(DDIA)数据存储与检索
Posted 雨钓Moowei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(DDIA)数据存储与检索相关的知识,希望对你有一定的参考价值。
翻译《Designing Data-Intensive Applications》
作者:Martin Kleppmann
译者:雨钓(有增改)
一、Storage And Retrieval
一个数据库最基本的要具有两个功能:当你给它一些数据的时候它可以帮你存储数据,之后当你需要这些数据时,他可以返回给你所需要的数据。
你(应用程序开发人员)向数据库提供固定格式的数据,稍后你就可以再次请求获取这些数据。 在本章中,我们将从数据库的角度讨论以下问题:数据库如何存储我们所给出的数据,以及当我们需要这些数据时,我们如何再次从数据库里找到它,即数据库内部是如何存储和检索数据的。
你可能会问,为什么作为一个应用开发人员需要关心数据库的存储和内部检索实现?毕竟我们基本不可能从头开始去实现自己的数据存储引擎,因为已经用众多可以直接使用的方案。此外针对事务性工作负载进行优化的存储引擎和为分析型工作负载进行优化的存储引擎之间存在很大的差别。
首先我们将从这一章开始讨论存储引擎,这些存储引擎可能在你熟悉的各种数据库中使用:传统的关系数据库,以及大多数所谓的No SQL数据库。我们将主要介绍这两个家族的存储引擎。
二、Data Structures That Power Your Database
一个最简单的存储引擎的实现如下:
#!/bin/bash
db_set ()
echo "$1,$2" >> database
db_get ()
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
这两个函数实现一个键值存储。您可以调用db_set key,它将在数据库中存储key和value。key和value可以是(几乎)任何你想要的东西——例如,value可以是一个JSON文档。之后你可以调用db_get key,查找与该特定key关联的最新值并返回它。
底层存储格式非常简单:一个文本文件,其中每一行都包含了一个key-value对,用逗号分隔(大致像CSV文件一样)。每个对db_set的调用都会将数据追加到文件的末尾,因此,如果你更新了一个key,那么这个key的旧版本不会被覆盖——你需要查看该文件中这个key所对应的所有历史value值,并找到最新的value。
我们的db_set函数实际上具有相当好的性能,因为它非常简单,同时将数据追加到文件的方式通常非常高效。与db_set函数类似,许多数据库在内部使用类似的日志格式,这是一个仅附加(Append only)的数据文件。
真正的数据库有更多的问题需要处理(比如并发控制,磁盘空间回收,这样日志就不会永远增长,处理错误等等),但是基本原理是一样的。日志格式的数据存储非常有用,我们将在之后的其余部分中多次遇到它们。
( “日志”一词通常用来指应用程序日志,其中应用程序输出用于描述正在发生的事情的文本。在这本书中,日志具有更一般的意义:一个附加的记录序列。它不需要是人类可读的;它可能是只用于其他程序的读取的二进制的文件。)
另一方面,如果数据库中有大量的记录,那么db_get函数的性能会很糟糕。每次你想要查找一个key时,db_get将从头到尾扫描整个数据库文件,查找key对应的所有记录。在算法术语中,查找的成本是O(n):如果你的数据库中的数据量增加时,那么查找所需的时间将成倍增长。
为了有效地发现数据库中某个key对应的value,我们需要不同的数据结构:索引。在这一章中,我们将研究一系列的索引结构,并对其进行比较; 它们背后的基本思想是将一些额外的元数据单独存储,充当路标,帮助你定位所需的数据。如果您想以几种不同的方式搜索相同的数据,您可能需要在数据的不同部分上使用几个不同的索引。
索引是派生自原始数据的附加结构。许多数据库允许您添加和删除索引,这并不影响数据库的内容;它只影响查询的性能。 维护额外的数据结构是有代价的,特别是在写操作上,对于写操作来说,无法在像之前那样简单将记录添加到文件中,任何类型的索引通常会减慢写操作,毕竟在写数据时索引也需要更新。
这在存储系统中是一个重要的权衡:选择良好的索引可以加快读取速度,但是每个索引都减慢了写入速度。 出于这个原因,数据库通常不会在默认情况下索引所有内容,但是需要你(应用程序开发人员或数据库管理员)结合你对应用程序主要查询模式的了解手动构建索引。 然后,你可以选择为你的应用程序构建最优的索引,而不必引入不必要的开销。
三、Hash Indexes
让我们从key-value数据的索引开始。这不是唯一可以作为索引实现的数据结构,但它非常常见,而且它是更复杂索引重要的组成部分。键值存储与大多数编程语言中可以找到的dictionary类型非常相似,通常是作为散列表(hashtable)实现的。hashtable在许多算法教科书中都有描述[1,2],因此我们不会详细讨论它们在这里是如何工作的。既然我们已经有了内存数据结构的哈希映射,为什么不使用它们来索引磁盘上的数据呢?
