Flink实战之电商用户行为实时分析
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink实战之电商用户行为实时分析相关的知识,希望对你有一定的参考价值。
🌻在前面的章节中,我们学习了flink的DataStream API、Table API和SQL,想必大家学完后都想找个项目实战一下,于是它来了,对往期内容感兴趣的同学可以参考👇:
- 链接: Flink学习之flink sql.
- 链接: Flink学习之Table API(python版本).
- 链接: Flink学习之DataStream API(python版本).
- 链接: Hadoop专题.
- 链接: Spark专题.
🍀今天我们实战的项目是关于电商用户行为实时分析,主要是用flink Table 和 SQL来实现,让我们更加了解flink处理的一整套流程。让我们开始今日份的学习吧!
目录
1. 环境部署
我这才用的是docker安装,参考的是阿里云flink教程,关于安装的部分,我在前面的章节中有详细说明👇:
- flink环境搭建: Flink学习之环境搭建.
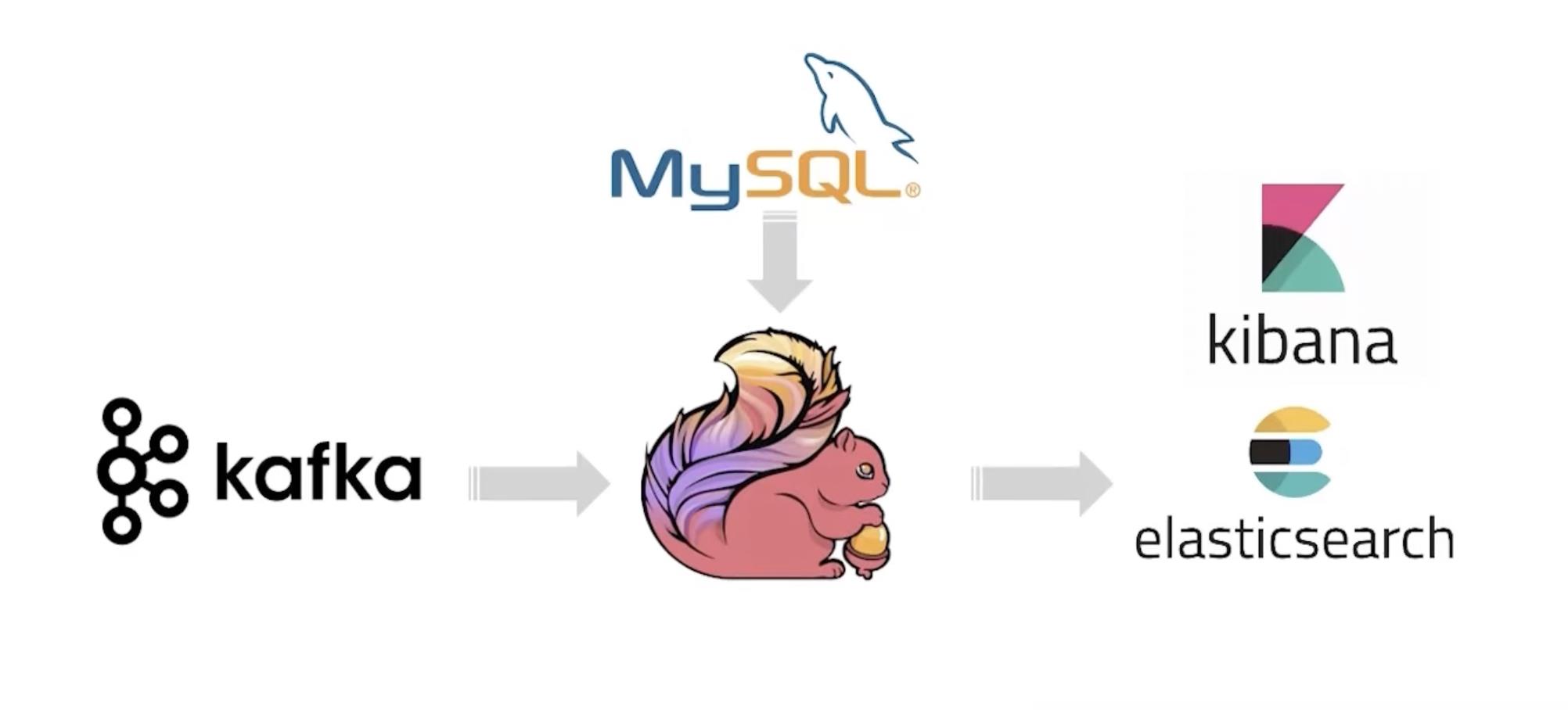
我这里建议使用docker,因为我们这个项目涉及到的东西较多:
- mysql
- kafka
- es
- kibana(BI工具)
结构如下:
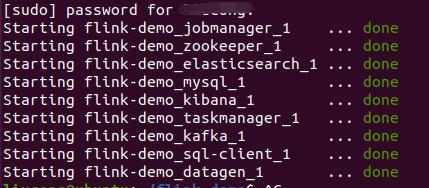
