C生万物 | 十分钟带你学会位段相关知识
Posted 烽起黎明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C生万物 | 十分钟带你学会位段相关知识相关的知识,希望对你有一定的参考价值。


结构体相关知识可以先看看这篇文章 —— 链接
一、什么是位段
位段的声明和结构是类似的,有两个不同:
- 位段的成员必须是
int、unsigned int或signed int - 位段的成员名后边有一个冒号和一个数字
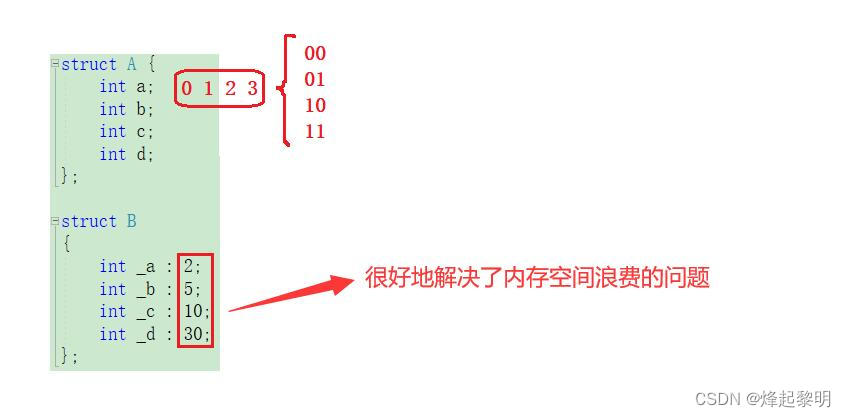
- 在下面,我分别写了一个结构体和一个位段,注意看位段的写法和结构体有什么不同
//结构体
struct A
int a;
int b;
int c;
int d;
;
//位段
struct B
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
;
- 然后我们
sizeof去计算一下这个结构体的大小
printf("结构体大小:%d\\n", sizeof(struct A));
printf("位段大小:%d\\n", sizeof(struct B));
可以看到,结构体的大小是16,位段是8,二者为何会存在区别呢?原因在于这个: 2吗?
- 那根据位段后面的这些数字,我们可以初步去断定可能大小是这些数组的总和,再转换为字节的。计算一下可以知道为
47b,在内存中1B = 8b,要存下这个47个比特位的话应该6个字节就够了,但是结果为什么是8呢?我们不得而知😐

学习了位段的相关知识后你就知道了
二、位段的内存分配
首先来科普一下位段的相关知识📖
- 位段的成员可以是 int unsigned int signed int 或者是 char (属于整形家族)类型
- 位段的空间上是按照需要以4个字节
[int]或者1个字节[char]的方式来开辟的。 - 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段
- 那从上面我们就可以提取出一些信息,知道了对于整型而言会开辟出4个字节的数据给到位段作为存放,那接下去呢我们就来分析一下这个位段
- 仔细观察可以得知每个成员都是整型,那首先开辟出32个比特位
_a占了2个比特位,还剩下【30b】_b占了5个比特位,还剩下【25b】_c占了10个比特位,还剩下【15b】_d占了30个比特位,但是剩下的【15b】不够用了,此时编译器会继续开辟出4B,也就是32b的空间来存放
- 所以最后的结果就是
4 + 4 = 8B
struct B
//4Byte - 32bit
int _a : 2; //30
int _b : 5; //25
int _c : 10; //15
//4Byte - 32bit
int _d : 30;
//4 + 4 = 8
;
看了我上面的这样计算,你一定会有这些疑问
💬 第一次是32b用剩后的【15b】去哪儿了呢?
💬 _d使用的是【15b】+ 后面开辟出来的32b,还是只用到后面的32b呢?
💬 难道所有平台都是这样吗?有没有不一样的计算方法?
- 上面是很多同学在课后提出来的疑问,关于这些,你在看完了我下面的分析后就会明白了👇
内存图分析位段分布
接下去我就通过对位段进行分析,然后观察内存分布来揭晓上面究竟是如何计算的。
为了方便期间,这里换一组位段,但是换汤不换药
struct S
char a : 3;
char b : 4;
char c : 5;
char d : 4;
;
int main(void)
struct S s = 0 ;
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
return 0;
- 首先来看一下存放这个位段需要的字节数。可以看到这个位段中的每个成员都是
char类型的,所以编译器会首先为其分配一个字节的空间,然后随着变量的存入,最终是需要三个字节
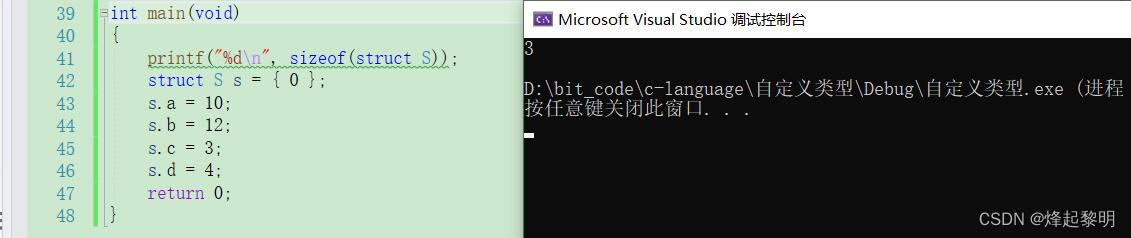
然后我们来逐一分析一下💻
- 刚才说了,这个位段在内存中需要开辟三个字节,这些变量要怎么存呢,首先看到变量a占了3个比特位,那是从左边的三位开始放还是右边的三位呢?总不可以从中间开始放吧!
