Elasticsearch+Kibana·入门·壹
Posted 欧尼焦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch+Kibana·入门·壹相关的知识,希望对你有一定的参考价值。
文章目录
1 认识elasticsearch
1.1 ES引入
1.1.1 elasticsearch作用
elasticsearch:一款从海量数据(
百万级别以上)中快速查找所需内容的开源搜索引擎。
例如:电商网站搜索商品

1.1.2 ES相关技术栈——ELK
此篇文章着重介绍elastic stack(ELK)技术栈:elasticsearch、kibana、Logstash、Beats实现ES搜索引擎功能。
注意: elasticsearch是ELK的核心,负责存储、搜索、分析数据

1.1.3 elasticsearch的底层lucene
Lucene**是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,官网地址:https://lucene.apache.org/ 。
1.1.4 elasticsearch与其他搜索技术(Solr)对比
1.2 正向索引与倒排索引
1.2.1 正向索引
条件:表(tb_goods)中的id创建索引
此时,根据表中id查询所需数据,就是正向索引

正向索引(正排索引):正排表以文档的ID为关键字,查找所需信息时需扫描表中每个文档中字的信息,直到找出所有包含所需信息的文档。
然而,
当搜索数据,条件是title符合"%手机%",
- 逐行获取数据,比如id为1的数据
逐行扫描(全表扫描)判断数据中的title是否符合搜索条件- 如若不符合,则以此循环,在面对百万级别数据时查询效率低下。
1.2.2.倒排索引
两个概念:
| 名词 | 解释 |
|---|---|
文档(Document) | 用来搜索的数据,对应数据库中,每一行数据就是一个文档。例如:一个商品信息 |
词条(Term) | 对文档数据进行算法拆分,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条 |
创建倒排索引(正向索引的特殊处理)流程:
- ①使用算法对文档进行拆分,得到一个个的此词条
- ② 创建表,每行数据包括词条、词条所在文档id、位置等信息
- ③ 由于词条唯一性,给词条创建索引,例如hash表结构索引
例如:对正向索引表拆分,有
小米关键字的文档对应id为1\\3\\4,以此类推,完成拆分

倒排索引的搜索流程:
- ① 用户输入条件“华为手机”进行搜索
- ② 对用户输入内容分词,得到词条:华为、手机
- ③ 凭借词条在倒排索引中查找,得到
词条所对应的文档id:1、2、3- ④ 最后,凭借查询得到的
词条所对应文档在正向索引中查询具体文档(正向索引表中id具有索引,查询性能较好,无需全表扫描)

1.2.3.正向、倒排索引比较
| 正向索引 | 倒排索引 |
|---|---|
| 正向索引传统根据id索引的方式 | 倒排索引先找到用户所需词条 |
| 根据词条查询,必须逐条获取每个文档,然后判断文档中是否包含所需词条 | 根据词条得到相对应文档id,其次根据id在正排表中获取id所对应文档。 |
1.2.4.正向、倒排索引优缺点
正向索引:
| 优点 | 缺点 |
|---|---|
| 可以给多个字段创建索引 | 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。 |
| 根据索引字段搜索、排序速度非常快 |
倒排索引:
| 优点 | 缺点 |
|---|---|
