视觉SLAM总结——SuperPoint / SuperGlue
Posted Leo-Peng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视觉SLAM总结——SuperPoint / SuperGlue相关的知识,希望对你有一定的参考价值。
视觉SLAM总结——SuperPoint / SuperGlue
视觉SLAM总结——SuperPoint / SuperGlue
在我刚开始接触SLAM算法的时候听到过一个大佬讲:“SLAM其实最重要的是前端,如果特征匹配做得足够鲁棒,后端就可以变得非常简单”,当时自己总结过一篇传统视觉特征的博客视觉SLAM总结——视觉特征子综述,由于当时对深度学习了解不够,因此并没有涵盖基于深度学习的视觉特征匹配方法,而实际上,基于深度学习的特征匹配效果要远优于传统方法。本博客结合代码对2018年提出的SuperPoint和2020年提出的SuperGlue两篇最为经典的深度学习算法进行学习总结。
1. SuperPoint
SuperPoint发表于2018年,原论文名为《SuperPoint: Self-Supervised Interest Point Detection and Description
》,该方法使用无监督的方式训练了一个用于提取图像特征以及特征描述子的网络。
1.1 网络结构
SuperPoint的网络结构如下图所示:
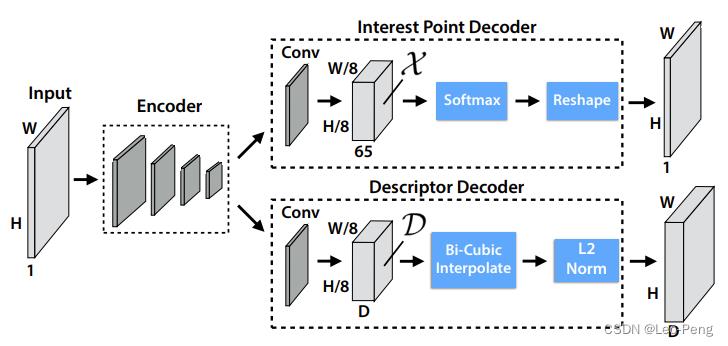
我们知道,图像特征通常包括两部分,特征点已经特征描述子,上图中两个分支即分别用来提取特征点和特征描述子。网络首先使用了VGG-Style的Encoder用于降低图像尺寸提取特征,Encoder部分由卷积层、Max-Pooling层和非线性激活层组成,通过三个Max-Pooling层将图像尺寸变为输出的
1
/
8
1/8
1/8,代码如下:
# Shared Encoder
x = self.relu(self.conv1a(data['image']))
x = self.relu(self.conv1b(x))
x = self.pool(x)
x = self.relu(self.conv2a(x))
x = self.relu(self.conv2b(x))
x = self.pool(x)
x = self.relu(self.conv3a(x))
x = self.relu(self.conv3b(x))
x = self.pool(x)
x = self.relu(self.conv4a(x))
x = self.relu(self.conv4b(x)) # x的输出维度是(N,128,W/8, H/8)
对于特征点提取部分,网路先将维度 ( W / 8 , H / 8 , 128 ) (W/8, H/8, 128) (W/8,H/8,128)的特征处理为 ( W / 8 , H / 8 , 65 ) (W/8, H/8, 65) (W/8,H/8,65)大小,这里的 65 65 65的含义是特征图的每一个像素表示原图 8 × 8 8\\times8 8×8的局部区域加上一个当局部区域不存在特征点时用于输出的Dustbin通道,通过Softmax以及Reshape的操作,最终特征会恢复为原图大小,代码如下:
# Compute the dense keypoint scores
cPa = self.relu(self.convPa(x)) # x维度是(N,128,W/8, H/8)
scores = self.convPb(cPa) # scores维度是(N,65,W/8, H/8)
scores = torch.nn.functional.softmax(scores, 1)[:, :-1] # scores维度是(N,64,W/8, H/8)
b, _, h, w = scores.shape
scores = scores.permute(0, 2, 3, 1).reshape(b, h, w, 8, 8) # scores维度是(N,W/8, H/8, 8, 8)
scores = scores.permute(0, 1, 3, 2, 4).reshape(b, h*8, w*8) # scores维度是(N,W/8, H/8)
scores = simple_nms(scores, self.config['nms_radius'])
这里指的注意的是我们是先对包括Dustbin通道的特征图进行Softmax操作后再进行Slice的。假如没有Dustbin通道,当 8 × 8 8\\times8 8×8的局部区域内没有特征点时,经过Softmax后64维的特征势必还是会有一个相对较大的值输出,但加入Dustbin通道后就可以避免这个问题,因此需要在Softmax操作后再进行Slice。最后再经过NMS后相应较大的位置即为输出的特征点。
对于特征描述子提取部分,网络先将维度 ( W / 8 , H / 8 , 128 ) (W/8, H/8, 128) (W/8,H/8,128)的特征处理为 ( W / 8 , H / 8 , 256 ) (W/8, H/8, 256) (W/8,H/8,256)大小,其中 256 256 256将是我们即将输出的特征的维度。按照通道进行归一化后根据特征点的位置通过双线性插值得到特征向量。