- 那我们假设一下,从右边往左边放,那么
a放完后就是b,占4个比特位,但是放c的时候就放不下了,所以需要在开辟1个字节的空间,此时d再来放的话也放不下了,所以也要再开辟1个字节 ,最后也就需要3个字节的空间
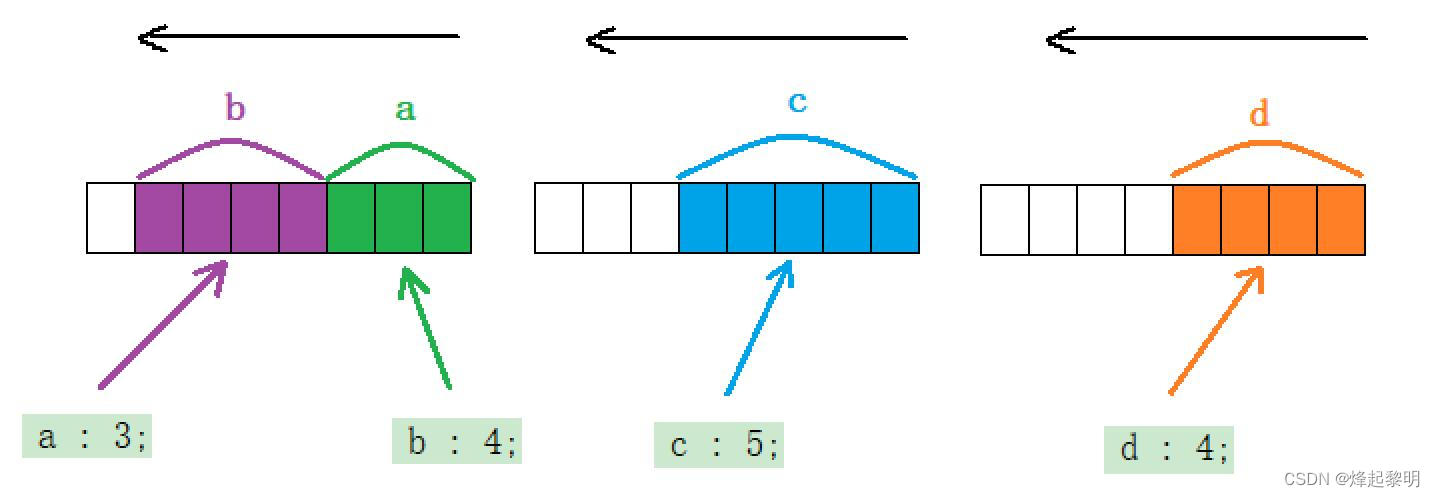
【详细分析如下】:
- 接下去我们就根据main函数中对位段各变量的初始化,来看看位段在内存中的分布情况:
a的初始值为10,不过这是十进制,转换为二进制形式的话就是[1010],转看位段这里a变量的是占了3位,所以会截断成010,将它放到第一个字节处的右边3个比特位处 - 接下去是
b,初始值为12,转换为二进制形式的话就是[1100],而b在内存中也刚好是占4个比特位的大小,刚好第一个字节处还可以放得过,所以继续顺位放置 - 然后是
c,初始值为3,转换为二进制形式的话就是11,但是c在内存中也占5个比特位的大小,所以要在前面做一个扩充便为[00011],但是第一个字节放不下了,上面放了【3】+【4】=【7】,只剩下1个比特位,那我们考虑再开一个字节的空间,为了保持连续性就直接把这个5个比特位的数据放到第二个字节的右边 - 最后的是
d,初始值为4,转换为二进制形式的话就是100,不过d在内存中也占4个比特位的大小,所以要在前面补上一个0,即为[0100],但是第二个字节也放不过了,只剩三个比特位了,所以我们考虑再开一个字节的空间,然后放这个d
上面只是我假设的编译器执行思维,不过真正是怎样的,我们还是要求证一下
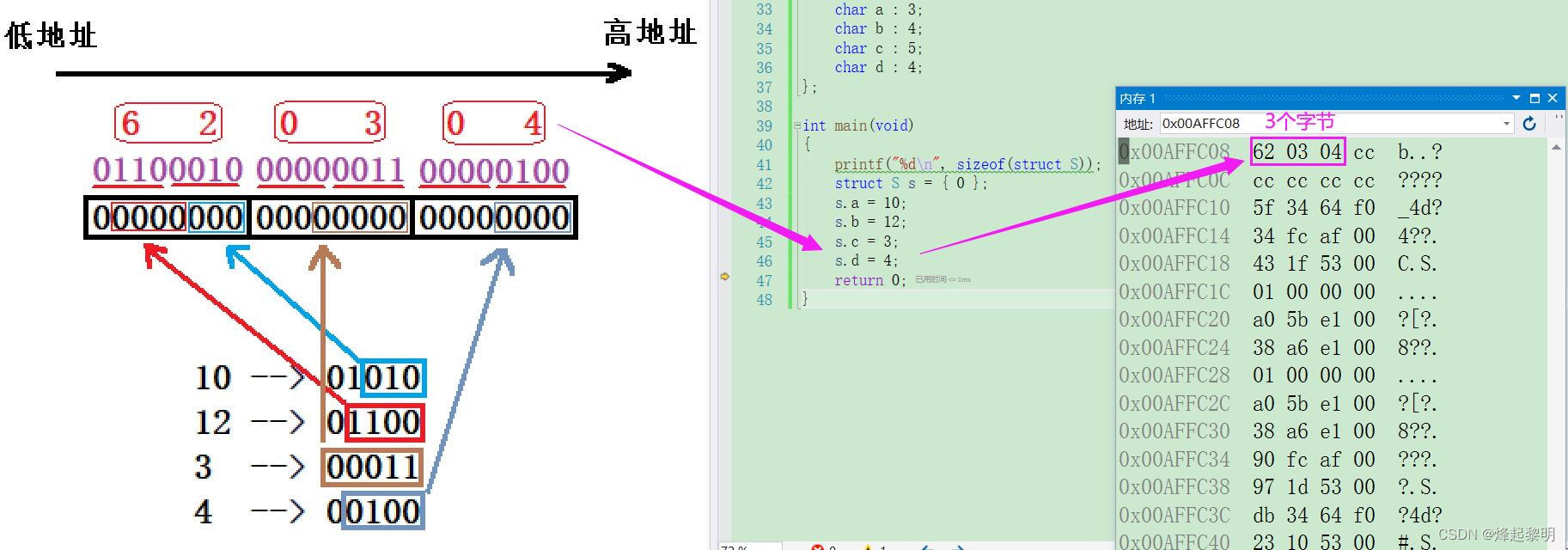
- 那要怎么求证呢?这个很简单,既然这些变量都是存放在位段中,那我们刚才都算出所存放的二进制形式了。对于内存中的地址一般我们看到都是十六进制,所以可以考虑把这些二进制4个为一组转换为十六进制看看
01100010即为——>0x6200000011即为——>0x0300000100即为——>0x04
- 而在内存中左边是低地址,右边是高地址,所以我们看到的应该是
62 03 04 cc。来通过【内存】观察一下吧
可以看到,确实和我们分析得是一模一样✌
看完了上面这个,相信你对一开始的那个位段如何去进行求解的整个流程应该是非常清楚了,留给读者自己的分析观察🔍
三、位段的跨平台问题
接下去我们再来讲讲有关位段的跨平台的问题
- int 位段被当成有符号数还是无符号数是不确定的
- 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32)
- 假设我们将位段中一个变量所占大小设置为30,即占30个比特位,那么它在32为机器上是没问题的,但是放到早期的16位机器上去的话,可能连编译都编不过,因为根本存放不下
- 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义
- 刚才我分析的时候假设的是从右往左进行分配,但是呢这在其他平台上可能又是不一样的了
- 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的
- 这也就是我们一开始纠结的【15】到底还用不用的问题,这里给出解答,还是不确定,取决于平台
总结:跟结构相比,位段可以达到同样的效果,但是可以很好的节省空间,但是有跨平台的问题存在
- 这可能还有的老铁不太理解,举个例子:假设结构体A中的这个变量
a只可能有【0】【1】【2】【3】这四种取值,那么只需要2个比特位就可以表达这四个数字了,即【00】【01】【10】【11】,那我们便可以使用位段来是实现:2,但若是放在普通结构体中的话就只能是一个整型4个字节32个比特位的大小,这也就浪费了很多的空间 - 同理,若是变量
b也只有5种表示形式的话,5个比特位就够了,c、d也是一样。那么这个时候位段就派上用场了,若是使用结构体的话就会浪费掉很多的空间。所以我们前面在看的时候,结构体所占的空间大小是16B,而位段只有8B
四、位段的应用
清楚了位段的相关知识和使用后,可能还是有同学比较迷惑这个位段到底是用来干嘛的,有什么实际应用场景吗?我们来看看
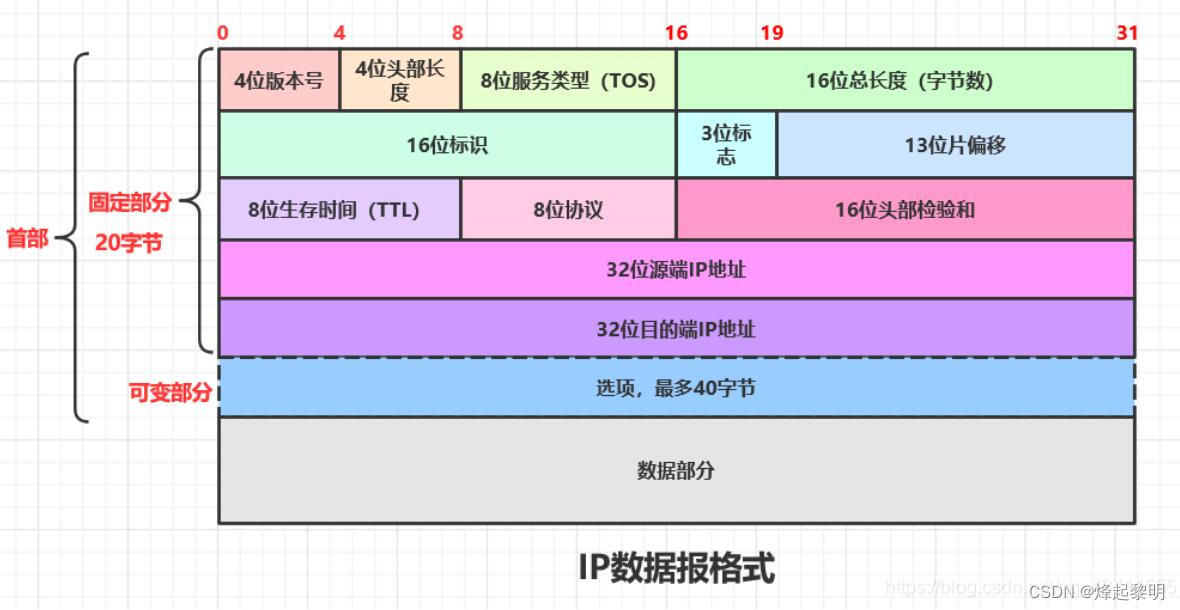
- 比方说这里有个IP数据包,有学习过《计算机网络》相关知识的读者应该都很清楚【不了解可以看看网络层知识点汇总】,我们平常在网络上和别人互相聊天的时候,所发送的消息并不是直接在网络链路上进行传送的,而是会将其封装到一个数据包中,它叫做IP数据包,例如我们所发送的
呵呵只是里面的一个数据部分,还存在其他很多的字段,这些字段都占有各自的字节数 - 其实对于这些字节数来说,就是使用【位段】来实现,精准地控制好每个字段需要多少字节数,,就不会造成浪费的现象了
五、总结与提炼
最后来总结一下本文所学习的内容📖
- 在本文中,我们首先讲到了位段的相关概念,知道了原来使用结构体还可以实现位段,不过在看了二者的大小后,却产生了疑惑,为什么位段所占的大小是这些呢?
- 在清楚了位段在内容中的相关分布后,我带着读者一步步分析了位段中的成员数据到底是怎么一个个存放到内存中的,也通过VS中的【内存】验证观察了我们的分析结果,是正确的
- 然后便说道了位段这个东西其实具备很大的不确定性,因为它存在跨平台的问题,在不同平台下实现的机制可能不同,所以就会导致最后的位段大小会不一致
- 最后,也说道了位段的作用以及其实际的应用场景,让读者学以致用
以上就是本文要介绍的所有内容,感谢您的阅读,如果觉得有帮助的话,可以给个三连哦❤️❤️❤️


大神带你 20 分钟学会 Ansible !
来源:见文末
一、基本部署
安装Ansible
# yum -y install epel-release
# yum list all *ansible*
# yum info ansible
# yum -y install ansibleAnsible配置文件
/etc/ansible/ansible.cfg 主配置文件
