Redis学习笔记28——Pika:如何基于SSD实现大容量Redis
Posted qq_34132502
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis学习笔记28——Pika:如何基于SSD实现大容量Redis相关的知识,希望对你有一定的参考价值。
着业务数据的增加,就需要 Redis 能保存更多的数据。你可能会想到使用 Redis 切片集群,把数据分散保存到多个实例上。但是这样做的话,会有一个问题,如果要保存的数据总量很大,但是每个实例保存的数据量较小的话,就会导致集群的实例规模增加,这会让集群的运维管理变得复杂,增加开销。如果增加单个实例的内存容量,但是在实例恢复,主从同步过程中会引起恢复时间增长、主从切换开销大、缓冲区容易溢出。
可以使用基于SSD来实现大容量的Redis实例,即Pika键值数据库。
Pika有两个特点:
- 单实例可以保存大容量数据,同时避免了实例恢复和主从同步时的潜在问题;
- 和 Redis 数据类型保持兼容,可以支持使用 Redis 的应用平滑地迁移到 Pika 上
使用大内存Redis实例的潜在问题
- 内存快照 RDB 生成慢
- 恢复效率低
- 主从节点全量同步时长增加
- 复制缓冲区容易溢出
RBD生成慢
内存大小和内存快照 RDB 的关系是非常直接的:实例内存容量大,RDB 文件也会相应增大,那么,RDB 文件生成时的 fork 时长就会增加,这就会导致 Redis 实例阻塞。
恢复效率低
RDB 文件增大后,使用 RDB 进行恢复的时长也会增加,会导致 Redis 较长时间无法对外提供服务。
主从节点全量同步时长增加
主从节点间的同步的第一步就是要做全量同步。全量同步是主节点生成 RDB 文件,并传给从节点,从节点再进行加载。试想一下,如果 RDB 文件很大,肯定会导致全量同步的时长增加,效率不高
复制缓冲区容易溢出
一旦缓冲区溢出了,主从节点间就会又开始全量同步,影响业务应用的正常使用。如果我们增加复制缓冲区的容量,这又会消耗宝贵的内存资源。
Pika
整体架构
Pika 键值数据库的整体架构中包括了五部分,分别是网络框架、Pika 线程模块、Nemo 存储模块、RocksDB 和 binlog 机制
网络架构
网络框架主要负责底层网络请求的接收和发送。
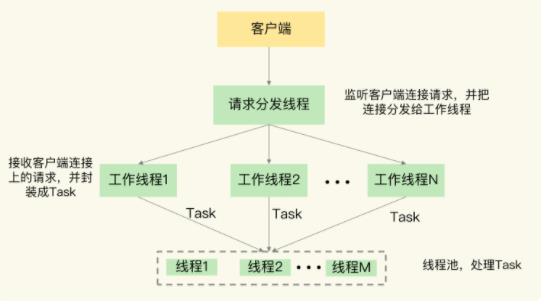
其次,Pika 线程模块采用了多线程模型来具体处理客户端请求,包括一个请求分发线程(DispatchThread)、一组工作线程(WorkerThread)以及一个线程池(ThreadPool)。
请求分发线程专门监听网络端口,一旦接收到客户端的连接请求后,就和客户端建立连接,并把连接交由工作线程处理。工作线程负责接收客户端连接上发送的具体命令请求,并把命令请求封装成 Task,再交给线程池中的线程,由这些线程进行实际的数据存取处理
Pika 如何基于 SSD 保存更多数据
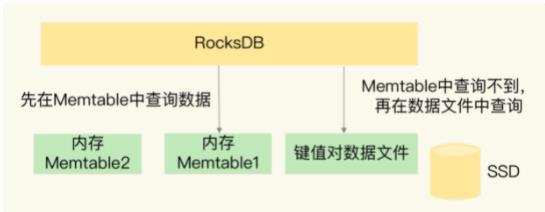
当 Pika 需要保存数据时,RocksDB 会使用两小块内存空间(Memtable1 和 Memtable2)来交替缓存写入的数据。Memtable 的大小可以设置,一个 Memtable 的大小一般为几 MB 或几十 MB。当有数据要写入 RocksDB 时,RocksDB 会先把数据写入到 Memtable1。等到 Memtable1 写满后,RocksDB 再把数据以文件的形式,快速写入底层的 SSD。同时,RocksDB 会使用 Memtable2 来代替 Memtable1,缓存新写入的数据。等到 Memtable1 的数据都写入 SSD 了,RocksDB 会在 Memtable2 写满后,再用 Memtable1 缓存新写入的数据。

当 Pika 需要读取数据的时候,RocksDB 会先在 Memtable 中查询是否有要读取的数据。这是因为,最新的数据都是先写入到 Memtable 中的。如果 Memtable 中没有要读取的数据,RocksDB 会再查询保存在 SSD 上的数据文件
会面临Redis保存大量数据时相同的问题么
其实不会
