大数据之 Solr 集群搭建
Posted 月亮给我抄代码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之 Solr 集群搭建相关的知识,希望对你有一定的参考价值。
什么是 Solr?
Solr 是一个高性能,采用 Java 开发,基于 Lucene 的全文搜索服务器。同时对其进行了扩展,提供了比 Lucene 更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
它对外提供类似于 Web-service 的 API 接口。用户可以通过 HTTP 请求,向搜索引擎服务器提交一定格式的 XML 文件,生成索引;也可以通过 Http Get 操作提出查找请求,并得到 XML 格式的返回结果。
Solr 集群搭建
- 解压文件
tar -zxvf solr-7.7.3.tgz -C /opt/module/
#修改名称
cd /opt/module/
mv solr-7.7.3/ solr
- 配置环境变量
#SOLR_HOME
export SOLR_HOME=/opt/module/solr
export PATH=$PATH:$SOLR_HOME/bin
保存并退出。
- 修改配置文件
# 进入 solr 安装目录的 bin 文件夹下
cd /opt/module/solr/bin
# 编辑文件 solr.in.sh
vi solr.in.sh
修改 Zookeeper 参数:
# 其中的连接地址修改为自己的
ZK_HOST="hadoop104:2181,hadoop105:2181,hadoop106:2181"

- 文件分发与同步
将 Solr 分发到其它机器上,并同步环境变量。
scp -r solr/ hadoop105:/opt/module/