/etc/ansible/hosts Inventory
/usr/bin/ansible-doc 帮助文件
/usr/bin/ansible-playbook 指定运行任务文件定义Inventory
# cd /etc/ansible/
# cp hosts{,.bak}
# > hosts
# cat hosts
[webserver]
127.0.0.1
192.168.10.149
[dbserver]
192.168.10.113使用秘钥方式连接
# ssh-keygen -t rsa
# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.10.149
# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.10.113
# ssh-copy-id -i /root/.ssh/id_rsa.pub root@127.0.0.1使用帮助
# ansible-doc -l 列出ansible所有的模块
# ansible-doc -s MODULE_NAME 查看指定模块具体适用Ansible命令应用基础
语法:ansible <host-pattern> [-f forks] [-m module_name] [-a args]
<host-pattern> 这次命令对哪些主机生效的
inventory group name
ip
all
-f forks 一次处理多少个主机
-m module_name 要使用的模块
-a args 模块特有的参数
# ansible 192.168.10.113 -m command -a 'date'
# ansible webserver -m command -a 'date'
# ansible all -m command -a 'date'二、常见模块
command 命令模块(默认模块)用于在远程主机执行命令;不能使用变量,管道等
# ansible all -a 'date'
cron 计划任务
month 指定月份
minute 指定分钟
job 指定任务
day 表示那一天
hour 指定小时
weekday 表示周几
state 表示是添加还是删除
present:安装
absent:移除
# ansible webserver -m cron -a 'minute="*/10" job="/bin/echo hello" name="test cron job"' #不写默认都是*,每个任务都必须有一个名字
# ansible webserver -a 'crontab -l'
# ansible webserver -m cron -a 'minute="*/10" job="/bin/echo hello" name="test cron job" state=absent' #移除任务user 用户账号管理
name 用户名
uid uid
state 状态
group 属于哪个组
groups 附加组
home 家目录
createhome 是否创建家目录
comment 注释信息
system 是否是系统用户
# ansible all -m user -a 'name="user1"'
# ansible all -m user -a 'name="user1" state=absent'group 组管理
gid gid
name 组名
state 状态
system 是否是系统组
# ansible webserver -m group -a 'name=mysql gid=306 system=yes'
# ansible webserver -m user -a 'name=mysql uid=306 system=yes group=mysql'copy 复制文件(复制本地文件到远程主机的指定位置)
src 定义本地源文件路径
dest 定义远程目录文件路径(绝对路径)
owner 属主
group 属组
mode 权限
content 取代src=,表示直接用此处的信息生成为文件内容
# yum -y install libselinux-python
# ansible all -m copy -a 'src=/etc/fstab dest=/tmp/fstab.ansible owner=root mode=640'
# ansible all -m copy -a 'content="hello ansible\nHi ansible" dest=/tmp/test.ansible'file 设置文件的属性
path|dest|name 对那个文件做设定
创建文件的符号链接:
src: 指定源文件
path: 指明符号链接文件路径
# ansible all -m file -a 'owner=mysql group=mysql mode=644 path=/tmp/fstab.ansible'
# ansible all -m file -a 'path=/tmp/fstab.link src=/tmp/fstab.ansible state=link'ping 测试指定主机是否能连接
# ansible all -m pingservice 管理服务运行状态
enabled 是否开机自动启动
name 指定服务名
state 指定服务状态
started 启动服务
stoped 停止服务
restarted 重启服务
arguments 服务的参数
# ansible webserver -m service -a 'enabled=true name=httpd state=started'shell 在远程主机上运行命令
尤其是用到管道变量等功能的复杂命令
