处理器 增强指令集
Posted 不会写代码的丝丽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了处理器 增强指令集相关的知识,希望对你有一定的参考价值。
浮点运算器(FPU)指令集
在原始的CPU指令集中并没有专门ALU用于浮点数的运算,只能用整数运算器去模拟浮点计算,效率极低。因此随着科技的发展推出了x87指令集用于浮点计算(遵守IEE754)。
x87指令集是x86的子集具体指令参阅 Floating-Point Unit (FPU) instructions set
为了支持浮点计算推出了st(0)-st(7) 八个寄存器,存储格式为IEE754。但是他们访问存储是通过类似循环栈结构方式。

本文将采用内联汇编的方式编写浮点指令
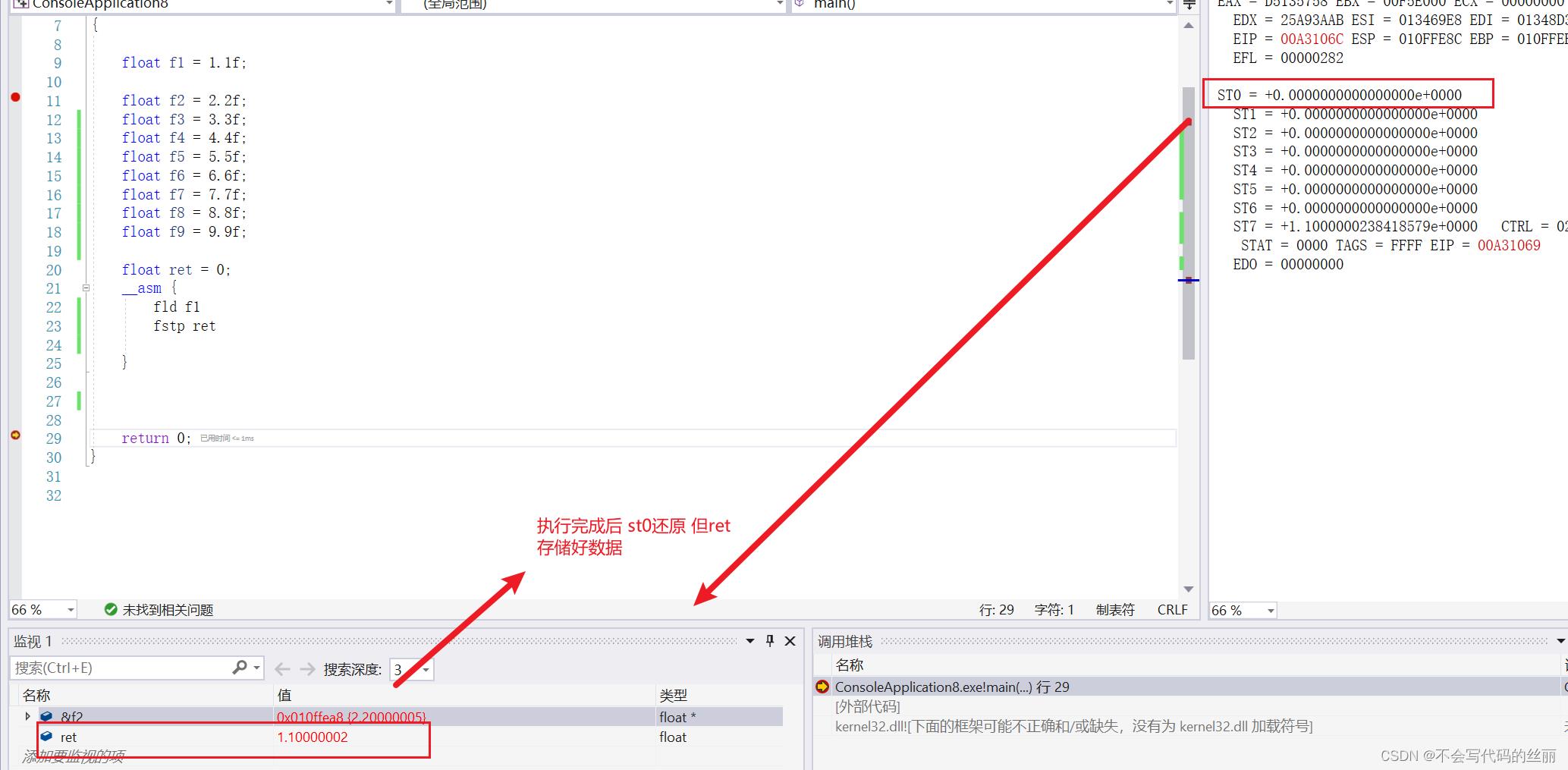
fld
