Vue学习——第五弹
Posted 沃和莱特
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Vue学习——第五弹相关的知识,希望对你有一定的参考价值。
前言
上一篇文章 Vue学习——【第四弹】 中学到了数据代理,这篇文章接着学习 Vue中的事件处理。
事件处理
我们在学习javascript时就经常接触事件处理,比如在进行表单、按钮、列表折叠等操作时,我们就经常用到 click(点击)事件。在JS中我们经常把事件处理看作一个DOM事件。
在Vue中,事件处理是控制数据变化的控制器,是连接视图与数据的桥梁。
事件处理的语法是:
v-on:事件名="处理事件的函数名" 或者是 @事件名="处理事件的函数名"
通常情况下,我们选择后者的写法
在这里,处理事件的函数名一定要写在 methods配置项中,以便让当前的组件实例访问。
工作机制
-
Vue先通过v-on指令将事件绑定到DOM元素上;
-
当触发事件时(如点击按钮、输入文本等),DOM元素会检测到,并向Vue实例传递事件对象;
-
Vue实例通过事件响应函数来处理这个事件对象,并执行相应的操作,如调用方法、更新数据等;
-
如果需要修改数据,Vue会自动重新渲染组件来更新DOM中的数据。
代码举例
比如我们给最常见的按钮绑定一个click事件,实现数据处理:
<body>
<div id="demo1">
<h3>message</h3>
<button v-on:click="show">了解更多</button> <!--给按钮添加点击事件,当点击按钮时就执行回调函数;下面是简写形式-->
<!-- <button @click="show">了解更多</button> -->
</div>
</body>
<script type="text/javascript">
new Vue(
el:'#demo1',
data:
message:'hello Vue',
,
// 使用一个配置项叫做 methods 将回调函数show添加到Vue实例中
methods: //将show函数作为一个方法放到 methods对象中
show()
alert('欢迎学习Vue')
)
</script>
运行效果:
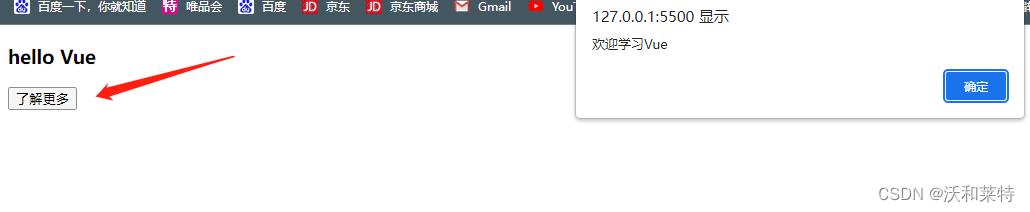
Vue先通过v-on指令将click事件绑定到DOM元素 button上;
当点击按钮时,DOM元素会检测到事件被触发,开始向Vue实例传递事件对象;
而Vue实例就会通过事件响应函数来处理这个click事件,并开始调用show()函数。
另外我们可以看下在methods配置项中函数的this指向问题,我们在控制台打印出methods配置项中函数中的this:
<script type="text/javascript">
new Vue(
el:"#demo1",
data:
message:"hello Vue"
,
methods:
show()
console.log("这是show函数中的this",this)
)
</script>
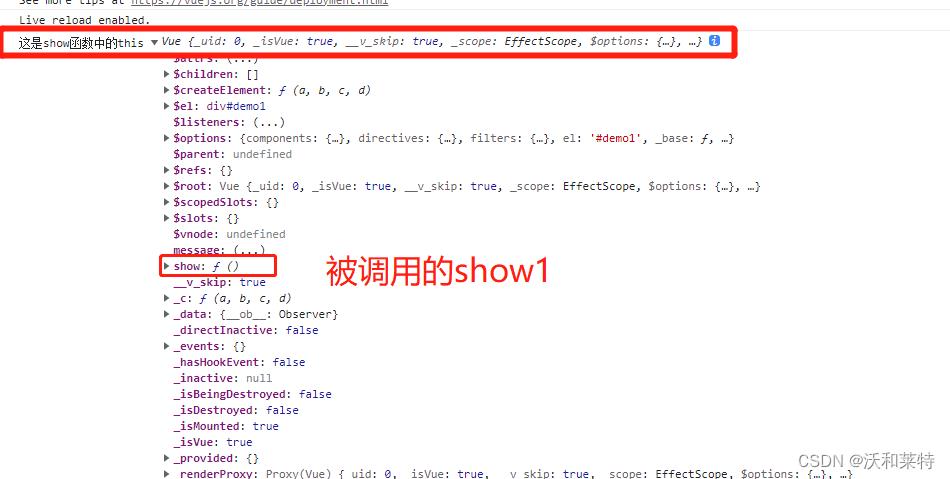
我们通过控制台打印的结果看出,这里的this指向的是Vue实例对象
当然在配置项中我们写的是普通函数,如果是换成箭头函数,它的this还会指向Vue实例对象吗?
