C++11线程,亲合与超线程
Posted 同皆无穷小
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++11线程,亲合与超线程相关的知识,希望对你有一定的参考价值。
原作者:Eli Bendersky
http://eli.thegreenplace.net/2016/c11-threads-affinity-and-hyperthreading/
转载自:http://blog.csdn.net/wuhui_gdnt/article/details/51280906
背景与简介
多年来,C与C++标准将多线程及并发处理排斥在外——在“目标机器依赖”世界的阴影之中,以“抽象机器”为目标的标准不包括它。在堆积如山,涉及并发的邮件列表及新闻组提问中,直接而冷血的“C++不知道线程是什么”的回答将永远提醒着这个过去。
不过这一切随着C++11的到来而终结。C++标准委员会意识到C++将不能维持其地位,除非它能与时俱进,并最终承认线程、同步机制、原子操作及内存模型的存在——就在标准里,迫使编译器及库厂商对所有支持的平台实现这些。这是IMHO,在C++11版本释放的雪崩式改进中最有积极意义的改进之一。
本文不是C++11线程的教程,但它使用它们作为主要的线程化机制来展示其观点。它以一个基本的例子开始,如何快速地转入到线程亲和性、硬件拓扑及超线程性能影响的特殊领域。它尽可能使用可移植的C++,对真正特殊的地方,清晰地标注出平台特定的调用。
逻辑CPU,核与线程
大多数现代机器是多CPU的。当然这些CPU如何分配到插槽及硬件核依赖于机器,但OS看到能并发执行任务的若干“逻辑”CPU。
在Linux上获取这个信息最简单的方式是cat/proc/cpuinfo,它依次列出系统中的CPU,对每个CPU提供一些信息(比如当前频率,cache大小等)。在我的(8CPU)机器上:
$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 60
model name : Intel(R)Core(TM) i7-4771 CPU @ 3.50GHz
[...]
stepping : 3
microcode : 0x7
cpu MHz :3501.000
cache size : 8192 KB
physical id : 0
siblings : 8
core id : 0
cpu cores : 4
apicid : 0
[...]
processor : 1
vendor_id : GenuineIntel
cpu family : 6
[...]
[...]
processor : 7
vendor_id : GenuineIntel
cpu family : 6
使用lscpu可以得到一个汇总输出:
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 60
Stepping: 3
CPU MHz: 3501.000
BogoMIPS: 6984.09
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 8192K
NUMA node0 CPU(s): 0-7
这里也很容易看到这个机器有4个核,每个拥有两个HW线程(参考hyperthreading)。而OS将它们视为8个“CPU”,编号从0到7。
每CPU启动一个线程
C++11线程库优雅地提供了一个我们可以用来查找机器上有多少CPU的实用函数,这样我们可以计划我们的并发策略。这个函数名为hardware_concurrency,下面是一个使用它来启动合适数量线程的完整例子。下面只是一个代码片段;本帖的完整代码例子,连同Linux的Makefile可以在这个代码库中找到。
int main(int argc,constchar** argv)
unsigned num_cpus = std::thread::hardware_concurrency();
std::cout << "Launching "<< num_cpus <<"threads\\n";
// A mutex ensures orderly access to std::cout from multiplethreads.
std::mutex iomutex;
std::vector<std::thread>threads(num_cpus);
for (unsigned i = 0; i <num_cpus; ++i)
threads[i] = std::thread([&iomutex, i]
// Use a lexical scope and lock_guard to safely lock the mutexonly for
// the duration of std::cout usage.
std::lock_guard<std::mutex>iolock(iomutex);
std::cout <<"Thread #" << i <<"is running\\n";
// Simulate important work done by the tread by sleeping for abit...