| 根据词条搜索、模糊搜索时,速度非常快 | 只能给词条创建索引,而不是字段 |
| 无法根据字段做排序 |
1.3 es相关概念
1.3.1 文档和字段
文档:ES面向文档存储,对应数据库中表中每行数据。文档数据最终会被序列化为JSON格式存储在ES中,其次JSON文档中的字段对应数据库表中每列,也就是
词条。

1.3.2.索引和映射
索引(Index):相同类型词条的集合
- 例如:
① 所有商品名称词条,可以组织在一起,称为商品的索引;
② 所有订单词条,可以组织在一起,称为订单的索引;

映射:数据库中字段有约束,对应ES索引库中就有映射(mapping)
1.3.3 mysql与elasticsearch对比
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table),而MySQL中索引时从0开始的下标 |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段/词条(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
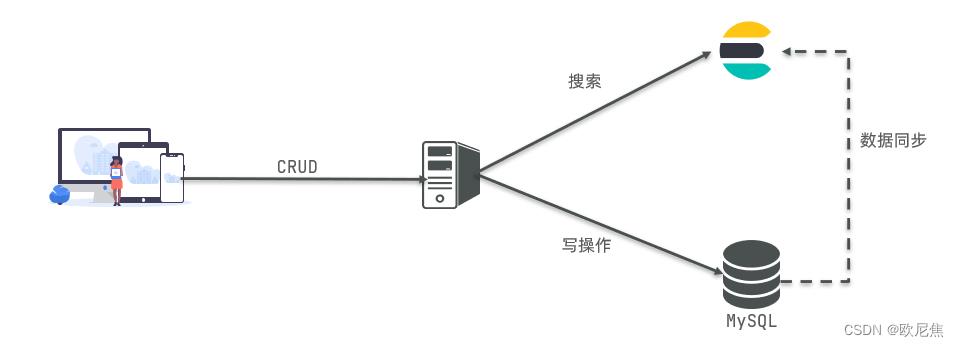
在企业中,MySQL常与ES结合使用:
1.3.4 DSL中属性解释
| 属性 | 解释 |
|---|---|
| _id | _id仅仅是一个字符串,与_index和_type组合时,就可以在es中唯一标识一个文档,当创建一个文档(相当于数据库中每一行数据)时,可以自定义_id,也可以让ES使用默认UUID自动生成 |
| _index | 索引(index)类似于MySQL(database),索引名字必须全部小写,不能以下划线开头,不能包含逗号。 |
| _type | 类型(type)类似于MySQL的table |
1.3.5 ES中特殊字段location、all
| 字段 | 解释 |
|---|---|
| location | 地理坐标,里面包含精度、纬度 |
| all | 一个组合字段,其目的是将多字段的值 利用copy_to合并,提供给用户搜索 |
地理坐标说明:

copy_to说明(把brand词条copy给all词条):

1.3.6 ES中别名aliases
示例:
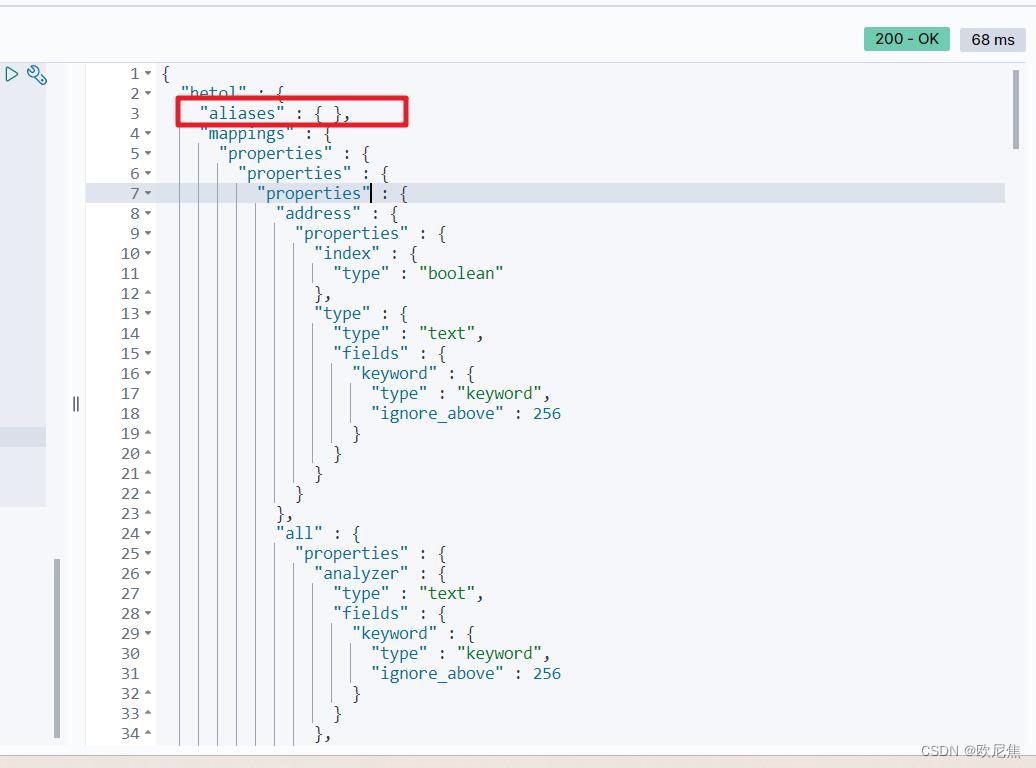
别名相关解释:
① ES中别名机制可类比数据库中视图。
② ES可对一个或多个索引指定别名,通过别名可以查找到一个或多个索引内容,ES会把别名映射到对应索引。
③ 可以对别名编写过滤器或路由,在系统中别名不能重复,也不能和索引名重复。
1.4.安装es、kibana、ik中文分词器
1.4.1 IK分词器的两种模式
| 模式 | 解释 |
|---|---|
| ik_smart | 智能切分,粗粒度 |
| ik_max_word | 最细切分,细粒度 |
1.4.2 IK分词器拓展词条、停用词条
① 利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
② 在词典中添加拓展词条或者停用词条
2 索引库操作
2.1 mapping(约束)映射属性
type:字段数据类型,常见的简单类型有:
| 类型 | 说明 |
|---|---|
| 字符串 | text(可分词的文本)、keyword(不可分词,例如:品牌、国家、ip地址) |
| 数值 | long、integer、short、byte、double、float |
| 布尔 | boolean |
| 日期 | date |
| 对象 | object |
① index:是否创建索引,默认为true
