用梯度下降的方式来拟合曲线
Posted 1037号森林里一段干木头
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用梯度下降的方式来拟合曲线相关的知识,希望对你有一定的参考价值。
文章目录
1. 简述
在之前的一篇文章opencv C++ 曲线拟合中为了拟合一条二次曲线,用超定方程的理论转为求最小二乘的方式来做,这是一个解析的方式求的解,也是全局最优的解。在深度学习中学到的函数是非常复杂的,不能保证是凸的,也没办法从解析的角度来计算一个最优解,这时最有效常用的方法就是梯度下降,为了加深对梯度下降的理解,所以这里以梯度下降来拟合多项式函数来探索一下。
2. 理论原理
以二次函数为例
设函数为 f ( x ) = a 0 + a 1 x + a 2 x 2 f(x)=a_0+a_1x+a_2x^2 f(x)=a0+a1x+a2x2,确定一组 a 0 , a 1 , a 2 a_0,a_1,a_2 a0,a1,a2的值,也就确定了二次函数,所以可以认为一组 a 0 , a 1 , a 2 a_0,a_1,a_2 a0,a1,a2值就是一个模型了。
样本为
(
x
,
y
)
(x,y)
(x,y),
y
^
\\haty
y^为模型的预测值,要评价一个模型好不好,我们可以用残差总和(loss)来表示,残差总和越小,模型越好。那我们的目标就是找一组
a
0
,
a
1
,
a
2
a_0,a_1,a_2
a0,a1,a2的值,使得下面的式子:
l
o
s
s
=
Σ
i
=
1
N
∥
y
i
−
y
i
^
∥
2
2
loss = \\Sigma_i=1^N\\|y_i - \\haty_i \\|_2^2
loss=Σi=1N∥yi−yi^∥22
最小即可。虽然在很多场合都会用MSE均方误差来做损失函数,但是为了方便手动计算梯度,就不用MSE了,两者回归出来的最优值是一样的。
设
W
=
[
a
0
a
1
a
2
]
W = \\beginbmatrix a_0 \\\\ a_1 \\\\ a_2 \\endbmatrix
W=
a0a1a2
,
Z
=
[
1
x
x
2
]
Z = \\beginbmatrix 1 \\\\ x \\\\ x^2 \\endbmatrix
Z=
1xx2
,则
f
(
x
)
f(x)
f(x)可以写为
f
(
x
)
=
W
T
Z
f(x)=W^TZ
f(x)=WTZ
整体的梯度下降步骤:
- 初始化权重W
直接随机初始化 - 计算拟合损失
对每一组数据 z i z_i zi, y i y_i yi in (Z,Y), l o s s i = ( y i − y i ^ ) 2 = ( y i − W T z i ) 2 = ( y i − ( w 1 z i 1 + w 2 z i 2 + w 3 z i 3 ) ) 2 loss_i =(y_i-\\hat y_i)^2 = (y_i - W^T z_i)^2 = (y_i - (w_1z_i1 + w_2z_i2 + w_3z_i3))^2 lossi=(yi−yi^)2=(yi−WTzi)2=(yi−(w1zi1+w2zi2+w3zi3))2
l
o
s
s
i
loss_i
lossi对
W
W
W的梯度就是
∇
=
[
−
2
(
y
i
−
(
w
1
z
i
1
+
w
2
z
i
2
+
w
3
z
i
3
)
z
i
1
−
2
(
y
i
−
(
w
1
z
i
1
+
w
2
z
i
2
+
w
3
z
i
3
)
z
i
2
−
2
(
y
i
−
(
w
1
z
i
1
+
w
2
z
i
2
+
w
3
z
i
3
)
z
i
3
]
\\nabla = \\beginbmatrix -2(y_i - (w_1z_i1 + w_2z_i2 + w_3z_i3)z_i1 \\\\ -2(y_i - (w_1z_i1 + w_2z_i2 + w_3z_i3)z_i2 \\\\ -2(y_i - (w_1z_i1 + w_2z_i2 + w_3z_i3)z_i3 \\endbmatrix
∇=
−2(yi−(w1zi1+w2zi2+w3zi3)zi1−2(yi−(w1zi1用梯度下降做点小实验
赶在国庆回家前做点小实验==
利用梯度下降法去拟合任意你想拟合的东西,哈哈
自己想出来的曲线:
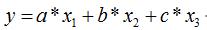
目标函数:
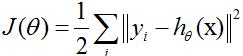
其中:
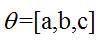 ,
,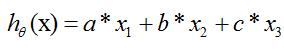
然后计算迭代式:

其中:
k表示第k次迭代,
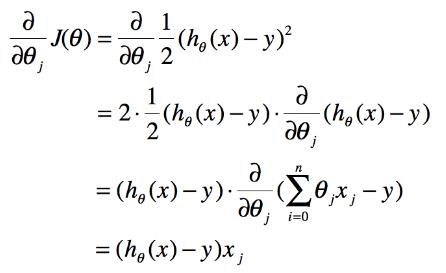
至此,有了梯度方向就可以计算啦,附上c++代码:
#include<iostream>
#include<vector>
#include<ctime>
using namespace std;
int main() {
//产生数据
srand(time(NULL));
vector<vector<double>> x(5,vector<double>(3,0.0));
for (int i = 0; i < 5; i++) {
for (int j = 0; j < 3; j++) {
x[i][j] = rand() % 10+1;
//cout << x[i][j] << " ";
}
//cout << ",";
}
//double *y = new double[5];
double y[5];
for (int i = 0; i < 5; i++) {
y[i] = 3 * x[i][0] + 5 * x[i][1] - 7 * x[i][2] + double((rand() % 7)) / 10;
// cout << y[i] << endl;
}
double a=0.0,b=0.0,c=0.0,
aa=0.0,bb=0.0,cc=0.0;
double diff;
double error=0,error1=0;
int itertornum = 0;//记录迭代次数
while (1) {
itertornum++;
for (int i = 0; i < 5; i++) {
cout << "第"<<itertornum<<"次迭代:"<<aa << "," << bb << "," << cc << "," << endl;
diff = y[i] - (a*x[i][0] + b*x[i][1] + c*x[i][2]);
aa = aa + 0.001*diff*x[i][0];
bb = bb + 0.001*diff*x[i][1];
cc = cc + 0.001*diff*x[i][2];
}
a = aa; b = bb; c = cc;//更新状态量
error = 0;
for (int i = 0; i < 5; i++) {
error += 0.5*(pow(y[i] - (a*x[i][0] + b*x[i][1] + c*x[i][2]), 2));
}
if (abs(error - error1) < 1e-5) {
break;
}
else {
error1 = error;
}
}
cout << "最终结果是:" << a <<","<< b<<"," << c<<endl;
system("pause");
return 0;
}
以上是关于用梯度下降的方式来拟合曲线的主要内容,如果未能解决你的问题,请参考以下文章