# ansible all -m shell -a 'echo magedu | passwd --stdin user1'script 将本地脚本复制到远程主机并运行之
# ansible all -m script -a '/tmp/test.sh'yum 安装程序包
name 程序包名称(不指定版本就安装最新的版本latest)
state present,latest表示安装,absent表示卸载
# ansible webserver -m yum -a 'name=httpd'
# ansible all -m yum -a 'name=ntpdate' #默认就是安装
# ansible all -m yum -a 'name=ntpdate state=absent'setup 收集远程主机的facts
每个被管理节点在接受并运行管理命令之前,会将自己主机相关信息,如操作系统版本,IP地址等报告给远程的ansible主机
# ansible all -m setup三、Ansible playbook
组成结构:
inventory #以下操作应用的主机
modules #调用哪些模块做什么样的操作
ad hoc commands #在这些主机上运行哪些命令
playbooks
tasks #任务,即调用模块完成的某操作
variable #变量
templates #模板
handlers #处理器,由某事件触发执行的操作
roles #角色四、YAML
4.1 YAML介绍
YAML是一个可读性高的用来表达资料序列的格式。YAML参考了其它多种语言,包括:XML、C语言、Python、Perl以及电子邮件格式RFC2822等。ClarkEvans在2001年首次发表了这种语言,另外Ingy dot Net与Oren Ben-Kiki也是这语言的共同设计者。
YAML Ain't Markup Language,即YAML不是XML,不过,在开发这种语言时,YAML的意思其实是:"Yet Another Markup Language"(仍是一种标记语言),其特性:
YAML的可读性好
YAML和脚本语言的交互性好
YAML使用实现语言的数据类型
YAML有一个一致的信息模型
YAML易于实现
YAML可以基于流来处理
YAML表达能力强,扩展性好
更多的内容及规范参见http://www.yaml.org
4.2 YAML语法
YAML的语法和其他高阶语言类似,并且可以简单表达清单、散列表、标量等数据结构,其结构(structure)通过空格来展示,序列(sequence)里的项用"-"来表示,Map里面的键值对用":"分割,下面是一个示例。
name: john smith
age: 41
gender: male
spouse:
name:jane smith
age:37
gender: female
children:
- name:jimmy smith
age:17
gender: male
- name:jenny smith
age: 13
gender: femaleYAML文件扩展名通常为.yaml,如example.yaml
4.2.1 list
列表的所有元素均使用"-"打头,例如:
# A list of testy fruits
- Apple
- Orange
- Strawberry
- Mango4.2.2 dictionary
字典通过key与value进行标识,例如:
---
# An employee record
name: Example Developer
job: Developer
skill: Elite也可以将key:value放置于{}中进行表示,例如:
---
#An exmloyee record
{name: Example Developer, job: Developer, skill: Elite}五、Ansible基础元素
5.1 变量
5.1.1 变量命名
变量名仅能由字母、数字和下划线组成,且只能以字母开头。
5.1.2 facts
facts是由正在通信的远程目标主机发回的信息,这些信息被保存在ansible变量中。要获取指定的远程主机所支持的所有facts,可使用如下命令进行:
#ansible hostname -m setup5.1.3 register
把任务的输出定义为变量,然后用于其他任务,实例如下:
tasks:
- shell: /usr/bin/foo
register: foo_result
ignore_errors: True5.1.4 通过命令行传递变量
在运行playbook的时候也可以传递一些变量供playbook使用,示例如下:
#ansible-playbook test.yml --extra-vars "hosts=www user=mageedu"5.1.5 通过roles传递变量
当给一个主机应用角色的时候可以传递变量,然后在角色内使用这些变量,示例如下:
- hosts: webserver
roles:
- common
- {role: foo_app_instance, dir: '/web/htdocs/a.com', port: 8080}5.2 Inventory
ansible的主要功用在于批量主机操作,为了便捷的使用其中的部分主机,可以在inventory file中将其分组命名,默认的inventory file为/etc/ansible/hosts
inventory file可以有多个,且也可以通过Dynamic Inventory来动态生成。
5.2.1 inventory文件格式
inventory文件遵循INI文件风格,中括号中的字符为组名。可以将同一个主机同时归并到多个不同的组中;此外,当如若目标主机使用非默认的SSH端口,还可以在主机名称之后使用冒号加端口号来表明。