一方面,Pika 基于 RocksDB 保存了数据文件,直接读取数据文件就能恢复,不需要再通过内存快照进行恢复了。而且,Pika 从库在进行全量同步时,可以直接从主库拷贝数据文件,不需要使用内存快照,这样一来,Pika 就避免了大内存快照生成效率低的问题。
另一方面,Pika 使用了 binlog 机制实现增量命令同步,既节省了内存,还避免了缓冲区溢出的问题。binlog 是保存在 SSD 上的文件,Pika 接收到写命令后,在把数据写入 Memtable 时,也会把命令操作写到 binlog 文件中。和 Redis 类似,当全量同步结束后,从库会从 binlog 中把尚未同步的命令读取过来,这样就可以和主库的数据保持一致。当进行增量同步时,从库也是把自己已经复制的偏移量发给主库,主库把尚未同步的命令发给从库,来保持主从库的数据一致。
Pika 如何实现 Redis 数据类型兼容
Pika 的底层存储使用了 RocksDB 来保存数据,但是,RocksDB 只提供了单值的键值对类型,RocksDB 键值对中的值就是单个值,而 Redis 键值对中的值还可以是集合类型。
为了保持和 Redis 的兼容性,Pika 的 Nemo 模块就负责把 Redis 的集合类型转换成单值的键值对。简单来说,我们可以把 Redis 的集合类型分成两类:
- 一类是 List 和 Set 类型,它们的集合中也只有单值;
- 另一类是 Hash 和 Sorted Set 类型,它们的集合中的元素是成对的,其中,Hash 集合元素是 field-value 类型,而 Sorted Set 集合元素是 member-score 类型。
Nemo 模块通过转换操作,把这 4 种集合类型的元素表示为单值的键值对。
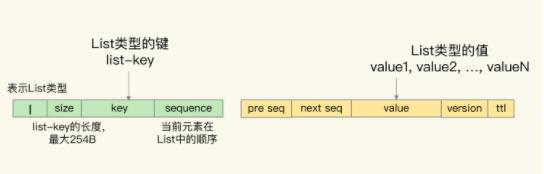
- List:key作为键,value作为值。又因为其是有序的,同时在value加上了
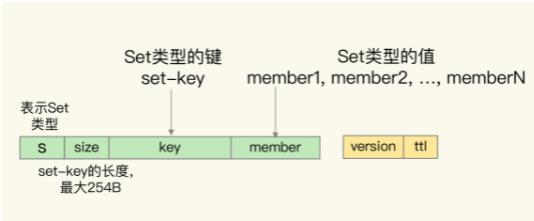
previous sequence和next sequence字段,分别表示前一个元素和后一个元素。在可以之前加上l表示List类型 - Set:在key前加上
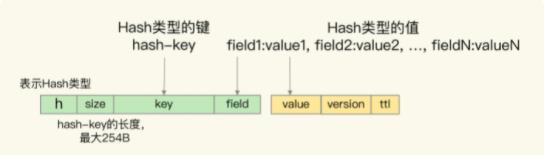
s表示Set类型。key和member分别表示键和值 - Hash:Hash 集合的 key 被嵌入到单值键值对的键当中,用 key 字段表示,而 Hash 集合元素的 field 也被嵌入到单值键值对的键当中,紧接着 key 字段,用 field 字段表示。Hash 集合元素的 value 则是嵌入到单值键值对的值当中,并且也带有版本信息和剩余存活时间
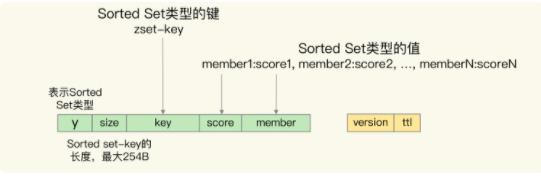
- 对于 Sorted Set 类型来说,该类型是需要能够按照集合元素的 score 值排序的,而 RocksDB 只支持按照单值键值对的键来排序。所以,Nemo 模块在转换数据时,就把 Sorted Set 集合 key、元素的 score 和 member 值都嵌入到了单值键值对的键当中,此时,单值键值对中的值只保存了数据的版本信息和剩余存活时间
Pika的优势和不足
首先,实例重启快。Pika 的数据在写入数据库时,是会保存到 SSD 上的。当 Pika 实例重启时,可以直接从 SSD 上的数据文件中读取数据,不需要像 Redis 一样,从 RDB 文件全部重新加载数据或是从 AOF 文件中全部回放操作,这极大地提高了 Pika 实例的重启速度,可以快速处理业务应用请求。
另外,主从库重新执行全量同步的风险低。Pika 通过 binlog 机制实现写命令的增量同步,不再受内存缓冲区大小的限制,所以,即使在数据量很大导致主从库同步耗时很长的情况下,Pika 也不用担心缓冲区溢出而触发的主从库重新全量同步。
但是性能和Redis比有所下降,而且SSD使用寿命和擦写次数相关,如果遇到访问量特别大的情况,SSD使用时间不会太长。
以上是关于Redis学习笔记28——Pika:如何基于SSD实现大容量Redis的主要内容,如果未能解决你的问题,请参考以下文章