docker promethues 的监控部署
Posted 遙遙背影暖暖流星
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了docker promethues 的监控部署相关的知识,希望对你有一定的参考价值。
promethues的简单使用
一,promethues的简介
promethues,即是普罗米修斯监控系统,是一款针对容器运维开发的功能强大的监控的系统
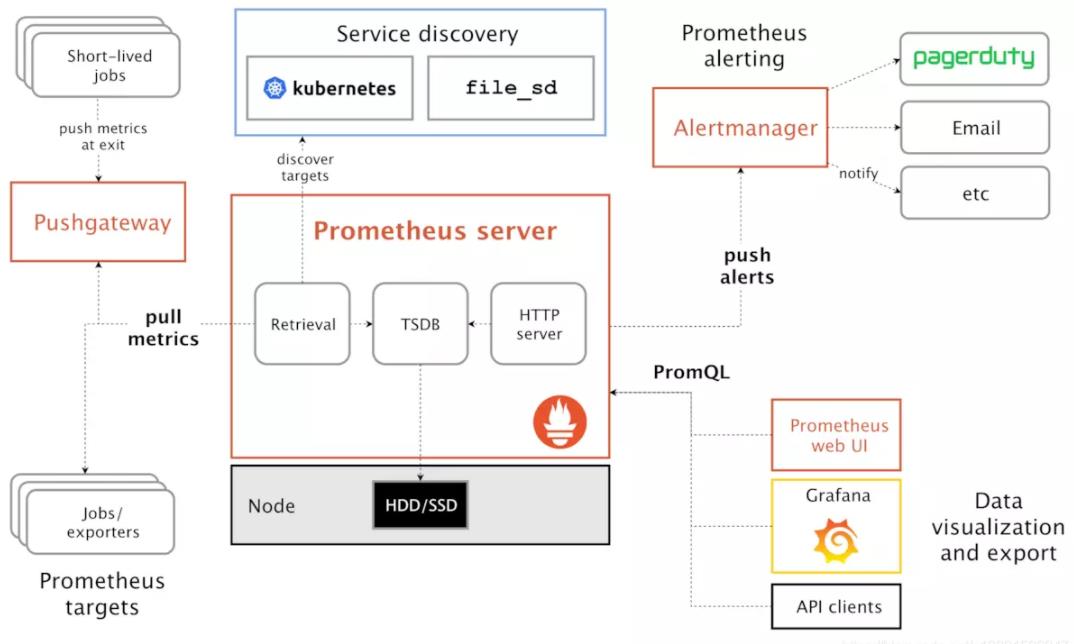
组件:
1、Server:负责定时在目标上抓取 Metrics(指标)数据。
2、Target:暴露一个HTTP服务接口用户Server抓取数据。
3、Exporter:客户端向服务端推送 Metrics 数据,并以 key/value 格式呈现。
4、Pushgateway:服务端自定义抓取数据的脚本,放在被监控的主机,由pushgateway进行推送。
5、AlertManager :接收server推送的告警信息,并触发告警。
6、Grafana:监控数据展示。
exporter指标数据直接由server端pull搜集
pushgateway 指标先通过脚本收集短周期临时的任务数据,push到pushgateway中,再由server端pull获取
Prometheus各组件运行流程如下:
1、Prometheus Server:Prometheus Sever是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储及查询。Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery(服务发现)的斱式劢态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Sever需要对采集到的数据迚行存储,Prometheus Server本身就是一个实时数据库,将采集到的监控数据按照时间序列的斱式存储在本地磁盘当中。Prometheus Server对外提供了自定义的PromQL,实现对数据的查询以及分析。另外Prometheus Server的联邦集群能力可以使其从其他的PrometheusServer实例中获取数据。