<script type="text/javascript">
new Vue(
el:'#demo1',
data:
message:'hello Vue'
,
methods:
show:(event)=>
console.log("show函数改为箭头函数后的this",this) //写成箭头函数后就不会有指向Vue实例的this,就会调用到全局的window;因此我们在Vue实例中写回调函数时最好写成普通函数
)
</script>
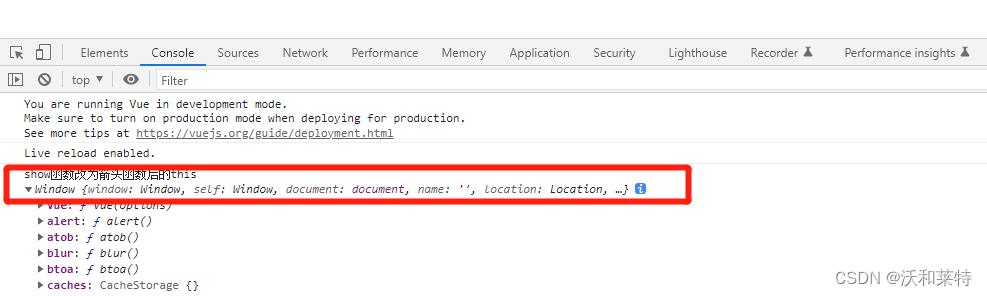 我们看到,如果是换成箭头函数,
我们看到,如果是换成箭头函数,此时的this指向是全局window
因为箭头函数是没有自己的this值的,它继承的是父级作用域中的this值;因此 如果把箭头函数写在methods配置项中,此时this指向的是Vue实例之外的对象,而一个普通函数的“this”则指的是当前的Vue实例。
也就是说,当我们在书写事件处理函数时,或者说methods配置项中的函数,要尽量写成普通函数,原因有如下几点:
1:使用箭头函数定义Vue的methods函数,this指向的是Window,而不是组件实例,需要用普通函数来定义methods函数,才能正确地访问组件实例的属性和方法。
2:如果在methods中包含了异步函数,那么箭头函数的“this”值将会是undefined,这会导致代码无法正常工作。
事件处理中函数中的参数传递