std::this_thread::sleep_for(std::chrono::milliseconds(200));
);
for (auto& t : threads)
t.join();
return 0;
Std::thread是平台特定线程对象的一层薄封装;这是对我们有利,我们不久将使用的东西。因此当我们启动一个std::thread时,实际的OS线程被启动了。这是相当底层的线程控制,但在本文里我不会讨论高级的结构,像基于任务的并发,留待以后的帖子。
线程亲和性
我们知道了如何查询系统所具有的CPU数量,以及如何启动任意数量的线程。现在让我们做一些稍微更先进的东西。所有现代OS支持设置每线程的亲和性。亲和性表示OS调度器不是随意地在任意CPU上运行该线程,而是被要求将指定线程调度到单个CPU或一组预定义的CPU。默认地,亲和性涵盖了系统中的所有逻辑CPU,因此基于调度考虑,OS可以为任意线程挑选任意CPU。另外,如果对调度器来说是合理的话,OS有时在CPU间迁移线程(不过它应该尝试尽量减少迁移,因为迁移损失了线程所在核的热cache)。让我们以另一个例子观察这个效应:
int main(int argc,constchar** argv)
constexpr unsigned num_threads = 4;
// A mutex ensures orderly access to std::cout from multiplethreads.
std::mutex iomutex;
std::vector<std::thread> threads(num_threads);
for (unsigned i = 0; i <num_threads; ++i)
threads[i] = std::thread([&iomutex, i]
while (1)
// Use a lexical scope and lock_guard to safely lock the mutexonly
// for the duration of std::cout usage.
std::lock_guard<std::mutex> iolock(iomutex);
std::cout<< "Thread #" << i <<":on CPU " <<sched_getcpu() <<"\\n";
// Simulate important work done by the tread by sleeping for abit...
std::this_thread::sleep_for(std::chrono::milliseconds(900));
);
for (auto& t : threads)
t.join();
return 0;
这个例子启动了4个无限循环的线程,它们睡眠然后报告运行的CPU。报告通过sched_getcpu函数完成(特定于glibc——其他平台有类似功能的其他API)。下面是一个运行样例:
$ ./launch-threads-report-cpu
Thread #0: on CPU 5
Thread #1: on CPU 5
Thread #2: on CPU 2
Thread #3: on CPU 5
Thread #0: on CPU 2
Thread #1: on CPU 5
Thread #2: on CPU 3
Thread #3: on CPU 5
Thread #0: on CPU 3
Thread #2: on CPU 7
Thread #1: on CPU 5
Thread #3: on CPU 0
Thread #0: on CPU 3
Thread #2: on CPU 7
Thread #1: on CPU 5
Thread #3: on CPU 0
Thread #0: on CPU 3
Thread #2: on CPU 7
Thread #1: on CPU 5
Thread #3: on CPU 0
^C
一些观察:线程有时调度到同一个CPU,有时到另一个CPU。同样,有相当部分的区域在进行。最终调度器设法将每个线程放置在不同的CPU,并维持它在那里。当然不同的限制(比如系统负荷)会导致不同的调度。
现在让我们重新运行这个例子,但这次使用taskset将进程的亲和性限定在两个CPU——5和6:
$ taskset -c 5,6 ./launch-threads-report-cpu
Thread #0: on CPU 5
Thread #2: on CPU 6
Thread #1: on CPU 5
Thread #3: on CPU 6
Thread #0: on CPU 5
Thread #2: on CPU 6
Thread #1: on CPU 5
Thread #3: on CPU 6
Thread #0: on CPU 5
Thread #1: on CPU 5
Thread #2: on CPU 6
Thread #3: on CPU 6
Thread #0: on CPU 5
Thread #1: on CPU 6
Thread #2: on CPU 6
Thread #3: on CPU 6
^C
不出所料,尽管这里发生了一些迁移,所有的线程都遵命被锁定在CPU5与6。
离题——线程ID和原生句柄