② analyzer:使用哪种分词器
③ properties:该字段的子字段
例如下面的json文档:
- 对应的每个字段映射(mapping):
① age:类型integer,参与搜索( “index”: true),无需分词( “type”: “keyword”)
②weight:类型为float,参与搜索( “index”: true),无需分词( “type”: “keyword”)
③isMarried:类型为boolean;参与搜索( “index”: true),无需分词( “type”: “keyword”)
④info:类型为字符串,需要分词器(type=text),参与搜索( “index”: true),需分词器,个人选用(“analyzer”: “ik_smart”)
⑤ email:类型为字符串,参与搜索( “index”: true),无需分词( “type”: “keyword”)
⑥ score:数组类型,但只需看元素的类型,类型为float;参与搜索( “index”: true),无需分词( “type”: “keyword”)
⑦ name:类型为object,需定义多个子属性
name.firstName;类型字符串,不需分词( “type”: “keyword”);参与搜索( “index”: true)
name.lastName;类型为字符串,不需分词( “type”: “keyword”);参与搜索( “index”: true)

2.2.索引库的CRUD
2.2.1 创建索引库和映射
基本语法:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
格式:
PUT /索引库名称
"mappings":
"properties":
"字段名":
"type": "text",
"analyzer": "ik_smart"
,
"字段名2":
"type": "keyword",
"index": "false"
,
"字段名3":
"properties":
"子字段":
"type": "keyword"
,
// ...略
示例:
PUT /heima
"mappings":
"properties":
"info":
"type": "text",
"analyzer": "ik_smart"
,
"email":
"type": "keyword",
"index": "falsae"
,
"name":
"properties":
"firstName":
"type": "keyword"
,
// ... 略
2.2.2.查询索引库
基本语法:
- 请求方式:GET
- 请求路径:/索引库名
- 请求参数:无
格式:
GET /索引库名
示例:

2.2.3.修改索引库
注意:倒排索引中数据结构发生改变(比如改变分词器),此时需重新创建倒排索引,因此索引库一旦创建,无法修改mapping已有字段。
- 虽然无法修改mapping中已有字段,但
允许添加新字段到mapping,不会对倒排索引产生影响。- 因此需要修改索引库时,需要先删除后添加新索引库。
语法说明:
PUT /索引库名/_mapping
"properties":
"新字段名":
"type": "integer"
示例:

2.2.4.删除索引库
语法:
- 请求方式:DELETE
- 请求路径:/索引库名
- 请求参数:无
格式:
DELETE /索引库名
3.文档操作
3.1.新增文档
语法:
POST /索引库名/_doc/文档id
"字段1": "值1",
"字段2": "值2",
"字段3":
"子属性1": "值3",
"子属性2": "值4"
,
// ...
