对线面试官:数据存储连环问
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对线面试官:数据存储连环问相关的知识,希望对你有一定的参考价值。
👇👇关注后回复 “进群” ,拉你进程序员交流群👇👇
作者丨idea
来源丨Java知音(ID:Java_friends)
如何理解存储引擎?
存储引擎是一款存储系统的核心,它能提供数据的crud操作,同时直接决定了存储系统的功能和性能。对于存储而言,影响存储的性能主要有两点,读速度和写速度。
通常来说顺序写入和顺序读取的效率要比随机读写的效率更高,即使如今大家都在使用ssd固态硬盘作为存储系统的底层,但是这条规律依然是可行的。
为什么顺序读写要比随机读写效率高?
首先我们要知道磁盘的组成是由一个个的盘面合成的,每隔盘面上有无数的盘道,而数据则是被记录在盘道中。每当我们需啊哟写入或者读取数据的时候,就需要发送一个信号给鸡计算机的磁头,让它去定位对应的位置,所以如果我们读和写的地址都是连续的话,这个磁头只需要定位到具体的盘道上,接下来按照 顺/逆时针 方向去旋转运作即可获得数据。同理,如果不是有序读写的话,可能会因此磁头在多个盘道上的切换,从而影响了整体效率。
常见的存储引擎类型有哪些?
hash存储引擎
这类存储引擎的特点我们可以归纳为是点查询,主要原理是根据key进行hash计算,然后定位到
具体的地址,接着根据实际存储的value大小去加载数据到内存中。其原理结构如下图所示:
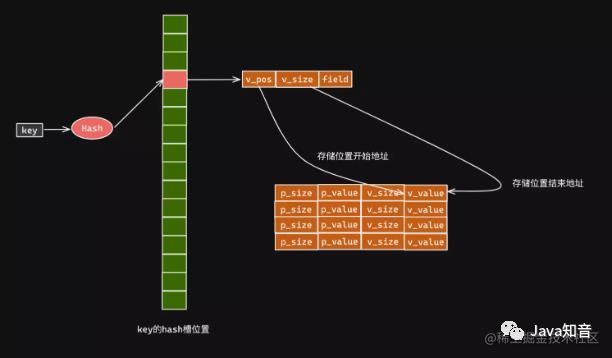
通常使用这类这类存储引擎的数据库,在单个元素的查询方面的性能是极佳的,时间复杂度O(1) , 例如一些简单的等于查询,和数量较少的in查询都是可以很快解决。
但是不太适合不适合使用范围性的查询,需要通过全表扫描才能实现范围查询,而且这类数据库也不太适合用在一些排序的场景中。
使用这类存储引擎的数据库代表有Redis,Memcached。
其实这两款高速缓存在设计上都有些类似,但是目前比较受欢迎的还是以Redis为主,所以下边我们介绍下Redis在数据存储方面是如何设计的。
Redis底层是如何对数据存储进行管理的
其实如果要了解Redis底层的数据存储,我们重点要关注下Redis底层的存储源代码设计。下边是Redis底层在数据存储上主要使用的几个代表类:
redisDB
dict
dictht
dictEntry
关于它们的源代码,我们重点看这几个:
这里我用一张图来表示他们之间的关系,好方便大家理解: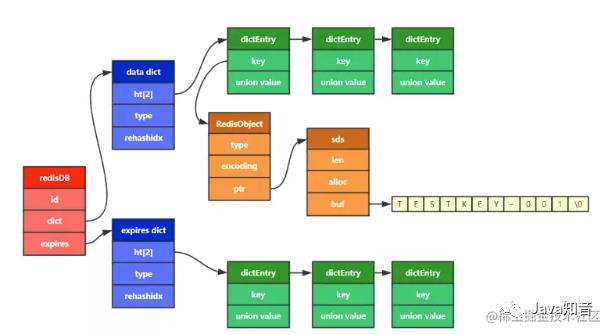
这里你会看到dict中包含了两个dictht数组,dictht ht[2] 你可以理解为是存储redis的key,value数据的2个数组,之所以要设计2个数组的存在是为了后续做rehash所使用。
Redis的rehash是什么
当hash列表中的某一个槽位上出现了hash冲突的时候,这时候redis会默认采用链表的方式去解决这种冲突问题。当有多个key都落在同一个槽位上的时候,会在同一个槽位上执行尾插法,这种处理方式就会导致今后可能redis的某一个槽位上存储了异常多的元素,增大了查询数据的时间复杂度。为了解决这种问题,redis会对哈希表执行rehash操作。
