图神经网络汇总和总结
Posted KPer_Yang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图神经网络汇总和总结相关的知识,希望对你有一定的参考价值。
下面所有博客是个人对EEG脑电的探索,项目代码是早期版本不完整,需要完整项目代码和资料请私聊。
数据集
1、脑电项目探索和实现(EEG) (上):研究数据集选取和介绍SEED
相关论文阅读分析:
1、EEG-SEED数据集作者的—基线论文阅读和分析
2、图神经网络EEG论文阅读和分析:《EEG-Based Emotion Recognition Using Regularized Graph Neural Networks》
3、EEG-GNN论文阅读和分析:《EEG Emotion Recognition Using Dynamical Graph Convolutional Neural Networks》
4、论文阅读和分析:Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification
5、论文阅读和分析:《DeepGCNs: Can GCNs Go as Deep as CNNs?》
6、论文阅读和分析: “How Attentive are Graph Attention Networks?”
7、论文阅读和分析:Simplifying Graph Convolutional Networks
8、论文阅读和分析:LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
9、图神经网络汇总和总结
相关实验和代码实现:
1、用于图神经网络的脑电数据处理实现_图神经网络 脑电
2、使用GCN训练和测试EEG的公开SEED数据集
3、使用GAT训练和测试EEG公开的SEED数据集
4、使用SGC训练和测试SEED数据集
5、使用Transformer训练和测试EEG的公开SEED数据集_eeg transformer
6、使用RGNN训练和测试EEG公开的SEED数据集
辅助学习资料:
1、官网三个简单Graph示例说明三种层次的应用_graph 简单示例
2、PPI数据集示例项目学习图神经网络
3、geometric库的数据处理详解
4、NetworkX的dicts of dicts以及解决Seven Bridges of Königsberg问题
5、geometric源码阅读和分析:MessagePassin类详解和使用
6、cora数据集示例项目学习图神经网络
7、Graph 聚合
8、QM9数据集示例项目学习图神经网络
9、处理图的开源库
回顾一下以前看过的图神经网络的综述:
注:看综述主要看对领域相关的分类和发展脉络,综述不会对每一种算法有详细叙述,看详细算法需要在脉络中找到自己合适的部分进行详读。
图类型:
不同的图类型,对应有不同的算法去解决相关问题;
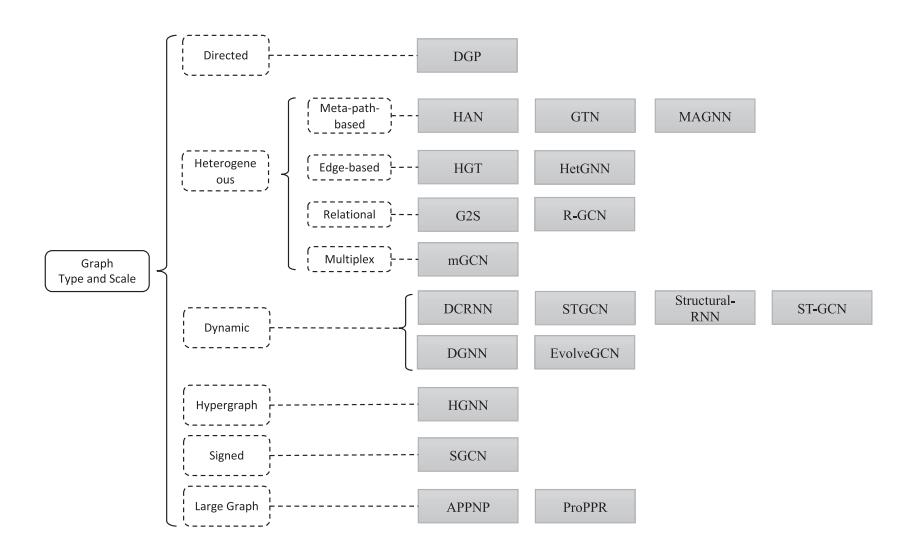
An overview of variants considering graph type and scale.
注意,这些类别是正交的,这意味着这些类型可以组合,例如,可以处理动态有向异构图。还有一些其他的图类型是为不同的任务设计的,比如超图和有符号图。这里我们不会列举所有类型,但最重要的想法是考虑这些图提供的附加信息。一旦我们指定了图形类型,在设计过程中就应该进一步考虑这些图形类型所提供的附加信息。
| 图类型 | |
|---|---|
| Undirected/Directed | 有向图中的边都是从一个节点定向到另一个节点,这比无向图提供了更多的信息。无向图中的每条边也可以看作是两条有向边. |
| Homogeneous/Heterogeneous | 同构图中的节点和边具有相同的类型,而异构图中的节点和边具有不同的类型. |
| Dynamic | 当输入特征或图的拓扑结构随时间变化时,将图视为动态图。在动态图中应考虑时间信息。 |
| Hypergraph | 超图可以被表示成 G = ( V , E , W e ) G=(V,E,W_e) G=(V,E,We),边 e ∈ E e \\in E e∈E,连接着两个或者更多的顶点,并且被分配一个权重 w ∈ W e w \\in W_e w∈We.邻接矩阵是一个$ |
| Signed | 有符号图是有符号边的图,即边可以是正的也可以是负的。SGCN (Derr等人,2018)没有简单地将负边视为缺失边或另一种类型的边,而是利用平衡理论来捕获正边和负边之间的相互作用。直观地说,平衡理论认为,我朋友的朋友(正面边)也是我的朋友,我敌人的敌人(负面边)也是我的朋友。为SGCN模拟正边和负边之间的相互作用提供了理论基础。 |
| Large Graph | 大规模图.“小”图和“大”图并没有明确的分类标准。该标准仍在随着计算设备的发展而变化(例如gpu的速度和内存)。在本文中,当一个图(空间复杂度为 O ( n 2 ) O(n^2) O(n2))的邻接矩阵或图拉普拉斯数不能被设备存储和处理时,我们将图视为一个大尺度图,这时需要考虑一些采样方法. |
Dynamic补充说明:图的结构,例如边和节点,随着时间不断变化。为了将图结构数据与时间序列数据一起建模,DCRNN (Li et al., 2018b)和STGCN (Yu et al., 2018)首先通过gnn收集空间信息,然后将输出输入序列模型,如序列到序列模型或RNNs。不同的是,structure - rnn (Jain et al., 2016)和ST-GCN (Yan et al., 2018)同时收集空间和时间信息。他们用时间连接扩展静态图结构,从而可以将传统gnn应用于扩展图。类似地,DGNN (Manessi et al., 2020)将GCN中每个节点的输出嵌入馈送到单独的lstm中。每个节点共享lstm的权值。另一方面,EvolveGCN (Pareja et al., 2020)认为,直接对节点表示的动态建模将阻碍模型在节点集不断变化的图上的性能。因此,它不是将节点特征作为RNN的输入,而是将GCN的权重输入到RNN中,以捕获图交互的内在动态。最近,一项研究(Huang et al., 2020)根据链路持续时间将动态网络分为几类,并根据现有模型的专业化将其分组。建立了动态图模型的总体框架,并将现有模型纳入总体框架。