示例:
POST /heima/_doc/1
"info": "张三学生",
"email": "zs@qq.cn",
"name":
"firstName": "三",
"lastName": "张"
3.2.查询文档
语法:
GET /索引库名称/_doc/id
示例:
GET /person/_doc/1
3.3.删除文档
语法:
DELETE /索引库名/_doc/id值
示例:
DELETE /person/_doc/1
3.4.修改文档
| 全量修改 | 直接覆盖原来的文档 |
|---|---|
| 增量修改 | 修改文档中的部分字段 |
3.4.1.全量修改
全量修改:
覆盖原来的文档,本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除,当id不存在,第二步新增也会执行,也就是从修改操作变成新增操作。
语法:
PUT /索引库名/_doc/文档id
"字段1": "值1",
"字段2": "值2",
// ... 略
示例:
PUT /heima/_doc/1
"info": "学生信息",
"email": "zy2@itcast.cn",
"name":
"firstName": "云",
"lastName": "赵"
3.4.2.增量修改
增量修改:只修改指定id匹配到对应文档中的字段。
语法:
POST /索引库名/_update/文档id
"doc":
"字段名": "新的值",
示例:
POST /heima/_update/1
"doc":
"email": "ZhaoYun@itcast.cn"
4.RestAPI
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
本篇使用:Java HighLevel Rest Client客户端API
4.1 根据MySQL数据库书写DSL
4.1.1 数据库表结构
CREATE TABLE `tb_hotel` (
`id` bigint(20) NOT NULL COMMENT '酒店id',
`name` varchar(255) NOT NULL COMMENT '酒店名称;例:7天酒店',
`address` varchar(255) NOT NULL COMMENT '酒店地址;例:航头路',
`price` int(10) NOT NULL COMMENT '酒店价格;例:329',
`score` int(2) NOT NULL COMMENT '酒店评分;例:45,就是4.5分',
`brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家',
`city` varchar(32) NOT NULL COMMENT '所在城市;例:上海',
`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级,从低到高分别是:1星到5星,1钻到5钻',
`business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹桥',
`latitude` varchar(32) NOT NULL COMMENT '纬度;例:31.2497',
`longitude` varchar(32) NOT NULL COMMENT '经度;例:120.3925',
`pic` varchar(255) DEFAULT NULL COMMENT '酒店图片;例:/img/1.jpg',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
4.1.2 ES的DSL
PUT /hotel
"mappings":
"properties":
"id":
"type": "long"
,
"name":
"type": "text",
"analyzer": "ik_smart",
"copy_to": "all"
,
"address":