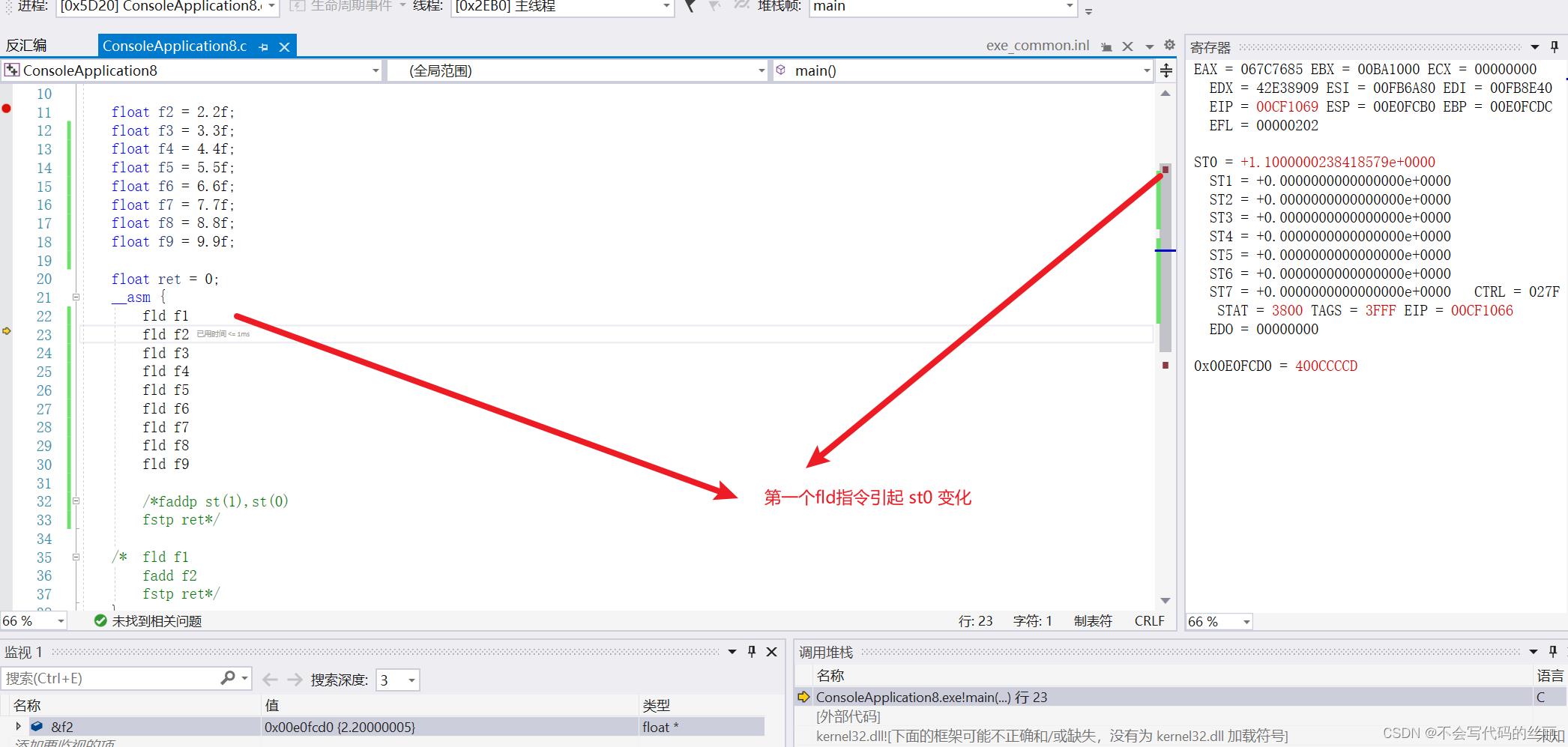
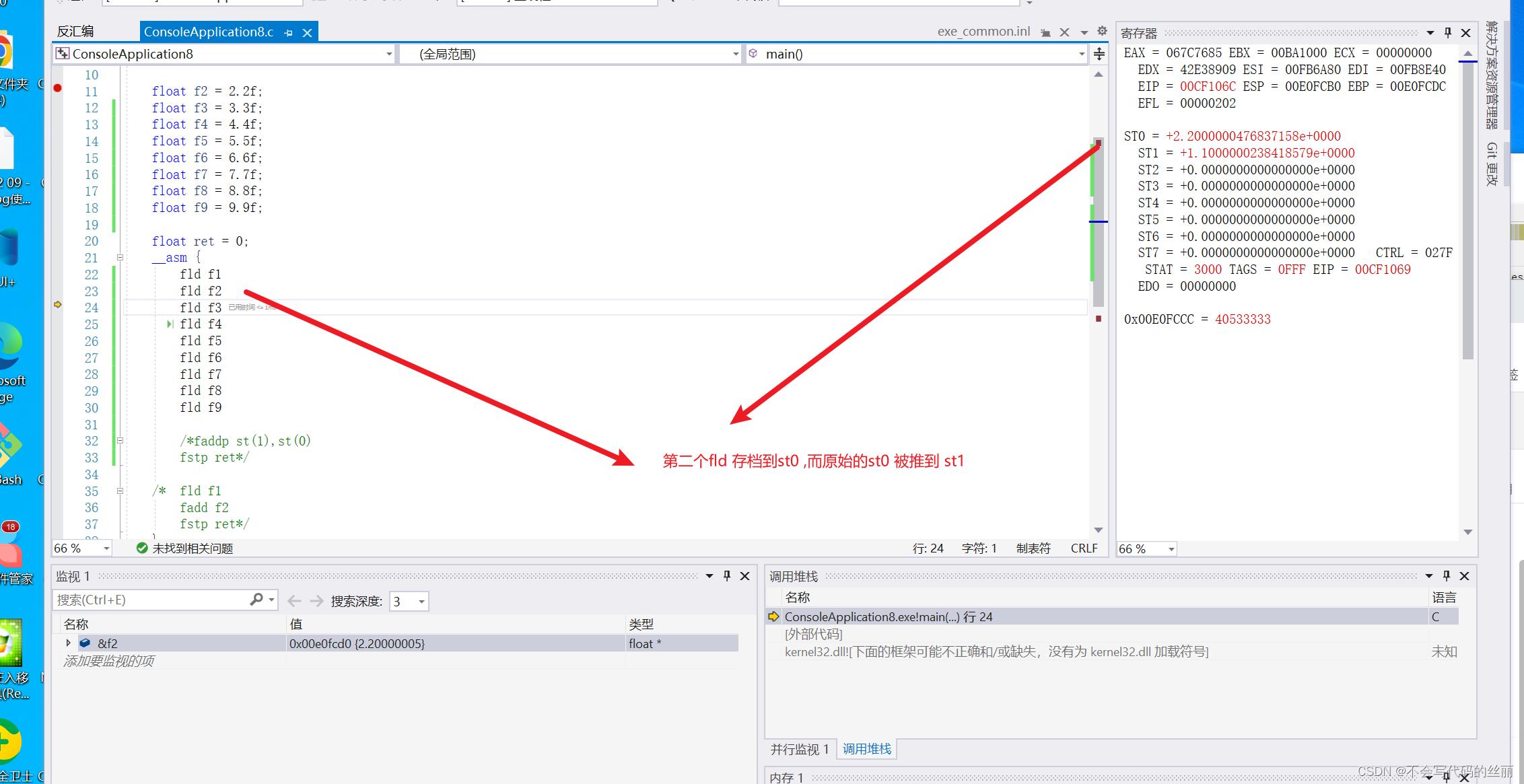
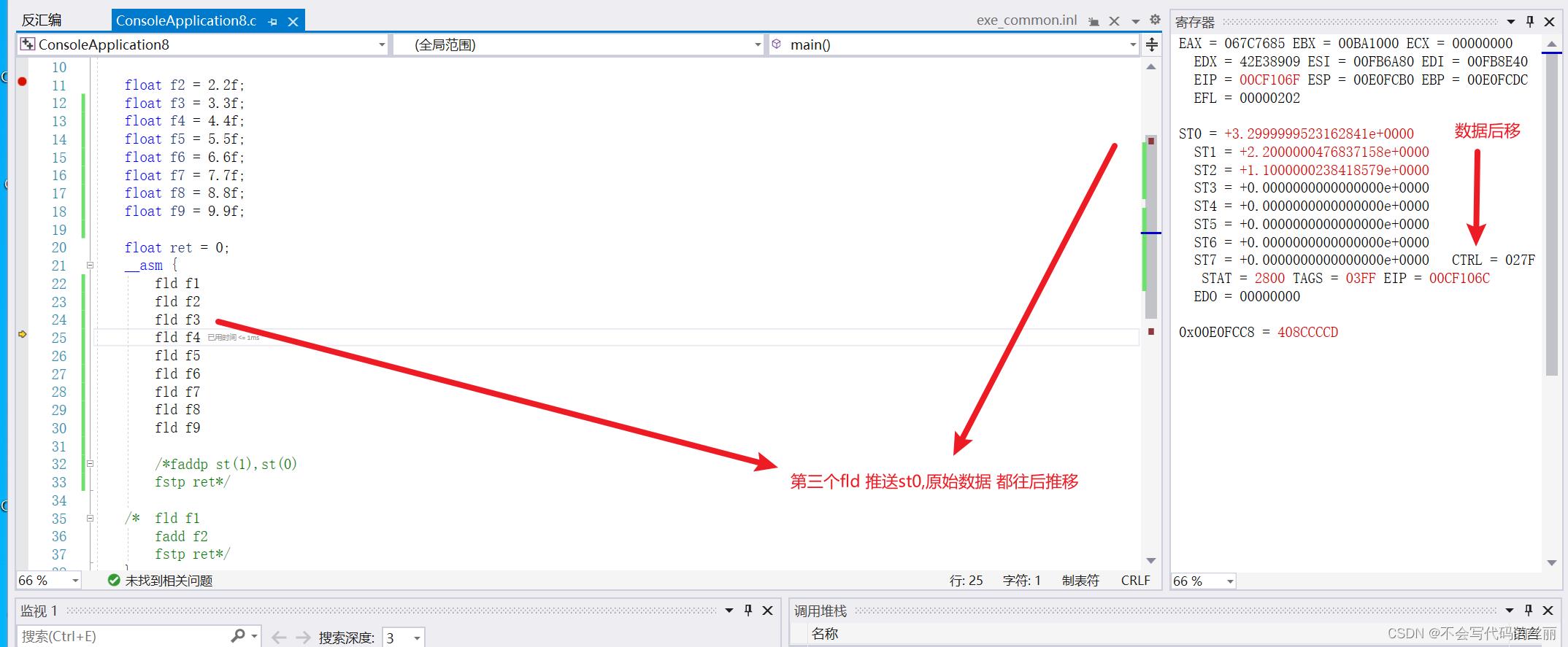
我们看一个例子去理解循环栈结构
fld: 用于加载一个数据到st(i)中,i数值取决于当前栈位置,当st存储完8个位置后会重新从st0覆盖
int main()
float f1 = 1.1f;
float f2 = 2.2f;
float f3 = 3.3f;
float f4 = 4.4f;
float f5 = 5.5f;
float f6 = 6.6f;
float f7 = 7.7f;
float f8 = 8.8f;
float f9 = 9.9f;
float ret = 0;
__asm
fld f1
fld f2
fld f3
fld f4
fld f5
fld f6