scp -r solr/ hadoop106:/opt/module/
scp -r /etc/profile hadoop105:/etc/profile
scp -r /etc/profile hadoop106:/etc/profile
环境变量分发完成后,注意在从机上使用 source /etc/profile 进行环境变量的刷新。
- 启动 Solr 集群
启动 Solr 集群前必须先启动 Zookeeper 服务!!!
# 启动 solr
solr start -force
# 停止 solr
solr stop
停止 Solr 服务时如果出现:Found 1 Solr nodes running! Must either specify a port using -p or -all to stop all Solr nodes on this host. 提示,则可以使用 solr stop -p 8983 进行关闭。
由于 Solr 本身并不推荐使用 root 账号进行启动,存在安全风险,可能会导致系统被攻击或者数据泄露,如果想要强行启动可以通过添加 -force 参数进行启动,但并不推荐这种做法。
- 新建 Solr 普通用户启动
由于 Solr 的安全性问题,我们不能使用 root 账号直接启动,所以需要创建一个普通用户进行启动。
在三台机器上都执行如下步骤:
# 添加一个普通用户 solr
useradd solr
# 设置一个密码
passwd solr
# 更改 solr 安装目录的所属组
chown -R solr:solr /opt/module/solr
普通用户启动 Solr 集群
# 三台机器都执行
sudo -i -u solr solr start
sudo -i -u 表示以另一个用户的身份登录系统并打开一个新的 Shell。
第一个 solr 表示的是一个普通用户。