"type": "keyword",
"index": false
,
"price":
"type": "integer"
,
"score":
"type": "integer"
,
"brand":
"type": "keyword",
"copy_to": "all"
,
"city":
"type": "keyword",
"index": true,
"copy_to": "all"
,
"starName":
"type": "keyword"
,
"business":
"type": "text",
"analyzer": "ik_smart"
,
"location":
"type": "geo_point"
,
"all":
"type": "text"
, "analyzer": "ik_smart"
,
"pic":
"type": "keyword",
"index": false
4.2 SpringBoot使用Java HighLevel Rest Client API
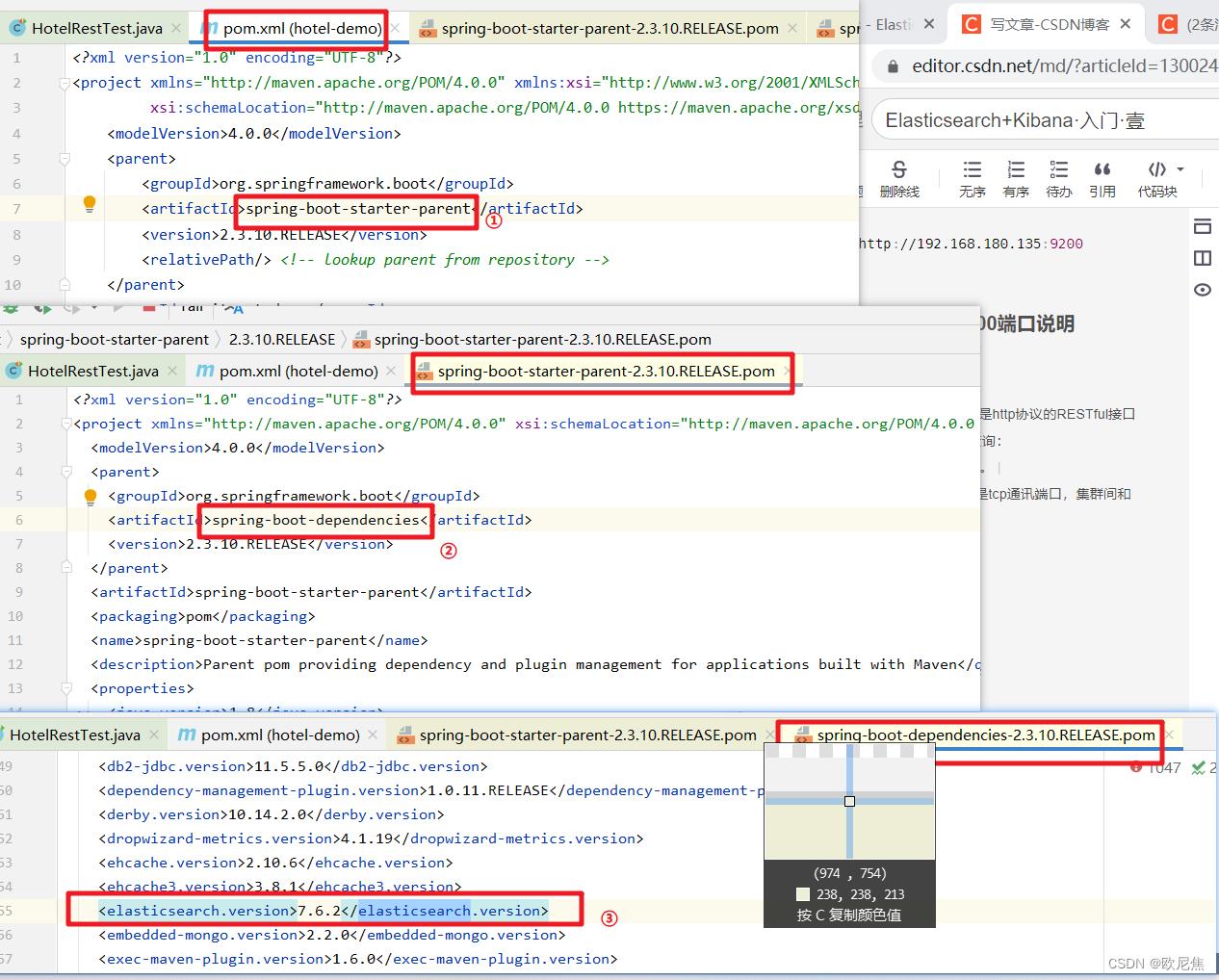
4.2.1 查看SpringBoot默认的ES版本是7.6.2
4.2.2 maven引入API坐标
<!--引入es的RestHighLevelClient依赖-->
<dependency> <groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
<!--SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本-->
<properties>
<java.version>1.8</java.version> <elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
4.2.3 yml添加配置
spring:
elasticsearch:
rest:
uris: http://192.168.180.135:9200
4.2.4 ES中9200与9300端口说明
| 端口 | 说明 |
|---|---|
| 9200 | ES节点与外部通讯端口。它是http协议的RESTful接口(各种CRUD操作都是通过端口,如查询:http://localhost:9200/user/_search)。 |
| 9300 | ES节点间通讯使用端口。它是tcp通讯端口,集群间和TCPclient都通过此端口。 |
4.3 创建索引库
4.3.1 封装DSL常量类
//Constants.java
public class Constants
public static final String MAPPING ="\\n" +
" \\"properties\\": \\n" +
" \\"id\\":\\n" +
" \\"type\\": \\"long\\"\\n" +
" ,\\n" +
" \\"name\\":\\n" +
" \\"type\\": \\"text\\",\\n" +
" \\"analyzer\\": \\"ik_smart\\",\\n" +
" \\"copy_to\\": \\"all\\"\\n" +
" ,\\n" +
" \\"address\\":\\n" +
" \\"type\\": \\"keyword\\", \\n" +
" \\"index\\": false\\n" +
" ,\\n" +
" \\"price\\":\\n" +
" \\"type\\": \\"integer\\"\\n" +
" ,\\n" +
" \\"score\\":\\n" +
" \\"type\\": \\"integer\\"\\n" +
" ,\\n" +
" \\"brand\\":\\n" +
" \\"type\\": \\"keyword\\",\\n" +
" \\"copy_to\\": \\"all\\"\\n" +