尽管C++11标准添加了一个线程库,它不能标准化所有的东西。OS在实现与管理线程方面是不尽相同的,在C++标准里展露每个可能的线程实现细节过于约束。相反,处理以标准的方式定义许多线程概念,线程库还通过展露原生句柄,让我们与平台特定的线程API交互。然后这些句柄可以被传递到底层的平台特定API(比如Linux上的POSIX线程或Windows上的WindowsAPI)来履行对程序更细粒度的控制。
这里是一个启动单线程,然后通过原生句柄查询其线程ID的例子程序:
int main(int argc,constchar** argv)
std::mutex iomutex;
std::thread t = std::thread([&iomutex]
std::lock_guard<std::mutex> iolock(iomutex);
std::cout << "Thread: my id = "<< std::this_thread::get_id() <<"\\n"
<< " my pthreadid = " <<pthread_self() <<"\\n";
);
std::lock_guard<std::mutex> iolock(iomutex);
std::cout << "Launched t: id = "<< t.get_id() <<"\\n"
<< " native_handle = " <<t.native_handle() <<"\\n";
t.join();
return 0;
在我机器上某次运行的输出是:
$ ./thread-id-native-handle
Launched t: id = 140249046939392
native_handle= 140249046939392
Thread: my id = 140249046939392
my pthread id =140249046939392
主线程(在入口运行main的默认线程)与生成线程都获得线程ID——一个我们可以打印的不透明类型的一个标准概念,保存在一个容器里(例如,在一个hash_map里将它映射到其他),仅此而已。另外,线程对象拥有返回一个由平台特定API识别的句柄“实现定义类型”的native_handle方法。在上面的输出里有两件事是值得注意的:
1. 线程ID实际上等同于原生句柄。
2. 另外,两者在数值上都等于由pthread_self返回的pthreadID。
尽管native_handle与pthreadID相等是标准明确暗示的[1],第一件事是令人吃惊的。它看起来像绝对不应该依赖的一个实现的假象。我检查了最近一个libc++的源代码,发现pthread_t id被用作 “原生”句柄以及线程对象的实际“id”[2]。
所有这些让我们离题甚远,因此让我们扼要重述。本节最重要的收获是,通过std::thread的native_handle方法可以获得底层平台特定的线程句柄。事实上,在POSIX平台上这个原生句柄是线程的thread_tID,因此在线程内对pthread_self的调用是获取同一个句柄的一个完美有效方式。
通过编程设置CPU亲和性
我们之前看到的,像taskset这样的命令行工具让我们控制整个进程的CPU亲和性。不过,有时我们更希望更细粒度的设置,在程序内部设置指定线程的亲和性。我们能怎么做呢?
在Linux上,我们可以使用pthread特定的pthread_setafftinity_np函数。这里是一个重现我们之前所做的例子,不过这次是在程序内部进行。事实上,让我们做得更有趣一些,通过设置其亲和性将每个线程固定到单个CPU:
int main(int argc,constchar** argv)
constexpr unsigned num_threads = 4;
// A mutex ensures orderly access to std::cout from multiplethreads.
std::mutex iomutex;
std::vector<std::thread>threads(num_threads);
for (unsigned i = 0; i <num_threads; ++i)
threads[i] = std::thread([&iomutex, i]
std::this_thread::sleep_for(std::chrono::milliseconds(20));
while (1)
// Use a lexical scope and lock_guard to safely lock the mutexonly
// for the duration of std::cout usage.
std::lock_guard<std::mutex> iolock(iomutex);
std::cout<< "Thread #" << i <<":on CPU " <<sched_getcpu() <<"\\n";
// Simulate important work done by the tread by sleeping for abit...
std::this_thread::sleep_for(std::chrono::milliseconds(900));
);
// Create a cpu_set_t object representing a set of CPUs. Clear itand mark
// only CPU i as set.