第二个 solr 表示的是 Solr 集群安装目录下的 /opt/module/solr/bin/solr 脚本启动文件,因为我们配置了环境变量,所以可以直接写 solr 。
启动完成后出现 Happy searching! 表示启动成功。
- 启动验证
我们可以访问 Solr 提供的 WEB UI 界面来进行验证,启动完成后,选择任意一台主机地址,访问 Solr 的默认端口 8983 即可进入,例如:192.168.0.104:8983。
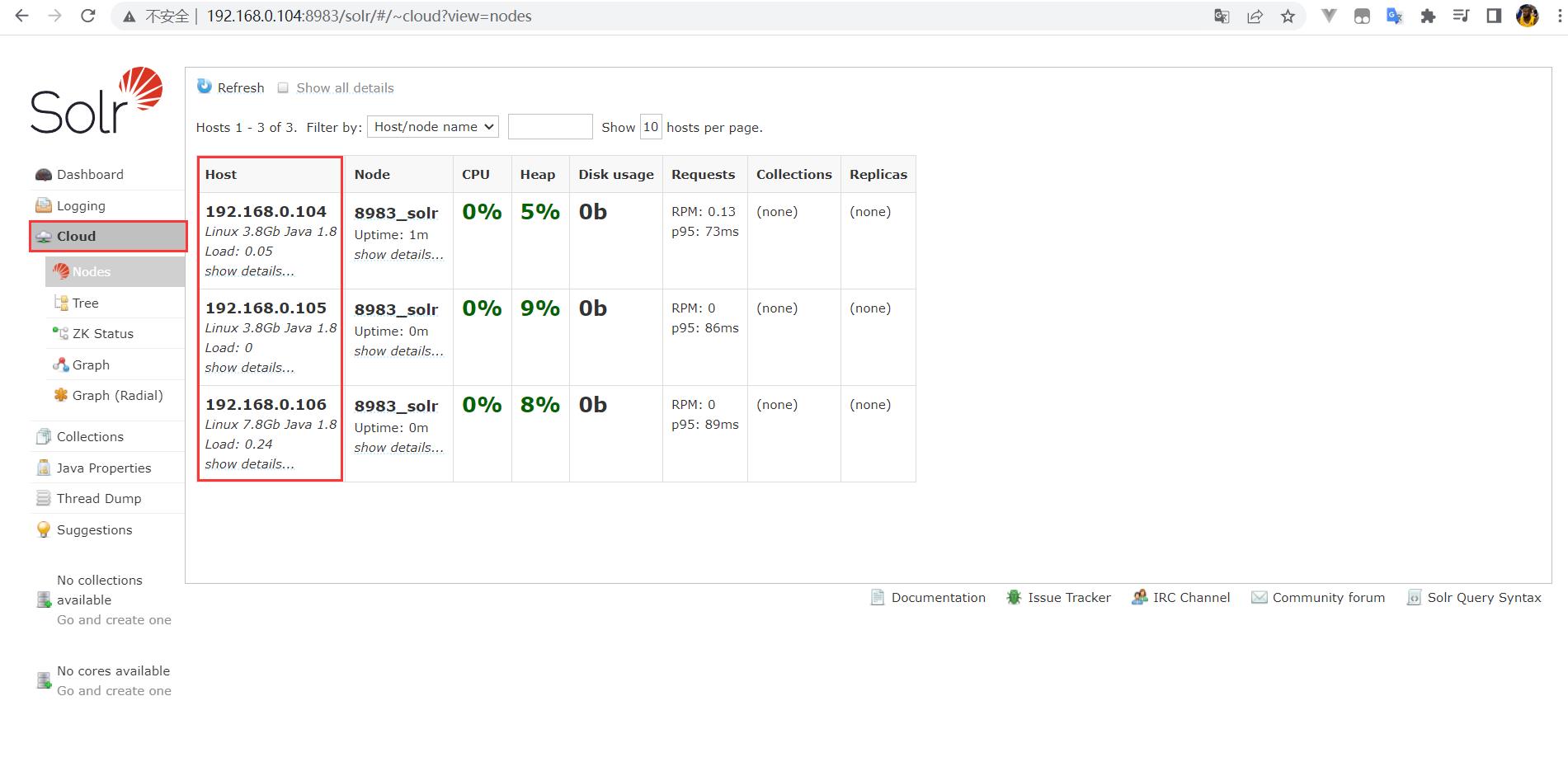
进入网页后打开 Cloud,如果发现三台机器都已经启动,则表示 Solr 集群部署完成。
- 异常处理
无法进入 Solr 的 WEB UI 界面,可能的原因如下:
-
一、
$SOLR_HOME/bin/solr.in.sh文件中的 Zookeeper 连接地址/端口是否设置正确。 -
二、未使用普通用户启动,或者没有把 Solr 的安装文件目录的所属组切换为普通用户,但这种情况一般是可以进入 WEB 界面的,只是一些功能无法使用。
-
三、配置文件都正确,使用普通用户启动 Solr(如:
sudo -i -u solr solr start),且出现了 Happy searching! 的提示,我们会认为启动成功了,但是打开网页访问时会出现如下错误界面:
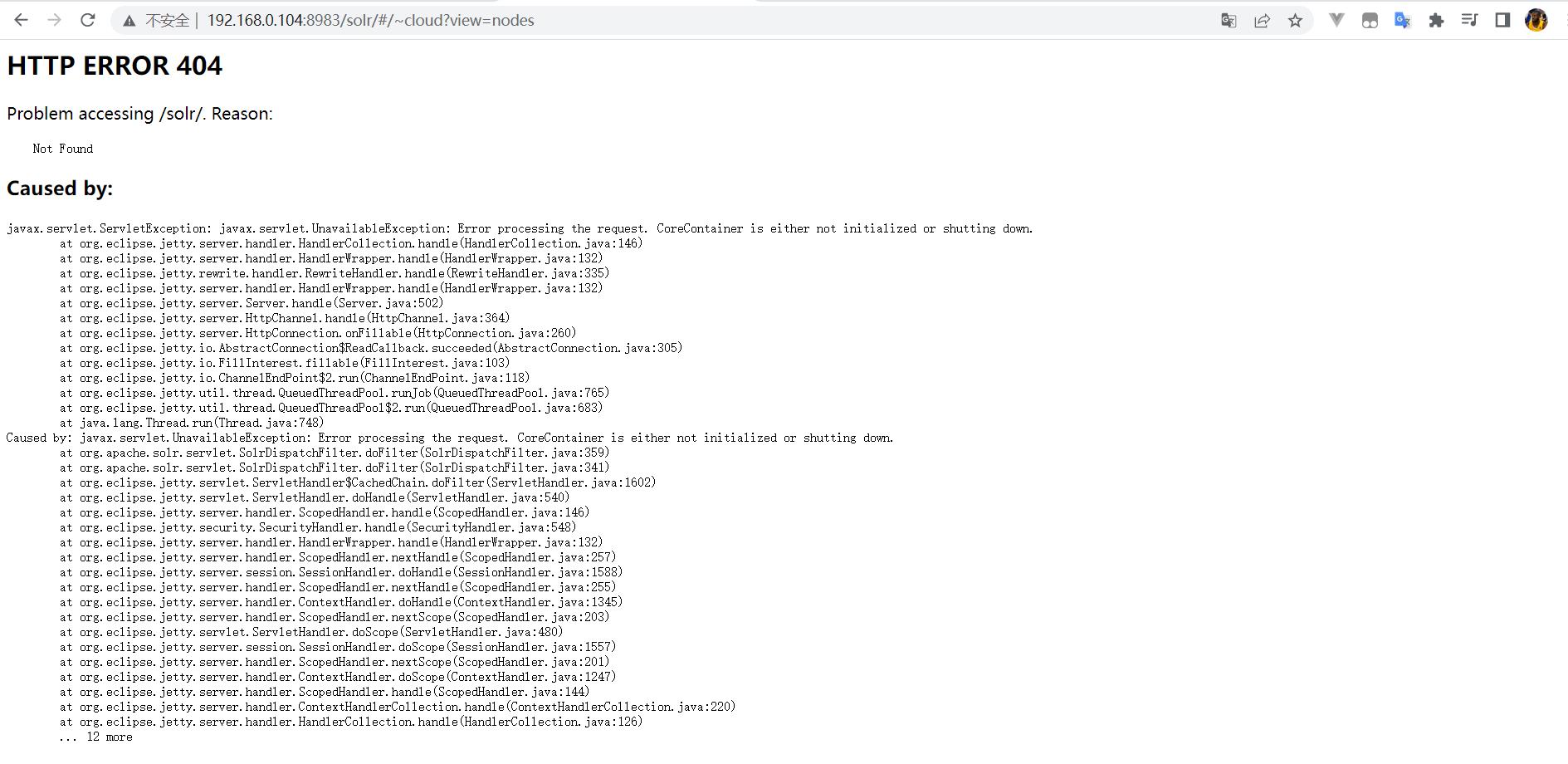
错误原因:javax.servlet.ServletException: javax.servlet.UnavailableException: Error processing the request. CoreContainer is either not initialized or shutting down.