2、Exporters:Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可以获取到需要采集的监控数据。可以将Exporter分为2类:(1)、直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。(2)、间接采集:原有监控目标并不直接支持Prometheus,因此需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如:mysql Exporter,JMX Exporter,Consul Exporter等。
3、AlertManager:在Prometheus Server中支持基于Prom QL创建告警规则,如果满足Prom QL定义的规则,则会产生一条告警。常见的接收方式有:电子邮件,webhook 等。
4、PushGateway:Prometheus数据采集基于Prometheus Server从Exporter pull数据,因此当网络环境不允许Prometheus Server和Exporter进行通信时,可以使用PushGateway来进行行中转。
:Prometheus的工作流:
1.Prometheus server定期从配置好的jobs和exporters中拉取metrics,或者接收来自Pushgateway发送过来的metrics,或者从其它的Prometheus server中拉metrics。
2.Prometheus server在本地存储收集到的metrics,并运行定义好的alerts.rules,记录新的时间序列或者向Alert manager推送警报。
3.Alertmanager根据配置文件,对接收到的警报迚行处理,发出告警。
4.在图形界面中,可规化采集数据
1、Metrics
prometheus 监控中 对于采集过来的数据,统一称为 metrics 数据。
Metrics:当我们需要为某个系统某个服务做监控、统计、就要用到 Metrics,Metrics 是一种对采样数据的总称 ( metrics 并不代表某一种具体的数据格式,而是一种对于度量计算单位的抽象)
如:
指标1 http_request_totalstatus="200",method="POST"
指标2 \\__name__="http_request_total",status="200",methos="POST"