fld f7
fld f8
fld f9
return 0;


FST
存储一个浮点数到内存,但是不弹出st(0)

FSTP
存储一个浮点数到内存,弹出st(0)
常见逻辑运算
FADD
执行加法,但是不弹出st
参数其中一个操作数一定是st(0),另一个数可为32位内存数或者其他st.


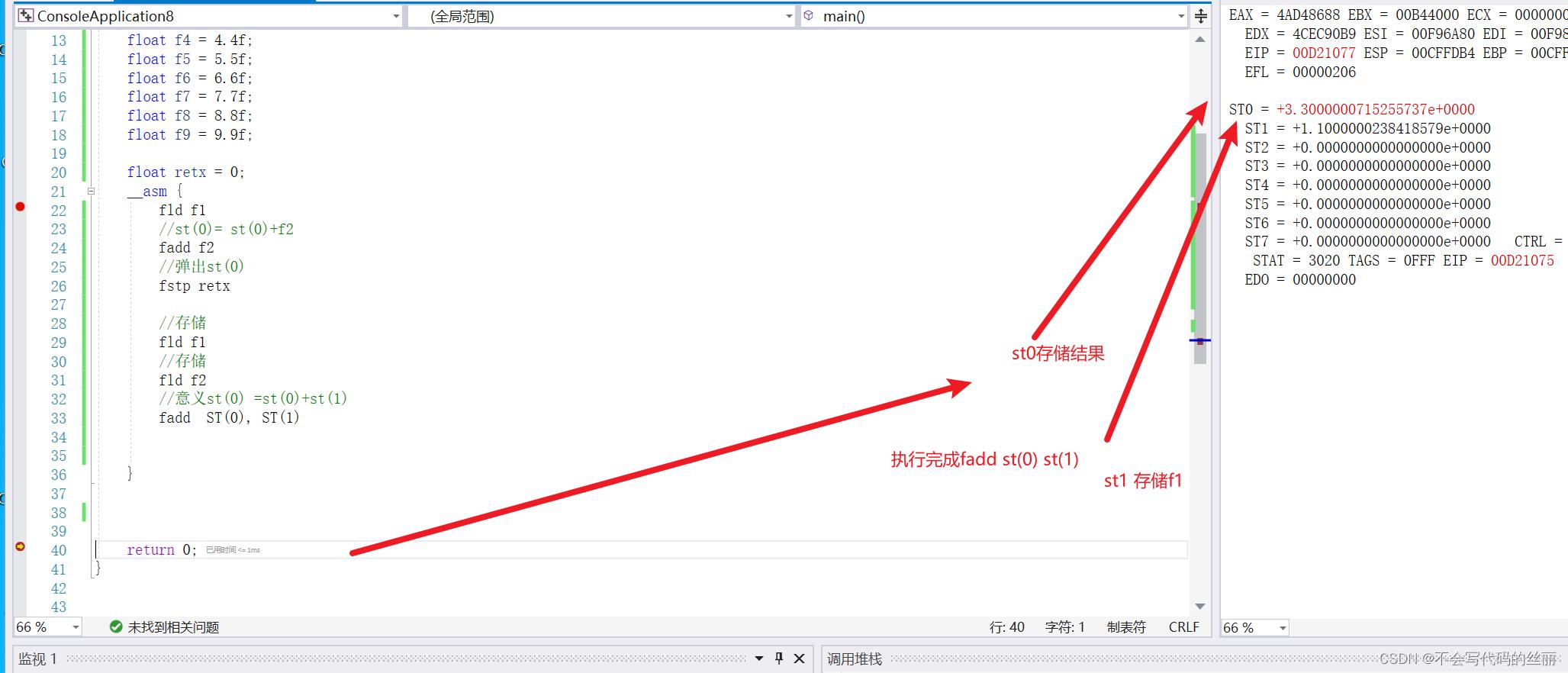
FADDP
和fadd差不多,只不过会弹出st
比较逻辑运算符
再浮点寄存器中有一个16位的状态寄存器如下图所示
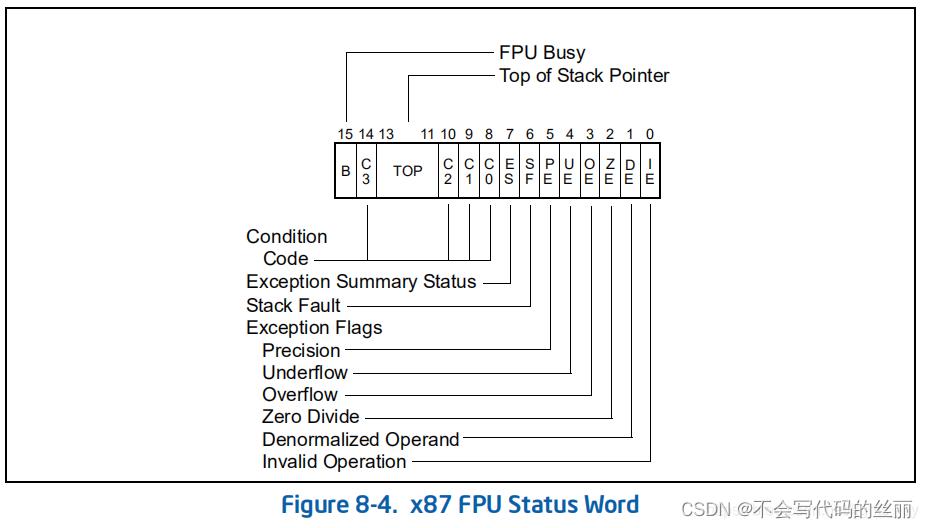
其中 第14, 10, 8用于做比较使用的状态标志位如下图所示
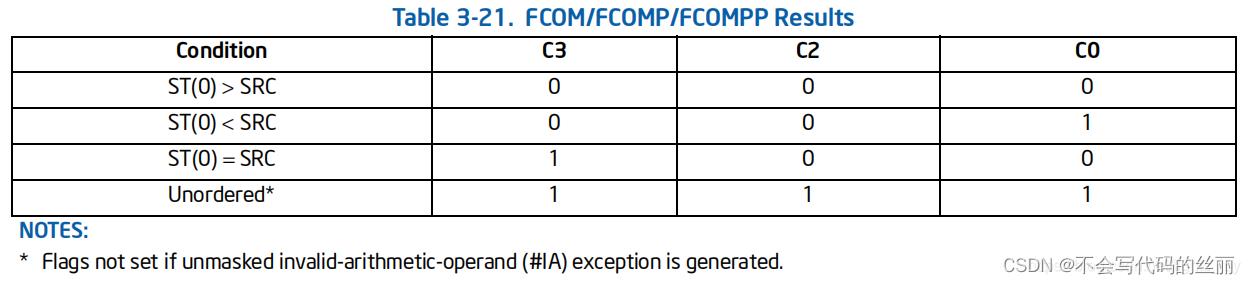
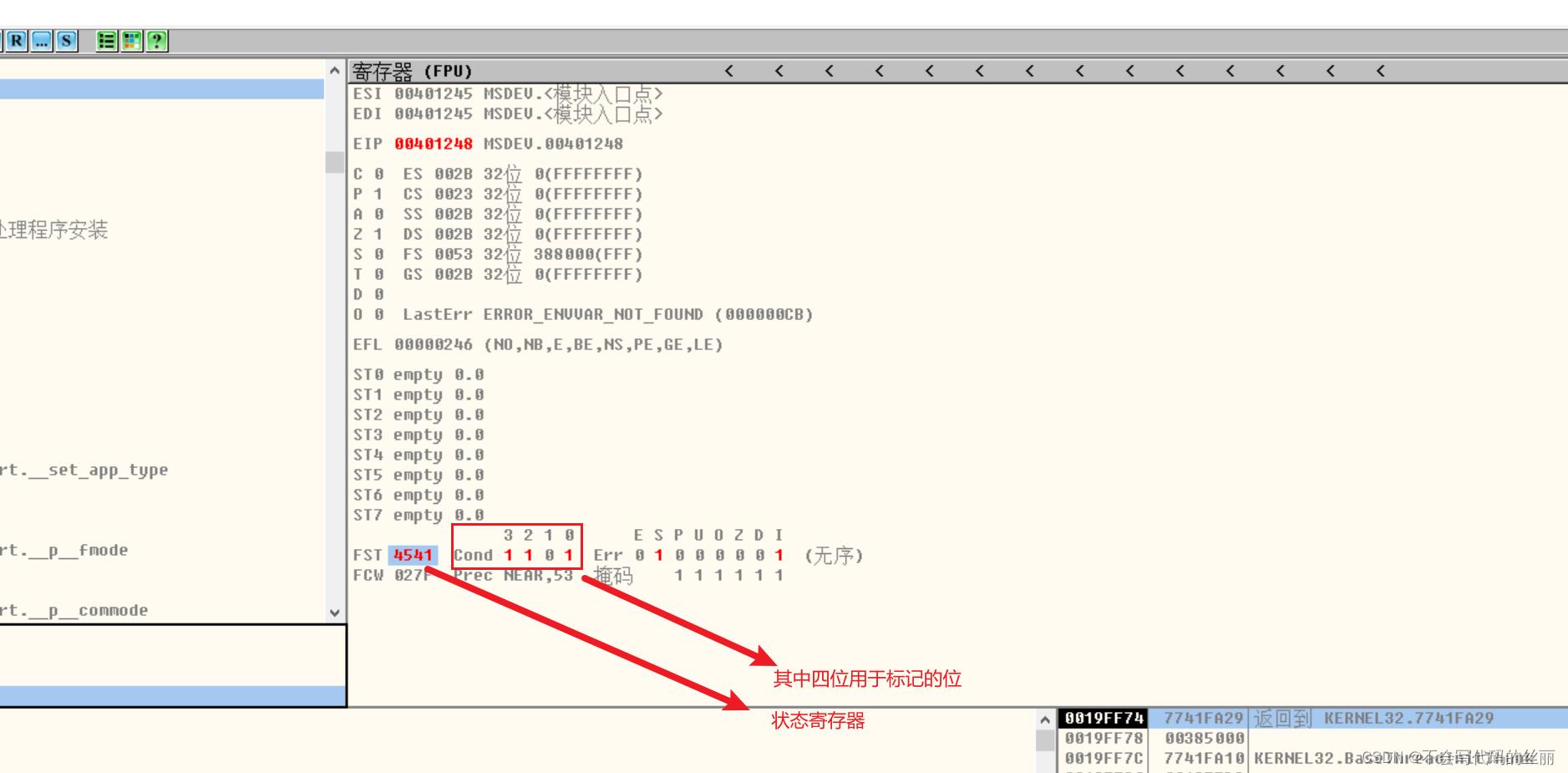
fcom