1.1 启动容器
#启动容器
sudo docker-compose up -d
各项服务将会进行启动:
1.2 启动flink sql 客户端
#启动flink clt客户端
sudo docker-compose exec sql-client ./sql-client.sh
启动成功如下:
1.3 容器的组成
- flink sql client:flink sql的客户端,用于提交sql
- flink集群:这里包括了jobmanager和taskmanager 用于执行sql任务
- datagen:数据源,用于生成用户数据,然后发送到kafka中。默认每秒生成2000条数据。
- mysql:作为维度表使用
- kafka:用作消息队列为flink提供数据
- zookeeper:kafka容器的依赖
- elasticsearch:用于存储flink产生的数据
- kibana:可视化es中的数据
2. 从kafka中导入数据
我们先看一下kafka里面的数据:
--查看10条数据
docker-compose exec kafka bash -c 'kafka-console-consumer.sh --topic user_behavior --bootstrap-server kafka:9094 --from-beginning --max-messages 10'
结果如下:

启动 flink sql clienk,你就可以看见一只大松鼠。
sudo docker-compose exec sql-client ./sql-client.sh
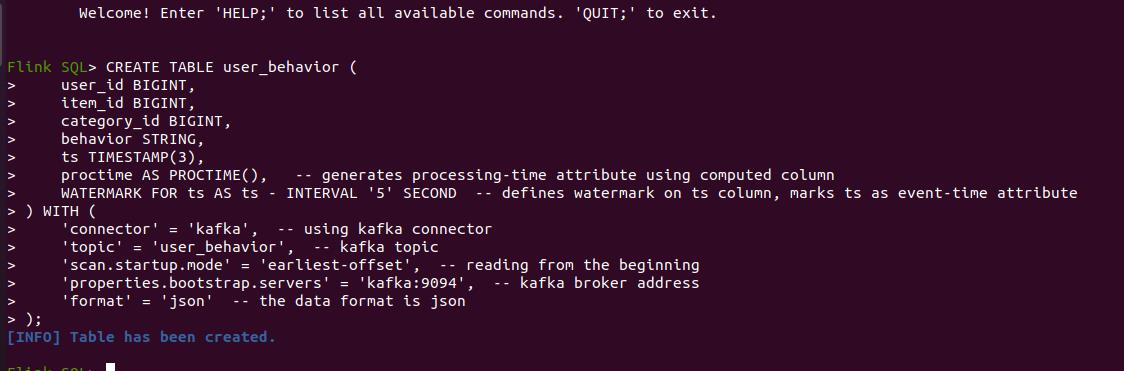
创建数据表,用来接受kafka中的数据。
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts TIMESTAMP(3),
proctime AS PROCTIME(), -- 数据处理时间
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND -- 水位线
) WITH (
'connector' = 'kafka', --kafka数据源
'topic' = 'user_behavior', -- kafka数据主题
'scan.startup.mode' = 'earliest-offset', -- 数据读取策略
'properties.bootstrap.servers' = 'kafka:9094', -- kafka 服务地址
'format' = 'json' -- 数据格式
);
结果如下:显示table已经创建成功了。
查看表的信息:
--展示所有表
show tables
-- 查看表的信息
desc 表名
结果如下:

select 的时候数据是一直变化的

flink 任务管理器中查看任务运行情况,端口号为localhost:8081
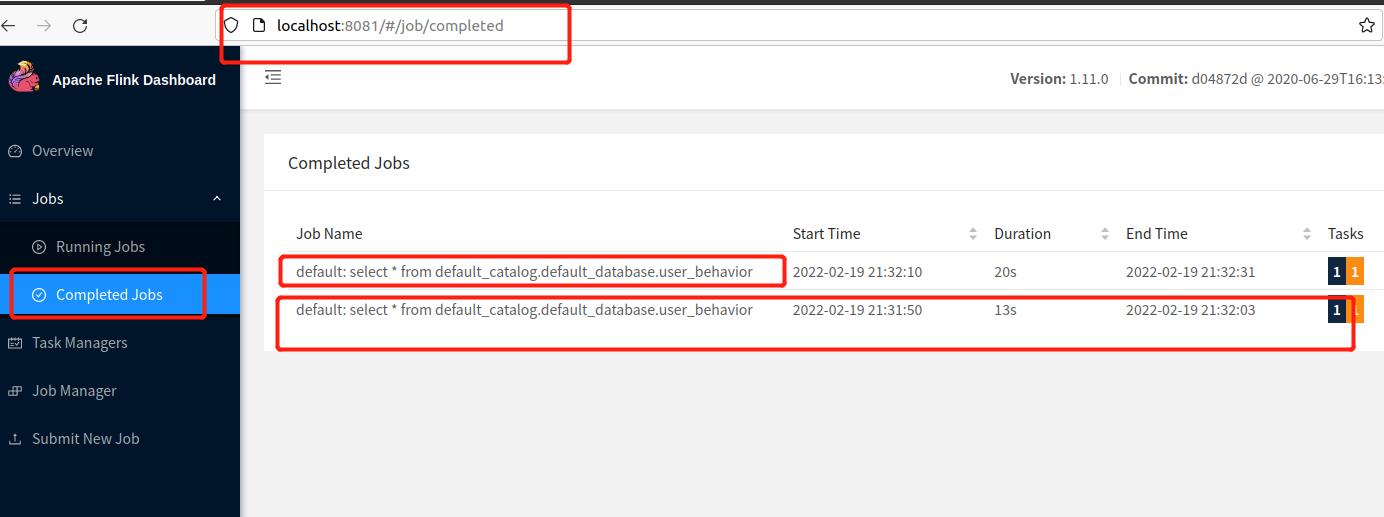