设计损失函数
根据不同的任务类型设计损失函数:
| Task | |
|---|---|
| Node-level | 节点级任务以节点为中心,包括节点分类、节点回归、节点聚类等。节点分类试图将节点分类为几个类,节点回归预测每个节点的连续值。节点聚类的目的是将节点划分为几个不相连的组,其中相似的节点应该在同一个组中。 |
| Edge-level | 任务是边分类和链路预测,这需要模型对边类型进行分类或预测两个给定节点之间是否存在边。 |
| Graph-level | 任务包括图分类、图回归和图匹配,所有这些都需要模型学习图表示。 |
根据监督进行分类:
| Type | |
|---|---|
| Supervised setting | 提供有标签数据 |
| Semi supervised setting | 给出少量的标记节点和大量的未标记节点用于训练。在测试阶段,transductive setting要求模型预测给定未标记节点的标签,而inductive setting提供来自相同分布的新的未标记节点进行推断。大多数节点和边缘分类任务都是半监督的。 |
| Unsupervised setting | 仅为模型提供未标记的数据以查找模式。节点聚类是典型的无监督学习任务。 |
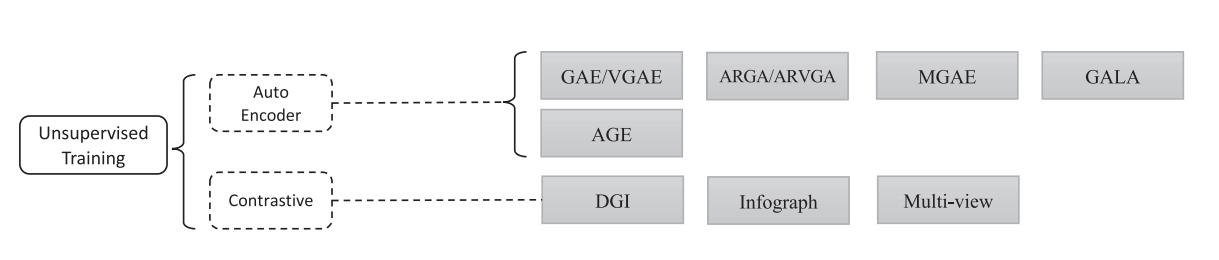
Unsupervised setting训练的分类:
神经网络模块:
传播模块、采样模块、池化模块是图的三个神经网络组成模块;
传播模块:用于在节点之间传播信息,以便聚合的信息可以捕获特征和拓扑信息。在传播模块中,卷积算子和循环算子通常用于聚集来自邻居的信息,而跳跃连接操作用于从节点的历史表示中收集信息,并缓解过平滑问题;
采样模块:当图很大时,通常需要采样模块在图上进行传播。采样模块通常与传播模块结合在一起;
池化模块:需要高层次子图或图的表示时,需要池化模块从节点中提取信息;
一个GNN的通常表示:
GNN模型的典型架构如图2的中间部分所示,使用卷积算子、循环算子、采样模块和跳跃连接在每一层传播信息,然后加入池化模块提取高层次信息。这些层通常被堆叠以获得更好的表示。注意,这种架构可以推广大多数GNN模型,但也有例外,例如NDCN (Zang and Wang, 2020)结合了常微分方程系统(ode)和GNN。
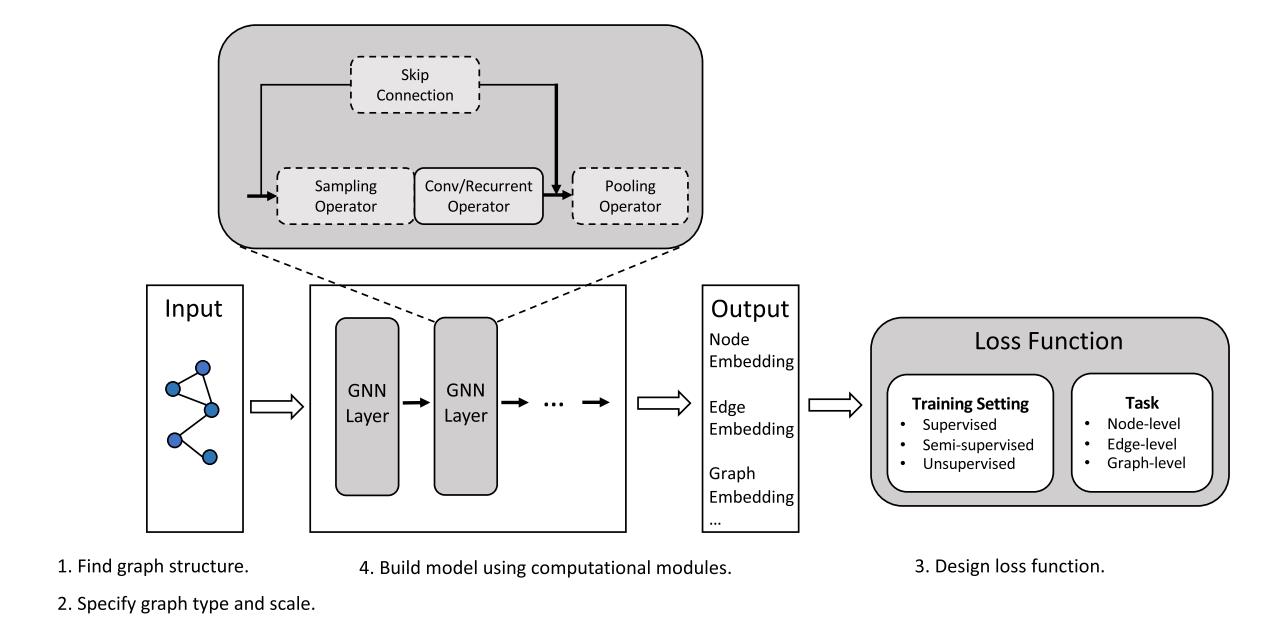
Fig. 2. The general design pipeline for a GNN model
传播模块:
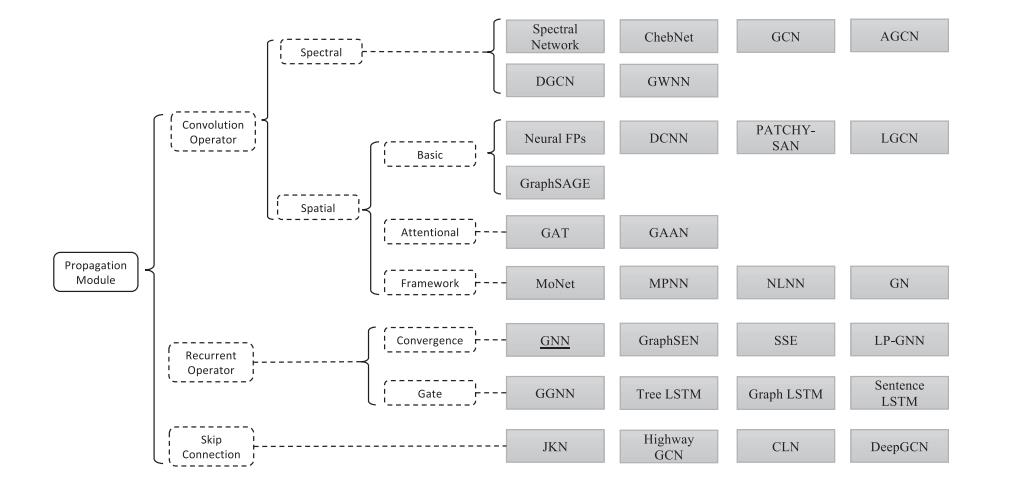
| 算子类型 | |
|---|---|
| convolution operator | 卷积算子分为谱方法和空间方法。 |
| recurrent operator | 循环算子和卷积算子之间的主要区别是卷积算子中的层使用不同的权值,而循环算子中的层共享相同的权值。 |
| skip connect | 许多应用程序展开或堆叠图神经网络层,目的是获得更好的结果,因为更多的层(即k层)使每个节点聚集更多来自邻居k-skip的信息。然而,在许多实验中观察到,更深入的模型并不能提高性能,甚至可能表现得更差。这主要是因为更多的层也可以从指数增长的扩展邻域成员中传播噪声信息。同时,因为当模型深入时,节点在聚合操作后倾向于具有类似的表示,还会导致过度平滑问题。因此,许多方法都试图添加“skip connect”来使GNN模型更深。 |
采样模块:

GNN模型从上一层的邻域聚集每个节点的消息。直观地,如果我们回溯多个GNN层,支持邻居的大小将随着深度呈指数增长。为了缓解这种“邻居爆炸”问题,一个有效的方法就是抽样。此外,当我们处理大型图时,我们不能总是存储和处理每个节点的所有邻域信息,因此需要采样模块来进行传播。三种图采样模块:节点采样、层采样和子图采样.
| 采样模块 | |
|---|---|
| Node sampling | 减少相邻节点大小的一种直接方法是从每个节点的邻域中选择一个子集。 |
| Layer sampling | 层抽样不是对每个节点的邻居进行抽样,而是在每层中保留一小组节点进行聚合,以控制扩展因子。 |
| Subgraph sampling | 不同于在完整图的基础上对节点和边进行采样,一种根本不同的方法是对多个子图进行采样,并将邻域搜索限制在这些子图内。 |
Node sampling: GraphSAGE (Hamilton et al., 2017a)对固定数量的邻居进行采样,确保每个节点的邻居大小为2到50个。为了减少采样方差,Chen等人(2018a)利用节点的历史激活作为控制变量,引入了一种基于控制变量的GCN随机逼近算法。该方法将接受域限制在1跳附近,并使用历史隐藏状态作为一个可负担的近似。PinSage (Ying et al., 2018a)提出了基于重要性的抽样方法。通过模拟从目标节点开始的随机行走,该方法选择规范化访问次数最高的top T节点。
Layer sampling:FastGCN (Chen et al., 2018b)直接对每一层的接受野进行采样。它使用重要性抽样,其中重要节点更有可能被抽样。与上述固定采样方法相比,Huang等人(2018)引入了一种参数化和可训练的采样器,以前一层为条件进行分层采样。此外,该自适应采样器在优化抽样重要性的同时降低了方差。LADIES (Zou等人,2019)打算通过从节点的邻居并集中生成样本来缓解分层采样中的稀疏性问题.