比较浮点数,但是只影响浮点标志寄存器不影响EFLAGS所以类似JE等指令无法使用
fcom 会影响 浮点状态寄存器 c0 c2 c3
fcomi
和fcom类似,但是会影响EFLAGS

一个DEMO
#include<stdio.h>
int main()
float f1 = 1.1f;
float f2 = 2.2f;
float f3 = 3.3f;
float f4 = 4.4f;
float f5 = 5.5f;
float f6 = 6.6f;
float f7 = 7.7f;
float f8 = 8.8f;
float f9 = 9.9f;
float retx = 0;
__asm
fld f1
fld f1
//比较st0 和st1,影响EFLAG标志
fcomi st(0),st(1)
//因为相等 所以跳转到jmpflag
je jmpflag
fld f8
fld f8
fld f8
fld f8
fld f8
jmpflag:
//存储
fld f9
fld f9
fld f9
fld f9
fld f9
return 0;
SIMD
单指令多数据 (single instruction ,multiple data) 是一组高效的指令集,可以在一个时间点计算多组数据,这对于矩阵和向量计算极为有用。
举个例子:

上面是一个再简单不过的矩阵计算。在正常情况也许我们取出每个矩阵行列相乘放入结果中。在原始指令集中也许我们一个个取出数据计算,但是如果我们有一个指令允许我们瞬间完成多个数据计算求和。这对于性能提升极大尤其在图像加解密方面。
MMX
mmx是第一个广泛部署在桌面的SIMD指令集(参考维基百科)
mmx缩写并没有官方释义但有以下参考:
MultiMedia eXtension 多媒体扩展
Multiple Math eXtension 多重数学扩展
Matrix Math eXtension 矩阵数学扩展