# Compute the dense descriptors
cDa = self.relu(self.convDa(x))
descriptors = self.convDb(cDa) # descriptor的维度是(N,256,8,8)
descriptors = torch.nn.functional.normalize(descriptors, p=2, dim=1) # 按通道进行归一化
# Extract descriptors
descriptors = [sample_descriptors(k[None], d[None], 8)[0]
for k, d in zip(keypoints, descriptors)]
其中双线性插值相关的操作在sample_descriptors中,该函数如下:
def sample_descriptors(keypoints, descriptors, s: int = 8):
""" Interpolate descriptors at keypoint locations """
b, c, h, w = descriptors.shape
keypoints = keypoints - s / 2 + 0.5
keypoints /= torch.tensor([(w*s - s/2 - 0.5), (h*s - s/2 - 0.5)],
).to(keypoints)[None]
# 这里*s的原因是keypoints在(W,H)特征图上提取的,而descriptor目前是在(W/s,H/s)的特征图上提取的
keypoints = keypoints*2 - 1 # normalize to (-1, 1)
args = 'align_corners': True if torch.__version__ >= '1.3' else
descriptors = torch.nn.functional.grid_sample(
descriptors, keypoints.view(b, 1, -1, 2), mode='bilinear', **args) # 双线性插值
descriptors = torch.nn.functional.normalize(
descriptors.reshape(b, c, -1), p=2, dim=1)
return descriptors
以上就完成了SuperPoint前向部分特征点和特征向量的提取过程,接下来看下这个网络是如何训练的?
1.2 损失函数
首先我们看下基于特征点和特征向量是如何建立损失函数的,损失函数公式如下: L ( X , X ′ , D , D ′ ; Y , Y ′ , S ) = L p ( X , Y ) + L p ( X ′ , Y ′ ) + λ L d ( D , D ′ , S ) \\mathcalL\\left(\\mathcalX, \\mathcalX^\\prime, \\mathcalD, \\mathcalD^\\prime ; Y, Y^\\prime, S\\right)=\\mathcalL_p(\\mathcalX, Y)+\\mathcalL_p\\left(\\mathcalX^\\prime, Y^\\prime\\right)+\\lambda \\mathcalL_d\\left(\\mathcalD, \\mathcalD^\\prime, S\\right) L(X,X′,D,D′;Y,Y′,S)=Lp(X,Y)+Lp(X′,Y′)+λLd(D,D′,S)其中 L p \\mathcalL_p Lp为特征点相关的损失, L d \\mathcalL_d Ld为特征向量相关的损失,其中 X \\mathcalX X、 Y Y Y、 D \\mathcalD D分别为图像上通过网络提取的特征点、特征向量和特征点的真值。
特征点相关损失 L p \\mathcalL_p Lp定义为一个交叉熵损失: L p ( X , Y ) = 1 H c W c ∑ h = 1 w = 1 H c , W c l p ( x h w ; y h w ) \\mathcalL_p(\\mathcalX, Y)=\\frac1H_c W_c \\sum_h=1 \\\\ w=1^H_c, W_c l_p\\left(\\mathbfx_h w ; y_h w\\right) Lp(X,Y)=HcWc1h=1w=1∑Hc,Wclp(xhw;yhw)其中 l p ( x h w ; y h w ) = − log ( exp ( x h w y ) ∑ k = 1 65 exp ( x h w k ) ) l_p\\left(\\mathbfx_h w ; y_h w\\right)=-\\log \\left(\\frac\\exp \\left(\\mathbfx_h w y\\right)\\sum_k=1^65 \\exp \\left(\\mathbfx_h w k\\right)\\right) lp(xhw;yhw)=−log(∑k=165exp(xhwk)exp(xhwy))其中 H c = H / 8 H_c=H/8 Hc=H/8, W c = W / 8 W_c=W/8 Wc=W/8; y h w y_h w yhw
以上是关于视觉SLAM总结——SuperPoint / SuperGlue的主要内容,如果未能解决你的问题,请参考以下文章