ntp.magedu.com
[webserver]
www1.magedu.com:2222
www2.magedu.com
[dbserver]
db1.magedu.com
db2.magedu.com
db3.magedu.com
如果主机名遵循相似的命名模式,还可使用列表的方式标识个主机,例如:
[webserver]
www[01:50].example.com
[databases]
db-[a:f].example.com5.2.2 主机变量
可以在inventory中定义主机时为其添加主机变量以便于在playbook中使用,例如:
[webserver]
www1.magedu.com http_port=80 maxRequestsPerChild=808
www2.magedu.com http_port=8080 maxRequestsPerChild=9095.2.3 组变量
组变量是指赋予给指定组内所有主机上的在playbook中可用的变量。例如:
[webserver]
www1.magedu.com
www2.magedu.com
[webserver:vars]
ntp_server=ntp.magedu.com
nfs_server=nfs.magedu.com5.2.4 组嵌套
inventory中,组还可以包含其它的组,并且也可以向组中的主机指定变量。不过,这些变量只能在ansible-playbook中使用,而ansible不支持。例如:
[apache]
httpd1.magedu.com
httpd2.magedu.com
[nginx]
ngx1.magedu.com
ngx2.magedu.com
[webserver:children] #固定格式
apache
nginx
[webserver:vars]
ntp_server=ntp.magedu.com5.2.5 inventory参数
ansible基于ssh连接inventory中指定的远程主机时,还可以通过参数指定其交互方式,这些参数如下所示:
ansible_ssh_host
ansible_ssh_port
ansible_ssh_user
ansible_ssh_pass
ansible_sudo_pass
ansible_connection
ansible_ssh_private_key_file
ansible_shell_type
ansible_python_interpreter5.3 条件测试
如果需要根据变量、facts或此前任务的执行结果来做为某task执行与否的前提时要用到条件测试。
5.3.1 when语句
在task后添加when字句即可使用条件测试;when语句支持jinja2表达式语句,例如:
tasks:
- name: 'shutdown debian flavored system"
command: /sbin/shutdown -h now
when: ansible_os_family == "Debian"when语句中还可以使用jinja2的大多"filter",例如果忽略此前某语句的错误并基于其结果(failed或success)运行后面指定的语句,可使用类似如下形式;
tasks:
- command:/bin/false
register: result
ignore_errors: True
- command: /bin/something
when: result|failed
- command: /bin/something_else
when: result|success
- command: /bin/still/something_else
when: result|skipped此外,when语句中还可以使用facts或playbook中定义的变量
# cat cond.yml
- hosts: all
remote_user: root
vars:
- username: user10
tasks:
- name: create {{ username }} user
user: name={{ username }}
when: ansible_fqdn == "node1.exercise.com"5.4 迭代
当有需要重复性执行的任务时,可以使用迭代机制。其使用格式为将需要迭代的内容定义为item变量引用,并通过with_items语句来指明迭代的元素列表即可。例如:
- name: add server user
user: name={{ item }} state=persent groups=wheel
with_items:
- testuser1
- testuser2上面语句的功能等同于下面的语句:
- name: add user testuser1
user: name=testuser1 state=present group=wheel
- name: add user testuser2
user: name=testuser2 state=present group=wheel事实上,with_items中可以使用元素还可为hashes,例如:
- name: add several users
user: name={{ item.name}} state=present groups={{ item.groups }}
with_items:
- { name: 'testuser1', groups: 'wheel'}
- { name: 'testuser2', groups: 'root'}Ansible的循环机制还有更多的高级功能,具体请参考官方文档http://docs.ansible.com/playbooks_loops.html
六、模板示例:
# grep '{{' conf/httpd.conf
MaxClients {{ maxClients }}