HTTP请求状态的总和 status 值 200,代表状态为 200
Metric类型:
Counter: 一种累加的metric,如请求的个数,结束的任务数,出现的错误数等
Gauge: 常规的metric,如温度,可任意加减。其为瞬时的,与时间没有关系的,可以任意变化的数据。
Histogram: 柱状图,用于观察结果采样,分组及统计,如:请求持续时间,响应大小。其主要用于表示一段时间内对数据的采样,并能够对其指定区间及总数进行统计。根据统计区间计算
Summary: 类似Histogram,用于表示一段时间内数据采样结果,其直接存储quantile数据,而不是根据统计区间计算出来的。不需要计算,直接存储结果
2、key/value
Metrics 是数据逻辑的概念,包含多种数据类型
Key / Value 是数据具体的格式,供用户使用查看
process_max_fas 65535
process_open_fds 10
##第一个代表的是 当前采集的 最大文件句柄 65535
第二个代表的是 当前采集的 被打开的文件句柄 10
如:一个 exporter 给我们采集来的服务器上 key/value 形式的 Metrics 数据
当一个 node_exporter 被安装和运行在被监控的服务器上后
使用简单的 curl命令 就可以看到 exporter 帮我们采集到的 metrics 数据的样子,以 key/value 形式展现和保存。curl localhost:9100/metrics9100 exporter 默认端口号
3、时序数据
prometheus存储的是时序数据,即按相同时序(相同名称和标签),以时间维度存储连续的数据的集合。
时序(time series)是由名字(Metric)以及一组key/value标签定义的,具有相同的名字以及标签属于相同时序。
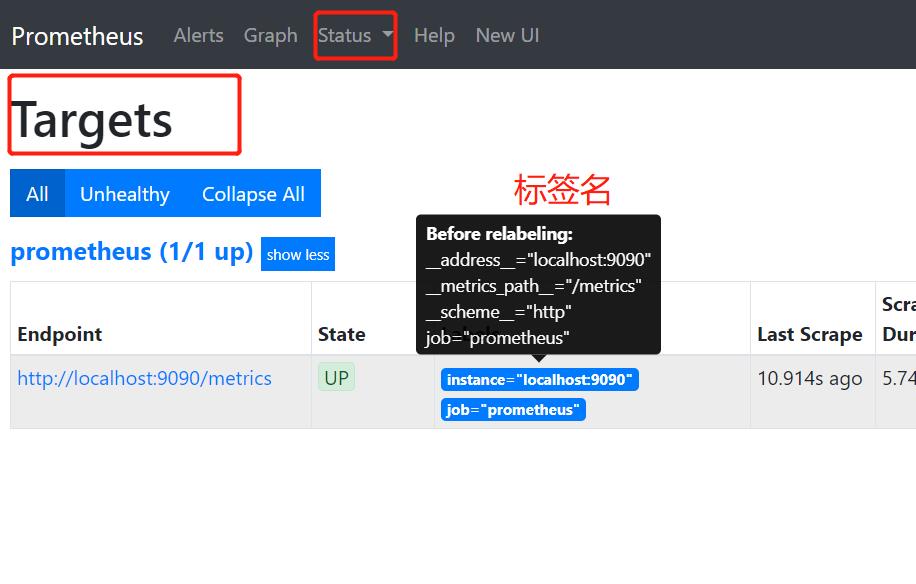
4、标签与样本
标签:使同一个时间序列有了不同维度的识别。例如 httprequests_totalmethod=”Get” 表示所有 http 请求中的 Get 请求。当 method=”post” 时,则为新的一个 metric。标签中的键由 ASCII 字符,数字,以及下划线组成,且必须满足正则表达式 [a-zA-Z:][a-zA-Z0-9_:]*。
