干翻Hadoop系列之:Hadoop前瞻之分布式知识
Posted 岁岁种桃花儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干翻Hadoop系列之:Hadoop前瞻之分布式知识相关的知识,希望对你有一定的参考价值。
前言
一:海量数据价值
二:海量数据两个棘手问题
1:海量数据如何存储?
掌握分布式存储数据的思想。
A:方案1:单机存储磁盘不够加磁盘
限制问题:
1:一台计算机不能无限制拓充
2:拓充的很多之后,计算机进行多磁盘寻址的问题。
1TB硬盘,100MB存储速度的时候
B:方案2:分布式存储
一台机器存不下,多台机器共同存储,读取数据时,多台数据同时读取数据。
三:海量数据如何计算
传统计算方式,时间很长,效率很低,能不能搞出来都是个问题。
解决方案:多台计算机同时计算,进行分布式计算。
第一章:大数据知识补充
一:大数据业务分析步骤
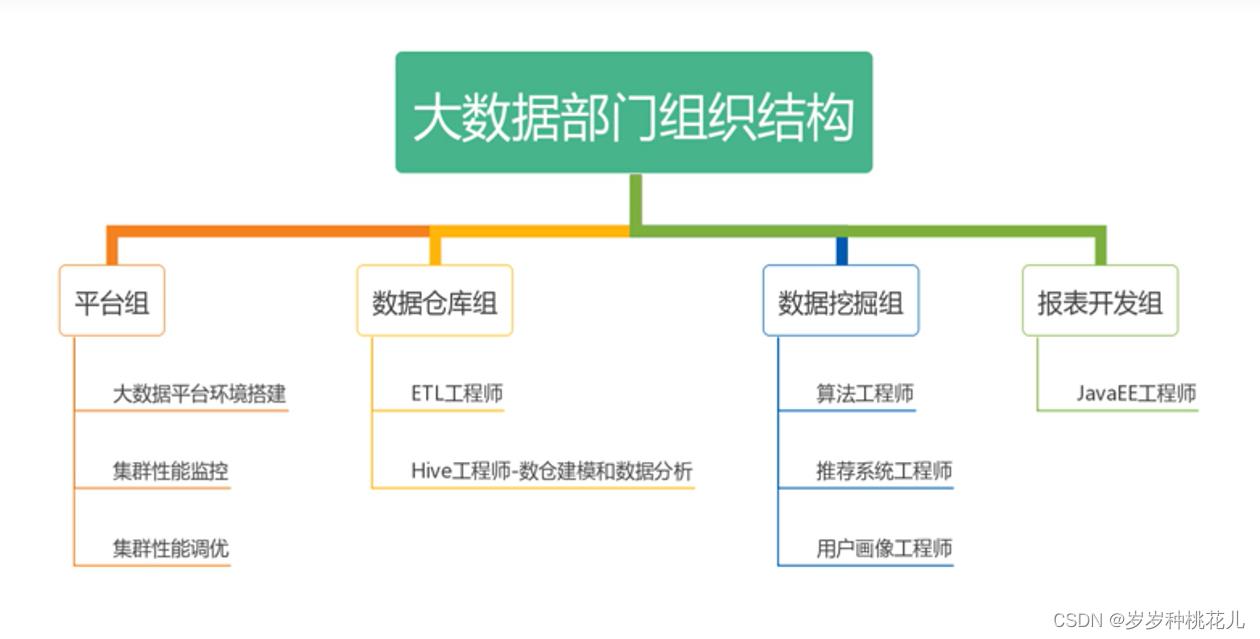
二:大数据部门介绍
第二章:分布式技术栈