Listen {{ httpd_port }}
# cat /etc/ansible/hosts
[webserver]
127.0.0.1 httpd_port=80 maxClients=100
192.168.10.149 httpd_port=8080 maxClients=200
# cat apache.yml
- hosts: webserver
remote_user: root
vars:
- package: httpd
- service: httpd
tasks:
- name: install httpd package
yum: name={{ package }} state=latest
- name: install configuration file for httpd
template: src=/root/conf/httpd.conf dest=/etc/httpd/conf/httpd.conf
notify:
- restart httpd
- name: start httpd service
service: enabled=true name={{ service }} state=started
handlers:
- name: restart httpd
service: name=httpd state=restarted七、Ansible playbooks
playbook是由一个或多个"play"组成的列表。play的主要功能在于将事先归并为一组的主机装扮成事先通过ansible中的task定义好的角色。从根本上来讲,所有task无非是调用ansible的一个module。将多个play组织在一个playbook中,即可以让他们连同起来按事先编排的机制同唱一台大戏。下面是一个简单示例。
- hosts: webserver
vars:
http_port: 80
max_clients: 256
remote_user: root
tasks:
- name: ensure apache is at the latest version
yum: name=httpd state=latest
- name: ensure apache is running
service: name=httpd state=started
handlers:
- name: restart apache
service: name=httpd state=restarted7.1 playbook基础组件
7.1.1 Hosts和Users
playbook中的每一个play的目的都是为了让某个或某些主机以某个指定的用户身份执行任务。hosts用于指定要执行指定任务的主机,其可以使一个或多个由冒号分隔主机组;remote_user则用于指定远程主机的执行任务的用户,如上面的实例中的
- hosts: webserver
remote_user: root不过,remote_user也可用于各task中,也可以通过指定其通过sudo的方式在远程主机上执行任务,其可用于play全局或其任务;此外,甚至可以在sudo时使用sudo_user指定sudo时切换的用户。
- hosts: webserver
remote_user: magedu
tasks:
- name: test connection
ping:
remote_user: magedu
sudo: yes7.1.2 任务列表和action
play的主题部分是task list。task list中的各任务按次序逐个在hosts中指定的所有主机上执行,即在所有主机上完成第一个任务后再开始第二个。在运行自上而下某playbook时,如果中途发生错误,所有已执行任务都可能回滚,在更正playbook后重新执行一次即可。
taks的目的是使用指定的参数执行模块,而在模块参数中可以使用变量。模块执行是幂等的。这意味着多次执行是安全的,因为其结果均一致。
每个task都应该有其name,用于playbook的执行结果输出,建议其内容尽可能清晰地描述任务执行步骤,如果为提供name,则action的结果将用于输出。
定义task可以使用"action: module options"或”module:options“的格式推荐使用后者以实现向后兼容。如果action一行的内容过多,也中使用在行首使用几个空白字符进行换行。
tasks:
- name:make sure apache is running
service: name=httpd state=started
tasks:
- name: run this command and ignore the result
shell: /usr/bin/somecommand || /bin/true在众多的模块中,只有command和shell模块仅需要给定一个列表而无需使用"key=value"格式,例如:
tasks:
- name: disable selinux
command: /sbin/setenforce 0如果命令或脚本的退出码不为零,可以使用如下方式替代:
或者使用ignore_errors来忽略错误信息:
tasks:
- name: run this command and ignore the result
shell: /usr/bin/somecommand
ignore_errors: True7.1.3handlers
用于当关注的资源发生变化时采取一定的操作。
"notify"这个action可用于在每个play的最后被触发,这样可以避免多次有改变发生时每次都执行执行的操作,取而代之,仅在所有的变化发生完成后一次性地执行指定操作,在notify中列出的操作称为handlers,也即notify中调用handlers中定义的操作。