样本:按照某个时序以时间维度采集的数据,称之为样本。实际的时间序列,每个序列包括一个float64的值和一个毫秒级的时间戳
一个 float64 值
一个毫秒级的 unix 时间戳
格式:Prometheus时序格式与OpenTSDB相似
=,…,例如:http_requests_totalmethod=”POST”,endpoint=”/api/tracks”。
5、instance 和 jobs
instance: 一个单独 scrape 的目标, 一般对应于一个进程。
jobs: 一组同种类型的 instances(主要用于保证可扩展性和可靠性),例如:
job: api-server
instance 1: 1.2.3.4:5670
instance 2: 1.2.3.4:5671
instance 3: 5.6.7.8:5670
instance 4: 5.6.7.8:5671
二、promethues的安装部署
实验环境
prometheus 192.168.100.21 prometheus-2.27.1.linux-amd64.tar.gz
node1 192.168.100.22 node_exporter-1.1.2.linux-amd64.tar.gz
node2 192.168.100.5 node_exporter-1.1.2.linux-amd64.tar.gz
node3 192.168.100.6 node_exporter-1.1.2.linux-amd64.tar.gz
做好时间同步 ntpdate ntp.aliyun.com
1、安装promethues server
.解压安装包
tar zxvf prometheus-2.27.1.linux-amd64.tar.gz -C /usr/local
#默认配置文件
cd /usr/local/
mv prometheus-2.27.1.linux-amd64/ prometheus-2.27.1
cd prometheus-2.27.1
cat prometheus.yml
[root@prometheus prometheus-2.27.1]# cat prometheus.yml
# my global config #全局设置
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. #每隔多久抓取一次指标,不设置默认1分钟