一:分布式概念
1:单机到分布式
访问量变高,单机扛不住
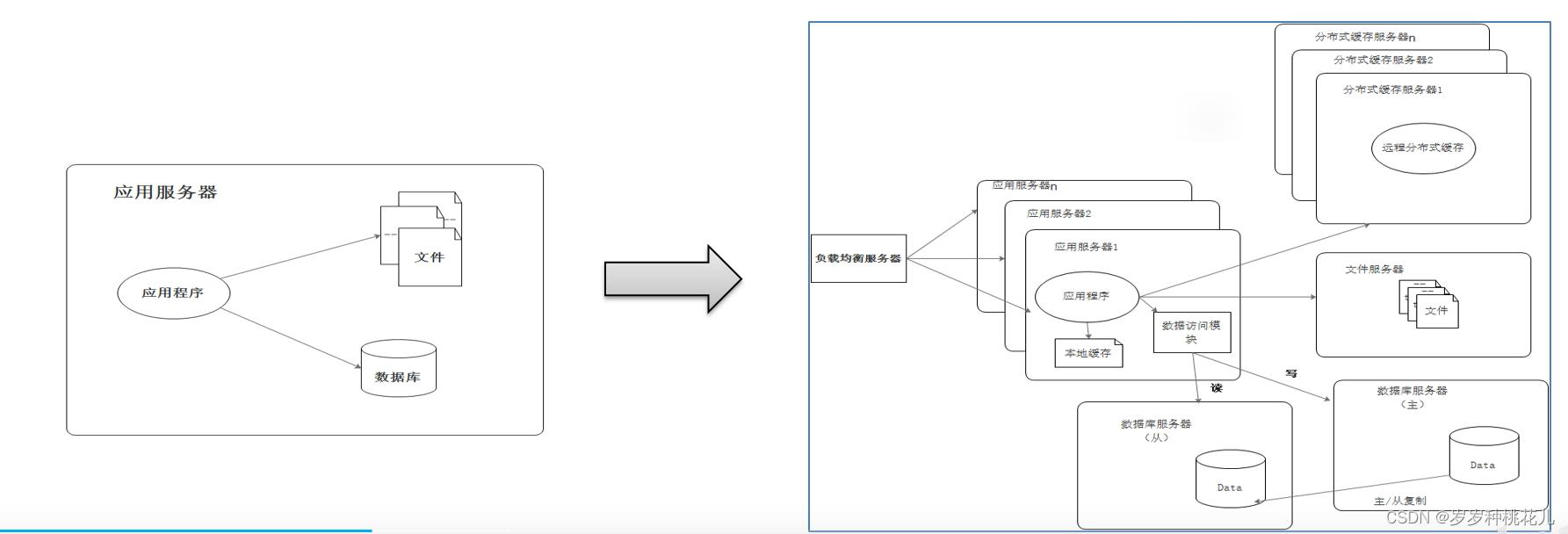
2:海量数据单机存不下、算不了
多线程计算,把CPU和内存榨干也是有上限瓶颈的。单机计算能力是受到物理硬件上限的限制。

二:分布式系统概述
分布式系统是一个硬件或软件组件分布在不同的网络计算机上
彼此之间仅仅通过消息传递进行通信和协调的系统。
一群互相独立计算机集合共同对外提供服务
对于系统的用户来说,就像是一台计算机在提供服务样
三:几个核心概念
1:负载均衡
概念:
Load Balance简称LB。将负载(工作任务)进行平衡、分摊到多个操作单元上进行。
说人话:
假设:单机服务最大qps为5w,现在没秒访问量有12W,单机肯定玩不转,需要加到三台机器。
图解:
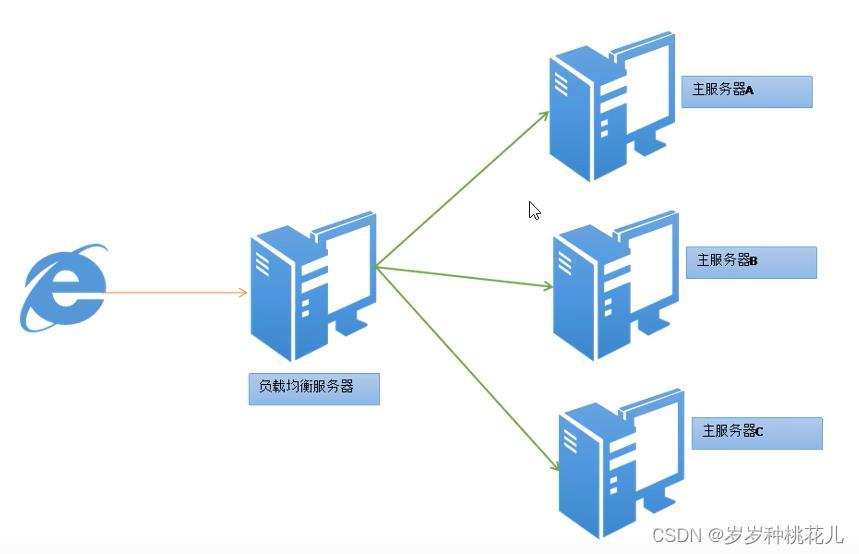
LB强调的是分布式概念呢?还是集群概念的?
集群的概念,因为这里是LB对应的后台服务是一样的,所以更加注重的是集群的概念。
2:故障转移
什么是单点故障?