- name: template configuration file
template: src=template.j2 dest=/etc/foo.conf
notify:
- restart memcached
- restart apachehandlers是task列表,这些task与前述的task并没有本质上的不同。
handlers:
- name: restart memcached
service: name=memcached state=restarted
- name: restart apache
service: name=apache state=restarted简单示例1:
# cat nginx.yml
- hosts: webserver
remote_user: root
tasks:
- name: create nginxn group
group: name=nginx system=yes gid=208
- name: create nginx user
user: name=nginx uid=208 group=nginx system=yes
- hosts: dbserver
remote_user: root
tasks:
- name: copy file to dbserver
copy: src=/etc/inittab dest=/tmp/inittab.ans
# ansible-playbook nginx.yml简单示例2:
# cat apache.yml
- hosts: webserver
remote_user: root
tasks:
- name: install httpd package
yum: name=httpd state=latest
- name: install configuration file for httpd
copy: src=/root/conf/httpd.conf dest=/etc/httpd/conf/httpd.conf
- name: start httpd service
service: enabled=true name=httpd state=started
# ansible-playbook apache.ymlhandlers 示例:
# cat apache.yml
- hosts: webserver
remote_user: root
tasks:
- name: install httpd package
yum: name=httpd state=latest
- name: install configuration file for httpd
copy: src=/root/conf/httpd.conf dest=/etc/httpd/conf/httpd.conf
notify:
- restart httpd
- name: start httpd service
service: enabled=true name=httpd state=started
handlers:
- name: restart httpd
service: name=httpd state=restarted
# ansible-playbook apache.ymlvariable 示例1:
# cat apache.yml
- hosts: webserver
remote_user: root
vars:
- package: httpd
- service: httpd
tasks:
- name: install httpd package
yum: name={{ package }} state=latest
- name: install configuration file for httpd
copy: src=/root/conf/httpd.conf dest=/etc/httpd/conf/httpd.conf
notify:
- restart httpd
- name: start httpd service
service: enabled=true name={{ service }} state=started
handlers:
- name: restart httpd
service: name=httpd state=restartedvariable 示例2:(在playbook中可以使用所有的变量)
# cat facts.yml
- hosts: webserver
remote_user: root
tasks:
- name: copy file
copy: content="{{ ansible_all_ipv4_addresses }} " dest=/tmp/vars.ans八、roles
ansible自1.2版本引入的新特性,用于层次性、结构化地组织playbook。roles能够根据层次型结构自动转载变量文件、tasks以及handlers等。要使用roles只需要在playbook中使用include指令即可。简单来讲,roles就是通过分别将变量、文件、任务、模板以及处理器放置于单独的目录中,并可以便捷地include他们的一种机制。角色一般用于基于主机构建服务的场景中,但也可以使用于构建守护进程的场景中
一个roles的案例如下所示:
site.yml
webserver.yml
fooserver.yml
roles/
common/
files/
templates/
tasks/
handlers/
vars/
meta/
webserver/
files/
templates/
tasks/
handlers/
vars/
meta/而在playbook中,可以这样使用role:
- hosts: webserver