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. #内置告警规则的评估周期
# scrape_timeout is set to the global default (10s). #收集指标间隔过期时间
# Alertmanager configuration #告警模块设置
alerting:
alertmanagers:
- static_configs: #静态配置
- targets:
# - alertmanager:9093 #端口
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: #告警规则
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs: #刮擦数据,采集
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' #名称
# metrics_path defaults to '/metrics' #默认数据展示路径
# scheme defaults to 'http'. #http方式
static_configs:
- targets: ['localhost:9090']
[root@prometheus prometheus-2.13.1]#
登陆192.168.100.21:9090,web表达式游览器
登陆192.168.100.21:9090/metrics,可以支持的指标数据类型,

复制任意一个指标类型进行搜索
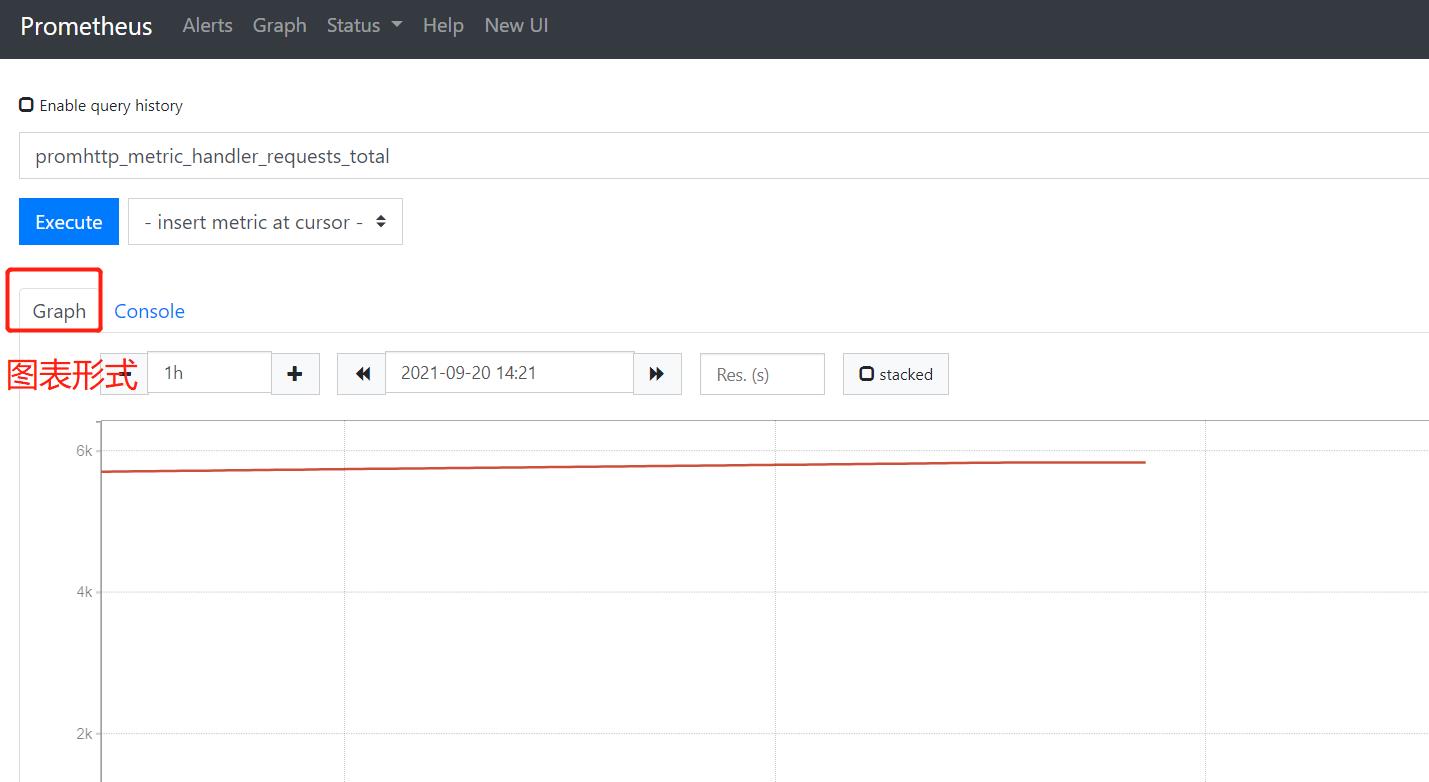
选择图标形式,生成图标
2、安装exporter
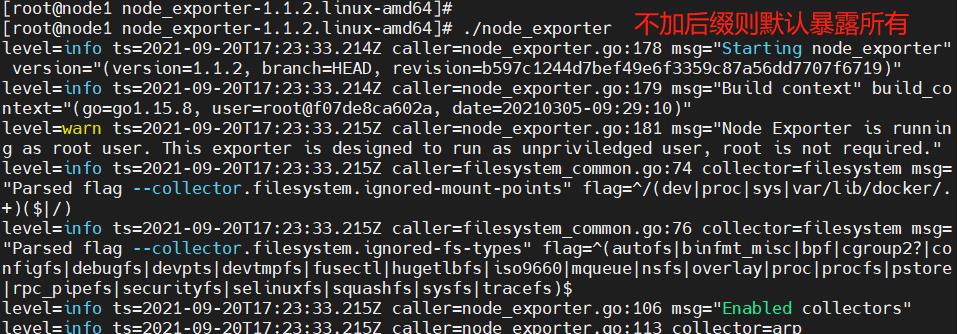
在node1上
解压安装包,命令优化路径,设置服务控制,开启服务
tar zxvf node_exporter-1.1.2.linux-amd64.tar.gz
cd node_exporter-1.1.2.linux-amd64
cp node_exporter /usr/local/bin #f复制命令让系统可以识别
上传数据包再解压
[root@node1 ~]# ls
anaconda-ks.cfg node_exporter-1.1.2.linux-amd64