" ,\\n" +
" \\"city\\":\\n" +
" \\"type\\": \\"keyword\\",\\n" +
" \\"index\\": true,\\n" +
" \\"copy_to\\": \\"all\\"\\n" +
" ,\\n" +
" \\"starName\\":\\n" +
" \\"type\\": \\"keyword\\"\\n" +
" ,\\n" +
" \\"business\\":\\n" +
" \\"type\\": \\"text\\",\\n" +
" \\"analyzer\\": \\"ik_smart\\"\\n" +
" ,\\n" +
" \\"location\\":\\n" +
" \\"type\\": \\"geo_point\\"\\n" +
" ,\\n" +
" \\"all\\":\\n" +
" \\"type\\": \\"text\\"\\n" +
" , \\"analyzer\\": \\"ik_smart\\"\\n" +
" ,\\n" +
" \\"pic\\":\\n" +
" \\"type\\": \\"keyword\\",\\n" +
" \\"index\\": false\\n" +
" \\n" +
" \\n" +
" ";
4.3.2 测试类——创建索引库
@Test
public void testCreateIndex() throws Exception
//目标:向es服务器发送请求,创建索引
// 1.创建request对象,创建——>create
CreateIndexRequest createIndexRequest = new CreateIndexRequest("hetol");
// 2.准备请求参数:DSL语句
// 2.1 Constants.MAPPING是我们定义的常量类
// 2.2 XContentType.JSON是由于创建索引时是JSON格式
createIndexRequest.mapping(Constants.MAPPING, XContentType.JSON);
// 3.通过ES客户端向ES服务器通信
// 3.1 RequestOptions:请求方式(同步/异步),默认是同步
CreateIndexResponse response = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
4.3.3 RequestOptions:请求方式(同步/异步)探究
ELK:elasticsearch快速入门之Kibana+Logstash安装
1.2、kibana快速入门
kinana的安装相对于elasticsearch的安装更为简单。kibana用于展示或是操作es中的数据。主要步骤就是配置kibana的配置文件。甚至保持默认值,都可以运行。注意kibana是由node开发。默认占用的端口号为5601,所以,如果要查看kibana的进程,可以使用netstat -tunlp | grep 5601 或使用 ps -ef | grep node查看。
官方有完整的安装过程:
https://www.elastic.co/guide/en/kibana/7.6/getting-started.html
1、下载并解压kinana
https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-linux-x86_64.tar.gz
2、解压到指定的目录下
$ tar -zxvf kibana-7.6.2-linux-x86_64.tar.gz -C /home/es/program/
由于解压后,目录太长,这儿修改一下目录的名称:
$ mv kibana-7.6.2-linux-x86_64 kibana
3、修改kibana的配置文件
在$KIBANA_HOME/config目录下的kibana.yml就是kibana的配置文件.
