Innodb MVCC的实现分析
Posted 守拙的厨子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Innodb MVCC的实现分析相关的知识,希望对你有一定的参考价值。
什么是mvcc(多版本并发控制)
Multiversion concurrency control (MCC or MVCC), is a concurrency control method commonly used by database management systems to provide concurrent access to the database and in programming languages to implement transactional memory
是数据库在实现事务隔离等特性下,尽量不减少并发处理能力的一种解决方案。
事务的特性
acid
其中对于隔离性,隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作,这种属性有时称为串行化.
通常来说,一个事务所做的修改在最终提交前,对其他事务是不可见的. 由此引出事务隔离级别的概念.
事务将假定只有它自己在操作数据库,彼此不知晓
其他事务相关概念
redo log innodb的事务日志
redo log就是保存执行的SQL语句到一个指定的Log文件, 当mysql执行recovery时重新执行redo
log记录的SQL操作即可。当客户端执行每条SQL(更新语句)时,redo log会被首先写入log buffer; redo log在磁盘上作为一个独立的文件存在,即Innodb的log文件
undo log
与redo log相反,undo log是为回滚而用,具体内容就是copy事务前的数据库内容(行)到undo buffer,在适合的时间把undo buffer中的内容刷新到磁盘。
undo buffer与redo buffer一样,也是环形缓冲,但当缓冲满的时候,undo buffer中的内容会也会被刷新到磁盘
与redo log不同的是,磁盘上不存在单独的undo log文件,所有的undo log均存放在主ibd数据文件中(表空间),即使客户端设置了每表一个数据文件也是如此.
undo log中记录的行,就是mvcc中的多版本数据。
锁
Innodb提供了基于行的锁,如果行的数量非常大,则在高并发下锁的数量也可能会比较大,据Innodb文档说,Innodb对锁进行了空间有效优化,即使并发量高也不会导致内存耗尽。
对行的锁有分两种:排他锁、共享锁。
共享锁针对读,排他锁针对写,完全等同读写锁的概念。如果某个事务在更新某行(排他锁),则其他事物无论是读还是写本行都必须等待;如果某个事物读某行(共享锁),则其他读的事物无需等待,而写事物则需等待。通过共享锁,保证了多读之间的无等待性,但是锁的应用又依赖Mysql的事务隔离级别。
事务隔离级别
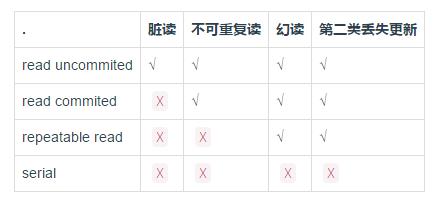
READ UNCOMMITED(未提交读)
事务中的修改,即使没有提交,对其他事务也是可见的. 其他事务可以读取到当前事务未提交的数据,一般很少使用.
READ COMMITED(提交读)
只能看见已经提交事务所做的修改.
REPTEATABLE READ(可重复读)
该级别保证了在同一事务中多次读取同样记录的结果是一致的. 这也是mysql默认的事务级别. 但是可能出现幻读/第二类丢失更新的情况.
幻读,当一个事务在读取某个范围的记录的时候,另外一个事务又在范围内插入了新的记录. 当之前的事务再次在该范围内读取记录的时候,会产生幻行.
SERIALIZABLE(可串行化的)
最高级别的隔离. 强制事务串行执行,避免了幻读问题.
会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用问题.