rehash的原理主要是通过增加槽位的数目,让元素分散在更多不同的槽点从而缩短相应链表都长度,降低查询的时间损耗。
而上边的这段dict源代码中,你会发现dictht ht[2]; 表示了两个数组,这两个数组就是为了处理rehahs的时候拷贝数据使用的。
倘若直接将redis的所有key都从一个数组直接拷贝到另外一个数组中处理的话,这样可能会对内存造成过大的压力。所以redis使用了渐进式rehash的设计方式来处理这种情况。
每次有请求过来的时候,会按照hash数组索引从小到大的顺序,依次执行数据拷贝迁移的操作。过程如下图所示:
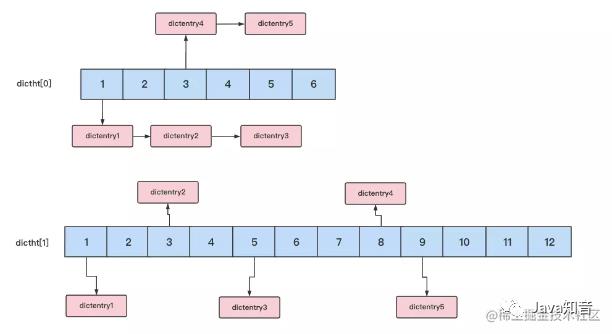
假设客户端发送了一次get指令,那么redis会先对1号键进行rehash操作,接着每次来一个请求就进行一次拷贝,从而将整个rehash的过程分散到了各次查询中进行处理。倘若没有redis没有收到请求,则会有个定时调度在后台定期进行hash列表中每个元素项的拷贝工作。最终当拷贝完成后,新的请求直接访问新的hashtable即可,同时将老的hashtable进行回收。
采用B+树存储引擎
在平时工作中这类设计可能是大家最常遇见的存储引擎了。这类存储引擎的代表就是mysql,下边我们重点以MySQL的B+数结构来介绍。
B+数其主要设计为通过一个Root节点去联系到一颗树的所有,另外还有一个Data节点去联系到所有的叶子节点,最后各个叶子节点之间通过双向链表互相联系到一起,具体如下图所示:
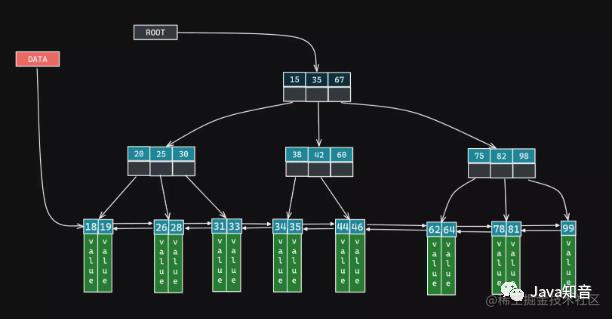
由于底层的叶子节点之间可以通过双向链表去访问,所以如果我们希望实现一些范围性查询的功能,利用MySQL是非常好的一种途径。
大多数情况下,根节点是存在于内存的,而第二层第三层的节点数据未必会在内存中,所以当我们发起一次查询的时候,最多需要n-1次磁盘io。这是因为当涉及到查询不存在内存中的节点时候,需要将节点的数据从磁盘中,以一个个page的单位加载到内存中进行查询计算。
使用B+树会存在哪些缺点
假设存储的某行数据中,某个字段占用的体积变大了,那么可能会导致节点中可存储的记录个数减少(因为每个节点的大小是固定的),如果少了的话,需要的叶子数会变多,层级也可能会增加。总而言之,行记录的体积过大,可能会导致这棵树的检索效率降低
由于B+树的最底层的叶子结点是按照一定顺序进行存储的,这也意味着,每次进行写入操作的时候,都会涉及到叶子结点内数据的挪动,又可能原先数据位于A节点,但是由于有了新的数据写入,该数据要被挪至B节点,这一现象我们一般称之为叶子结点的裂变。因此常规的MySQL在随机写方面的性能会有所欠缺。
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击👆卡片,关注后回复【面试题】即可获取
在看点这里 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于对线面试官:数据存储连环问的主要内容,如果未能解决你的问题,请参考以下文章