Jetson AGX Xavier实现TensorRT加速YOLOv5进行实时检测
Posted luoganttcc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Jetson AGX Xavier实现TensorRT加速YOLOv5进行实时检测相关的知识,希望对你有一定的参考价值。
上一篇:Jetson AGX Xavier安装torch、torchvision且成功运行yolov5算法
下一篇:Jetson AGX Xavier测试YOLOv4
一、前言
由于YOLOv5在Xavier上对实时画面的检测速度较慢,需要采用TensorRT对其进行推理加速。接下来记录一下我的实现过程。
二、环境准备
如果还没有搭建YOLOv5的python环境,按照下文步骤执行。反之,直接跳过第一步执行第二步。
1、参考文章《Jetson AGX Xavier配置yolov5虚拟环境》建立YOLOv5的Python环境,并参照《Jetson AGX Xavier安装Archiconda虚拟环境管理器与在虚拟环境中调用opencv》,将opencv导入环境,本文Opencv采用的是3.4.3版本。
2、在环境中导入TensorRT的库。与opencv的导入相同。将路径 /usr/lib/python3.6/dist-packages/ 下关于TensorRT的文件夹,复制到自己所创建环境的site-packages文件夹下。例如:复制到/home/jetson/archiconda3/envs/yolov5env/lib/python3.6/site-packages/之下。
3、在环境中安装pycuda,如果pip安装不成功,网上有许多解决办法。
-
conda activate yolov
5env
-
pip install pycuda
三、加速步骤
以加速YOLOv5s模型为例,以下有v4.0与v5.0两个版本,大家任选其一即可。
1、克隆工程
①v4.0
-
git
clone -b v4.0 https://github.com/ultralytics/yolov5.git
-
git
clone -b yolov5-v4.0 https://github.com/wang-xinyu/tensorrtx.git
②v5.0
-
git
clone -b v5.0 https://github.com/ultralytics/yolov5.git
-
git
clone -b yolov5-v5.0 https://github.com/wang-xinyu/tensorrtx.git
2、生成引擎文件
①下载yolov5s.pt到yolov5工程的weights文件夹下。
②复制tensorrtx/yolov5文件夹下的gen_wts.py文件到yolov5工程下。
③生成yolov5s.wts文件。
-
conda activate yolov5env
-
cd /xxx/yolov5
-
-
以下按照自己所下版本选择
-
#v4.0
-
python gen_wts.py
-
-
#v5.0
-
python gen_wts.py -w yolov5s.pt -o yolov5s.wts
④生成引擎文件
进入tensorrtx/yolov5文件夹下。
mkdir build
复制yolov5工程中生成的yolov5s.wts文件到tensorrtx/yolov5/build文件夹中。并在build文件夹中打开终端:
-
cmake ..
-
make
-
#v4.0 sudo ./yolov5 -s [.wts] [.engine] [s/m/l/x/]
-
#v5.0 sudo ./yolov5 -s [.wts] [.engine] [s/m/l/x/s6/m6/l6/x6 or c/c6 gd gw]
-
sudo ./yolov5 -s yolov5s.wts yolov5s.engine s
生成yolov5s.engine文件。
四、加速实现
1、图片检测加速
- sudo ./yolov5 -d yolov5s.engine ../samples
- 或者
- conda activate yolov5env
- python yolov5_trt.py
2、摄像头实时检测加速
由于本人没有学习过C++语言,所以只能硬着头皮修改了下yolov5_trt.py脚本,脚本的代码格式较差,但是能够实现加速,有需要的可以作为一个参考。
在tensorrt工程下新建一个yolo_trt_test.py文件。复制下面 v4.0或者v5.0的代码到yolo_trt_test.py。注意yolov5s.engine的路径,自行更改。
①v4.0代码
-
"""
-
An example that uses TensorRT's Python api to make inferences.