在进行事件绑定时我们可以给调用的函数进行传递实参的,它的语法是
@事件名=“事件函数(实参1,实参2,…实参n)”
如果是不给调用的函数传递参数的话,它会默认传递event
<div id="demo">
message
<button @click="show">了解更多</button> <!--没有给show函数传递实参-->
</div>
<script type="text/javascript">
new Vue(
el:"#demo",
data:
message:"hello Vue"
,
methods:
show(a) //这里的show中传递的是形参
console.log("这是默认传递的参数",a)
)
</script>
运行结果:
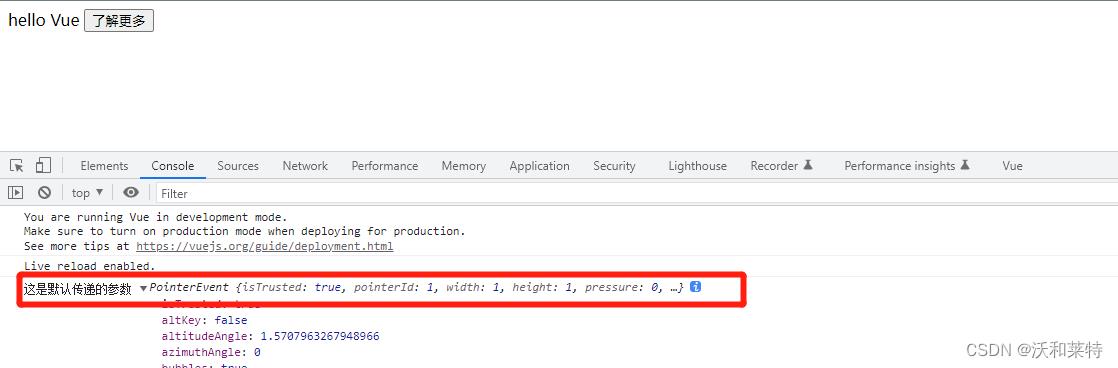 这是在不给show函数传递实参的情况下,Vue会默认我们传递了一个参数,并且这个参数是一个事件对象。
这是在不给show函数传递实参的情况下,Vue会默认我们传递了一个参数,并且这个参数是一个事件对象。
如果我们给它传递一个实参会发生什么呢?
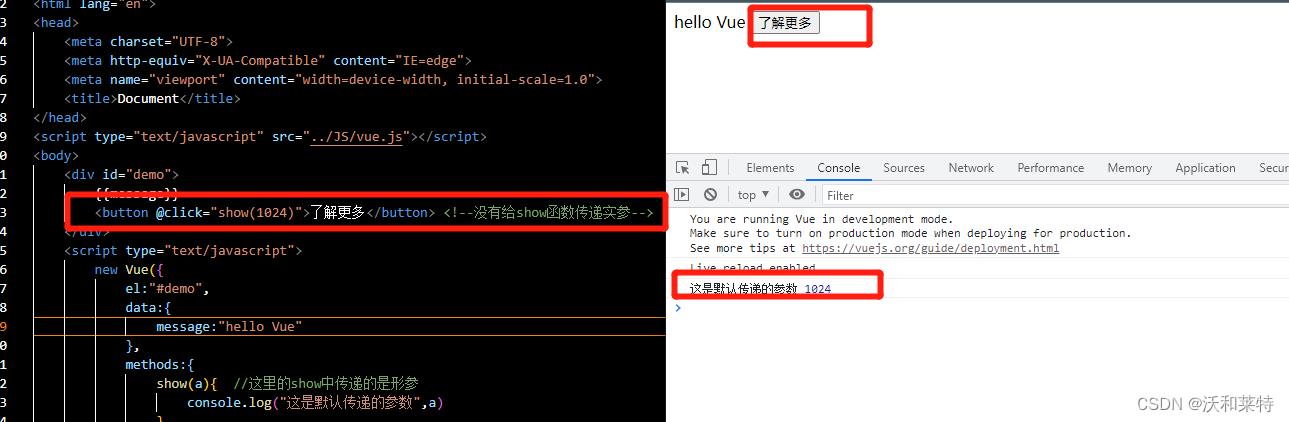
如图,我们给show函数传递了一个数值 1024,通过控制台运行的结果可以看出,当我们点击按钮时,就会调用show,并将传递的参数 1024打印出来,但是原来Vue给我们默认传递的event怎么没有显示出来呢?