显示处理请求时出错,CoreContainer 未初始化或正在关闭。
于是我就去查看了 Solr 的日志文件,在日志头部发现了如下错误:
org.apache.solr.common.SolrException: solr.xml does not exist in /opt/module/solr cannot start Solr

显示无法找到 solr.xml 文件。
solr.xml 文件是 Solr 的核心配置文件之一,定义了 Solr 实例的基本配置信息和核心配置信息,是 Solr 正常运行的必要条件之一。
Solr 默认的 solr.xml 文件位于 Solr 安装目录下的 server/solr/ 目录下。
解决方法也很简单,只需要在启动的时候指定 solr.xml 的文件目录即可,如下所示:
sudo -i -u solr solr start -Dsolr.solr.home=/opt/module/solr/server/solr/
通过 -Dsolr.solr.home 参数指定 solr.xml 文件的路径即可,问题得到解决。
但是每次都添加这么一大串参数十分繁琐,我们可以在 $SOLR_HOME/bin/solr.in.sh 文件中直接指定 SOLR_HOME 参数,如下所示:

SOLR_HOME=/opt/module/solr/server/solr/
注意同步到其它机器上,然后就彻底解决该问题啦!
搭建 SolrCloud 集群服务
一、概述
Lucene是一个Java语言编写的利用倒排原理实现的文本检索类库
Solr是以Lucene为基础实现的文本检索应用服务。Solr部署方式有单机方式、多机Master-Slaver方式、Cloud方式。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案。当索引越来越大,一个单一的系统无法满足磁盘需求,查询速度缓慢,此时就需要分布式索引。在分布式索引中,原来的大索引,将会分成多个小索引,solr可以将这些小索引返回的结果合并,然后返回给客户端。
二、特色功能
SolrCloud有几个特色功能:
集中式的配置信息使用ZK进行集中配置。启动时可以指定把Solr的相关配置文件上传 Zookeeper,多机器共用。这些ZK中的配置不会再拿到本地缓存,Solr直接读取ZK中的配置信息。配置文件的变动,所有机器都可以感知到。另外,Solr的一些任务也是通过ZK作为媒介发布的。目的是为了容错。接收到任务,但在执行任务时崩溃的机器,在重启后,或者集群选出候选者时,可以再次执行这个未完成的任务。
自动容错SolrCloud对索引分片,并对每个分片创建多个Replication。每个 Replication都可以对外提供服务。一个Replication挂掉不会影响索引服务。更强大的是,它还能自动的在其它机器上帮你把失败机器上的索引Replication重建并投入使用。
近实时搜索立即推送式的replication(也支持慢推送)。可以在秒内检索到新加入索引。
查询时自动负载均衡SolrCloud索引的多个Replication可以分布在多台机器上,均衡查询压力。如果查询压力大,可以通过扩展机器,增加Replication来减缓。
自动分发的索引和索引分片发送文档到任何节点,它都会转发到正确节点。
事务日志确保更新无丢失,即使文档没有索引到磁盘。
其它值得一提的功能有:
索引存储在HDFS上索引的大小通常在G和几十G,上百G的很少,这样的功能或许很难实用。但是,如果你有上亿数据来建索引的话,也是可以考虑一下的。我觉得这个功能最大的好处或许就是和下面这个“通过MR批量创建索引”联合实用。
通过MR批量创建索引有了这个功能,你还担心创建索引慢吗?