在这一步中,我们使用DDL语句创建了user_behavior表,并用WITH语句从kafka中导入了数据。
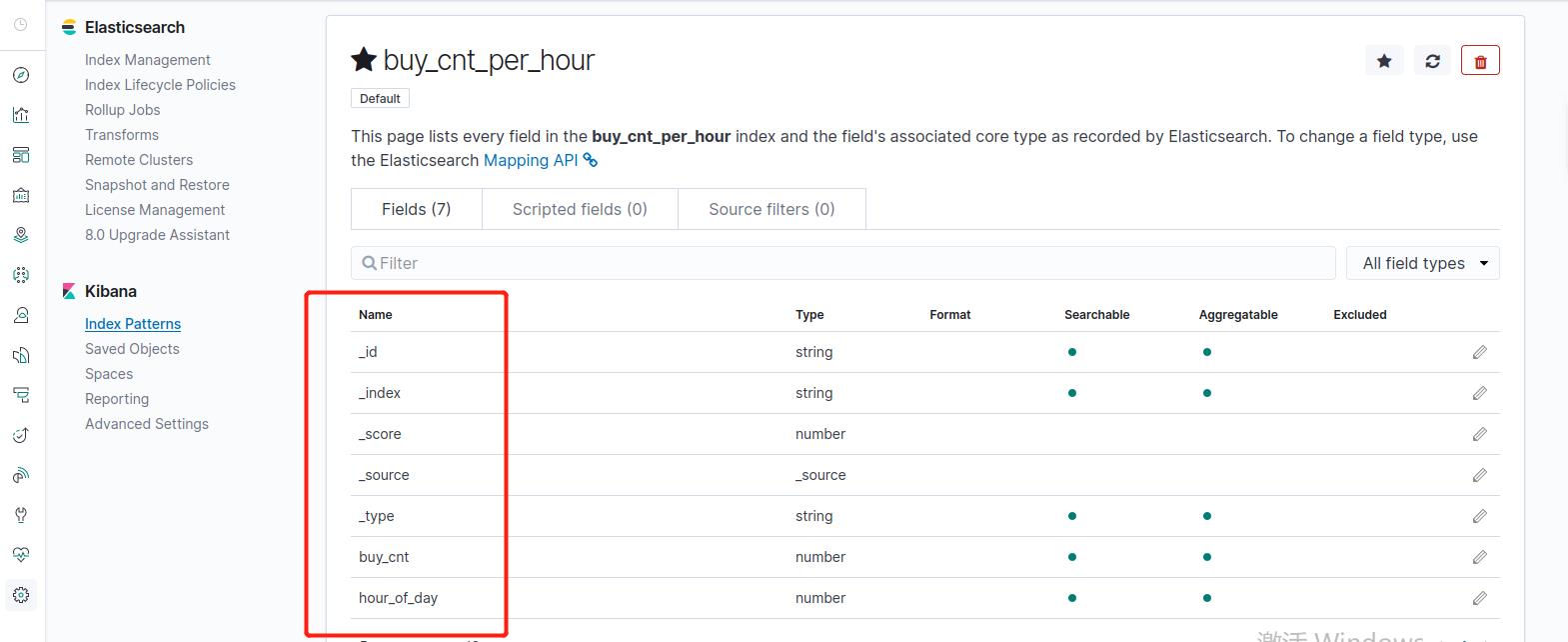
3. 统计每小时的成交量
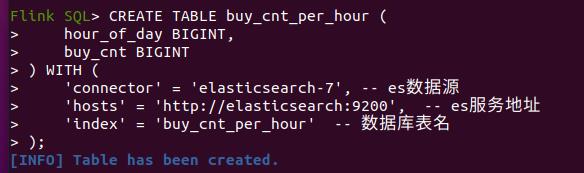
创建数据表buy_cnt_per_hour,将数据导出到es数据库中,主要导出的数据是2列:小时、成交量
CREATE TABLE buy_cnt_per_hour (
hour_of_day BIGINT,
buy_cnt BIGINT
) WITH (
'connector' = 'elasticsearch-7', -- es数据源
'hosts' = 'http://elasticsearch:9200', -- es服务地址
'index' = 'buy_cnt_per_hour' -- 数据库表名
);
结果如下:
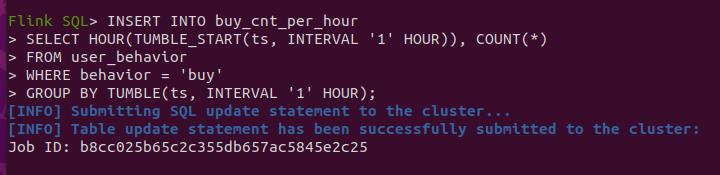
需要查询每小时有多少buy的行为,并将数据导出到es中(insert语句)
--这里涉及到flink的窗口函数,tumble滚动窗口。
INSERT INTO buy_cnt_per_hour
SELECT HOUR(TUMBLE_START(ts, INTERVAL '1' HOUR)), COUNT(*)
FROM user_behavior
WHERE behavior = 'buy'