-
"""
-
import ctypes
-
import os
-
import random
-
import sys
-
import threading
-
import time
-
-
import cv2
-
import numpy
as np
-
import pycuda.autoinit
-
import pycuda.driver
as cuda
-
import tensorrt
as trt
-
import torch
-
import torchvision
-
-
INPUT_W =
608
-
INPUT_H =
608
-
CONF_THRESH =
0.15
-
IOU_THRESHOLD =
0.45
-
int_box=[
0,
0,
0,
0]
-
int_box1=[
0,
0,
0,
0]
-
fps1=
0.0
-
def
plot_one_box(
x, img, color=None, label=None, line_thickness=None):
-
"""
-
description: Plots one bounding box on image img,
-
this function comes from YoLov5 project.
-
param:
-
x: a box likes [x1,y1,x2,y2]
-
img: a opencv image object
-
color: color to draw rectangle, such as (0,255,0)
-
label: str
-
line_thickness: int
-
return:
-
no return
-
-
"""
-
tl = (
-
line_thickness
or
round(
0.002 * (img.shape[
0] + img.shape[
1]) /
2) +
1
-
)
# line/font thickness
-
color = color
or [random.randint(
0,
255)
for _
in
range(
3)]
-
c1, c2 = (
int(x[
0]),
int(x[
1])), (
int(x[
2]),
int(x[
3]))
-
C2 = c2
-
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
-
if label:
-
tf =
max(tl -
1,
1)
# font thickness
-
t_size = cv2.getTextSize(label,
0, fontScale=tl /
3, thickness=tf)[
0]
-
c2 = c1[
0] + t_size[
0], c1[
1] + t_size[
1] +
8
-
cv2.rectangle(img, c1, c2, color, -
1, cv2.LINE_AA)
# filled
-
cv2.putText(
-
img,
-
label,
-
(c1[
0], c1[
1]+t_size[
1] +
5),
-
0,
-
tl /
3,
-
[
255,
255,
255],
-
thickness=tf,
-
lineType=cv2.LINE_AA,
-
)
-
-
-
-
-
-
class
YoLov5TRT(
object):
-
"""
-
description: A YOLOv5 class that warps TensorRT ops, preprocess and postprocess ops.
-
"""
-
-
def
__init__(
self, engine_file_path):
-
# Create a Context on this device,
-
self.cfx = cuda.Device(
0).make_context()
-
stream = cuda.Stream()
-
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
-
runtime = trt.Runtime(TRT_LOGGER)
-
-
# Deserialize the engine from file
-
with
open(engine_file_path,
"rb")
as f:
-
engine = runtime.deserialize_cuda_engine(f.read())
-
context = engine.create_execution_context()
-
-
host_inputs = []
-
cuda_inputs = []
-
host_outputs = []
-
cuda_outputs = []
-
bindings = []
-
-
for binding
in engine:
-
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
-
dtype = trt.nptype(engine.get_binding_dtype(binding))
-
# Allocate host and device buffers
-
host_mem = cuda.pagelocked_empty(size, dtype)
-
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
-
# Append the device buffer to device bindings.
-
bindings.append(
int(cuda_mem))
-
# Append to the appropriate list.
-
if engine.binding_is_input(binding):
-
host_inputs.append(host_mem)
-
cuda_inputs.append(cuda_mem)
-
else:
-
host_outputs.append(host_mem)
-
cuda_outputs.append(cuda_mem)
-
-
# Store
-
self.stream = stream
-
self.context = context
-
self.engine = engine
-
self.host_inputs = host_inputs
-
self.cuda_inputs = cuda_inputs
-
self.host_outputs = host_outputs
-
self.cuda_outputs = cuda_outputs
-
self.bindings = bindings
-
-
-
def
infer(
self, input_image_path):
-
global int_box,int_box1,fps1
-
# threading.Thread.__init__(self)
-
# Make self the active context, pushing it on top of the context stack.
-
self.cfx.push()
-
# Restore
-
stream = self.stream
-
context = self.context
-
engine = self.engine
-
host_inputs = self.host_inputs
-
cuda_inputs = self.cuda_inputs
-
host_outputs = self.host_outputs
-
cuda_outputs = self.cuda_outputs
-
bindings = self.bindings
-
-
# Do image preprocess
-
input_image, image_raw, origin_h, origin_w = self.preprocess_image(
-
input_image_path
-
)
-
# Copy input image to host buffer
-
np.copyto(host_inputs[
0], input_image.ravel())