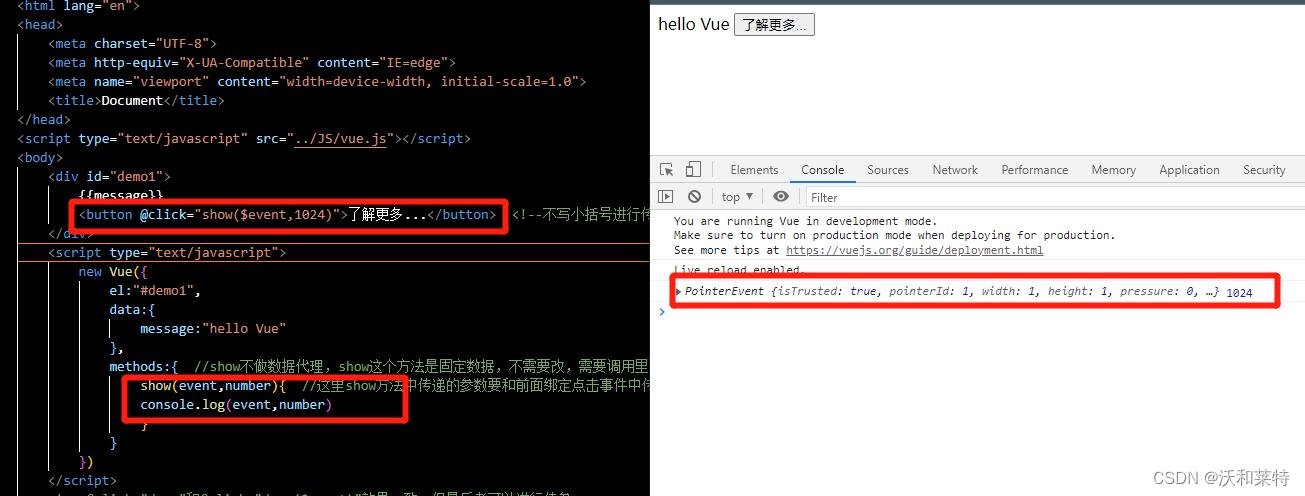
在Vue中,如果我们需要在传递实参的同时也保留事件对象,此时可以用$event占位符来解决:
关于methods配置项
我们尝试将methods配置项中的方法放到data中,看会出现什么结果:
<body>
<div id="demo1">
message
<button @click="show1($event,1024)">放进data中</button>
<button @click="show2($event,1010)">在data外</button>
</div>
<script type="text/javascript">
const vm = new Vue(
el:"#demo1",
data:
message:"hello Vue",
show1(event,number)
console.log(event,number)
//这里将show放到了data中,此时Vue会将show做一次数据代理,但是show本身是不需要进行数据代理的,这种做法会让Vue变得冗余
,
methods:
show2(event,number)
console.log(event,number)
)
</script>
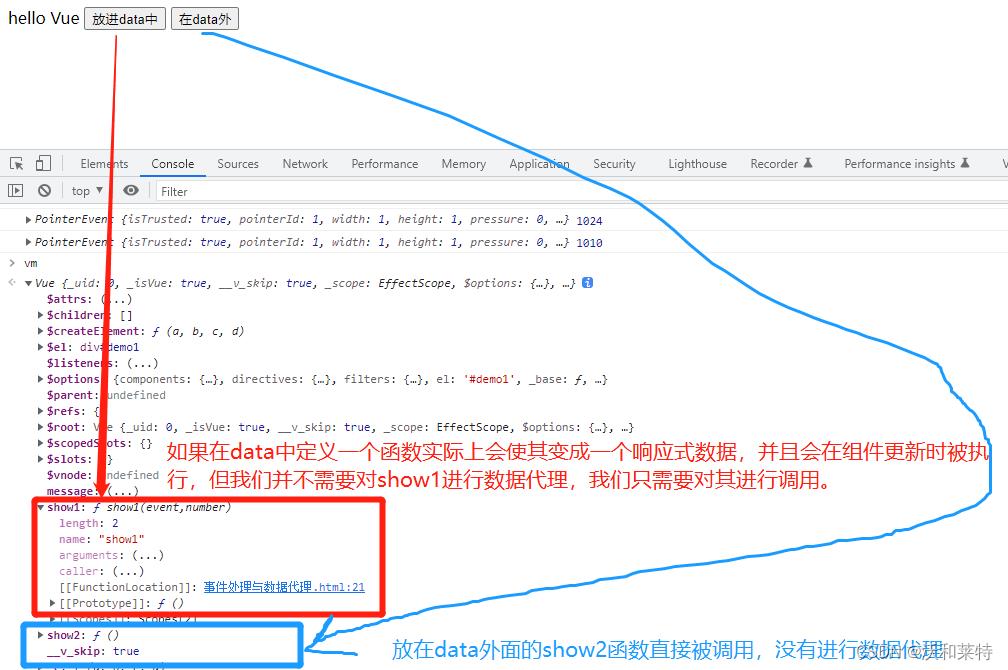
在最后控制台的最下面我们看到show1的确是进行了数据代理,但是这对于show1来说是毫无意义的。
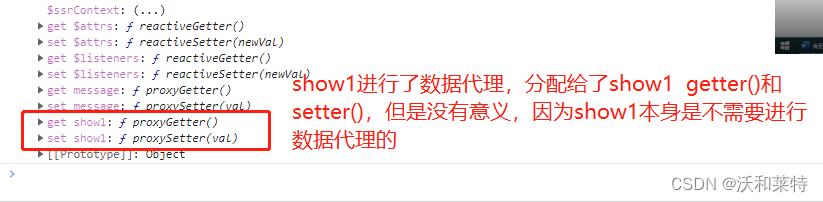
在Vue中,data用于存储组件的数据状态,而methods用于存储组件的函数方法。
事件处理需要调用组件的函数方法来处理,而data只用于存储数据状态而不是函数方法。并且在Vue中有针对组件生命周期的函数调用,如果将函数写在methods中,可以很方便地调用这些函数来实现组件的生命周期。
小结
1:Vue中的事件处理的语法:
v-on:事件名=“处理事件的函数名”
简写形式为 @事件名=“处理事件的函数名”。
2:处理事件的函数名一定要写在 methods配置项中,以便让当前的组件实例访问。
3:当我们在书写事件处理函数时,或者说methods配置项中的函数,要尽量写成普通函数。
4:将事件处理的函数写在methods中是Vue的推荐做法,这也符合Vue的设计原则和响应式数据的特性。
第五弹:VGG
接下来讲一个目前经常被用到的模型,来自牛津大学的VGG,该网络目前还有很多改进版本,这里只讲一下最初的模型,分别从论文解析和模型理解两部分组成。
一、论文解析
一:摘要
……
从Alex-net发展而来的网络主要修改一下两个方面:
1,在第一个卷基层层使用更小的filter尺寸和间隔;
2,在整个图片和multi-scale上训练和测试图片。
二:网络配置
2.1配置
2.1.1 小的Filter尺寸为3*3
卷积的间隔s=1;3*3的卷基层有1个像素的填充。
1:3*3是最小的能够捕获上下左右和中心概念的尺寸。
2:两个3*3的卷基层的有限感受野是5*5;三个3*3的感受野是7*7,可以替代大的filter尺寸
3:多个3*3的卷基层比一个大尺寸filter卷基层有更多的非线性,使得判决函数更加具有判决性。