GROUP BY TUMBLE(ts, INTERVAL '1' HOUR);
结果如下:
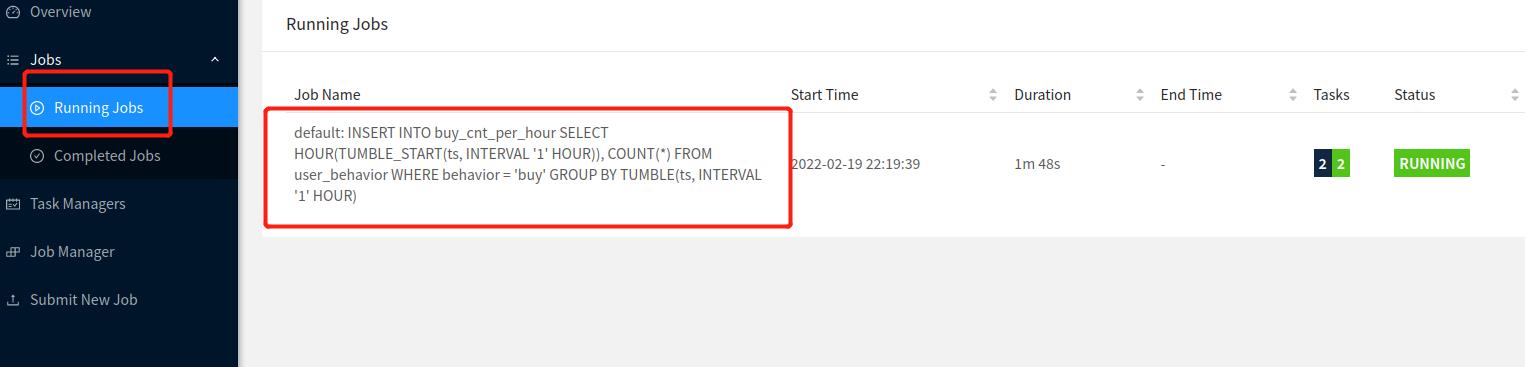
看一下flink的执行任务,显示正在运行,说明数据正在源源不断输入到es中。
4. 可视化结果
我们这里用kibana来可视化上面输出的结果。我们这里需要通过localhost:5601来访问kibanba。
创建数据源,点击红色的框框,即可创建成功。
数据源展示:
创建BI报表

画出图像,进行保存。

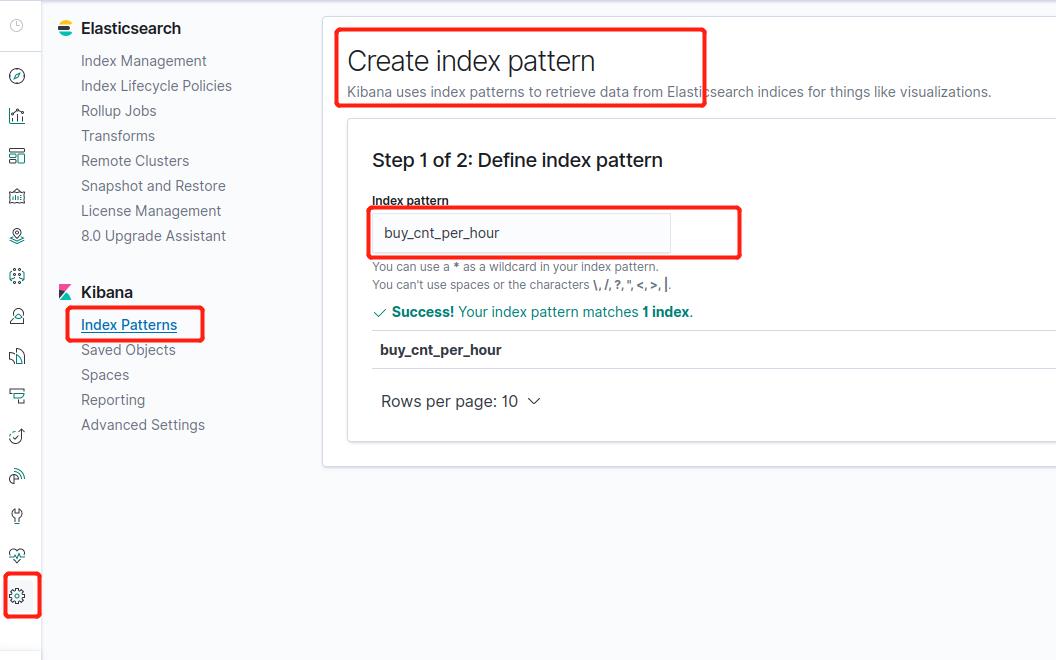
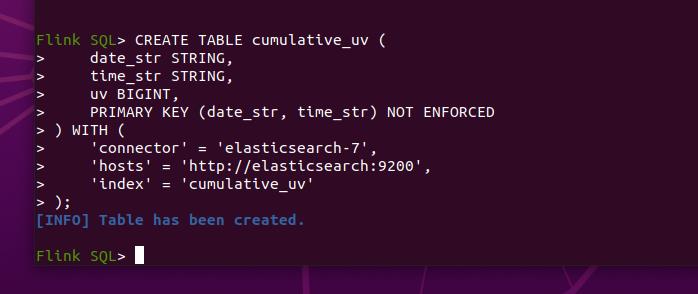
5. 统计一天每10分钟累计用户数
这一部分的统计是可视化一天中,某个时刻的累计独立用户数,也就是每一个时刻的UV数都是从0到该时刻的累加。
创建一个es表用于汇总和导出数据。
CREATE TABLE cumulative_uv (
date_str STRING,
time_str STRING,
uv BIGINT,
PRIMARY KEY (date_str, time_str) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://elasticsearch:9200',
'index' = 'cumulative_uv'
);
创建成功:
数据开发,使用data_format抽出基本的日期和时间,再用substr和字符串连接函数’||’ 将时间修正到10分钟级别。
INSERT INTO cumulative_uv
SELECT date_str, MAX(time_str), COUNT(DISTINCT user_id) as uv
FROM (
SELECT
DATE_FORMAT(ts, 'yyyy-MM-dd') as date_str,
SUBSTR(DATE_FORMAT(ts, 'HH:mm'),1,4) || '0' as time_str,
user_id
FROM user_behavior)
GROUP BY date_str;
连接成功:
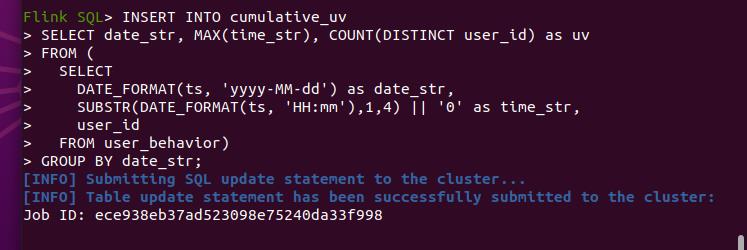
依旧是在kibana中可视化:
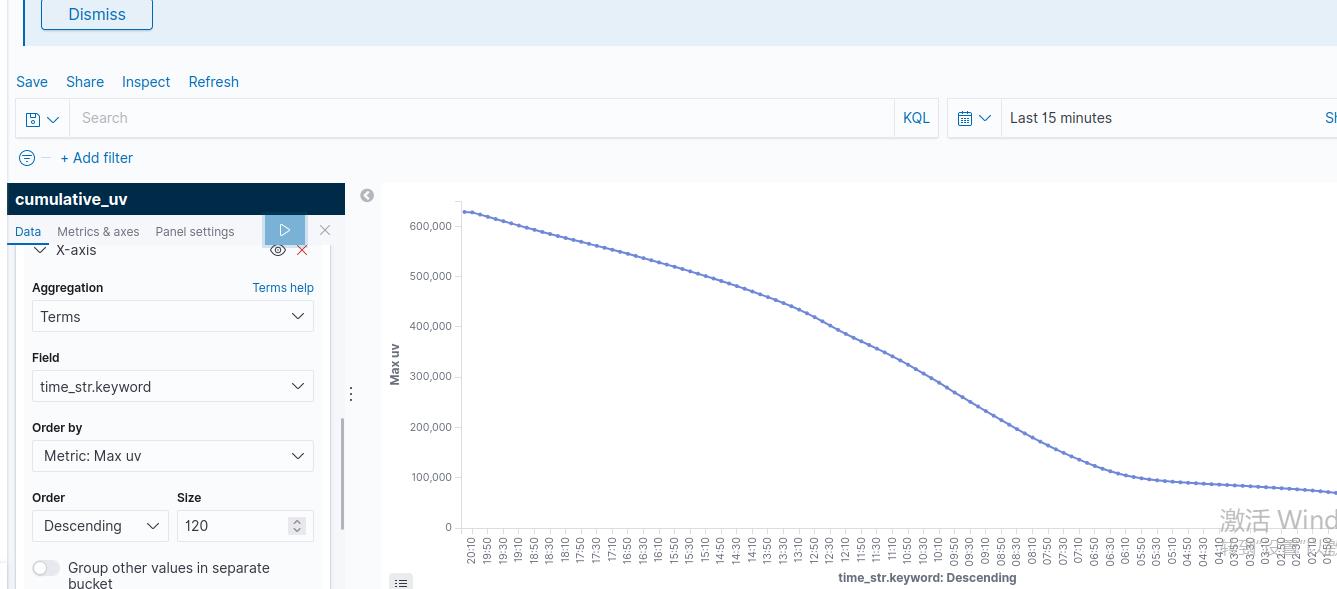
BI数据报表展示如下:

6. 顶级项目排行
这一部分要制作的是类目排行榜,了解哪些类目是支柱类目,由于类目分类太细,于是采用维度表进行映射,规约到顶级类目,而mysql容器中准备了子类目和顶级类目的映射关系,作为dim表。
连接mysql表,用于后续连接
CREATE TABLE category_dim (
sub_category_id BIGINT,
parent_category_name STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysql:3306/flink',