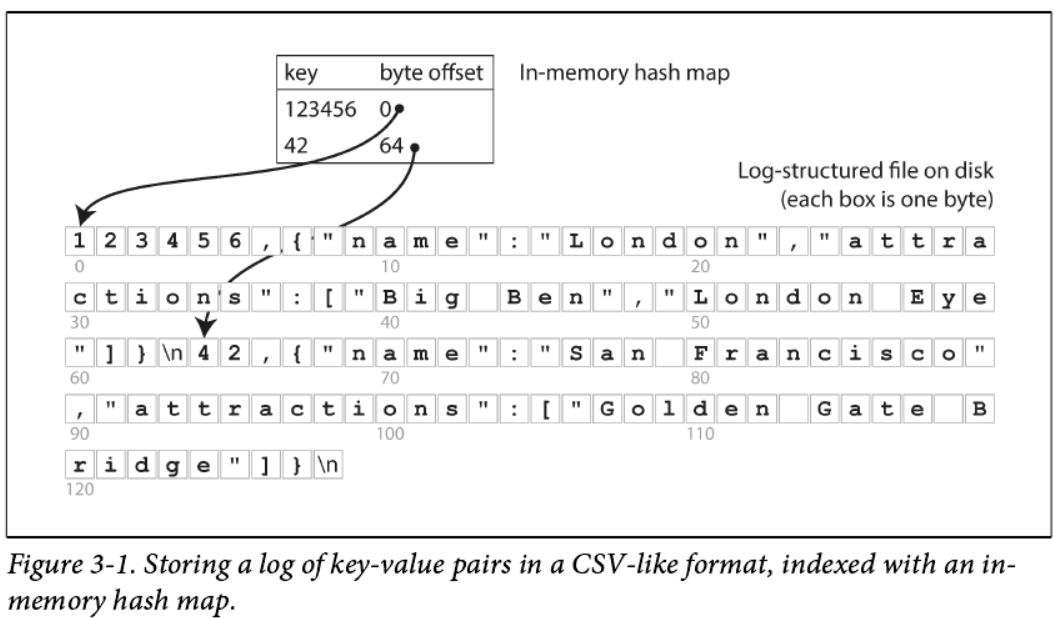
假设我们的数据存储只包括对文件的追加,就像前面的例子一样。 那么,最简单的索引策略是:保存一个内存哈希映射,其中每个key都映射到数据文件中的一个字节偏移位置,该位置存储有对应的数值,如图3-1所示。
无论何时将新的key-value对添加到文件中,您都会更新hashtable以反映您刚刚编写的数据的偏移量(这既适用于插入新键,也用于更新存在键)。当你想查找一个key时,使用hashtable来查找数据文件中的偏移量,定位该位置,并读取该值。
这听起来可能过于简单,但却是可行的方法。这实际上是(Bitcask 中的默认存储引擎)所做的[3]。
Bitcask 提供高性能的读和写,需要满足的前提就是所有的key都存储在内存里,因为hashtable被完全保留在内存中。 但是value并没有存在内存里,而是存储在磁盘上,所以Value可以使用比可用内存更多的空间。如果数据文件的那一部分已经在文件系统缓存中,那么读操作将不会有任何磁盘I/O。
像Bitcask这样的存储引擎非常适合于每个key的value经常更新的情况。 例如,key可能是一个视频的URL,而value可能是它被播放的次数(每次点击播放按钮时value都会增加)。 在这种工作负载中,会有很多写操作,但是key的数据量相对较少——每个key都有大量的写操作,但是在内存中保留所有key是可行的。
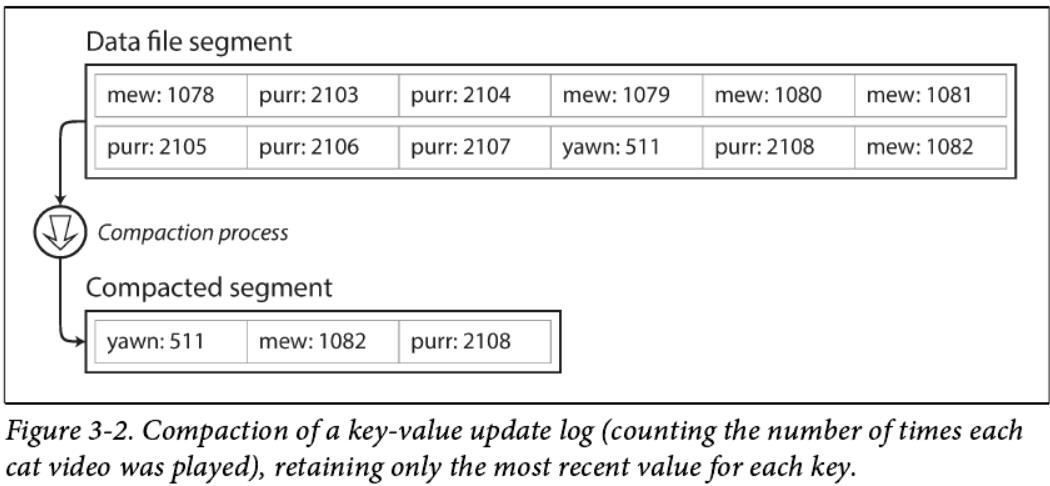
到目前为止,我们一直对文件进行了追加,那么我们如何避免最终耗尽磁盘空间呢? 一个好的解决方案是,当它达到一定的大小时, 通过关闭这个文件,并将写入到一个新的文件中。这样每个文件中存储的都是一小段数据,称之为:Data file segment。然后我们可以对这些文件中的内容进行压缩,如图3-2所示。压缩意味着将文件中重复key合并,并且只保留每个key的最新值。