roles:
- common
- webserver也可以向roles传递参数,例如:
- hosts: webserver
roles:
- common
- { role: foo_app_instance, dir:'/opt/a',port:5000}
- { role: foo_app_instance, dir:'/opt/b',port:5001}甚至也可以条件式地使用roles,例如:
- hosts:webserver
roles:
- { role: some_role, when: "ansible_so_family == 'RedHat" }8.1 创建role的步骤
创建以roles命名的目录:
在roles目录中分别创建以各角色命名的目录,如webserver等
在每个角色命名的目录中分别创建files、handlers、meta、tasks、templates和vars目录;用不到的目录可以创建为空目录,也可以不创建
在playbook文件中,调用各角色
8.2 role内各目录中可应用的文件
task目录:至少应该包含一个为main.yml的文件,其定义了此角色的任务列表;此文件可以使用include包含其它的位于此目录中的task文件;
file目录:存放由copy或script等模板块调用的文件;
template目录:template模块会自动在此目录中寻找jinja2模板文件;
handlers目录:此目录中应当包含一个main.yml文件,用于定义此角色用到的各handlers,在handler中使用inclnude包含的其它的handlers文件也应该位于此目录中;
vars目录:应当包含一个main.yml文件,用于定义此角色用到的变量
meta目录:应当包含一个main.yml文件,用于定义此角色的特殊设定及其依赖关系;ansible1.3及其以后的版本才支持;
default目录:应当包含一个main.yml文件,用于为当前角色设定默认变量时使用此目录;
# mkdir -pv ansible_playbooks/roles/{webserver,dbserver}/{tasks,files,templates,meta,handlers,vars}
# cp /etc/httpd/conf/httpd.conf files/
# pwd
/root/ansible_playbooks/roles/webserver
# cat tasks/main.yml
- name: install httpd package
yum: name=httpd state=present
- name: install configuretion file
copy: src=httpd.conf dest=/etc/httpd/conf/httpd.conf
tags:
- conf
notify:
- restart httpd
- name: start httpd
service: name=httpd state=started
# cat handlers/main.yml
- name: restart httpd
service: name=httpd state=restarted
# pwd;ls
/root/ansible_playbooks
roles site.yml
# cat site.yml
- hosts: webserver
remote_user: root
roles:
- webserver
# ansible-playbook site.yml九、Tags
tags用于让用户选择运行或跳过playbook中的部分代码。ansible具有幂等性,因此会自动跳过没有变化的部分,即便如此,有些代码为测试其确实没有发生变化的时间依然会非常的长。此时,如果确信其没有变化,就可以通过tags跳过此些代码片段。
tags:在playbook可以为某个或某些任务定义一个"标签",在执行此playbook时,通过为ansible-playbook命令使用--tags选项能耐实现仅运行指定的tasks而非所有的;
# cat apache.yml
- hosts: webserver
remote_user: root
vars:
- package: httpd
- service: httpd
tasks:
- name: install httpd package
yum: name={{ package }} state=latest
- name: install configuration file for httpd
template: src=/root/conf/httpd.conf dest=/etc/httpd/conf/httpd.conf
tags:
- conf
notify:
- restart httpd
- name: start httpd service
service: enabled=true name={{ service }} state=started
handlers:
- name: restart httpd
service: name=httpd state=restarted
# ansible-playbook apache.yml --tags='conf'特殊tags:always #无论如何都会运行
来源:https://my.oschina.net/kangvcar/blog/1830155
*声明:推送内容及图片来源于网络,部分内容会有所改动,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
- END -
更多Python好文请点击【阅读原文】哦
↓↓↓
以上是关于C生万物 | 十分钟带你学会位段相关知识的主要内容,如果未能解决你的问题,请参考以下文章