假设一个场景,我们一个门户网页,需要订单系统、商品系统、支付系统…进行支持。结果突然某台服务器嗝屁了 ,此为单点故障。
故障转移:
1:当活动的服务或者应用意外终止时,快速启用冗余设备、备用服务器实例、系统、硬件、网络接替它工作
2:故障转移也称之为容错系统,所谓容错只是可以容忍错误的发生。
3:故障转移的和核心是设置备份,出现故障时,主备切换。
4:主备切换的前提是数据状态保持一致。服务状态一致,缓存状态一致,数据存储状态一致。
3:伸缩性
伸缩线称之为弹性可拓展性。动态拓展缩减我们的后台实例数量
流量大时拓展服务器,流量小时缩减服务器。
总结:
1:负载均衡:解决一个处理不了,多个共同处理的问题
2:故障转移:解决单点故障 容忍错误发生 业务连续
3:伸缩性:动态扩容,缩容
大数据系列之Hadoop框架
Hadoop框架中,有很多优秀的工具,帮助我们解决工作中的问题。
Hadoop的位置

从上图可以看出,越往右,实时性越高,越往上,涉及到算法等越多。
越往上,越往右就越火……
Hadoop框架中一些简介
HDFS
HDFS,(Hadoop Distributed File System) hadoop分布式文件系统。在Google开源有关DFS的论文后,由一位大牛开发而成。HDFS的建立在集群之上,适合PB级大量数据的存储,扩展性强,容错性高。它也是Hadoop集群的基础,大部分内容都存在了HDFS上。
MapReduce
MapReduce,是Hadoop中的计算框架,由两部分构成。Map操作以及Reduce操作。MapReduce,会生成计算的任务,分配到各个节点上,执行计算。这样就避免了移动集群上面的数据。而且其内部,也有容错的功能。在计算过程中,某个节点宕掉之后,会有策略进行应对。Hadoop集群,上层的一些工具,比如Hive或者Pig等,都会转换为基本的MapReduce任务来执行。
HBase
HBase源自谷歌的BigTable。HBase是面向列存储的数据库,性能高,扩展性强,可靠性高。HBase的内容,存储在HDFS上,当然它也可以使用其他的文件系统,如S3等。HBase作为一个顶级项目,使用频率很高。如:我们可以用来存储,爬虫爬来的网页的信息等。具体的HBase的概念请见后续详细说明。延迟较低。
Hive
Hive,是一个查询的工具,在HBase中,对于SQL的支持不太好。而Hive解决了这一类的问题。以sql形式操作hbase,更爽一些。Hive编写的一些sql语句,其实最后也还是会变成MapReduce程序。当然这种查询,不能与关系型数据库mysql等比较,hive查询时,是秒级或分钟级的,时间比较长。
Sqoop
Sqoop,也是一个很神奇的数据同步工具。在关系型数据库中,我们会遇到一种情景,将Oracle数据导入到Mysql,或者将Mysql数据,导入到Oracle。那其实Sqoop也是类似的功能。sqoop可以将Oracle,Mysql等关系型数据库中的数据,导入到HBase,HDFS上,当然也可以从HDFS或HBase导入到Mysql或Oracle上。
Flume
Flume,是日志收集工具,是分布式的,可靠的,容错的,可以定制的。应用场景如:100台服务器,需要监测各个服务器的运行情况,这时可以用flume将各个服务器的日志,收集过来。Flume也有两个版本。Flume OG 和Flume NG。现在基本都用NG了。
Impala
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。Imapa可以和Phoenix,Spark Sql联系起来了解一下。
Spark
Spark是一个内存计算的框架。目前一个大的趋势。MapReduce会有很大的IO操作,而Spark是在内存中计算。速度是Hadoop的10倍(官网上这样说的)。Spark是目前一个趋势,是需要了解的。
Zookeeper
Zookeeper,动物管理员。Zookeeper叫分布式协作服务。作用主要是,统一命名,状态同步,集群管理,配置同步。Zookeeper在HBase,以及Hadoop2.x中,都有用到。
Mahout
数据挖掘算法库,里面内置了大量的算法。可以用来做预测、分类、聚类等。工具很强大,但是技术要求能力较高。
Pig
和Hive类似。具体区别自己搜搜。Pig可以构建数据仓库。可用来对数据仓库中数据,进行查询分析。Pig也有自己的查询语法,很不幸,不是sql形式,Pig Latin。
Ambari
Ambari是一个管理平台。可以对集群进行统一的部署。也是很方便的。
以上是关于干翻Hadoop系列之:Hadoop前瞻之分布式知识的主要内容,如果未能解决你的问题,请参考以下文章