4:多个3*3的卷积层比一个大尺寸的filter有更少的参数,假设卷基层的输入和输出的特征图大小相同为C,那么三个3*3的卷积层参数个数3*(3*3*C*C)=27CC;一个7*7的卷积层参数为49CC;所以可以把三个3*3的filter看成是一个7*7filter的分解(中间层有非线性的分解)。
2.1.2 1*1 filter:
作用是在不影响输入输出维数的情况下,对输入线进行线性形变,然后通过Relu进行非线性处理,增加网络的非线性表达能力。
Pooling:2*2,间隔s=2;
2.2 结构

和之前流行的三阶段网络不通的是,本文是有5个max-pooling层,所以是5阶段卷积特征提取。每层的卷积个数从首阶段的64个开始,每个阶段增长一倍,直到达到最高的512个,然后保持。
基本结构A:
Input(224,224,3)→64F(3,3,3,1)→max-p(2,2)→128F(3,3,64,1)→max-p(2,2) →256F(3,3,128,1)→256F(3,3,256,1)→max-p(2,2)→512F(3,3,256,1)→512F(3,3,512,1)→max-p(2,2)→512F(3,3,256,1)→512F(3,3,512,1)→max-p(2,2)→4096fc→4096fc→1000softmax
8个卷基层,3个全连接层,共计11层;作者只说明了使用3*3filter的原因,至于层数,阶段数,特征数为什么这么设计,作者并没有说明。
参数个数:网络E和OverFeat模型参数差不多

B:在A的stage2 和stage3分别增加一个3*3的卷基层,10个卷积层,总计13层
C:在B的基础上,stage3,stage4,stage5分别增加1*1的卷积层,13个卷基层,总计16层
D:在C的基础上,stage3,stage4,stage5分别增加3*3的卷积层,13个卷基层,总计16层
E:在D的基础上,stage3,stage4,stage5分别增加3*3的卷积层,16个卷基层,总计19层
三,分类框架
3.1训练参数设置
Minibatch=256,其它的都一样。
作者发现,尽管VGG比Alex-net有更多的参数,更深的层次;但是VGG需要很少的迭代次数就开始收敛。这是因为
1,深度和小的filter尺寸起到了隐式的规则化的作用
2,一些层的pre-initialisation
pre-initialisation:网络A的权值W~(0,0.01)的高斯分布,bias为0;由于存在大量的ReLU函数,不好的权值初始值对于网络训练影响较大。为了绕开这个问题,作者现在通过随机的方式训练最浅的网络A;然后在训练其他网络时,把A的前4个卷基层(感觉是每个阶段的以第一卷积层)和最后全连接层的权值当做其他网络的初始值,未赋值的中间层通过随机初始化。
Multi-scale 训练
把原始 image缩放到最小边S>224;然后在full image上提取224*224片段,进行训练。
方法1:在S=256,和S=384上训练两个模型,然后求平均
方法2:类似OverFeat测试时使用的方法,在[Smin,Smax]scale上,随机选取一个scale,然后提取224*224的图片,训练一个网络。这种方法类似图片尺寸上的数据增益。
3.2 测试
测试阶段的方法和OverFeat测试方法相同,首先选定一个scale:Q,然后在这个图片上应用卷积网络,在最后一个卷积阶段产生unpooled FM,然后利用sliding window方法,每个pooling window产生一个分类输出,然后融合各个pooling window的结果,得到最终分类。这样比10-view更加高效,只需计算一次卷积过程。