compose_tomcat node_exporter-1.1.2.linux-amd64.tar.gz
[root@node1 ~]# cd node_exporter-1.1.2.linux-amd64/
[root@node1 node_exporter-1.1.2.linux-amd64]#]# cp node_exporter /usr/local/bin
[root@node1 node_exporter-1.1.2.linux-amd64]# ./node_exporter
登陆node节点192.168.100.22:9100可以看到页面

其他exporter暴露器
(1)在promethues官网下载各类型exporter
(2)通过github官网,克隆数据代码到本地
yum install -y git*
git clone https://github.com/prometheus/node_exporter.git
3、将node节点加到server中
netstat -nautp | grep prometheus
killall -9 prometheus
vim /usr/local/prometheus-2.27.1.linux-amd64/prometheus.yml
-----最后一行添加------
- job_name: ‘nodes’
static_configs:- targets:
- 192.168.100.22:9100
- 192.168.100.5:9100
- 192.168.100.6:9100
——>wq
./prometheus
- targets:
#显示node节点状态

4、在其他两个node节点安装exporter
同样的操作
tar zxvf node_exporter-1.1.2.linux-amd64.tar.gz
cd node_exporter-1.1.2.linux-amd64/
cp node_exporter /usr/local/bin
./node_exporter
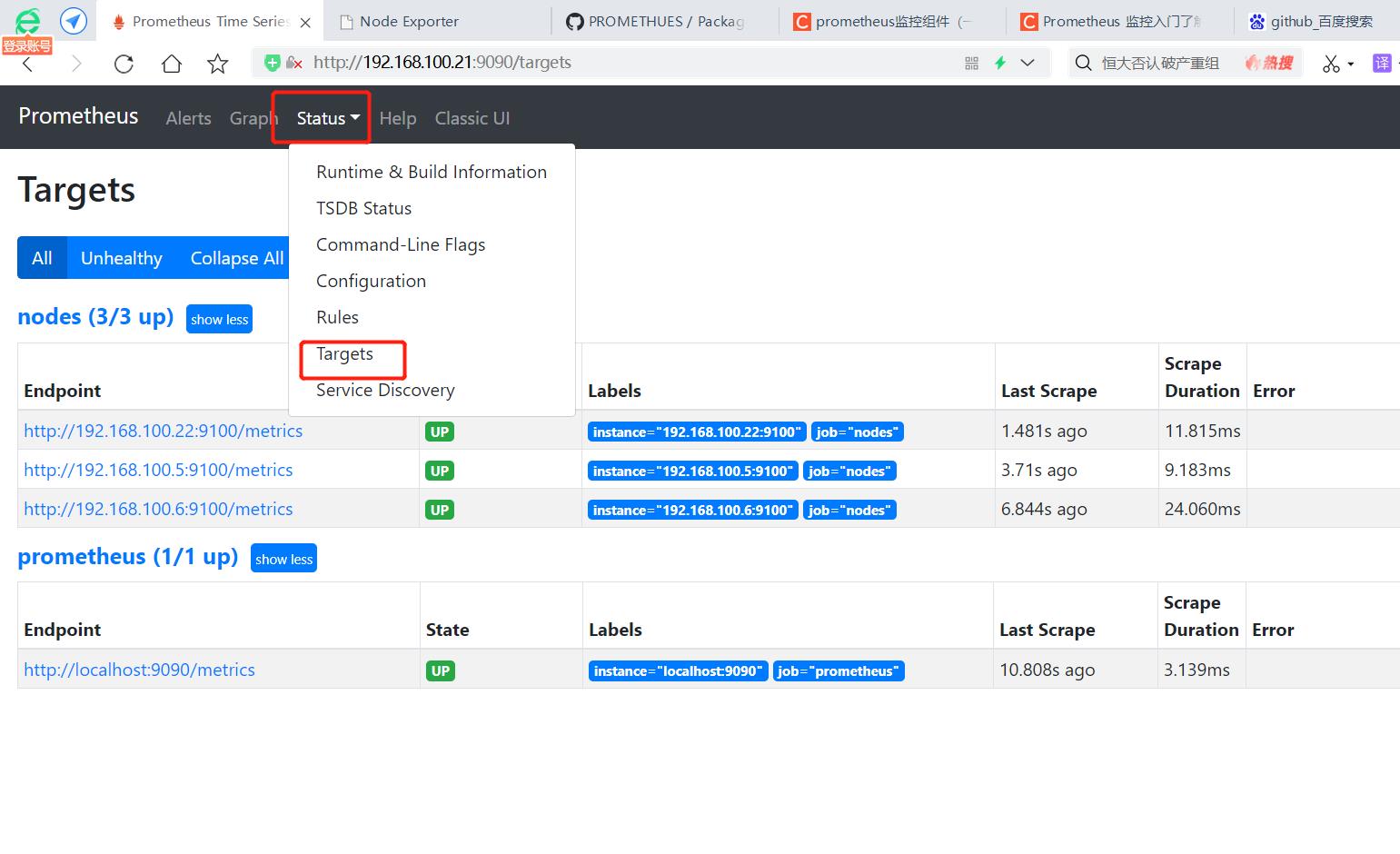
#登陆http://192.168.100.21:9090/targets
可以看到所有节点已经开启
5、表达式浏览器(promQL 过滤使用)