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(i,&cpuset);
int rc =pthread_setaffinity_np(threads[i].native_handle(),
sizeof(cpu_set_t), &cpuset);
if (rc != 0)
std::cerr << "Error calling pthread_setaffinity_np: " << rc <<"\\n";
for (auto& t : threads)
t.join();
return 0;
注意我们如何使用之前讨论的native_handle方法来将底层的原生句柄传递给pthread调用(它接受一个pthread_tID作为第一个参数)。在我机器上这个程序的输出是:
$ ./set-affinity
Thread #0: on CPU 0
Thread #1: on CPU 1
Thread #2: on CPU 2
Thread #3: on CPU 3
Thread #0: on CPU 0
Thread #1: on CPU 1
Thread #2: on CPU 2
Thread #3: on CPU 3
Thread #0: on CPU 0
Thread #1: on CPU 1
Thread #2: on CPU 2
Thread #3: on CPU 3
^C
线程确实如要求的那样固定到单个CPU。
使用超线程共享一个核
真正好玩的东西来了。我们已经学习了一点CPU的拓扑结构,然后逐步地开发越来越复杂的程序,使用C++线程库与POSIX调用来微调给定机器上我们对CPU的使用,直到精确选择在CPU上运行的线程。
但是为什么这很重要?为什么你希望将线程固定到某些CPU?让OS做它擅长的事情,为你管理这些线程不是更合理吗?好吧,在大多数情形下是这样的,但不总是。
明白吗,不是所有的CPU都是一样的。如果你的机器有一个现代处理器,它很可能有多个核,每个带有多个硬件线程——通常是2。例如正如我在本文开头展示的,我的(Haswell)处理器有4个核,每个带有2个线程,总共8个硬件线程——8个逻辑线程对OS可用。我可以使用优良的工具lstopo来显示我处理器的拓扑结构:
[1]虽然它不保证,因为C++标准“不知道”POSIX是什么。
[2] 在POSIX版的libstdc++也是一样的(虽然代码更费解,如果你想自己检查)。
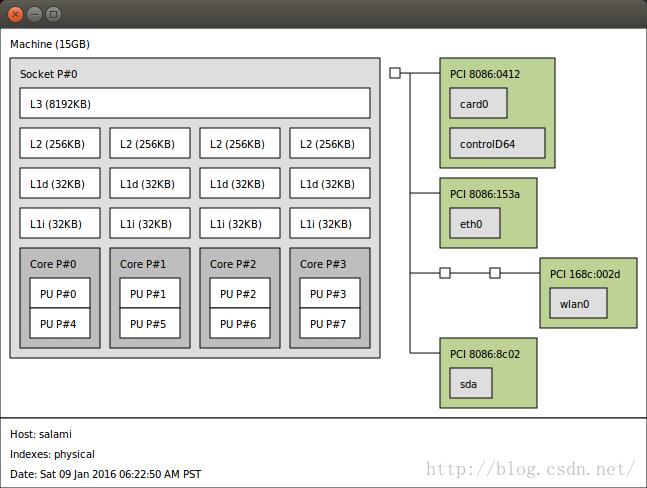
一个非图形化来看哪些线程共享同一个核的方式是查看每逻辑CPU存在的特殊系统文件。例如,对于CPU0:
$ cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list
0,4
更强大的(服务器级别)处理器有多个插槽,每个带有一个多核CPU。例如,在工作时我有一台带2个插槽的机器,每个是启用了超线程的8核CPU:总共32个硬件线程。更一般的情形通常出现在NUMA架构下,其中OS可以管理多个松散连接甚至不共享系统内存与总线的CPU。
重要的问题是——硬件线程共享什么,它如何影响我们编写程序。再看一眼上面展示的lstopo图。很容易看到在每个核的两个线程间共享L1与L2cache。L3是所有核共享的。对于多插槽机器,同一个插槽上的核共享L3,但通常每个插槽有自己的L3。在NUMA里,每个处理器通常访问自己的DRAM,一个处理器访问另一个处理器的DRAM需要使用某些通讯机制。
不过,cache不是核内线程共享的唯一对象。它们还共享许多核的执行资源,像执行引擎,系统总线接口,指令获取及解码单元,分支预测器等等[1]。