'table-name' = 'category',
'username' = 'root',
'password' = '123456',
'lookup.cache.max-rows' = '5000',
'lookup.cache.ttl' = '10min'
);
创建成功

创建es表,用于存储类目统计结果
CREATE TABLE top_category (
category_name STRING PRIMARY KEY NOT ENFORCED,
buy_cnt BIGINT
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://elasticsearch:9200',
'index' = 'top_category'
);
创建成功:

通过对mysql的dim表进行关联,补全类目名称,这里使用一个视图,简化逻辑,就不用建表了。
CREATE VIEW rich_user_behavior AS
SELECT U.user_id, U.item_id, U.behavior, C.parent_category_name as category_name
FROM user_behavior AS U LEFT JOIN category_dim FOR SYSTEM_TIME AS OF U.proctime AS C
ON U.category_id = C.sub_category_id;
创建成功:

统计完后,根据类目分组,统计出buy的次数,并写入到es中。
INSERT INTO top_category
SELECT category_name, COUNT(*) buy_cnt
FROM rich_user_behavior
WHERE behavior = 'buy'
GROUP BY category_name;
写入成功:
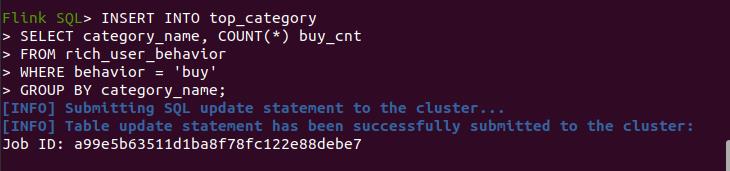
可视化类目排行,过程同上几张报表,最终结果如下:

但是感觉差一张图显示的效果不好看,我们最后用张目标图来补充上,用来统计我们用户数到100000的进度。

最后展示结果:
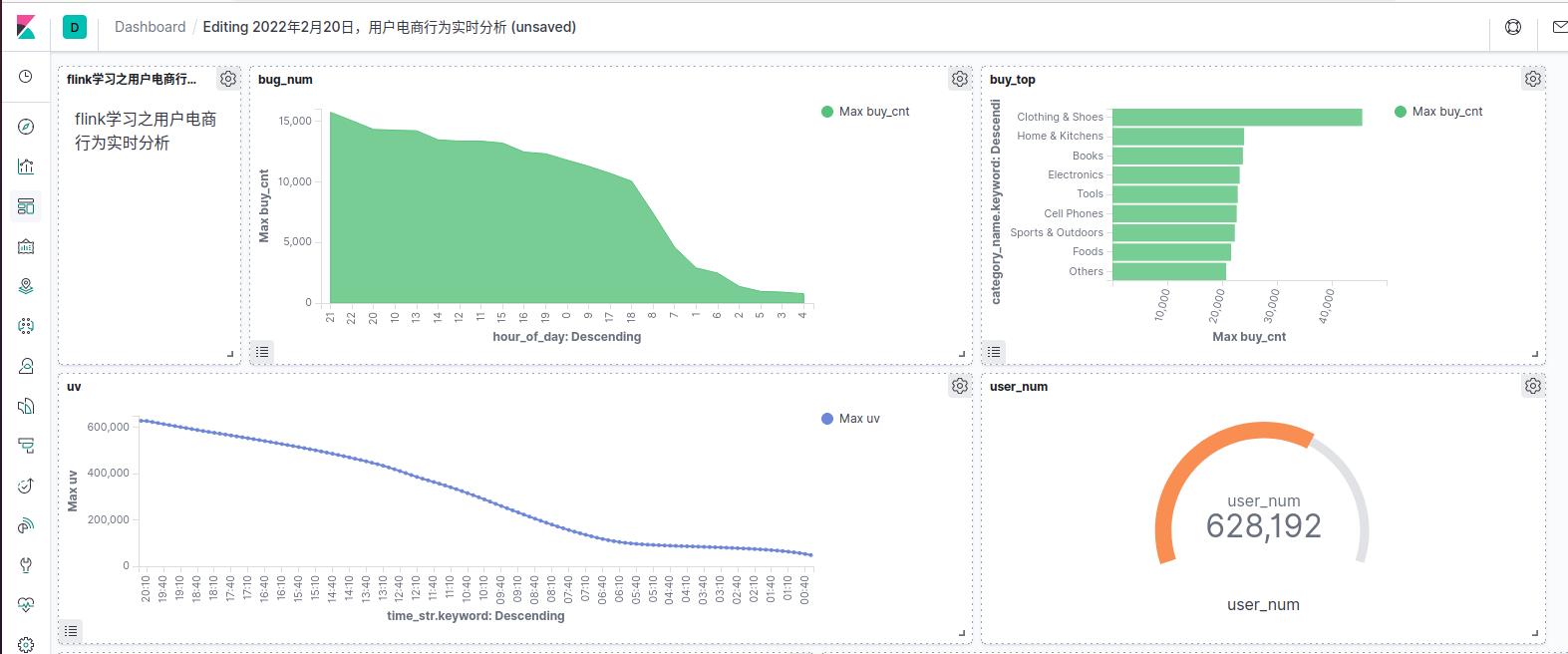
7. 总结
- 本项目参考的是阿里云apache flink的官方教程,从数据源到flink处理,到输出到es,制作报表这一整套流程都涵盖在内,很好的对我们前面学习的流处理框架、流处理的API进行了实践。
- 本实践的运行环境是ubuntu20.04,内存4G,CPU分配1core。
8. 参考资料
官方文档: 官方Flink SQL demo.
《Flink入门与实战》
《PyDocs》(pyflink官方文档)
《Kafka权威指南》
《Apache Flink 必知必会》
《Apache Flink 零基础入门》
《Flink 基础教程》
以上是关于Flink实战之电商用户行为实时分析的主要内容,如果未能解决你的问题,请参考以下文章