2、表达式浏览器常规使用
在prometheusUI控制台上可以进行数据过滤
####简单的用法:
#CPU使用总量
node_cpu_seconds_total
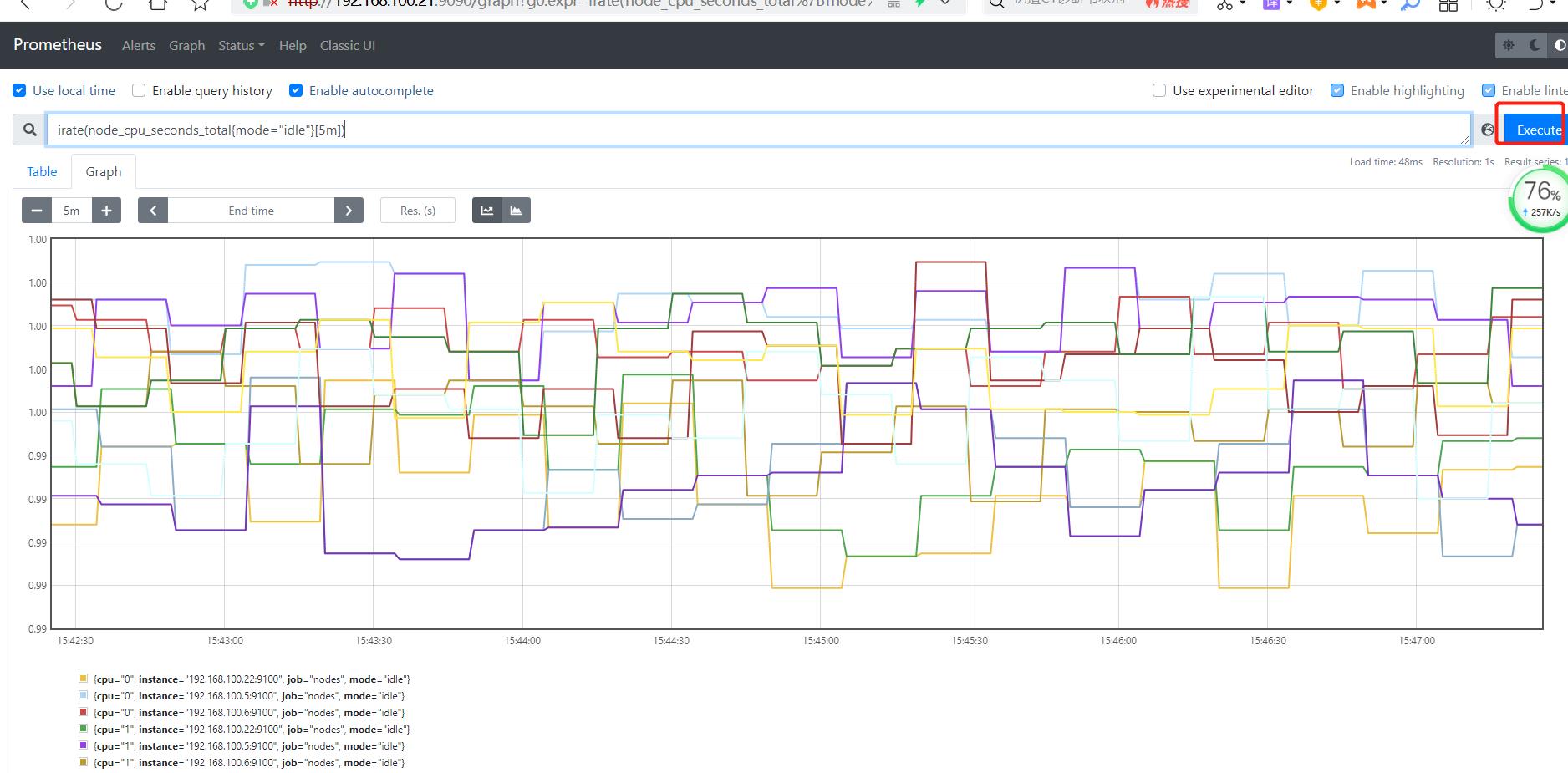
#进阶1:
计算过去5分钟内的CPU空闲速率
PromQL: irate(node_cpu_seconds_totalmode="idle"[5m])
解析:
irate:速率计算函数(灵敏度非常高)
node_cpu_seconds_total:node节点CPU使用总量(指标)
mode="idle" 空闲指标(标签)
5m:过去的5分钟内,所有CPU空闲数的样本值,每个数值做速率运算
mode="idle" :整体称为标签过滤器
#进阶2:
每台主机CPU 在5分组内的平均使用率
PromQL:(1- avg (irate(node_cpu_seconds_totalmode='idle'[5m]))by (instance))* 100
解析
avg:平均值
avg (irate(node_cpu_seconds_totalmode='idle'[5m]):可以理解为CPU空闲量的百分比
by (instance):表示的是所有节点
(1- avg (irate(node_cpu_seconds_totalmode='idle'[5m]))by (instance))* 100:CPU 5分钟内的平均使用率
其他常用的指标:
1、查询1分钟平均负载
node_load1 > on (instance) 2 * count (node_cpu_seconds_totalmode='idle') by(instance)
node_load5
node_load15
1、5、15分钟的cpu负载
一般来说以上的值不能长时间大于CPU核心数量
top
查询指定CPU使用率
2、内存使用率
node_memory_MemTotal_bytes
node_memory_MemFree_bytes
node_memory_Buffers_bytes
node_memory_Cached_bytes
计算使用率:
可用空间:以上后三个指标之和
已用空间:总空间减去可用空间
使用率:已用空间除以总空间
以上是关于docker promethues 的监控部署的主要内容,如果未能解决你的问题,请参考以下文章