因此如果你想知道为什么超线程有时被视为CPU厂商耍的花招,现在你知道了。因为同核的两个线程共享了这么多东西,在通常的概念上它们不是完全独立的CPU。是的,对某些负荷这个安排是有利益的,但对于另一些则没有。有时它甚至会是有害的,就像大量“如何禁止超线程以提升应用程序X的性能”在线提问所暗示的。
共享核与分离核的性能演示
我已经实现了一个基准(benchmark)来让我在不同逻辑CPU上的并行线程中运行不同的浮点“工作负荷”,并比较这些工作负荷完成的完成时间。每个工作负荷有自己的浮点大数组,必须计算出一个浮点结果。这个基准从用户的输入算出在哪个CPU上运行哪个工作负荷,然后使用我们之前看过的API对每个线程按要求精确设置CPU亲和性,在不同的线程里并行地释放所有的工作负荷。如果你感兴趣,完整的基准连同Linux的Makefile在这里可以获得;在本文的余下部分,我将黏贴短的代码片段与结果。
我将关注两个工作负荷。第一个是简单的累加器:
void workload_accum(const std::vector<float>& data,float& result)
auto t1 =hires_clock::now();
float rt = 0;
for (size_t i = 0; i <data.size(); ++i)
rt += data[i];
result = rt;
// ... runtime reporting code
它将输入中的所有浮点值加起来。这类似于std::accumulate。
现在我将运行三个测试:
1. 在单个CPU上运行accum,来得到应该基准性能参数。测量它多久完成。
2. 在不同的核上运行accum。测量每个实例要多久完成。
3. 在同一个核的两个线程上运行两个accum实例[2]。测量每个实例要多久完成。
报告的数字(这里及随后)是作为一个工作负荷输入的1亿个浮点数的执行时间。我取几次运行的平均值:
[1] 更多细节参考超线程的维基页面及Agner Fog的这篇帖子。
[2] 哪些CPU属于同一个核或不同核的知识来自我机器的lstopo图。
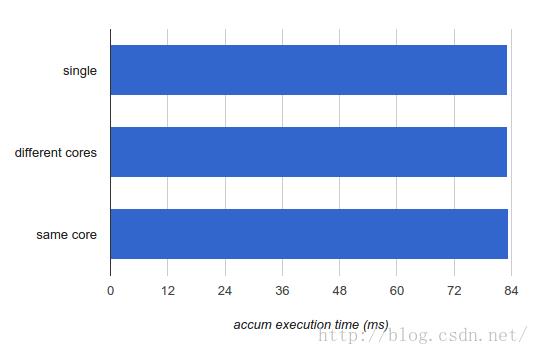
显然当一个运行accum的线程与另一个线程共享核时,其运行时间完成不受影响。这是好消息也是坏消息。好消息是这个特定的工作负荷很好地适应超线程,因为运行在同一个核上的两个线程显然做到了互不打扰。坏消息是出于相同的原因,它不是一个好的单线程实现,因为相当明显它没有最佳地使用处理器资源。
为了给出更多一点细节,让我们看一下workload_accum的内部循环的反汇编代码:
4028b0: f3 41 0f 5804 90 addss (%r8,%rdx,4),%xmm0
4028b6: 48 83 c201 add $0x1,%rdx
4028ba: 48 39ca cmp %rcx,%rdx
4028bd: 75 f1 jne 4028b0
相当简单。编译器使用addssSSE指令在一个SSE(128位)寄存器的低32位中累加浮点值。在Haswell上,这个指令的延迟是3个周期。延迟,而不是吞吐率,在这里是重要的,因为我们保持累加到xmm0。因此一个加法在下一个开始之前必须完成[1]。另外,尽管Haswell有8个执行单元,addss仅使用其中一个。这是相当低的硬件使用率。因此,在设法同一个核上运行两个互不干扰的线程是合理的。
作为另一个例子,考虑稍微更复杂的工作负荷:
void workload_sin(const std::vector<float>& data,float& result)
auto t1 = hires_clock::now();