3.3 部署细节
利用C++ Caffe toolbox,在4个Titan Gpu上并行计算,比单独GPU快3.75倍,每个网络差不多2-3周。
四,分类实验
4.1 测试阶段single-scale对比

A vs A-LRN:A-LRN结果没有A好,说明LRN作用不大。
A vs B,C,D,E:越深越好
A vs C:增加1*1filter,即增加额外的非线性确实提升效果
C vs D:3*3的filter比1*1filter要好,使用较大的filter能够捕捉更大的空间特征。
训练方法:在scale区间[256;512]通过scale增益来训练网络,比在固定的两个S=256和S=512,结果明显提升。Multi-scale训练确实很有用,因为ZF论文中,卷积网络对于缩放有一定的不变性,通过multi-scale训练可以增加这种不变性的能力。
4.2 Multi-scale训练
方法1:single-scale训练 S,multi-scale测试 {S-32,S,S+32}
方法2:multi-scale训练[Smin;Smax],multi-scale测试{Smin,middle,Smax}
结果:此处结果为B’

1 B vs B’, C vs C’,……:single-scale训练,利用multi-scale测试,有0.2%的top-5提升。
2 B-256 vs B-384 ……:single-scale在256和348上训练,无论用什么测试方法,结果基本上差不多。说明网络在单个scale上提取能力有限。
3 multi-scale训练,multi-scale测试,对于网络提升明显,D’和E’的top-5分类达到了7.5%。
4.3 模型融合
通过结果求平均,融合上面不同网络的结果。

模型融合结果如上图,比较有意思的是,模型D和E两个顶尖模型融合的结果比融合7个模型的结果还要好。这个比较有意思,模型融合个数多,反而没有两个网络的好。这个是为什么?没有想明白。
4.4和其他网络比较
本文的结果和博文9中的结果有一些差距,感觉可能是训练平台和方法的原因,不同的训练平台和方法对于结果也有影响。

五,定位
5.1 定位网络
和OverFeat的方法类似,使用模型D(参数最少,表现最好)通过回归函数来替换分类器,两种分类方法:SCR(single-classregression),用一个回归函数来学习预测所有类别的bounding box;PCR(per-class regression)每个类别有自己单独的一个回归函数。
训练:分别在S=256和S=384上训练两个模型,网络反馈学习时,探究了两种情况1,fine tuning整个网络;2,只调整全连接层。
测试:
第一种测试框架:定位网络只应用在图像的裁剪中心,用于比较不同的网络修改下性能。

1,发现fine-tuning整个网络的定位性能,比值调整全连接层权值的定位结果要好。
2,PCR比SCR结果好,这个和OverFeat的结果相反。
所以最好的定位方法是采用PCR,fine-tuning整个网络。
第二种测试框架:利用OverFeat的贪婪融合过程(不使用offset pooling),在整个图像上密集应用定位网络;首先根据softmax分类结果给定bounding box的置信得分,然后融合空间相似的bounding box,最后选取最大置信得分的bounding box。