MMX 额外定义了8个寄存器mm0-mm7,但本质是公用了st0-st7,但是只能用于整数不能用于浮点。
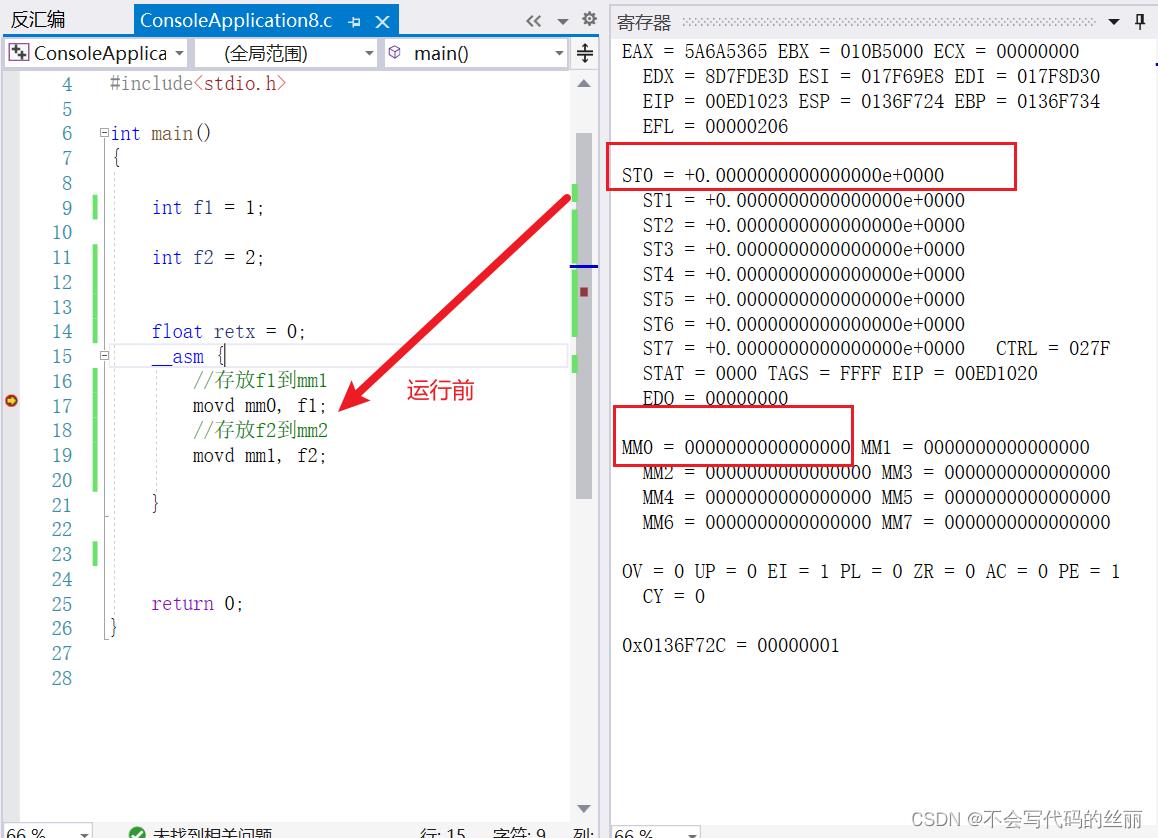
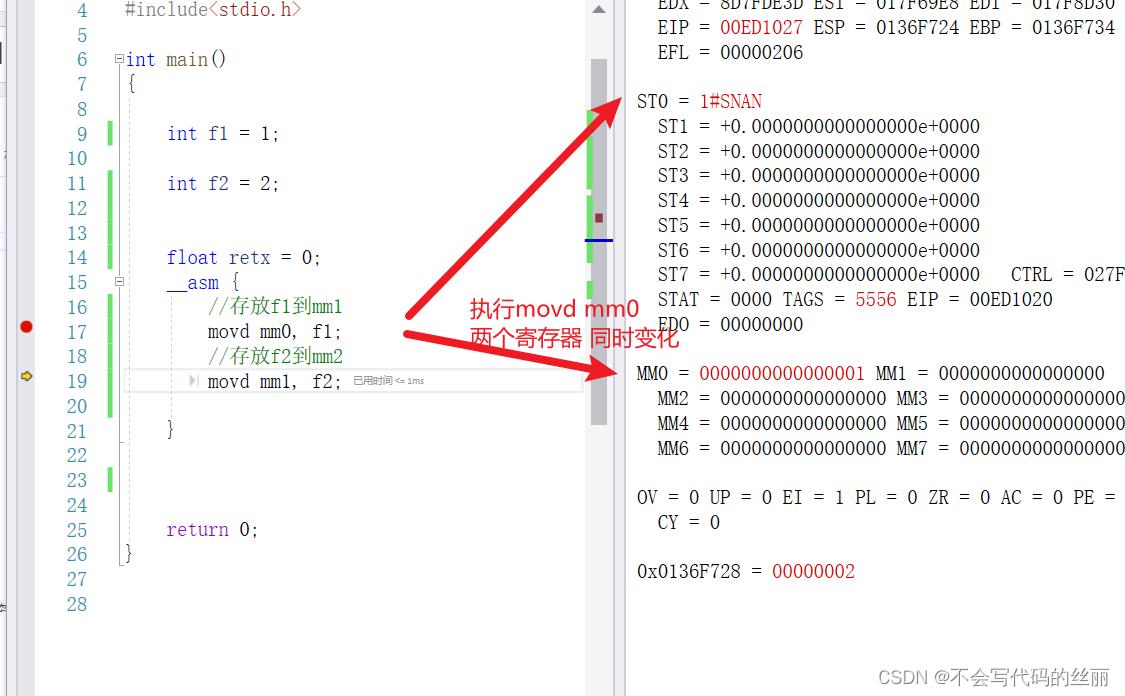

我们看一个真正SIMD指令例子:
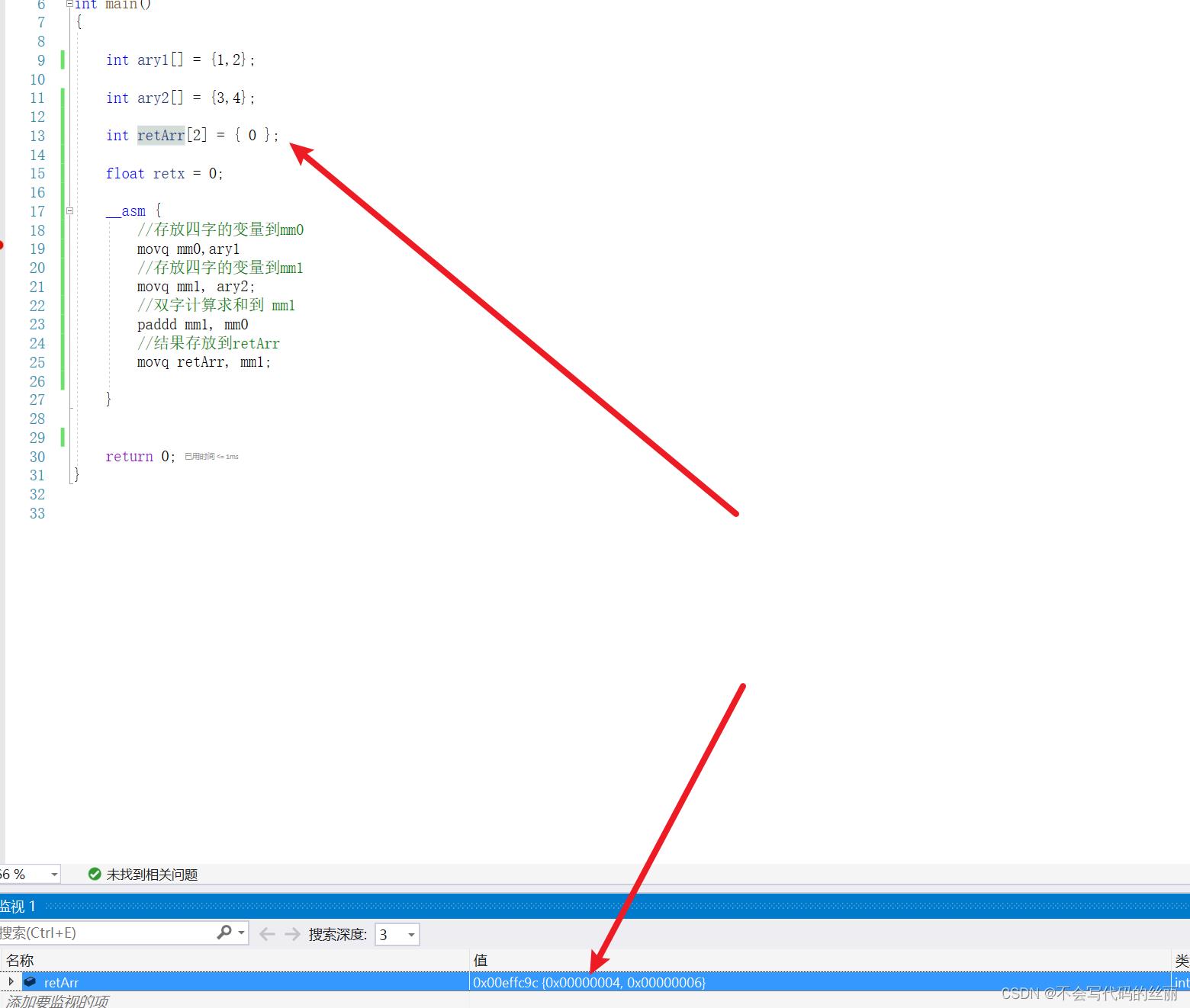
我们可以看到我们只运行了paddd指令即可完成两个int的计算求和。
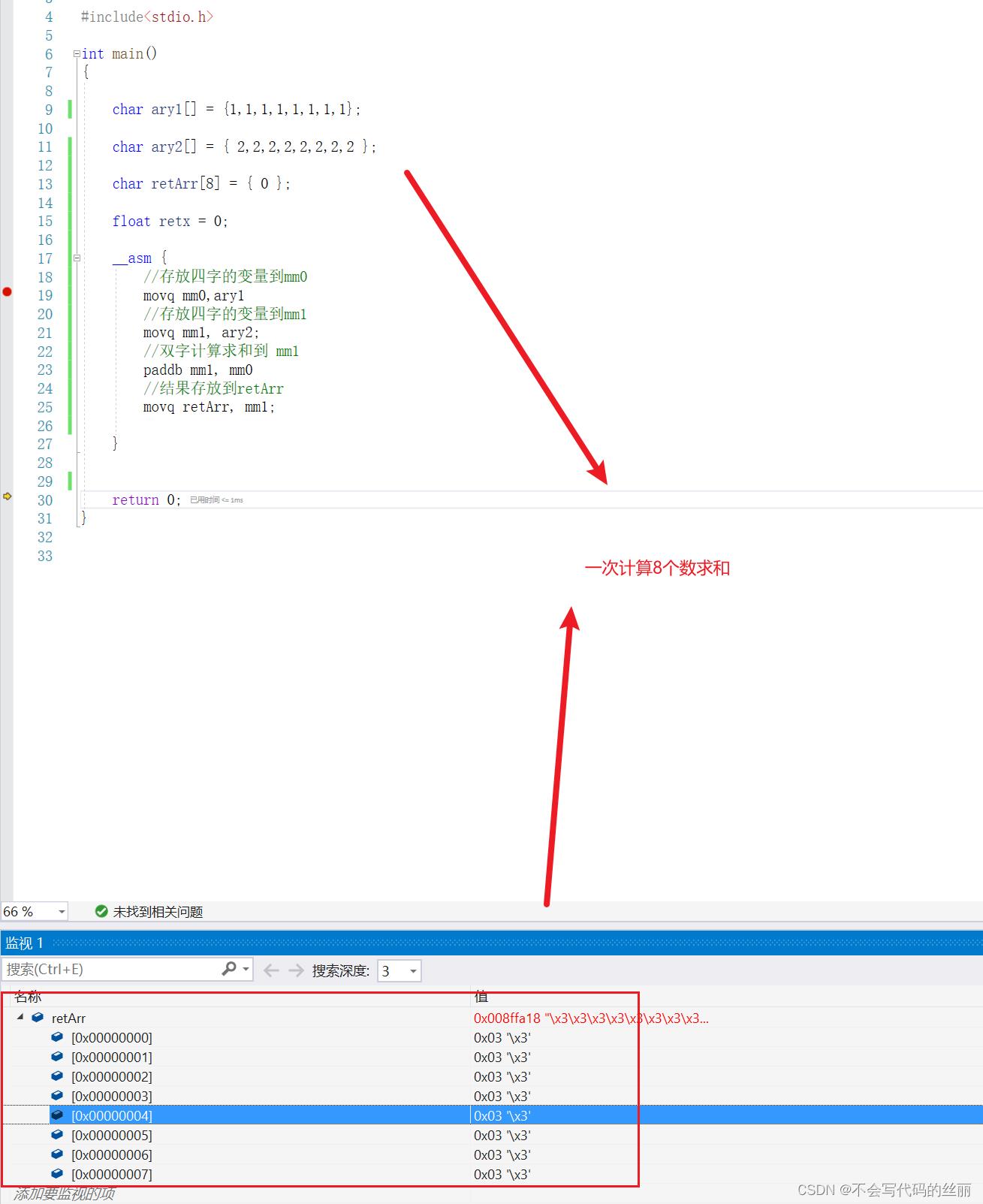
SSE
由于MMX不支持浮点计算AMD推出了3D Now!.
3D Now! 发布一年后,Intel在MMX基础上发展出SSE(Streaming SIMD Extensions) 指令集,用来取代MMX。
SSE推出新8个寄存器XMM0~XMM7每个寄存器大小为128