-
# Transfer input data to the GPU.
-
cuda.memcpy_htod_async(cuda_inputs[
0], host_inputs[
0], stream)
-
# Run inference.
-
context.execute_async(bindings=bindings, stream_handle=stream.handle)
-
# Transfer predictions back from the GPU.
-
cuda.memcpy_dtoh_async(host_outputs[
0], cuda_outputs[
0], stream)
-
# Synchronize the stream
-
stream.synchronize()
-
# Remove any context from the top of the context stack, deactivating it.
-
self.cfx.pop()
-
# Here we use the first row of output in that batch_size = 1
-
output = host_outputs[
0]
-
# Do postprocess
-
result_boxes, result_scores, result_classid = self.post_process(
-
output, origin_h, origin_w
-
)
-
# Draw rectangles and labels on the original image
-
for i
in
range(
len(result_boxes)):
-
box1 = result_boxes[i]
-
plot_one_box(
-
box1,
-
image_raw,
-
label=
"::.2f".
format(
-
categories[
int(result_classid[i])], result_scores[i]
-
),
-
)
-
return image_raw
-
-
# parent, filename = os.path.split(input_image_path)
-
# save_name = os.path.join(parent, "output_" + filename)
-
# # Save image
-
# cv2.imwrite(save_name, image_raw)
-
-
def
destroy(
self):
-
# Remove any context from the top of the context stack, deactivating it.
-
self.cfx.pop()
-
-
def
preprocess_image(
self, input_image_path):
-
"""
-
description: Read an image from image path, convert it to RGB,
-
resize and pad it to target size, normalize to [0,1],
-
transform to NCHW format.
-
param:
-
input_image_path: str, image path
-
return:
-
image: the processed image
-
image_raw: the original image
-
h: original height
-
w: original width
-
"""
-
image_raw = input_image_path
-
h, w, c = image_raw.shape
-
image = cv2.cvtColor(image_raw, cv2.COLOR_BGR2RGB)
-
# Calculate widht and height and paddings
-
r_w = INPUT_W / w
-
r_h = INPUT_H / h
-
if r_h > r_w:
-
tw = INPUT_W
-
th =
int(r_w * h)
-
tx1 = tx2 =
0
-
ty1 =
int((INPUT_H - th) /
2)
-
ty2 = INPUT_H - th - ty1
-
else:
-
tw =
int(r_h * w)
-
th = INPUT_H
-
tx1 =
int((INPUT_W - tw) /
2)
-
tx2 = INPUT_W - tw - tx1
-
ty1 = ty2 =
0
-
# Resize the image with long side while maintaining ratio
-
image = cv2.resize(image, (tw, th))
-
# Pad the short side with (128,128,128)
-
image = cv2.copyMakeBorder(
-
image, ty1, ty2, tx1, tx2, cv2.BORDER_CONSTANT, (
128,
128,
128)
-
)
-
image = image.astype(np.float32)
-
# Normalize to [0,1]
-
image /=
255.0
-
# HWC to CHW format:
-
image = np.transpose(image, [
2,
0,
1])
-
# CHW to NCHW format
-
image = np.expand_dims(image, axis=
0)
-
# Convert the image to row-major order, also known as "C order":
-
image = np.ascontiguousarray(image)
-
return image, image_raw, h, w
-
-
def
xywh2xyxy(
self, origin_h, origin_w, x):
-
"""
-
description: Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
-
param:
-
origin_h: height of original image
-
origin_w: width of original image
-
x: A boxes tensor, each row is a box [center_x, center_y, w, h]
-
return:
-
y: A boxes tensor, each row is a box [x1, y1, x2, y2]
-
"""
-
y = torch.zeros_like(x)
if
isinstance(x, torch.Tensor)
else np.zeros_like(x)
-
r_w = INPUT_W / origin_w
-
r_h = INPUT_H / origin_h
-
if r_h > r_w:
-
y[:,
0] = x[:,
0] - x[:,
2] /
2
-
y[:,
2] = x[:,
0] + x[:,
2] /
2
-
y[:,
1] = x[:,
1] - x[:,
3] /
2 - (INPUT_H - r_w * origin_h) /
2
-
y[:,
3] = x[:,
1] + x[:,
3] /
2 - (INPUT_H - r_w * origin_h) /
2
-
y /= r_w
-
else:
-
y[:,
0] = x[:,
0] - x[:,
2] /
2 - (INPUT_W - r_h * origin_w) /
2
-
y[:,
2] = x[:,
0] + x[:,
2] /
2 - (INPUT_W - r_h * origin_w) /
2
-
y[:,
1] = x[:,
1] - x[:,
3] /
2
-
y[:,
3] = x[:,
1] + x[:,
3] /
2
-
y /= r_h
-
-
return y
-
-
def
post_process(
self, output, origin_h, origin_w):
-
"""
-
description: postprocess the prediction
-
param:
-
output: A tensor likes [num_boxes,cx,cy,w,h,conf,cls_id, cx,cy,w,h,conf,cls_id, ...]