本文配置以下内容,其他都保持默认值:
server.port: 5601
server.host: "server101"
server.name: "server101"
elasticsearch.hosts: ["http://server101:9200"]
I18n.locale: “zh-CN” #配置中文
4、启动kibana
$cd $KINANA_HOME
$ ./bin/kibana 此种方式,kibana会将所有日志信息输出到控制台。可以使用 $ ./bin/kibana &以后台方式运行。
5、访问
在浏览器中,输入:http://server101:5601访问,可以导入一些测试数据后,将显示以下效果:
kibana的配置可以参考官方网站。
1.3、logstash快速入门
1、下载 logstash
https://artifacts.elastic.co/downloads/logstash/logstash-7.6.2.tar.gz
2、解压
$ tar -zxvf logstash-7.6.2.tar.gz -C /home/es/program/
$ mv logstash-7.6.2 logstash
1、使用logstash采集日志
1、logstash是一个重量级的日志采集工具,它同时还可以对采集到的数据处理后再保存到es中去。
2、在配置logstash之前,先启动es。
步1、配置logstash配置文件
在$LOGSTASH_HOME/config目录下,创建logstash1.conf文件。并添加以下配置。
$ touch logstash1.conf
$vim logstash1.conf
input {
file {
path => "/home/es/logs/*.log" #读取日志的目录
type => "elasticsearch"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "mylog-%{+YYYY.MM.dd}"
}
stdout { #在控制台显示数据
codec => rubydebug
}
}
步2、启动logstash
通过-f可以指定配置文件:
logstash]$ ./bin/logstash -f config/logstash1.conf
以非后台方式启动,可以在控制台,查看到logstash接收到的数据。
步3、测试
在/home/es/logs目录下,输出一些日志进行测试:
[es@server101 logs]$ echo Hello >> log.log
[es@server101 logs]$ echo 中文信息 >> log.log
[es@server101 logs]$ echo Hello2 >> log.log
[es@server101 logs]$ echo 使用空格分开的测试 空格后面的数据 >> log.log
此时,转到logstash的后台,查看数据:
{
"path" => "/home/es/logs/log.log",
"@version" => "1",
"@timestamp" => 2020-05-01T14:25:33.080Z,
"host" => "server101",
"message" => "Hello",
"type" => "elasticsearch"
}
{
"path" => "/home/es/logs/log.log",
"@version" => "1",
"@timestamp" => 2020-05-01T14:25:49.140Z,
"host" => "server101",
"message" => "中文信息",
"type" => "elasticsearch"
}
{
"path" => "/home/es/logs/log.log",
"@version" => "1",
"@timestamp" => 2020-05-01T14:25:54.161Z,
"host" => "server101",
"message" => "Hello2",
"type" => "elasticsearch"
}
{
"path" => "/home/es/logs/log.log",
"@version" => "1",
"@timestamp" => 2020-05-01T14:26:28.266Z,
"host" => "server101",
"message" => "使用空格分开的测试 空格后面的数据",
"type" => "elasticsearch"
}
2、读取filebeat的数据
步1、配置logstash
在$LOGSTASH_HOME/config目录下,新增加:logstash2.conf,并添加以下内容:
$touch logstash2.conf
$vim logstash2.conf
input {
beats {
port => 5044 #logstash监听的端口
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "mybeats-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}
步2、启动logstash
logstash]$ ./bin/logstash -f config/logstash2.conf
步3、配置filebeat
下载并上传filebeat,解压并重命名:
$ tar -zxvf filebeat-7.6.2.tar.gz -C /home/es/program/
$ mv filebeat-7.6.2 filebeat
编辑filebeat.yml文件:(由地filebeat.yml中已经存在了一些配置,这儿只配置logstash即可,可以重新创建一个新的配置文件)内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/es/logs/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
#output.elasticsearch: #这儿删除es的配置
#hosts: [“localhost:9200”]
output.logstash: #这儿是打开logstash的配置
hosts: [“localhost:5044”]
#其他地方,保持默认就可以了。
启动filebeat:
filebeat]$ ./filebeat -e -c filebeat.yml
测试,由于filebeat监听的是/home/es/logs/*.log文件,所以,我们在这个目录下,创建几个文件,并输入数据:
[es@server101 logs]$ echo Hello >> log.log
[es@server101 logs]$ echo 你好 这是新行 >> log.log
现在,直接查询logstash的控制输出如下:
{
..省略..
"message" => "Hello",
"@version" => "1"
}
{
..省略..
"message" => "你好 这是新行",
"@version" => "1"
}
到此,已经可以基本上了解filebeat将数据发送到logstash的过程了。
其他TODO:
logstash中的filter将数据处理成json对象。
以上是关于Elasticsearch+Kibana·入门·壹的主要内容,如果未能解决你的问题,请参考以下文章