强大的RESTful API通常你能想到的管理功能,都可以通过此API方式调用。这样写一些维护和管理脚本就方便多了。
优秀的管理界面主要信息一目了然;可以清晰的以图形化方式看到SolrCloud的部署分布;当然还有不可或缺的Debug功能。
三、SolrCloud的基本概念
Cluster集群:一组Solr节点,逻辑上作为一个单元进行管理,整个集群使用同一套Schema和SolrConfig
Node节点:一个运行Solr的JVM实例
Collection:在SolrCloud集群中逻辑意义上的完整的索引,常常被划分为一个或多个Shard。这些Shard使用相同的config set,如果Shard数超过一个,那么索引方案就是分布式索引。
Core:也就是Solr Core,一个Solr中包含一个或者多个SolrCore,每个Solr Core可以独立提供索引和查询功能,Solr Core额提出是为了增加管理灵活性和共用资源。
SolrCloud中使用的配置是在Zookeeper中的,而传统的Solr Core的配置文件是在磁盘上的配置目录中。
Config Set:Solr Core提供服务必须的一组配置文件,每个Config Set有一个名字。必须包含solrconfig.xml和schema.xml,初次之外,依据这两个文件的配置内容,可能还需要包含其他文件。
Config Set存储在Zookeeper中,可以重新上传或者使用upconfig命令进行更新,可以用Solr的启动参数bootstrap_confdir进行初始化或者更新。
Shard分片:Collection的逻辑分片。每个Shard被分成一个或者多个replicas,通过选举确定那个是Leader。
Replica:Shard的一个拷贝。每个Replica存在于Solr的一个Core中。
Leader:赢得选举的Shard replicas,每个Shard有多个replicas,这几个Replicas需要选举确定一个Leader。选举可以发生在任何时间。当进行索引操作时,SolrCloud将索引操作请求传到此Shard对应的leader,leader再分发它们到全部Shard的replicas。
四、Solr 文档
Apache SolrCloud 参考指南
http://lucene.apache.org/solr/guide/6_6/solrcloud.html
Apache Solr文档
https://cwiki.apache.org/confluence/display/solr/
Solr 参数配置
https://cwiki.apache.org/confluence/display/solr/Format+of+solr.xml
Solr控制脚本参考
https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=50234737
环境
VMware版本号:12.0.0
CentOS版本:CentOS 7.3.1611
Solr 版本:solr-6.6.0
ZooKeeper版本:ZooKeeper-3.4.9.tar.gz 具体参考《CentOs7.3 搭建 ZooKeeper-3.4.9 Cluster 集群服务》
https://segmentfault.com/a/1190000010807875
JDK环境:jdk-8u144-linux-x64.tar.gz 具体参考《CentOs7.3 安装 JDK1.8》
https://segmentfault.com/a/1190000010716919
注意事项
关闭防火墙
$ systemctl stop firewalld.service
Solr 6(和SolrJ客户端库)的Java支持的最低版本现在是Java 8。
Solr 安装
下载 Solr
下载最新版本的Solr ,我在北京我就选择,清华镜像比较快 , 文件大概140M
清华镜像:https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/6.6.0/
阿里镜像:https://mirrors.aliyun.com/apache/lucene/solr/6.6.0/
提取tar文件
$ cd /opt/
$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/6.6.0/solr-6.6.0.tgz
$ tar -zxf solr-6.6.0.tgz
$ cd solr-6.6.0
集群配置
1.编辑 solr.in.sh
集群中的每台机器都要按照以下说明进行配置启动
首先到 solr 安装目录的 bin 下,编辑 solr.in.sh 文件
搜索 SOLR_HOST, 取消注释, 设置成自己的 ip
搜索 SOLR_TIMEZONE, 取消注释, 设置成 UTC+8
把node1 的solr.in.sh 修改为一下配置
SOLR_HOST="node1"
SOLR_TIMEZONE="UTC+8"
2.复制 Solr 配置
1. 把 node1 编辑好的 Solr 文件及配置通过 scp-r 复制到集群 node2, node3
$ for a in {2..3} ; do scp -r /opt/solr-6.6.0/ node$a:/opt/solr-6.6.0 ; done
2. 然后修改 node2, node3 的上的 solr.in.sh 的 SOLR_HOST 为机器的ip
格式 SOLR_HOST="ip"
$ vi /opt/solr-6.6.0/bin/solr.in.sh
3.启动 ZooKeeper 集群
$ for a in {1..3} ; do ssh node$a "source /etc/profile; /opt/zookeeper-3.4.9/bin/zkServer.sh start" ; done
4.启动 SolrCloud 集群
在任意一台机器,启动 SolrCloud 集群 并且关联 ZooKeeper 集群
$ for a in {1..3} ; do ssh node$a "source /etc/profile; /opt/solr-6.6.0/bin/solr start -cloud -z node1:2181,node2:2181,node3:2181 -p 8983 -force" ; done
5.创建集群库
在任意一台机器
$ /opt/solr-6.6.0/bin/solr create_collection -c test_collection -shards 2 -replicationFactor 3 -force
-c 指定库(collection)名称-shards 指定分片数量,可简写为 -s ,索引数据会分布在这些分片上-replicationFactor 每个分片的副本数量,每个碎片由至少1个物理副本组成
响应
Connecting to ZooKeeper at node3:2181 ...