Subgraph sampling:ClusterGCN (Chiang et al., 2019)通过图聚类算法对子图进行采样,而GraphSAINT (Zeng et al., 2020)则直接对节点或边进行采样以生成子图
池化模块:

在计算机视觉领域,卷积层之后通常是池化层,以获得更多的一般特征。复杂且大规模的图通常具有丰富的层次结构,这对于节点级和图级分类任务具有重要意义。与这些池化层类似,很多工作都侧重于在图上设计分层池化层。两种池化模块:直接池化模块和分层池化模块。
| 池化模块 | |
|---|---|
| Direct pooling modules | 直接池化模块直接从具有不同节点选择策略的节点学习graph-level表示。这些模块在某些变体中也称为读出函数。Simple Node Pooling、Set2set、SortPooling |
| Hierarchical pooling modules | 前面提到的方法直接从节点学习图表示,它们不研究图结构的层次结构。Hierarchical pooling modules遵循分层池模式并按层学习图形表示的方法。Graph Coarsening、Edge-Conditioned Convolution (ECC) 、gPool、EigenPooling、SAGPool。 |
参考:
1、图神经网络(GNN)模型原理及应用综述_图神经网络模型_的博客-CSDN博客
2、《Graph neural networks: A review of methods and applications》
计算机网络知识点汇总
个人博客欢迎访问
总结不易,如果对你有帮助,请点赞关注支持一下
OSI七层协议模型
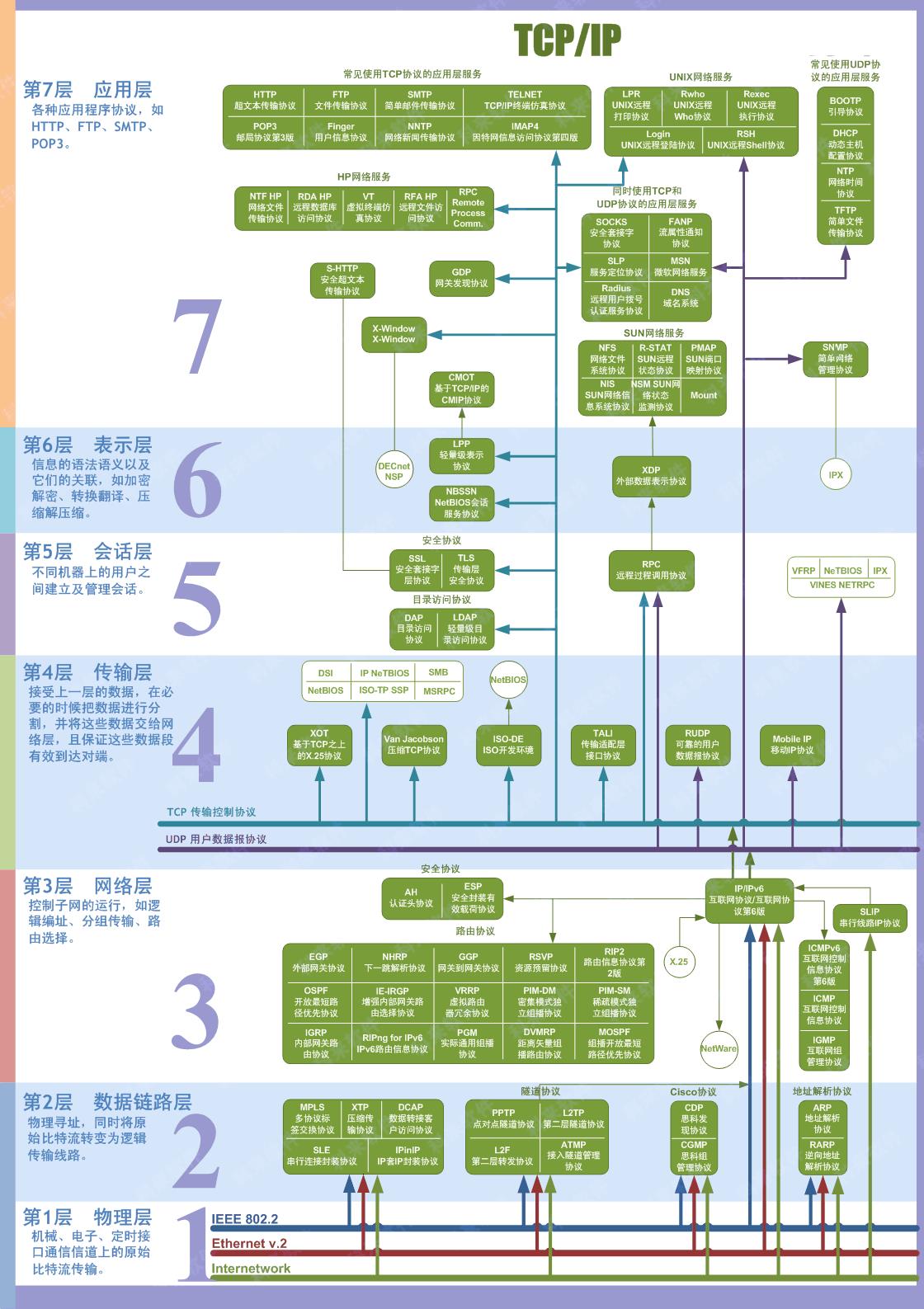

- TCP/IP是一个四层的体系结构,主要包括:应用层、运输层、网际层和网络接口层。
- 五层协议的体系结构主要包括:应用层、运输层、网络层,数据链路层和物理层。
- OSI七层协议模型主要包括是:应用层(Application)、表示层(Presentation)、会话层(Session)、运输层(Transport)、网络层(Network)、数据链路层(Data Link)、物理层(Physical)
为什么要对网路协议进行分层
- 简化问题难度和复杂度。由于各层之间独立,我们可以分割大问题为小问题
- 灵活性好。当其中一层的技术变化时,只要层间接口关系保持不变,其他层不受影响
- 易于实现和维护
- 促进标准化工作。分开后,每层功能可以相对简单地被描述
网络协议分层的缺点: 功能可能出现在多个层里,产生了额外开销
五层协议的体系结构只是为了介绍网络原理而设计的,实际应用还是 TCP/IP 四层体系结构
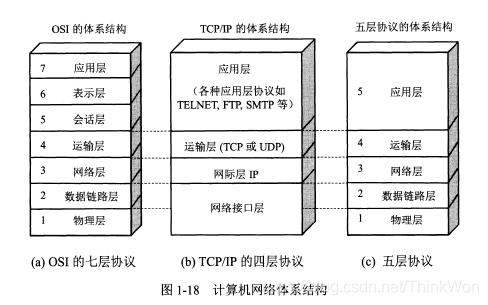
TCP/IP协议族
TCP(传输控制协议)和IP(网际协议) 是最先定义的两个核心协议,所以才统称为TCP/IP协议族
应用层
应用层的任务是通过应用进程间的交互来完成特定网络应用,应用层协议定义的是应用进程间的通信和交互规则
对于不同的网络应用需要不同的应用层协议,在互联网中应用层协议很多,如域名系统 DNS,支持万维网应用的 HTTP 协议,支持电子邮件的 SMTP 协议、FTP协议等等
DNS
域名系统(Domain Name System,Domain Name被译为域名)是因特网的一项核心服务,它作为可以将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。(百度百科)例如:一个公司的 Web 网站可看作是它在网上的门户,而域名就相当于其门牌地址,通常域名都使用该公司的名称或简称。例如上面提到的微软公司的域名,类似的还有:IBM 公司的域名是 www.ibm.com、Oracle 公司的域名是 www.oracle.com、Cisco公司的域名是 www.cisco.com 等
HTTP
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW(万维网) 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法
运输层
运输层的主要任务是负责两台主机进程之间的通信提供的数据传输服务,应用进程利用该服务传送应用层报文
运输层主要使用一下两种协议
- 传输控制协议-TCP:提供面向连接的,可靠的数据传输服务
- 用户数据协议-UDP:提供无连接的,尽最大努力的数据传输服务(不保证数据传输的可靠性)
TCP
- TCP 是面向连接的。(就好像打电话一样,通话前需要先拨号建立连接,通话结束后要挂机释放连接)
- 每一条 TCP 连接只能有两个端点,每一条TCP连接只能是点对点的(一对一)
- TCP 提供可靠交付的服务。通过TCP连接传送的数据,无差错、不丢失、不重复、并且按序到达
- TCP 提供全双工通信。TCP 允许通信双方的应用进程在任何时候都能发送数据。TCP 连接的两端都设有发送缓存和接收缓存,用来临时存放双方通信的数据
- 面向字节流。TCP 中的“流”(Stream)指的是流入进程或从进程流出的字节序列。“面向字节流”的含义是:虽然应用程序和 TCP 的交互是一次一个数据块(大小不等),但 TCP 把应用程序交下来的数据仅仅看成是一连串的无结构的字节流
UDP
- UDP 是无连接的;
- UDP 使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的链接状态(这里面有许多参数);
- UDP 是面向报文的;
- UDP 没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如 直播,实时视频会议等);
- UDP 支持一对一、一对多、多对一和多对多的交互通信;
- UDP 的首部开销小,只有8个字节,比TCP的20个字节的首部要短。
TCP和UDP的区别
| TCP | UDP | |
|---|---|---|
| 是否连接 | 面向连接 | 无连接 |
| 是否可靠 | 可靠传输,使用流量控制和拥塞控制 | 不可靠传输,不使用流量控制和拥塞控制 |
| 连接对象的个数 | 只能是一对一通信 | 支持一对一,一对多,多对一和多对多交互通信 |
| 传输方式 | 面向字节流 | 面向报文 |
| 首部开销 | 首部最小20字节,最大60字节 | 首部开销小,仅8字节 |
| 场景 | 可靠性要求较高的场景,文件传输 | 实时性要求较高的场景(IP电话、视频会议、直播) |
每一个应用层(TCP/IP参考模型的最高层)协议一般都会使用到两个传输层协议之一:
运行在TCP协议上的协议:
- HTTP(Hypertext Transfer Protocol,超文本传输协议),主要用于普通浏览。
- HTTPS(HTTP over SSL,安全超文本传输协议),HTTP协议的安全版本。
- FTP(File Transfer Protocol,文件传输协议),用于文件传输。
- POP3(Post Office Protocol, version 3,邮局协议),收邮件用。
- SMTP(Simple Mail Transfer Protocol,简单邮件传输协议),用来发送电子邮件。
- TELNET(Teletype over the Network,网络电传),通过一个终端(terminal)登陆到网络。
- SSH(Secure Shell,用于替代安全性差的TELNET),用于加密安全登陆用。
运行在UDP协议上的协议:
- BOOTP(Boot Protocol,启动协议),应用于无盘设备。
NTP(Network Time Protocol,网络时间协议),用于网络同步。 - DHCP(Dynamic Host Configuration Protocol,动态主机配置协议),动态配置IP地址。
运行在TCP和UDP协议上: - DNS(Domain Name Service,域名服务),用于完成地址查找,邮件转发等工作。
网络层
网络层的任务就是选择合适的网间路由和交换节点,确保计算机通信的数据及时传送。在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 IP 协议,因此分组也叫 IP 数据报 ,简称数据报。
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Intert Prococol)和许多路由选择协议,因此互联网的网络层也叫做网际层或 IP 层。
数据链路层
数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。
在两个相邻节点之间传送数据时,数据链路层将网络层交下来的 IP 数据报组装成帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
在接收数据时,控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特结束
物理层
在物理层上所传送的数据单位是比特。 物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的
总结
- TCP向上层提供面向连接的可靠服务,UDP向上层提供无连接的不可靠服务
- 虽然UDP并没有TCP传输来的准确,但是也能在很多实时性要求高的地方有所作为
- 对数据准确性要求高,速度可以相对较慢的,可以选用TCP
TCP的可靠性
TCP怎么保证数据传输的可靠性
- 校验和:TCP将保持它首部和数据的校验和,这是一个端到端的校验和,目的是检测数据在传输过程中的任何变化。如果收到端的校验和有差错,TCP将丢弃这个报文段和不确定收到此报文段
- TCP接收端会丢弃重复的数据
- 确认应答和序列号:TCP传输时对每个字节的数据都进行了编号,每次接收方收到数据后,都会对传输方进行应答(ACK),其中带有对应的确认序列号,告诉发送方接受了那些数据,下一次的数据从哪里发
- 超时重传:当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段
- 连接管理:三次挥手 + 四次挥手
- 流量控制:TCP连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端能接纳的数据,当接受方来不及处理发送方的数据,能提示发送方降低发送速率,防止包丢失。TCP使用的流量控制协议是可变大小的滑动窗口协议(TCP利用滑动窗口实现流量控制)
- 拥塞控制:慢开始、拥塞避免、快重传、快恢复
- 停止等待协议:它的基本原理就是每发完一个分组就停止发送,等待对方确认。在接收到确认后再发送下一个分组
自动重传请求ARQ
停等式ARQ
停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重转时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求ARQ
连续ARQ协议
停等式ARQ对信道利用率低,连续ARQ协议可提高信道利用率,发送方维护一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认,接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了
优点
信道利用率高,容易实现,即使确认丢失,也不必重传。
缺点
不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5条 消息,中间第三条丢失(3号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
拥塞控制和流量控制的区别
拥塞:对资源的需求 > 可用资源时 网络的性能变坏
拥塞控制:全局过程,防止过多的数据注入网络中,使得网络中路由器或者链路不过载
流量控制:点对点通信的控制,抑制发送端发送数据的速率,便于接收端来得及接受
拥塞控制的方法
主要有四种算法:慢开始、拥塞避免、快重传、快恢复
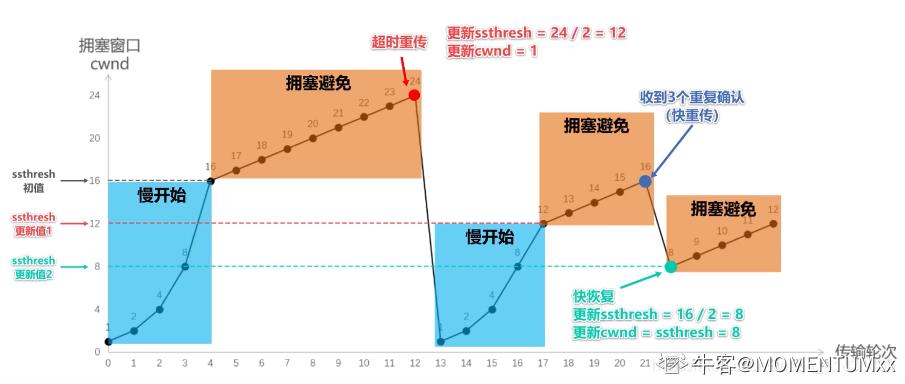
发送方维护一个拥塞窗口,先进行慢开始算法,一开始发送方发送一个字节,在收到接收方的确认后,然后发送的字节数量增大一倍,按照指数逐步增大窗口的大小,直到达到慢开始门限。然后使用拥塞控制算法,增长速率变为线性增长,直到出现超时,重新将窗口的大小调为1字节,使用慢开始算法,同时慢开始门限调整为超时点的一半,达到门限后继续执行拥塞避免,如果收到3-ACK,可能是报文丢失,使用快恢复算法发送缺失的报文段,同时执行快恢复算法,将门限调整至此时窗口的一半,并执行拥塞避免算法
流量控制的方法
滑动窗口协议是传输层进行流控的一种措施,接收方通过通告发送方自己的可以接受缓冲区大小(这个字段越大说明网络吞吐量越高),从而控制发送方的发送速度,不过如果接收端的缓冲区一旦面临数据溢出,窗口大小值也会随之被设置一个更小的值通知给发送端,从而控制数据发送量(发送端会根据接收端指示,进行流量控制)。
滑动窗口是解决流量控制的问题的方法,如果接收端和发送端对数据包的处理速度不同,如何让双方达成一致,接收端的缓存传输数据给应用层,但这个过程不一定是即时的,如果发送的速度太快,会出现接受端的overflow,流量控制解决的是这个问题