事务隔离级别从上往下依次减弱,数据库实现的成本也越来越小,可支持的并发相应也越来越大。
数据读取过程中的问题
脏读(dirty read) A事务读取B事务尚未提交的数据并在此基础上操作,而B事务执行回滚,那么A读取到的数据就是脏数据
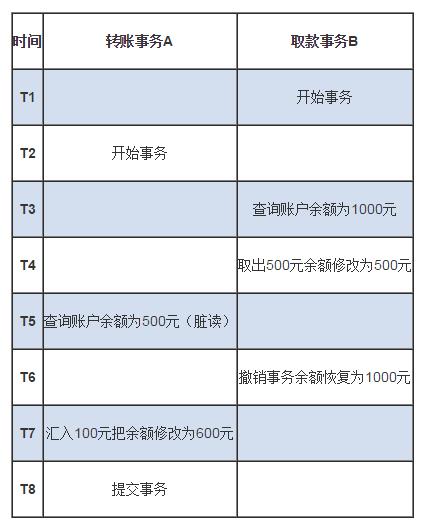
不可重复读(Unrepeatable Read):事务A重新读取前面读取过的数据,发现该数据已经被另一个已提交的事务B修改过了. 即: A 先查询一次数据,然后 B 更新之并提交,A 再次查询,得到和上一次不同的查询结果
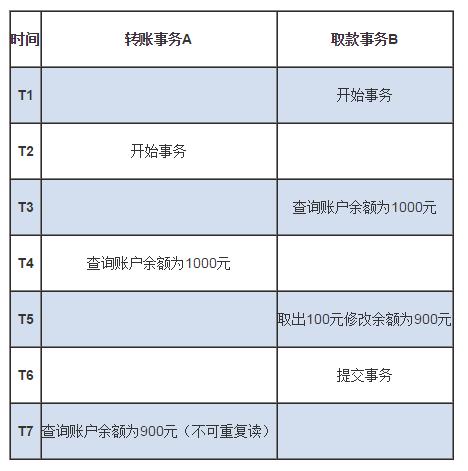
幻读(phantom read): A 查询一批数据,B 插入或删除了某些记录并提交,A 再次查询,发现结果集中出现了上次没有的记录,或者上次有的记录消失了

- 第二类更新丢失 A 和 B 查询同样的记录,进行 “读取、计算、更新”,即各自 基于最初查询的结果 (非必须) 更新记录并提交,后提交的数据将覆盖先提交的,导致最终数据错误。
并发进行自增 / 自减是发生覆盖丢失的一个典型场景

不同的事务隔离级别面临的问题
innodb mvcc的实现
InnoDB表数据的组织方式为主键聚簇索引。由于采用索引组织表结构,记录的ROWID是可变的(索引页分裂的时候,Structure Modification Operation,SMO),因此二级索引中采用的是(索引键值, 主键键值)的组合来唯一确定一条记录
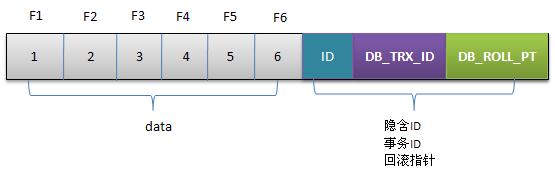
无论是聚簇索引,还是二级索引,其每条记录都包含了一个DELETED BIT位,用于标识该记录是否是删除记录。
除此之外,聚簇索引记录还有两个系统列:DATA_TRX_ID,DATA_ROLL_PTR。DATA _TRX_ID表示产生当前记录项的事务ID;DATA _ROLL_PTR指向当前记录项的undo信息。
聚簇索引行结构(DELETED BIT省略):

聚簇索引中包含版本信息(事务号+回滚指针), 回滚指针指向的是undo log中的记录
二级索引结构

Read view
innoDB默认的隔离级别为Repeatable Read (RR),可重复读。InnoDB在开始一个RR读之前,会创建一个Read View。Read View用于判断一条记录的可见性
struct read_view_struct
trx_id_t low_limit_no;
trx_id_t low_limit_id; /* 事务号 >= low_limit_id的记录,对于当前Read View都是不可见的 */
trx_id_t up_limit_id; /* 事务号 < up_limit_id ,对于当前Read View都是可见的 */
ulint n_trx_ids; /* Number of cells in the trx_ids array */
trx_id_t* trx_ids; /* Additional trx ids which the read should
not see: typically, these are the active
transactions at the time when the read is
serialized, except the reading transaction
itself; the trx ids in this array are in a
descending order */
trx_id_t creator_trx_id; /* trx id of creating transaction, or
(0, 0) used in purge */
read view 是会当前系统中的活跃事务列表(trx_sys->trx_list)的一个副本。需要注意一个观点: read view里面记录的,简单来说,就是系统当时活跃的事务id信息,这些事务所做的增删改操作,是不可见的,因为当时并未提交
low_limit_id 是“高水位”即当时活跃事务的最大id,如果读到row的db_tx_id>=low_limit_id,说明这些id在此之前的数据都没有提交,如注释中的描述,这些数据都不可见
if (trx_id >= view->low_limit_id)
return(FALSE);