INFO - 2017-08-24 11:57:30.581; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at node3:2181 ready
Uploading /opt/solr-6.6.0/server/solr/configsets/data_driven_schema_configs/conf for config test_collection to ZooKeeper at node3:2181
Creating new collection 'test_collection' using command:
http://192.168.252.121:8983/solr/admin/collections?action=CREATE&name=test_collection&numShards=2&replicationFactor=3&maxShardsPerNode=2&collection.configName=test_collection
{
"responseHeader":{
"status":0,
"QTime":11306},
"success":{
"192.168.252.123:8983_solr":{
"responseHeader":{
"status":0,
"QTime":9746},
"core":"test_collection_shard1_replica2"},
"192.168.252.122:8983_solr":{
"responseHeader":{
"status":0,
"QTime":9857},
"core":"test_collection_shard1_replica3"},
"192.168.252.121:8983_solr":{
"responseHeader":{
"status":0,
"QTime":9899},
"core":"test_collection_shard2_replica1"}}}
SolrCloud状态 图表
可以看到 solr 2个分片,个3个副本
6.服务状态
如果您不确定SolrCloud状态
$ /opt/solr-6.6.0/bin/solr status
响应
Found 1 Solr nodes:
Solr process 2926 running on port 8983
{
"solr_home":"/opt/solr-6.6.0/server/solr",
"version":"6.6.0 5c7a7b65d2aa7ce5ec96458315c661a18b320241 - ishan - 2017-05-30 07:32:53",
"startTime":"2017-08-24T08:32:16.683Z",
"uptime":"0 days, 0 hours, 34 minutes, 51 seconds",
"memory":"63.8 MB (%13) of 490.7 MB",
"cloud":{
"ZooKeeper":"node1:2181,node2:2181,node3:2181",
"liveNodes":"3",
"collections":"1"}}
/opt/solr-6.6.0/bin/solr createcollection -c wwwymqiocollection -shards 2 -replicationFactor 3 -force
7.删除集群库
在任意一台机器 ,执行命令 ./solrdelete-c<collection>
将检查/opt/solr-6.6.0/server/solr/test_collection_shard1_replica2/opt/solr-6.6.0/server/solr/test_collection_shard2_replica2
配置目录是否被其他集合使用。如果没有,那么该目录将从SolrCloud 集群 中删除
$ /opt/solr-6.6.0/bin/solr delete -c test_collection
Connecting to ZooKeeper at node1:2181,node2:2181,node3:2181
INFO - 2017-08-24 17:56:53.679; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at node1:2181,node2:2181,node3:2181 ready
Deleting collection 'test_collection' using command:
http://node3:8983/solr/admin/collections?action=DELETE&name=test_collection
{
"responseHeader":{
"status":0,
"QTime":924},
"success":{
"node1:8983_solr":{"responseHeader":{
"status":0,
"QTime":69}},
"node3:8983_solr":{"responseHeader":{
"status":0,
"QTime":86}},
"node2:8983_solr":{"responseHeader":{
"status":0,
"QTime":91}}}}
8.停止集群
在任意一台机器 ,停止 SolrCloud 集群
在SolrCloud模式下停止Solr,可以使用 -all
$ for a in {1..3} ; do ssh node$a "source /etc/profile; /opt/solr-6.6.0/bin/solr stop -all " ; done
或者
$ for a in {1..3} ; do ssh node$a "source /etc/profile; /opt/solr-6.6.0/bin/solr stop -cloud -z node1:2181, -z node2:2181, -z node3:2181 -p 8983 -force" ; done
9.副本状态
$ /opt/solr-6.6.0/bin/solr healthcheck -c test_collection -z node1:2181,node2:2181,node3:2181 -p 8983 -force