TCP双方各自维护一个发送窗口和接受窗口,发送窗口只有收到发送窗口内字节的ACK确认,才会移动发送窗口的左边界,接收窗口只有在前面所有的段都确认的情况下才会移动左边界,当在前面还有字节未接收但收到后面字节的情况下,窗口不会移动,并不对后续字节确认。以此确保对端会对这些数据重传。
HTTP
HTTP报文结构
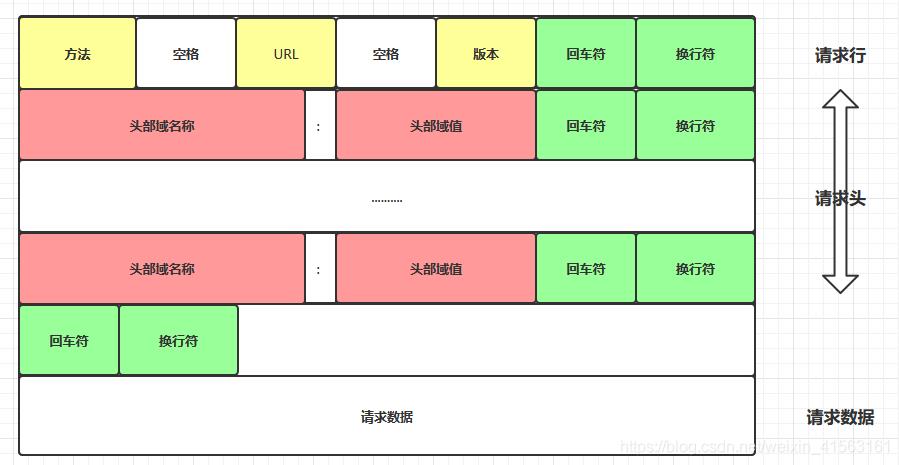
HTTP请求协议包
-
请求行
- url:请求地址
- method:请求方式
-
请求头
- Client-IP:提供了运行客户端的机器的IP地址
- From:提供了客户端用户的E-mail地址
- Host:给出了接收请求的服务器的主机名和端口号
- Referer:提供了包含当前请求URI的文档的URL
- UA-Color:提供了与客户端显示器的显示颜色有关的信息
- UA-CPU:给出了客户端CPU的类型或制造商
- UA-OS:给出了运行在客户端机器上的操作系统名称及版本
- User-Agent:将发起请求的应用程序名称告知服务器
- Accept:告诉服务器能够发送哪些媒体类型
- Accept-Charset:告诉服务器能够发送哪些字符集
- Accept-Encoding:告诉服务器能够发送哪些编码方式
- Accept-Language:告诉服务器能够发送哪些语言
- TE:告诉服务器可以使用那些扩展传输编码
- Expect:允许客户端列出某请求所要求的服务器行为
- Range:如果服务器支持范围请求,就请求资源的指定范围
- Cookie:客户端用它向服务器传送数据
- Cookie2:用来说明请求端支持的cookie版本
-
空白填充
-
请求体
- 请求参数【POST】
HTTP响应协议包
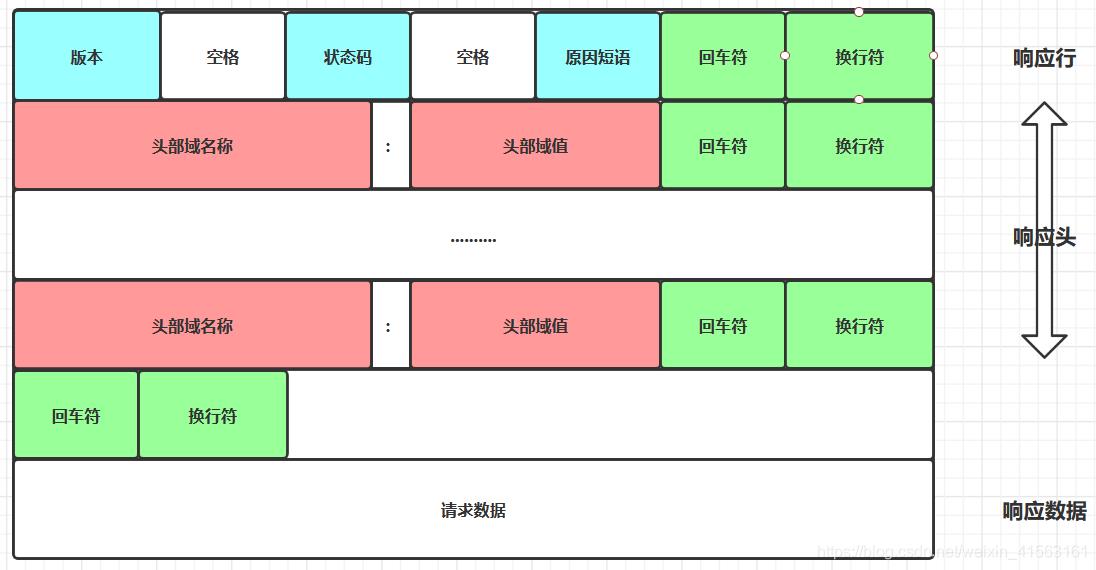
- 状态行
- HTTP状态码
- 响应头
- Age:(从最初创建开始)响应持续时间
- Public:服务器为其资源支持的请求方法列表
- Retry-After:如果资源不可用的话,在此日期或时间重试
- Server:服务器应用程序软件的名称和版本
- Title:对HTML文档来说,就是HTML文档的源端给出的标题
- Warning:比原因短语更详细一些的警告报文
- Accept-Ranges:对此资源来说,服务器可接受的范围类型
- Vary:服务器会根据这些首部的内容挑选出最适合的资源版本发送给客户端
- Proxy-Authenticate:来自代理的对客户端的质询列表
- Set-Cookie:在客户端设置数据,以便服务器对客户端进行标识
- Set-Cookie2:与Set-Cookie类似
- WWW-Authenticate:来自服务器的对客户端的质询列表
- 空白填充
- 响应体
- 可能被访问静态资源文件内容,可能被访问的静态资源文件命令,可能被访问的动态资源文件运行结果
GET和POST的区别
- 幂等性:GET用于无副作用(不改变服务器资源)、幂等的场景,POST用于副作用、不幂等的场景
- 传参方式:GET请求对应的参数放在URL中,而POST请求对应的参数放在请求体中
- 长度限制:浏览器会对URL最大字符长度做限制,导致GET请求的参数数量有限
- 安全性:GET请求参数暴露在URL中,安全性没有POST高
HTTP状态码
HTTP状态码表示客户端HTTP请求的返回结果、标识服务器处理是否正常、表明请求出现的错误等
| 类别 | 原因短语 |
|---|---|
| 1XX | Informational(信息性状态码) 接受的请求正在处理 |
| 2XX | Success(成功状态码) 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) 服务器处理请求出错 |
常用HTTP状态码
1xx:
100:通知浏览器本次返回的资源文件,并不是一个独立的资源文件,需要浏览器接受响应包后,继续向Http服务器索要其他资源文件
| 2xx | 成功(请求被正常处理) |
|---|---|
| 200 | OK,表示从客户端发来的请求在服务器端被正确处理 |
| 204 | No content,表示请求成功,但响应报文不含实体的主体部分 |
| 206 | Partial Content,进行范围请求成功 |
| 3XX | 重定向(表明浏览器要执行特殊处理) |
|---|---|
| 301 | moved permanently,永久性重定向,表示资源已被分配了新的 URL |
| 302 | found,临时性重定向,表示资源临时被分配了新的 URL |
| 303 | see other,表示资源存在着另一个 URL,应使用 GET 方法获取资源(对于301/302/303响应,几乎所有浏览器都会删除报文主体并自动用GET重新请求) |
| 304 | not modified,表示服务器允许访问资源,但请求未满足条件的情况(与重定向无关) |
| 307 | temporary redirect,临时重定向,和302含义类似,但是期望客户端保持请求方法不变向新的地址发出请求 |
| 4XX | 客户端错误 |
|---|---|
| 400 | bad request,请求报文存在语法错误 |
| 401 | unauthorized,表示发送的请求需要有通过 HTTP 认证的认证信息 |
| 403 | forbidden,表示对请求资源的访问被服务器拒绝,可在实体主体部分返回原因描述 |
| 404 | not found,表示在服务器上没有找到请求的资源 |
| 5XX | 服务器错误 |
|---|---|
| 500 | internal sever error,表示服务器端在执行请求时发生了错误 |
| 501 | Not Implemented,表示服务器不支持当前请求所需要的某个功能 |
| 503 | service unavailable,表明服务器暂时处于超负载或正在停机维护,无法处理请求 |
HTTP的通信过程
作为标准的C/S模型,http协议总是由客户端发起,服务器进行响应
- DNS解析,域名系统DNS将域名解析成IP地址
- 建立TCP连接,进行TCP的三次握手
- 浏览器发送请求
- 服务器响应浏览器,向浏览器发送数据
- 通信完毕,TCP连接关闭
HTTPS的通信过程
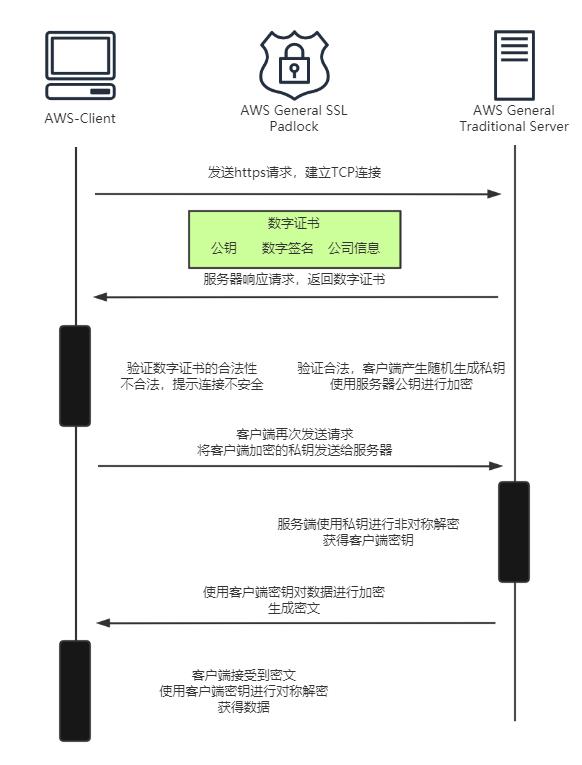
https通信是建立在SSL连接层之上的请求和响应,客户端将加密组件发送到服务器端,服务端进行匹配后将数字证书等信息发送到客户端,客户端进行证书验证,验证通过后使用非对称加密对数据的密钥进行协商,协商后得到对称的加密密钥,然后使用对称算法进行TCP链接,然后与客户端进行三次握手后,进行数据传输,传输完成后,四次挥手,断开链接,通信结束。
- 客户端和服务器端通过TCP建立来连接,发送https请求
