"]>grade_R_avg,0).values
# 设置F维度的高低值
data_2020_maxtime["F_S"] = data_2020_maxtime["F_S"].values.astype(int)
# 根据平均分设置判断高低
grade_F_avg = data_2020_maxtime["F_S"].values.sum()/data_2020_maxtime["F_S"].count()
print(grade_F_avg)
# 将高对应为1 ,低的对应为0
data_F_S = data_2020_maxtime["F_S"].where(data_2020_maxtime["F_S"]>grade_F_avg,0)
data_2020_maxtime["F_high_low"] = data_F_S.where(data_2020_maxtime["F_S"]<grade_F_avg,1).values
# 设置M维度的高低值
data_2020_maxtime["M_S"] = data_2020_maxtime["M_S"].values.astype(int)
# 根据平均分设置判断高低
grade_M_avg = data_2020_maxtime["M_S"].values.sum()/data_2020_maxtime["M_S"].count()
print(grade_M_avg)
# 将高对应为1 ,低的对应为0
data_M_S = data_2020_maxtime["M_S"].where(data_2020_maxtime["M_S"]>grade_M_avg,0)
data_2020_maxtime["M_high_low"] = data_M_S.where(data_2020_maxtime["M_S"]<grade_M_avg,1).values
# 6、对每个用户进行类型标记
data_rfm = data_2020_maxtime[["uid","R_high_low","F_high_low","M_high_low"]]
# data_rfm = data_2020_maxtime
def get_sum_values(series):
return"".join([str(i) for i in series.values.tolist()[1:]])
# 添加RFM字符串列
data_rfm["data_rfm"]= data_rfm.apply(get_sum_values,axis=1)
dic=
"111":"重要价值客户",
"011":"重要保持客户",
"101":"重要发展客户",
"001":"重要挽留客户",
"110":"一般价值客户",
"010":"一般保持客户",
"100":"一般发展客户",
"000":"一般挽留客户",
# RFM字符串数据映射成对应类型文字
data_rfm["data_rfm"]=data_rfm["data_rfm"].map(dic)
data_2020_maxtime["data_rfm"] =data_rfm["data_rfm"]
data_2020_maxtime.to_excel("RFM_Result_New.xlsx")
运行结果:
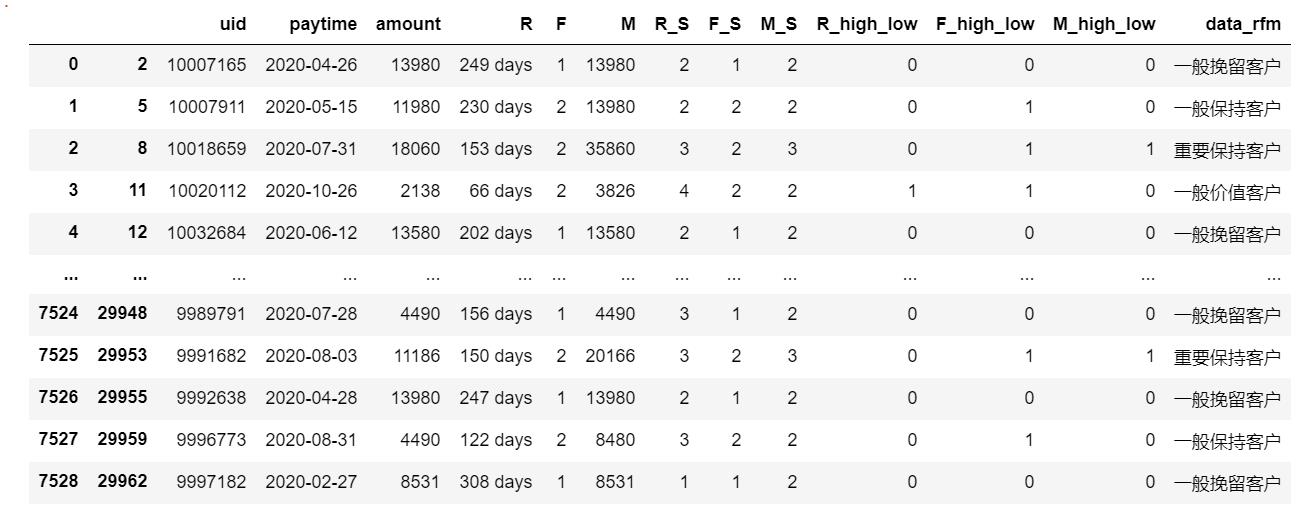
至此分类完成,可以针对不同的客户属性提供不同的业务。
以上是关于RFM模型学习的主要内容,如果未能解决你的问题,请参考以下文章