响应
INFO - 2017-08-24 16:34:26.906; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at node1:2181,node2:2181,node3:2181 ready
{
"collection":"test_collection",
"status":"healthy",
"numDocs":0,
"numShards":2,
"shards":[
{
"shard":"shard1",
"status":"healthy",
"replicas":[
{
"name":"core_node3",
"url":"http://node1:8983/solr/test_collection_shard1_replica1/",
"numDocs":0,
"status":"active",
"uptime":"0 days, 0 hours, 2 minutes, 10 seconds",
"memory":"58.6 MB (%12) of 490.7 MB",
"leader":true},
{
"name":"core_node5",
"url":"http://node2:8983/solr/test_collection_shard1_replica3/",
"numDocs":0,
"status":"active",
"uptime":"0 days, 0 hours, 1 minutes, 58 seconds",
"memory":"50.2 MB (%10.2) of 490.7 MB"},
{
"name":"core_node6",
"url":"http://node3:8983/solr/test_collection_shard1_replica2/",
"numDocs":0,
"status":"active",
"uptime":"0 days, 0 hours, 1 minutes, 46 seconds",
"memory":"56.3 MB (%11.5) of 490.7 MB"}]},
{
"shard":"shard2",
"status":"healthy",
"replicas":[
{
"name":"core_node1",
"url":"http://node1:8983/solr/test_collection_shard2_replica1/",
"numDocs":0,
"status":"active",
"uptime":"0 days, 0 hours, 2 minutes, 10 seconds",
"memory":"58.6 MB (%12) of 490.7 MB",
"leader":true},
{
"name":"core_node2",
"url":"http://node3:8983/solr/test_collection_shard2_replica2/",
"numDocs":0,
"status":"active",
"uptime":"0 days, 0 hours, 1 minutes, 46 seconds",
"memory":"58.8 MB (%12) of 490.7 MB"},
{
"name":"core_node4",
"url":"http://node2:8983/solr/test_collection_shard2_replica3/",
"numDocs":0,
"status":"active",
"uptime":"0 days, 0 hours, 1 minutes, 58 seconds",
"memory":"51.9 MB (%10.6) of 490.7 MB"}]}]}
10.ZK管理配置
配置文件上传到ZooKeeper 集群
可用参数(所有参数都是必需的)
-n<name> 在ZooKeeper中设置的配置名称,可以通过管理界面,点击菜单,Cloud 选中 Tree / configs 下查看,配置列表-d<configset dir>配置设置为上传的路径。路径需要有一个“conf”目录,依次包含solrconfig.xml等。最好可以提供绝对路径-z<zkHost> Zookeeper IP 端口,多个zk用"," 分隔
SolrCloud是通过Zookeeper集群来保证配置文件的变更及时同步到各个节点上,所以,可以将配置文件上传到Zookeeper集群。
$ /opt/solr-6.6.0/bin/solr zk upconfig -z node1:2181,node2:2181,node3:2181 -n mynewconfig -d /opt/solr-6.6.0/server/solr/configsets/basic_configs/
响应
Connecting to ZooKeeper at node1:2181,node2:2181,node3:2181 ...
Uploading /opt/solr-6.6.0/server/solr/configsets/basic_configs/conf for config mynewconfig to ZooKeeper at node1:2181,node2:2181,node3:2181
删除上传到ZooKeeper 集群的solr 配置
rm 删除 -r 递归删除
$ /opt/solr-6.6.0/bin/solr zk rm -r /configs/mynewconfig -z node1:2181,node2:2181,node3:2181
响应
Connecting to ZooKeeper at node1:2181,node2:2181,node3:2181 ...
Removing Zookeeper node /configs/mynewconfig from ZooKeeper at node1:2181,node2:2181,node3:2181 recurse: true
Contact
出处:http://www.ymq.io/2017/08/23/SolrCloud
版权归作者所有,转载请注明出处
以上是关于大数据之 Solr 集群搭建的主要内容,如果未能解决你的问题,请参考以下文章