此外,由于压缩常常使segment更小(假设一个key在一个segment内平均被重写了多次),我们也可以同时将所有的segment合并在一起执行压缩,如图3-3所示。segment 在写入后不会被修改,因此将合并之后的segment写入到一个新segment中。segment的合并和压缩可以在后台线程中完成,而在压缩合并进行的过程中,我们仍然可以使用旧的segment段文件,以正常的方式完成读和写。合并压缩过程完成之后,我们将读请求改为读取新合并的segment而不是旧的segment,然后旧的segment就可以被删除掉以释放磁盘空间。
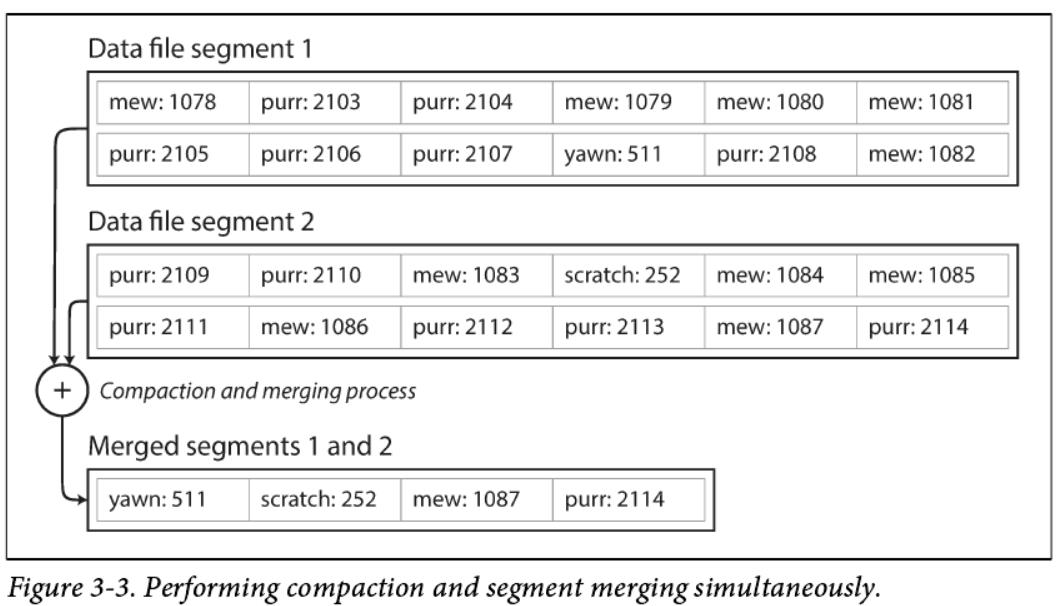
每个segment都有自己的内存hashtable作为索引。为了找到key对应的value的值,我们首先检查最近的segment的hashtable。如果key不存在,我们将检查第二个最近的部分,等等。segment合并的过程减少了segment的数量,所以查找操作不需要检查太多的hashtable。这个简单的想法在实践中有很多细节。简单地说,真正实现的一些重要问题是:
- File format:
CSV不是日志文件的最佳存储格式。使用二进制格式可以更快更简单,首先计算字符串的所占的字节长度,然后将字符串编码成字节进行存储,之后当使用该字符串时,只需要重固定位置开始获取一定长度的字节数据进行解码就可以了。 - Deleting records:
如果您想删除一个key及其Value,则必须将一个特殊的删除记录附加到数据文件(有时称为Tombstone)。当segment被合并时,合并的进程会将标记有Tombstone记录删除掉。 - Crash recovery:
如果数据库重新启动,内存中的Hashtable索引就会丢失。原则上,您可以通过从头到尾读取整个segment文件来恢复每个segment的hashtable,并将hashtable中所有key对应的偏移量更新为最新的值。但是,如果segment文件很大,这可能需要很长时间,同时这会使服务器重负载过重。Bitcask通过将每个segment的hashtable镜像存储在磁盘上, 这样就可以更快地装入内存,而不需要扫描所有数据文件。 - Partially written records:
数据库可能在任何时候崩溃,甚至在将一条记录追加到segment的过程中数据库都可能崩溃掉。Bitcask文件包含校验,允许检测和忽略该数据文件损坏的部分。 - Concurrency control:
由于写操作是严格按顺序执行的,所以一个常见的选择是只有一个写线程。segment的数据是唯一的,而且是不可变的,所以它们可以被多线程并发读取。即只有一个写线程可以有多个读线程。
这种append-only log机制,第一眼看上去感觉会很浪费:**为什么不更新文件,用新Value重写旧的Value?**然而,append-only的设计是有优势的,原因如下:
- Append和Segment合并操作都是顺序写操作,它比随机写要快得多,特别是在磁盘驱动器上。 在某种程度上,顺序写在固态硬盘(ssd)上也有很大的优势[4]。 我们之后将进一步讨论这个问题。
- 如果segment文件只是附加的或不可变的,那么并发控制和崩溃恢复要简单得多。例如,您不必担心当一个值被覆盖时发生失败后的处理操作,因为如果在覆盖时发生失败,那么留给你的将是一个不完整的数据文件。
- 合并旧segment可以避免一个问题:随着时间的推移数据文件变得很零碎很分散。
然而Hash 索引也有它的局限性:
- Hashtable必须存入内存,所以如果你有非常多的key,你就不走运了。 原则上,您可以在磁盘上维护一个Hashtable,但不幸运的是,磁盘上的Hashtable执行效果并不好,它需要大量的随机访问I/O,当数据量很大时,这种操作是非常昂贵的,并且散列冲突需要复杂的处理逻辑。
- 范围查询无效。例如,你不能轻松地扫描kitty00000和kitty99999之间的所有key,您必须在hashtable中查找每一个key。
在下一节中,我们将会看到一个索引结构,它没有上面这些限制:
未完待续。。。。

以上是关于(DDIA)数据存储与检索的主要内容,如果未能解决你的问题,请参考以下文章