float rt = 0;
for (size_t i = 0; i <data.size(); ++i)
rt +=std::sin(data[i]);
result = rt;
// ... runtime reporting code
这里不是累加数值,我们将它们的sin累加起来。Std::sin是一个相当复杂的函数,它运行简化泰勒级数多项式逼近,里面有很多数字运算(通常连同一个查找表)。这将使得核的执行单元比简单的相加更加繁忙。让我们再次检查一下三个不同模式的运行情况:
[1] 有几个方式优化这个循环,比如手动展开它来使用几个XMM寄存器,或甚至更好——使用addps指令同时累加4个浮点值。不过这不是严格安全的,因为浮点值的加法不是可分配的。编译器需要看到-ffast-math标记来启用这样的优化。
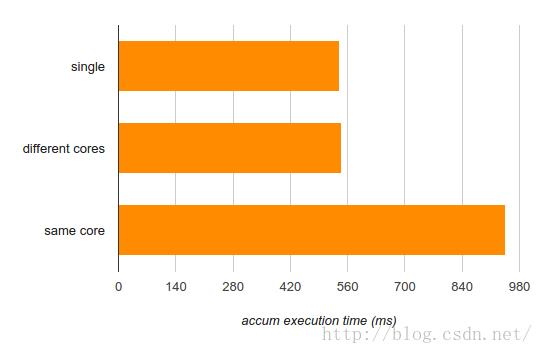
这更有趣了。虽然运行在不同的核上确实不会损害单个线程的性能(因此计算有很好的可并行性),但在同一个核上运行是有损害的——很大(超过75%)。
又一次的,这里有好消息与坏消息。好消息是即使在同一个核上,如果你希望尽可能地运算数字,两个线程加起来要快于单个线程(945ms运算两个输入数组,而单个线程需要540* 2 = 1080 ms来达到这个效果)。坏消息是如果你关心延迟,在同一个核上运行多个线程确实损害了它——线程竞争核的执行单元,降低了彼此的速度。
关于移植性的提示
目前为止在本文的例子都是Linux特定的。不过,我们这里碰到的都是多平台可用的,还有可移植的库来撬动移植问题。但如果你需要跨平台的移植性,使用它们将稍微繁琐和冗长一些,代价并不大。一个我觉得有用的好的可移植库是hwloc,它是OpenMPI项目的部分。它是高度可移植的——运行在Linux,Solaris,*BSD,Windows,你能说得出名字的系统上。实际上,之前我提到的lstopo工具就是构建在hwloc之上的。
Hwloc是一个通用的API,可以使你查询系统的拓扑结构(包括插槽,核,cache,NUMA节点等)以及设置及查询亲和性。我不准备在它身上花太多时间,但我在本文的代码库里包括了一个简单的例子。它显示了系统的拓扑结构并将调用线程绑定到某个逻辑处理器。它也展示了如何使用hwloc构建一个程序。如果你关心可移植性,我希望这个例子对你有用。如果你了解hwloc其他很酷的用法,或其他相同用途的可移植库——告诉我一身。
结语
好了,我们学了什么?我们已经看到如何检查并设置线程亲和性。我们也学到了如何控制在逻辑CPU上线程的放置,通过使用C++标准线程库联同POSIX调用,并通过C++线程库为这个目的展露作为桥梁的原生句柄。接下来我们看了如何找出处理器的实际硬件拓扑,并选择哪些线程共享核,哪些线程运行在不同的核上,以及为什么这很重要。
就像性能关键代码那样,结论是测量是最重要的事情,没有之一。在现代性能调优里有如此多的控制变量,很难预测怎样会更快,以及为什么。
不同的工作负荷有相当不同的CPU使用特点,这使得它们更适合或更不适合共享一个CPU核,一个插槽或NUMA节点。是的,OS在我的机器上看到8个CPU,标准线程库甚至让我以一个可移植的方式查询这个数字;但不是所有的CPU都是类似的——要从机器上榨出最好的性能,理解这是重要的。
我没有十分深入两个展示工作负荷微操作层面的性能,因为那不是本文的关注点。也就是说,我希望本文从另一个角度来了解在多线程执行里什么是重要的。在解决如何并行化有关算法时,不总是计入物理资源的共享——不过正如我们在这里看到的,确实应该计入。
以上是关于C++11线程,亲合与超线程的主要内容,如果未能解决你的问题,请参考以下文章