- 服务器响应请求,并将数字证书发送给客户端,数字证书包括公共密钥、域名、申请证书的公司
- 客户端收到服务器端的数字证书之后,会验证数字证书的合法性。
- 如果公钥合格,那么客户端会生成client key,一个用于进行对称加密的密钥,并用服务器的公钥对客户端密钥进行非对称加密。
- 客户端会再次发起请求,将加密之后的客户端密钥发送给服务器
- 服务器接受加密文后,会用私钥对其进行非对称解密,得到客户端秘钥,并使用客户端密钥进行对称加密,生成密钥文并发送
- 客户端收到密文,并使用客户端密钥进行解密获得数据
什么是对称加密与非对称加密
对称加密是指加密和解密使用同一个密钥的方式,这种方式存在的最大问题就是密钥发送问题,即如何安全地将密钥发送给对方
非对称加密是指使用一对非对称密钥,即公钥和私钥,公钥可以随意发布,但是私钥只有自己知道,发送密文的一方使用对方的公钥进行加密处理,对方接受到加密信息后,使用自己的私钥进行解密。由于非对称加密的方式不需要发送用来解密的私钥,所以可以保证安全性;但是和对称加密比起来,非常的慢
HTTP与HTTPS的区别
| 区别 | HTTP | HTTPS |
|---|---|---|
| 端口 | 80 | 443 |
| 传输协议 | 超文本传输协议,属于明文传输,客户端于服务器端都无法验证对方的身份 | 安全的超文本传输协议,经过SSL(Secure Socket Layer)加密后的传输协议,SSL运行于TCP之上 |
| 安全性 | 不安全 | 使用了TLS/SSL加密,比http更加安全,共享秘钥加密和公开秘钥加密并用的混合加密机制 |
| 开销 | - | 需要申请CA证书,证书一般需要向认证机构购买 |
| 资源消耗 | 较少 | 由于加解密处理,会消耗更多的 CPU 和内存资源 |
HTTP2
HTTP2可以提高网页的性能
- 采用二进制格式而非文本格式
- 完全的多路服务用,而非有序并阻塞的,只需一个连接即可实现
- 使用报头压缩,降低开销
- 服务器推送
HTTP1(短连接)中浏览器限制了同一个域名下的请求数量(Chrome一般是6个),但在请求很多资源的时候,由于队列阻塞,浏览器达到最大请求数量时,剩余资源需要等待当前六个请求完之后才能发起请求
HTTP2(长连接)引入了多路复用技术,这个技术可以只通过一个TCP连接就可以传输所有请求数据,多路复用可以绕过浏览器限制同一个域名下的请求数量的问题,进而提高了网页的性能
长连接和短连接
长连接(HTTP1.1、HTTP2):client方与server方先建立连接,连接建立后不断开,然后再进行报文发送和接收。这种方式下由于通讯连接一直存在。此种方式常用于P2P通信。
短连接(HTTP1.0):Client方与server每进行一次报文收发交易时才进行通讯连接,交易完毕后立即断开连接。此方式常用于一点对多点通讯。
总结
由上可以看出,长连接可以省去较多的TCP建立和关闭的操作,减少浪费,节约时间。对于频繁请求资源的客户来说,较适用长连接。不过这里存在一个问题,存活功能的探测周期太长,还有就是它只是探测TCP连接的存活,属于比较斯文的做法,遇到恶意的连接时,保活功能就不够使了。在长连接的应用场景下,client端一般不会主动关闭它们之间的连接,Client与server之间的连接如果一直不关闭的话,会存在一个问题,随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可 以避免一些恶意连接导致server端服务受损;如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,这样可以完全避免某客户端连累后端服务。
短连接对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段。但如果客户请求频繁,将在TCP的建立和关闭操作上浪费时间和带宽。
Session、Cookie、Token
HTTP协议本身是无状态的。什么是无状态呢,即服务器无法判断用户身份
Cookie
Cookie是由Web服务器保存在用户浏览器上的小文件(key-value格式),包含用户相关信息,客户端向服务器发起请求,如果服务器需要记录该用户的状态,就使用response向客户端浏览器颁发一个Cookie(【将Cookie写入到响应头中】来交还给当前浏览器。)。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户身份
Cookie的销毁时间
- 默认情况下Cookie对象是存储在浏览器缓存中的,只要浏览器关闭,Cookie对象就会被销毁
- 可以手动设置Cookie的存活时间,浏览器回将接受到的Cookie存放在客户端计算机的硬盘上同时需要指定Cookie在硬盘上的存活时间,在存活时间范围内,关闭浏览器,关闭客户端计算机,关闭服务器,都不会导致Cookie被销毁。在存活时间到达时,Cookie自动从硬盘上被删除
//表示Cookie对象将在硬盘上存活60s
Cookie.setMaxAge(60);
Session(会话作用域对象)
Session是依赖于Cookie实现的,Session是服务器对象
Session是浏览器和服务器会话过程中,服务器分配的一块存储空间,服务器认为浏览器在Cookie中设置SessionId,浏览器在想服务器请求过程中传输 cookie 包含 sessionid,服务器根据 sessionid 获取出会话中存储的信息,然后确定会话的身份信息。
Session的销毁时间
- 用户与HttpSession关联时使用的Cookie只能存放在浏览器的缓存中
- 在浏览器关闭的时候,意味着用户与他的HttpSession关系被切断
- Tomcat无法检测浏览器何时关闭,因此在浏览器关闭时,并不会导致Tomcat将浏览器关联的HttpSession进行销毁
- 为了解决这个问题,Tomcat会为每一个HttpSession对象设置***【空闲时间】***,这个空闲时间默认是30mins,如果当前HttpSession对象
<session-config>
<session-timeout>5</session-timeout><!--当前网站中每一个session最大的空闲时间是5mins-->
</session-config>
Session和Cookie的区别
| 区别 | Session | Cookie |
|---|---|---|
| 存储位置 | 服务端计算机内存中 | 客户端计算机(内存/硬盘) |
| 数据类型 | 共享数据只能是String类型 | SessionMap集合存储共享数据,可以存储任意类型的共享数据 |
| 安全性 | 安全性较差,可能被伪造 | 安全性相对较高 |