常用命令
- movss 传入单精度到xmm寄存器
- movsd 传入双精度到xmm寄存器
- movaps 传入地址对齐的单精度到xmm寄存器(地址必须模16)
- movups 传入地址未对齐的单精度到xmm寄存器
- movapd 传入对齐的双精度到xmm寄存器(地址必须模16)
- movupd 传入未对齐的双精度到xmm寄存器
- addss 单精度加法
- addsd 双精度加法
- addps 打包加法单精度

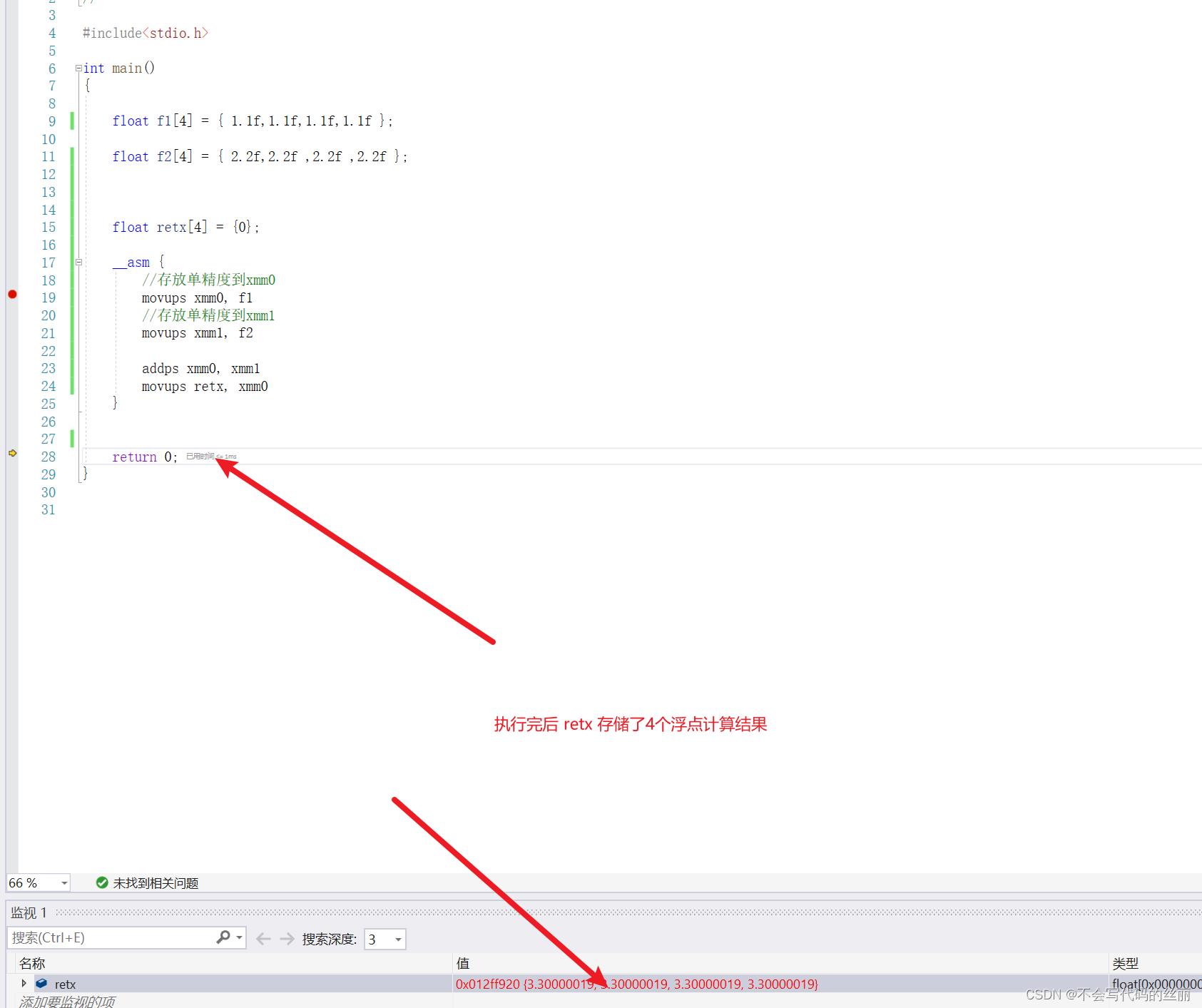
AVX
SSE5第五代由AMD提出,但由于市场竞争Intel直接宣布跳过SSE5推出AVX。
AVX全称 Advanced vector extensions(高级矢量扩展)
AVX 新增了8寄存器 YMM0-YMM7 为256位。其中需要注意XMM0和YMM0是共用寄存器的。另外提供三操作数。