在不同scale下,定位结果。

1,适当的scale对于定位结果有影响S=384好于S=256。
2,multi-scale比single-scale好。
3,multi-model fusion会更好。
和其它state-of-the-art方法比较:

在使用较少的scale下,在不使用offset pooling情况下,本文的结果比OverFeat提高很多;曹成这种提高的原因主要在于网络结构上的不同,好网络,好分类,好定位,估计还有好检测。
六,结论
深度是获得好结果的关键。
一些理解和困惑
感觉本文在网络探讨阶段和博文9中探索最优网络比较类似;都是首先提出一个结果不错的基础网络A,然后在网络A上进行一些列的修改,一步一步地提高网络性能,进而探索好的网络设计应该是什么样的;博文9平衡网络各个因素探讨的方式比本文比计较复杂度情况下增加深度,更加精细。而且两篇文章的关于深度的结论相同,深度可以提升结果,但是深度会饱和。
这里最大的疑问就是他们的网络A是怎么提来的。
博文9中的A结构:
Input(224,224,3)→64F(7,7,3,s=2) →max-p(3,3,3)→128F(5,5,64) →max-p(2,2,2) →256F(3,3,128)→256F(3,3,256)→256F(3,3,256)→spp(6*6,3*3,2*2,1*1)→4096fc→4096fc→softmax
感觉博文9的结构借鉴了Alex-net,ZF-net和本文的VGG,例如这种三段式结构是从瘦身版的Alex-net和ZF-net中来的,第一个卷积层有64个filter而不是96个,感觉是借鉴了本文第一卷积层的结构;还有就是可能依据本文或OverFeat中剔除了LRN。
但是本文的结构就找不到关系了, 5阶段,filter的个数尺寸,网络结构等64-128-256-512-512;使用3*3小filter作者已经解释了原因,但是这个关键的网络结构作者并没有给出具体的设计依据,而是直接给出了结果;感觉一个是凭借经验,再有就是凭借实验;结合博文9中的观点,感觉VGG网络还可以利用其中层析替换思想来提高分类结果。
里一个困惑,就是“PCR比SCR结果好,这个和OverFeat的结果相反”;OverFeat中在三scale下 SCR-vs-PCR为31.3-vs-44.1;SCR要明显好于PCR,OverFeat作者的解释是PCR顶层有更多的回归函数,继而有更多的参数,而每个类别的训练样本有限,导致每个类别的回归函数不能够很好的训练;但是本文作者的网络中PCR明显好于SCR,训练样本并没有增多,现在感觉OverFeat这种每类训练样本少的解释合理性有待商榷;此外网络结构不同感觉是两个结果区别的关键,除卷积提取阶段不同外;全连接层的结构也不同OverFeat网络是4096-1024-regression;本文的网络是4096-4096-regression;从对比来看造成这种差距的原因估计是网络结果上的问题;但是这个可以解释为什么本文的结果比OverFeat的结果好,如果用网络结构来解释PCR比SCR好,感觉有些牵强。所以感觉PCR和SCR两种预测bounding box方法的影响因素,还是有些不明白。“还有一个不同的地方就是在上面的测试中,本文给出了图片真正的分类,然后更具真是的类比,预测bounding box;而不是采用先预测分类,在预测bounding box的方法” 。