| 存储空间 | 单个Cookie保存的数据不能超过4K,很多浏览器最多保存20个Cookie | 无限制 |
| 占用服务器资源 | - | session一定时间内保存在服务器上,当访问增多,占用服务器性能 |
Token
为什么需要Token
Token是在客户端频繁向服务端请求数据,服务端频繁的去数据库查询用户名和密码并进行对比,判断用户名和密码是否正确,并做出相应提示,在这样的背景下,Token便应运而生
什么是Token
Token是服务端生成的一串字符串,以做客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将次Token返回给客户端,以后客户单只需要带上这个Token来请求数据即可,不需要带上用户名和密码
使用Token的目的
Token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮
Token 是在服务端产生的。如果前端使用用户名/密码向服务端请求认证,服务端认证成功,那么在服务端会返回 Token 给前端。前端可以在每次请求的时候带上 Token 证明自己的合法地位
Token和Session的区别
- Session机制存在服务器压力增大,CSRF跨站伪造请求攻击,扩展性不强
- Session存储在服务器端,Token存储在客户端
- Token提供认证和授权功能,作为身份认证,Token安全性比Session好
- Session这种会话存储方式方式只适用于客户端代码和服务端代码运行在同一台服务器上,Token适用于项目级的前后端分离(前后端代码运行在不同的服务器下)
Cookie是如何保持登录状态的
用户登录的时候,服务器根据用户名和密码在服务器数据库中校验该用户是否正确,校验正确后则可以根据用户ID和时间戳等属性加密生成一个Token,并返回给浏览器,只要这个访问会话没有关闭,所有访问服务器的请求都会带上这个Cookie
如何保证Cookie不会被窃取
- 通过设置httpOnly属性,这样Cookie只能在http中传输,而不会被脚本窃取,但是网络拦截http请求还是会得到Cookie
- 在Cookie中加入校验信息,这个校验信息与用户到的使用环境相关,比如ip地址,计算机的物理地址等,在服务器端对校验的时候,如果校验值放生了变化,则要求重新登录
Servlet
Servlet(Servlet Applet),全称Java Servlert .是用Java编写的服务器端程序。其主要功能在与交互式的浏览和修改数据,生成动态Web内容。狭义的servlet是指Java语言实现的一个接口,广义的Servlet是指任何实现了这个Servlet的类,一般情况下,人们将Servlet理解为后者。比如HttpServlet类继承自Servlet类,可以利用继承Http Servlet 来实现Http请求,当不是Http请求的时候,也可以定义其他形式的Servlet。
Servlet的线程安全性
Servlet不是线程安全的,多线程并发的读写会导致数据不同步的问题
解决的办法是尽量不要定义name属性,而是要把name变量分别定义在doGet()和doPost()方法内。虽然使用synchronized(name){}语句块可以解决问题,但是会造成线程的等待,不是很科学的办法。
注意:多线程的并发的读写Servlet类属性会导致数据不同步。但是如果只是并发地读取属性而不写入,则不存在数据不同步的问题。因此Servlet里的只读属性最好定义为final类型的。
Servlet的生命周期
- Web容器加载Servlet并将其实例化后,Servlet生命周期开始,容器运行其init()方法进行Servlet的初始化
- 请求到达时调用Servlet的Service()方法,service()方法会根据需要调用与请求对应的doGet或doPost方法
- 当服务器关闭或者项目被卸载时,服务器会将Servlet实例销毁,此时调用Servlet的destroy()方法
- init()方法和destroy()方法只执行一次,service方法客户端每次请求Servlet都会执行。Servlet中有时会用到一些需要初始化与销毁的资源,因此可以把初始化资源的代码放入init方法中,销毁资源的代码放入destroy方法中,这样就不需要每次处理客户端的请求都要初始化与销毁资源。
计网面试题
浏览器输入一个网址后发生了什么
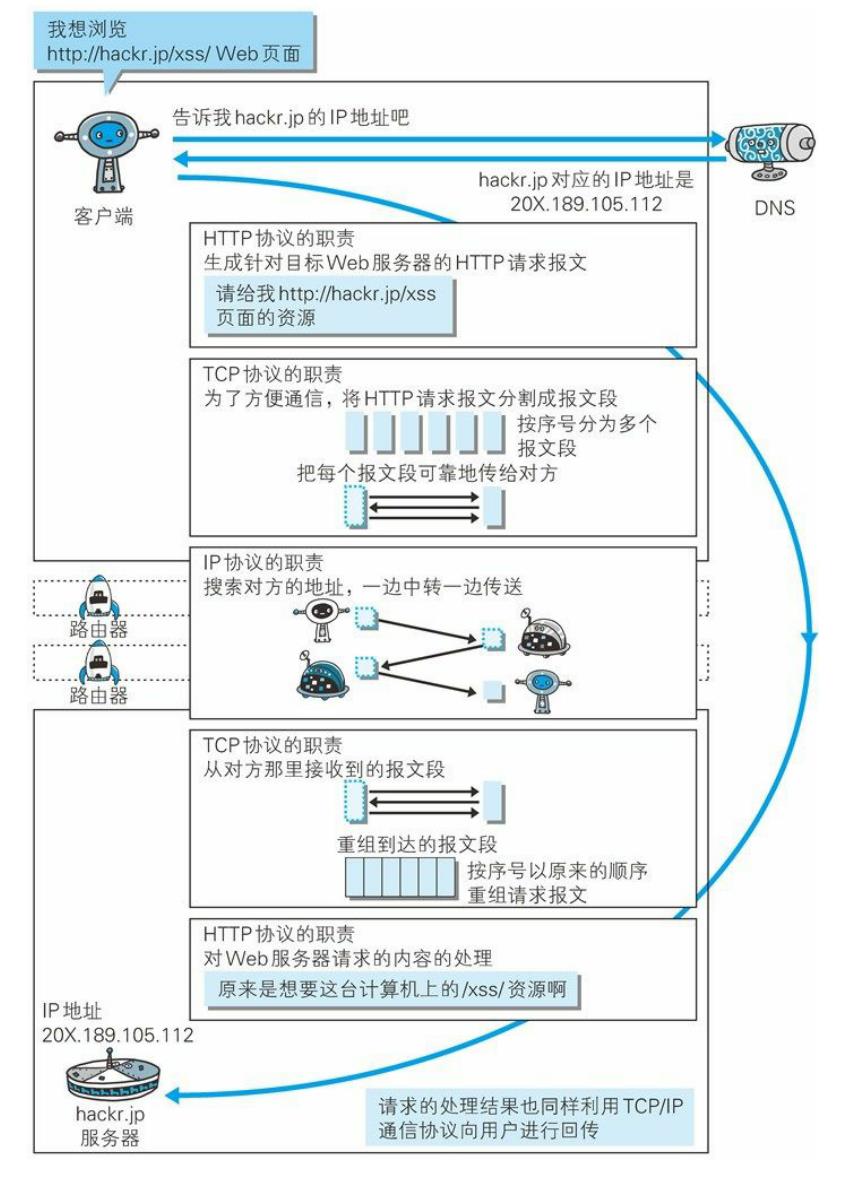
- DNS解析:浏览器会根据输入的URL去查找对应的IP,寻找过程遵循就近原则,依次是:浏览器缓存–>操作系统缓存–>路由器缓存–>本地(ISP)域名服务器缓存–>根域名服务器
- 进行TCP连接:浏览器得到IP后,向服务器发送TCP连接,TCP经过三次握手
- 浏览器发送HTTP请求:HTTP请求方式为get包含树主机(Host)、用户代理(User-Agent),用户代理就是自己的浏览器,他是你的“代理人”,Connection(连接属性)中的keep-alive表示浏览器告诉对方服务器在传输完现在请求的内容后不要断开连接,不断开的话下次继续连接速度就很快了。会有Cookies,Cookies包含了用户的登录信息,一般保存的是用户的JSESSIONID,在每次向服务器发送请求的时候会重新发送给服务器,服务器就知道是哪个浏览器了
- 服务请求处理:服务器传回来响应头(包含状态码)和就要的要求的页面内容
- 浏览器解析渲染页面
- 关闭TCP连接(四次挥手)
TCP三次握手的过程
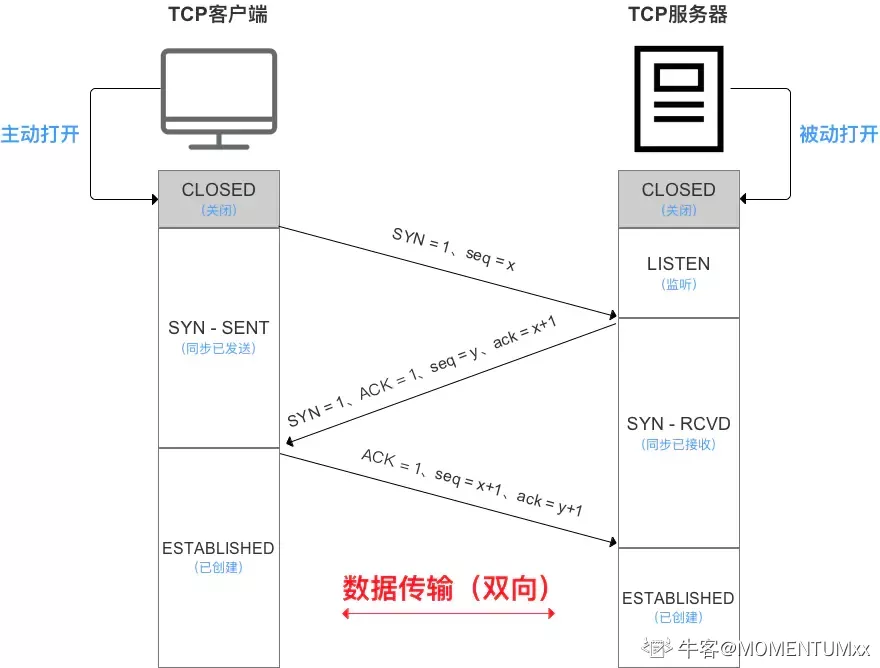
- 客户端向服务器发送一个连接请求的报文段(SYN=1、seq=x)客户端变为SYN-SENT状态
- 服务端接受到请求连接报文段后,若同意建立连接,则向客户端发送确认报文(SYN=1、ACK=1、seq=y、ack=x+1)(服务器变成SYN-RECEIVED)
- 客户端确认报文段后,向服务器再次发出连接确认报文(ACK=1、seq=x+1、ack=y+1)(客户端和服务端变为ESTABLISHED)
SYN
SYN是TCP/IP建立连接时使用的握手信号,在客户端和服务端建立连接时客户端首先发送一个syn消息,服务端使用syn-ack应答表示接收到了这个消息,最后客户端再以ack消息响应,这样再客户端和服务器之间才能建立起可靠的TCP连接,数据才可以在客户端和服务器之间传递。
为什么要回传SYN
接收端传回发送的SYN是为了告诉发送端,服务端确认接受到了信号
为什么要传ACK
传了syn证明发送方到接收方的通道没有问题,但是接收方到发送方的通道还需要ack信号来进行验证
为什么需要三次握手
为了信息对等和防止出现请求超时导致脏连接
- 信息对等就是确保两台机器都具备发送和接受的能力,也就是确保发送端到接收端和接收端到发送端的通道都没有问题