SSE迁移到AVX比较简单只需要在原始指令集前加V即可

一个DEMO:
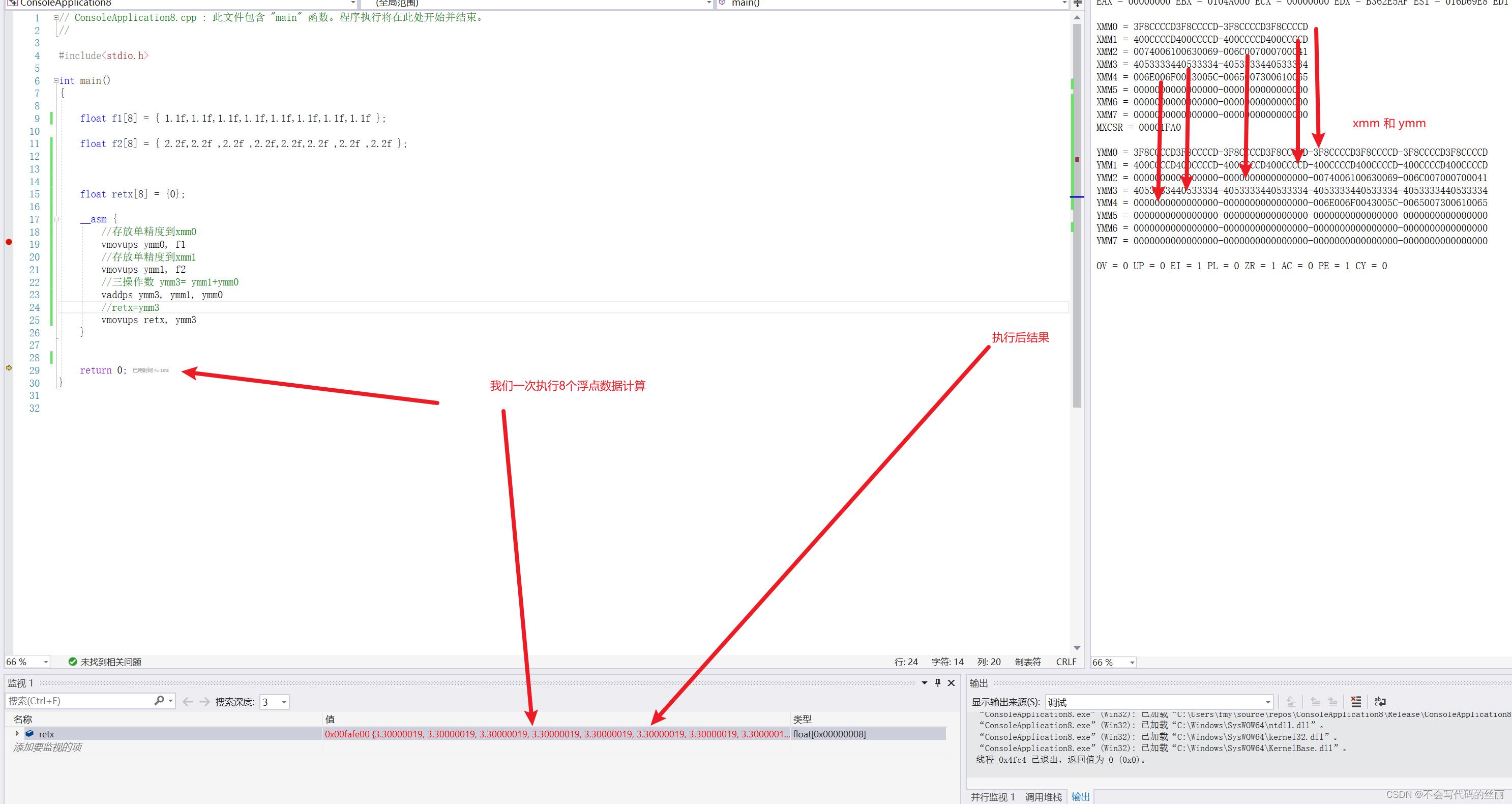
其他
你可以通过cpu-z查看CPU支持的SIMD指令

在VC中可以选择是否开启对应的指令集

如果你不想使用汇编也想使用SIMD指令,在windows可以使用immintrin.h对应的下函数。
#include<stdio.h>
#include<immintrin.h>
int main()
__m64 d;
__m64 d2;
d.m64_i32[0] = 1;
d.m64_i32[1] = 1;
d2.m64_i32[0] = 2;
d2.m64_i32[1] = 2;
__m64 ret = _m_paddd(d, d2);
return 0;
参考
以上是关于处理器 增强指令集的主要内容,如果未能解决你的问题,请参考以下文章