二、模型分析
可知,VGG是在AlexNet上所改进的,两者的比较如下:
相同点
1.最后三层FC层(Fully Connected全连接层)结构相同。
2.都分成五层(组)。
3.每层和每层之间用pooling层分开。
不同点
1.AlexNet每层仅仅含有一个Convolution层,filter的大小7x7(很大);而VGG每层含有多个(2~4)个Convolution层,filter的大小是3x3(最小)。很明显,VGG是在模仿Alex的结构,然而它通过降低filter的大小,增加层数来达到同样的效果。我提出我的一个对这种模仿的一种我自己的理解。因为不是论文中讲到,仅仅是我自己的理解,仅供大家参考。
作者在论文中说了一句
"This can be seen as imposing a regularisation on the 7 × 7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters"
他说7x7 filter可以被分解成若干个3x3的filter的叠加。
类比一下n维空间的向量x,x的正交分解
x = x1(1, 0, 0, ....) + x2(0, 1, 0, ...) + x3(0, 0, 1,...) + ... + xn(0, 0, 0, ..., 1)
每一组的每一层的filter被类比成n维欧几里得空间的基底。
若VGG的一组含有3层3x3的filter,则我们则假设一个7x7的filter可以被分解成3种“正交”的3x3的filter。
作者原文:First, we incorporate three non-linearrectification layers instead of a single one, which makes the decision function more discriminative.Second, we decrease the number of parameters: assuming that both the input and the output of athree-layer 3 × 3 convolution stack has C channels, the stack is parametrised by 3 32C^2 = 27C^2weights; at the same time, a single 7 × 7 conv. layer would require 72C^2 = 49C^2
2.AlexNet的Channel明显小于VGG。猜测VGG的之所以能够达到更高的精准性,源自于更多的Channel数。而由于filter size的减小,channel可以大幅度增加,更多的信息可以被提取。
VGG真的创新点太少,他只是通过实验告诉我们网络深度对性能有举足轻重的影响,然后就是卷积核大小的理解。
相关参考:
http://blog.csdn.net/whiteinblue/article/details/43560491
http://hacker.duanshishi.com/?p=1690
http://www.jianshu.com/p/9c6d90e4f20e
以上是关于Vue学习——第五弹的主要内容,如果未能解决你的问题,请参考以下文章