FP-tree的FP-tree构造算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FP-tree的FP-tree构造算法相关的知识,希望对你有一定的参考价值。
参考技术A输入:事务数据库D和最小支持度阈值minσ。
输出:D所对应的FP-tree。
方法:FP-tree是按以下步骤构造的:
(1)扫描事务库D,获得D中所包含的全部频繁项集1F,及它们各自的支持度。对1F中的频繁项按其支持度降序排序得到L。
(2)创建FP-tree的根结点T,以“null”标记。再次扫描事务库。对于D中每个事务,将其中的频繁项选出并按L中的次序排序。设排序后的频繁项表为[p|P],其中p是第一个频繁项,而P是剩余的频繁项。调用insert_tree([p|P],T)。insert_tree([p|P],T)过程执行情况如下:如果T有子女N使N .item_name=p.item_name,则N的计数增加1;否则创建一个新结点N,将其计数设置为1,链接到它的父结点T,并且通过node_link将其链接到具有相同item_name的结点。如果P非空,递归地调用insert_tree(P,N)。FP-tree是一个高度压缩的结构,它存储了用于挖掘频繁项集的全部信息。FP-tree所占用的内存空间与树的深度和宽度成比例,树的深度一般是单个事务中所含项目数量的最大值;树的宽度是平均每层所含项目的数量。由于在事务处理中通常会存在着大量的共享频繁项,所以树的大小通常比原数据库小很多。频繁项集中的项以支持度降序排列,支持度越高的项与FP-tree的根距离越近,因此有更多的机会共享结点,这进一步保证了FP-tree的高度压缩。
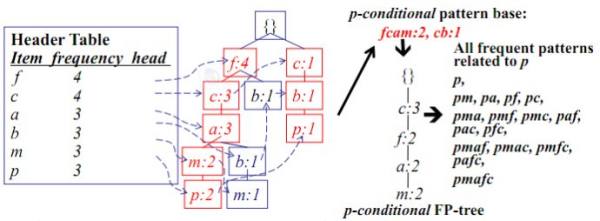
FP并行算法的几个相关方向
1 集群系统中的 FP-tree 并行算法(many for one一个任务 还是 云计算one for many多个任务?)
计算机集群系统利用网络把一组具有高性能的工作站或者 PC 机按一定的结构连接起来, 从而形成了高效的并行的计算处理
系统。 各节点之间使用消息传递实现通信,集群系统通常用于改进单个计算机的计算速度与可靠性。
FP-growth 算法在挖掘每个条件模式库的过程是彼此独立进行的,相互之间没有数据和信息交换。 这一互相独立的特点可以把
FP-growth 算法转换为并行算法,如果将每个条件模式库的挖掘看成一个子任务,那么总的频繁模式挖掘任务就能够被划分为数目
与频繁项数目相等的若干个子任务。
然后将这些子任务分配给计算机集群中的各个节点分别执行,计算机集群的各个节点完成各
自的子任务后,将计算结果传送到中央节点,由中央节点形成统一的计算结果。
2 划分 FP-tree 为小 FP-tree 的并行计算方法
对于给定的关联规则挖掘任务,如何将其分解成多个相互独立的子任务? 从而进行并行分布式处理。 下面将分析的一种方法是
将 FP-tree 划分成小 FP-tree,然后进行并行计算。
需要证明全部局部树的组合和全局树的等价性。
具体方法是:根据 FP-tree 相应的 HeaderTable 各个项前缀路径的总长度,将 Header Table 分组,构造结点数量大致相等的小
FP 树。 构建小 FP 树的方法是,分别提取 Header Table 节点链结点位置,找出对应结点的条件模式基,之后用同一组 Header Table 包
含的所有条件模式基产生出新的 FP 树和 Header Table,在为某部分 Header Table 构造新 FP 树和新 Header Table 时,不用将这部分
Header Table 包含的项以外的项放进新 Header Table。 这样便将大 FP-tree 划分为多个小 FP-tree 方便多进程或多台机器并行处理。
3 划分数据库事务的并行 FP-Growth 算法(基于Hadoop平台,可以自动分布,每个map默认64MB。待续详细。)
在并行 FP-Growth 算法当中,一种算法是将数据库里的记录按照数量进行等分,然后在多个进程上进行并行计算。
该算法基本步骤如下:
1) 划分数据库中的事务,将个数近乎相等的事务指定到相应处理进程;
2) 各进程分别计算项的计数,然后汇总得到频繁 1-项集;
3) 每个处理进程按照分配的事务得到频繁模式树,全局频繁 1-项集列表里的每个项皆由一个结点链和每个局部的 FP-tree 中
的结点相连;
4) 在全局 1-频繁项集列表、多颗局部 FP-tree 以及它们之间的相互连接组成的并行频繁模式树上面 ,进而可以进行并行频繁
模式的挖掘。
以上是关于FP-tree的FP-tree构造算法的主要内容,如果未能解决你的问题,请参考以下文章