up_limit_id 是“低水位”即当时活跃事务列表的最小事务id,如果row的db_tx_id
if (trx_id < view->up_limit_id)
return(TRUE);
在两个limit_id之间的我们需要从小到大逐个比较一下:
n_ids = view->n_trx_ids;
for (i = 0; i < n_ids; i++)
trx_id_t view_trx_id
= read_view_get_nth_trx_id(view, n_ids – i – 1);
if (trx_id <= view_trx_id)
return(trx_id != view_trx_id);
这样我们在要在事务中获取100行数据,我们就能根据这100行的row db_tx_id即本事务的read_view来判断此版本的数据在事务中是否可见
如果数据不可见我们需要去哪里找上版本的数据呢?就是通过刚才提到过的7BIT的DATA_ROLL_PTR去undo信息中寻找,同时再判断下这个版本的数据是否可见,以此类推。
innodb更新
insert
InnoDB为每个新增行记录,如insert into test value(’1′,’aaa’), 会创建新的row,row db_tx_id即为当前系统版本号作为创建ID。
update
如update test set value=’bbb’ where key =’bbb’,InnoDB会复制了一行,这个新行的版本号使用了本次db_tx_id更新的版本号。它也把之前版本号作为了删除行的版本,即把原有row delete bit置为删除,不可见。
1.初始数据行
后面三个隐含字段分别对应该行的事务号和回滚指针,假如这条数据是刚INSERT的,可以认为ID为1,其他两个字段为空。
2.事务1更改该行的各字段的值
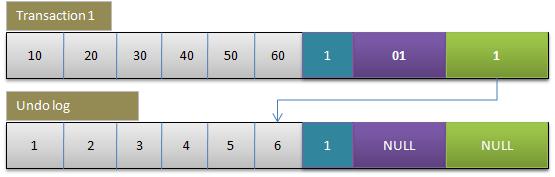
当事务1更改该行的值时,会进行如下操作:
用排他锁锁定该行
记录redo log
把该行修改前的值Copy到undo log,即上图中下面的行
修改当前行的值,填写事务编号,使回滚指针指向undo log中的修改前的行
3.事务2修改该行的值
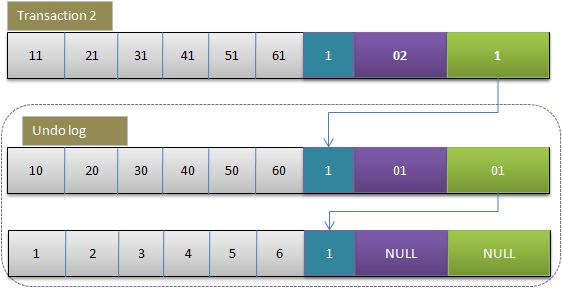
此时undo log,中有有两行记录,并且通过回滚指针连在一起
如果undo log一直不删除,则会通过当前记录的回滚指针回溯到该行创建时的初始内容,所幸的时在Innodb中存在purge线程,它会查询那些比现在最老的活动事务还早的undo log,并删除它们
delete
InnoDB为每个删除行的记录当前系统版本号作为行的删除ID,也就是说把之前说的BIT位置成不可见的。
事务提交
当事务正常提交时Innodb只需要在redo log中更改事务状态为COMMIT即可
而Rollback则稍微复杂点,需要根据当前回滚指针从undo log中找出事务修改前的版本,并恢复。如果事务影响的行非常多,回滚则可能会变的效率不高。
再谈mvcc
Innodb的实现方式是:
事务以排他锁的形式修改原始数据
把修改前的数据存放于undo log,通过回滚指针与主数据关联
修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
比如,如果Transaciton1执行理想的MVCC,修改Row1成功,而修改Row2失败,此时需要回滚Row1,但因为Row1没有被锁定,其数据可能又被Transaction2所修改,如果此时回滚Row1的内容,则会破坏Transaction2的修改结果,导致Transaction2违反ACID
理想MVCC难以实现的根本原因在于企图通过乐观锁代替二段提交。修改两行数据,但为了保证其一致性,与修改两个分布式系统中的数据并无区别,而二提交是目前这种场景保证一致性的唯一手段。二段提交的本质是锁定,乐观锁的本质是消除锁定,二者矛盾,故理想的MVCC难以真正在实际中被应用,Innodb只是借了MVCC这个名字,提供了读的非阻塞而已。
所以实际的innodb事务的实现中, 若并发事务T1与T2种有共享资源,比如对涉及到对同一行数据的修改,这个时候,先开启的事务会锁住需要的资源,直到commit或者rollback释放资源,这两个事务只能按照事务开启顺序依次执行。 若T1与T2无共享资源,则完全可以并发执行,互相不干扰
以上是关于Innodb MVCC的实现分析的主要内容,如果未能解决你的问题,请参考以下文章