- 什么是脏连接:客户端的SYN请求超时,客户端超时重传,但是S端接收到了超时的SYN请求,建立了新的连接
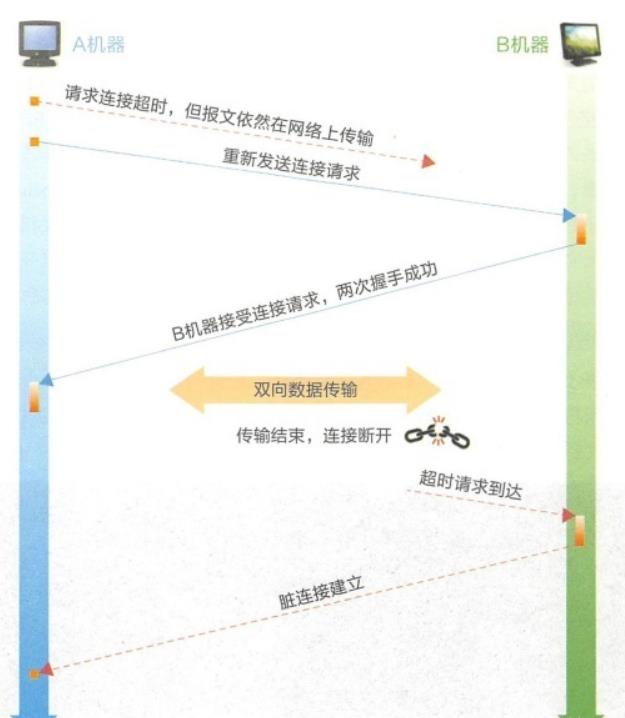
如果只有两次握手的话,服务器返回的确认报文如果丢失,客户端没有收到确认,所以关闭连接,但是此时服务端已经开启了连接
TCP四次挥手的过程
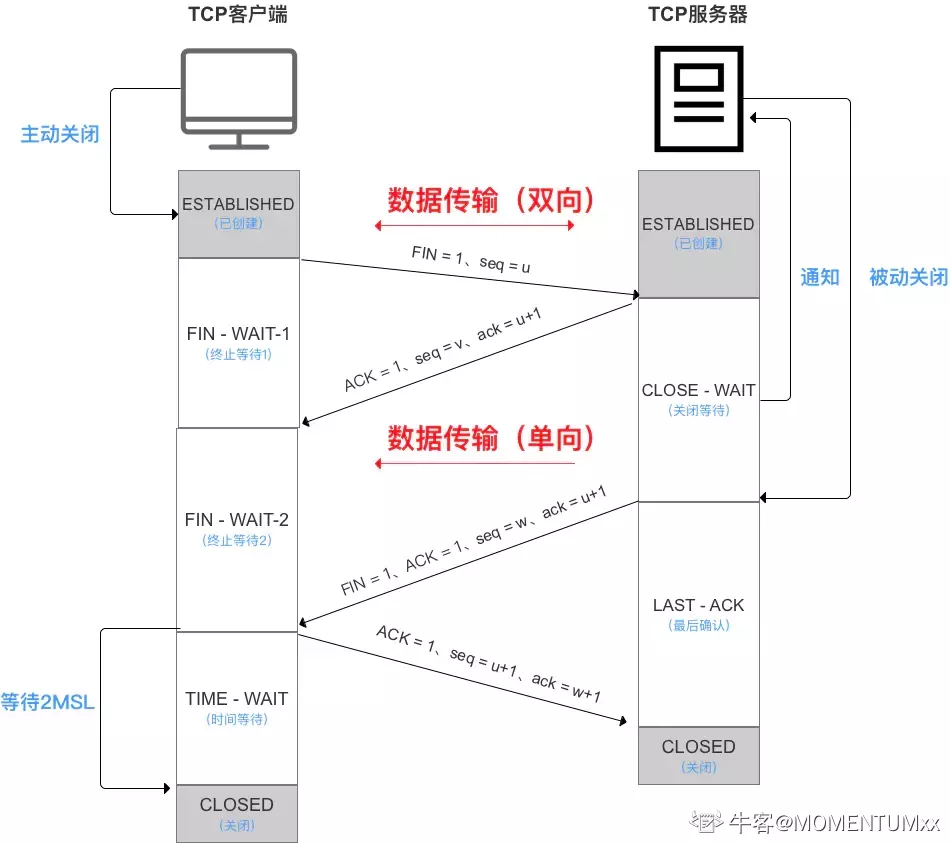
- 客户端向服务端发送一个连接释放报文
- 服务端收到连接释放报文后,向客户端返回连接释放确认报文
- 若服务器已无要向客户端发送的数据,则发出连接释放的报文段
- 客户端收到连接释放报文向服务器发回连接释放确认报文
为什么需要四次挥手
由于TCP的半关闭造成的,半关闭就是TCP提供了连接的一端在他结束它的发送后还能接受来此另一端的发送
第二次挥手后服务端进入CLOSE_WAIT(关闭等待)状态,此时的TCP处于半关闭状态,客户端到服务端的连接释放,此时客户端已无数据发送,而服务端还可以向客户端发送数据,所以第二次挥手不能发送FIN报文,只有当服务端也没有数据要发送了,才在第三次挥手时发送FIN报文,告诉客户端不再发送数据了。
为什么客户端关闭连接前需要等待2MSL
MSL(Maximum Segment Lifetime),为“报文最大生存时间”,是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
- 保证客户端发送的最后一个ACK报文段能够达到服务端,这个ACK报文段有可能丢失,是服务器收不到确认,服务端会重传FIN-ACK报文段,客户端能在2MSL时间内收到这个报文段,接着客户端重传一次确认,重新启动2MSL计时器,最后客户端和服务端都进入到CLOSED状态。
- 防止已失效的连接请求报文段出现在本连接,客户端发送完最后一个ACK报文后,在经过2MSL就可以是本连接持续时间内所产生的报文段都从网络中消失,使下一个新的连接中不会出现这种旧的连接请求报文段
DNS域名解析用的是什么协议
同时使用TCP和UDP协议
DNS在区域传输的时候使用TCP协议。其他时候使用UDP协议
DNS区域传输时使用TCP协议
DNS规范规定了两种DNS服务器:主DNS服务器和辅助DNS服务器,辅助域名服务器会定时向主域名服务器进行查询以便了解数据是否有变动,如有变动,会执行一次区域传输,进行数据同步。区域传送使用TCP而不是UDP,因为数据同步传送的数据量比一个请求应答的数据量要多的多。而TCP是一种可靠连接,保证了数据的准确性
域名解析时使用UDP协议
客户端向DNS服务器查询域名,一般返回的内容不超过512字节,使用UDP传输即可,不需要经过TCP三次握手,这样DNS服务器负载更低
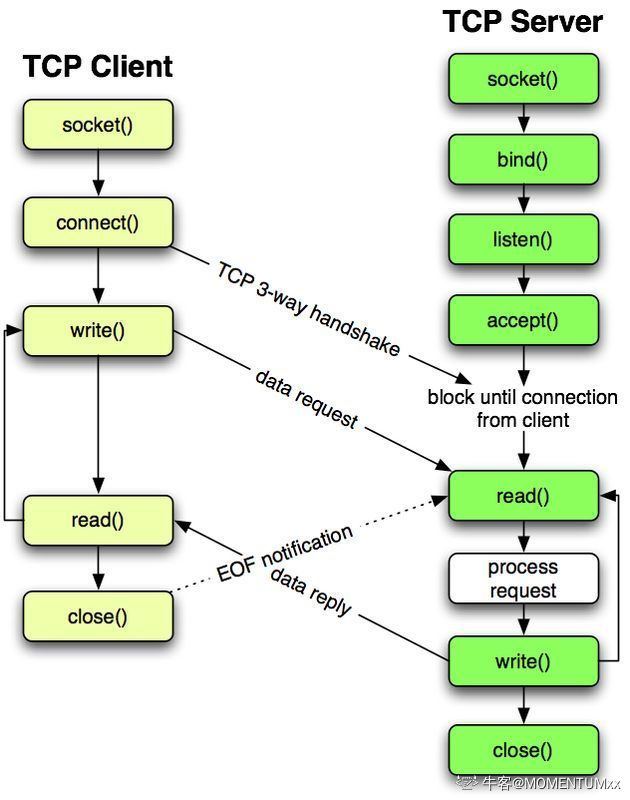
什么是socket,客户端和服务端的socket通信过程
socket是传输层和应用层之间的一个抽象层,socket是一种打开–读/写–关闭模式的实现,服务器和客户端各自维护一个”文件“(Unix一切皆文件),在建立连接打开后,可以向文件写入内容供对方读取或者读取对方内容,通讯结束时关闭文件。
socket通信过程
socket保证了不同计算机之间的通信,也就是网络通信。对于网站,通信模型是服务器和客户端之间的通信,两段都建立了一个Socket对象,然后通过Socket对象对数据进行传输。通常服务器处于一个无限循环,等待客户端的连接
客户端过程:
创建socket,连接服务器,将socket与远程主机连接,发送数据,读取响应数据,直到数据交换完毕,关闭连接,结束TCP对话
服务端过程:
创建socket,与本机地址及端口进行绑定,然后通知TCP准备好接收连接,调用accept()阻塞,等待来自客户端的连接。如果客户端与服务器建立了连接,客户端发送数据请求,服务器接收请求并处理请求,然后把响应数据发送给客户端,客户端读取数据,直到数据交换完毕,最后关闭连接。
PING命令的原理
PING是用于测试网络连接质量的程序。PING发送一个ICMP(Internet Control Messages Protocol)即网络控制报文协议
原理
利用网络上机器IP地址的唯一性,给目标IP地址发送一个数据包,再要求对方返回一个同样大小的数据包来确定两台网络机器是否连接相同,时延是多少
如何实现负载均衡
一、实现负载均衡的几种技术
1、HTTP重定向协议实现负载均衡:根据用户的http请求计算出一个真实的web服务器地址,并将该web服务器地址写入http重定向响应中返回给浏览器,由浏览器重新进行访问。
2、DNS域名解析负载均衡:原理:在DNS服务器上配置多个域名对应IP的记录。例如一个域名www.baidu.com对应一组web服务器IP地址,域名解析时经过DNS服务器的算法将一个域名请求分配到合适的真实服务器上。
3、反向代理负载均衡:反向代理处于web服务器这边,反向代理服务器提供负载均衡的功能,同时管理一组web服务器,它根据负载均衡算法将请求的浏览器访问转发到不同的web服务器处理,处理结果经过反向服务器返回给浏览器。
4、IP负载均衡:在网络层通过修改目标地址进行负载均衡。
5、数据链路层负载均衡:在数据链路层修改Mac地址进行负载均衡。
二、常见的负载均衡算法
轮询法、随机法、加权轮询法、加权随机法
如果客户端禁止 cookie 能实现 session 还能用吗?
Cookie 与 Session,一般认为是两个独立的东西,Session采用的是在服务器端保持状态的方案,而Cookie采用的是在客户端保持状态的方案。
但为什么禁用Cookie就不能得到Session呢?因为Session是用Session ID来确定当前对话所对应的服务器Session,而Session ID是通过Cookie来传递的,禁用Cookie相当于失去了Session ID,也就得不到Session了。
假定用户关闭Cookie的情况下使用Session,其实现途径有以下几种:
- 手动通过URL传值、隐藏表单传递SessionID。
- 用文件、数据库等形式保存Session ID,在跨页过程中手动调用。
参考:
《图解HTTP》
《通信网络基础》
计网面试题
一位牛客大佬总结的知识点,链接找不到了
总结不够全面,持续更新…
以上是关于图神经网络汇总和总结的主要内容,如果未能解决你的问题,请参考以下文章
节:1-1.2 | 神经网络输入输出连小学生都能看懂的深度学习基础总结
人工智能领域常用的开源框架和库(含机器学习/深度学习/强化学习/知识图谱/图神经网络)
人工智能领域常用的开源框架和库(含机器学习/深度学习/强化学习/知识图谱/图神经网络)
机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总