-
origin_h: height of original image
-
origin_w: width of original image
-
return:
-
result_boxes: finally boxes, a boxes tensor, each row is a box [x1, y1, x2, y2]
-
result_scores: finally scores, a tensor, each element is the score correspoing to box
-
result_classid: finally classid, a tensor, each element is the classid correspoing to box
-
"""
-
# Get the num of boxes detected
-
num =
int(output[
0])
-
# Reshape to a two dimentional ndarray
-
pred = np.reshape(output[
1:], (-
1,
6))[:num, :]
-
# to a torch Tensor
-
pred = torch.Tensor(pred).cuda()
-
# Get the boxes
-
boxes = pred[:, :
4]
-
# Get the scores
-
scores = pred[:,
4]
-
# Get the classid
-
classid = pred[:,
5]
-
# Choose those boxes that score > CONF_THRESH
-
si = scores > CONF_THRESH
-
boxes = boxes[si, :]
-
scores = scores[si]
-
classid = classid[si]
-
# Trandform bbox from [center_x, center_y, w, h] to [x1, y1, x2, y2]
-
boxes = self.xywh2xyxy(origin_h, origin_w, boxes)
-
# Do nms
-
indices = torchvision.ops.nms(boxes, scores, iou_threshold=IOU_THRESHOLD).cpu()
-
result_boxes = boxes[indices, :].cpu()
-
result_scores = scores[indices].cpu()
-
result_classid = classid[indices].cpu()
-
return result_boxes, result_scores, result_classid
-
-
-
class
myThread(threading.Thread):
-
def
__init__(
self, func, args):
-
threading.Thread.__init__(self)
-
self.func = func
-
self.args = args
-
-
def
run(
self):
-
self.func(*self.args)
-
-
-
if __name__ ==
"__main__":
-
# load custom plugins
-
PLUGIN_LIBRARY =
"build/libmyplugins.so"
-
ctypes.CDLL(PLUGIN_LIBRARY)
-
engine_file_path =
"yolov5s.engine"
-
-
# load coco labels
-
-
categories = [
"person",
"bicycle",
"car",
"motorcycle",
"airplane",
"bus",
"train",
"truck",
"boat",
"traffic light",
-
"fire hydrant",
"stop sign",
"parking meter",
"bench",
"bird",
"cat",
"dog",
"horse",
"sheep",
"cow",
-
"elephant",
"bear",
"zebra",
"giraffe",
"backpack",
"umbrella",
"handbag",
"tie",
"suitcase",
"frisbee",
-
"skis",
"snowboard",
"sports ball",
"kite",
"baseball bat",
"baseball glove",
"skateboard",
"surfboard",
-
"tennis racket",
"bottle",
"wine glass",
"cup",
"fork",
"knife",
"spoon",
"bowl",
"banana",
"apple",
-
"sandwich",
"orange",
"broccoli",
"carrot",
"hot dog",
"pizza",
"donut",
"cake",
"chair",
"couch",
-
"potted plant",
"bed",
"dining table",
"toilet",
"tv",
"laptop",
"mouse",
"remote",
"keyboard",
"cell phone",
-
"microwave",
"oven",
"toaster",
"sink",
"refrigerator",
"book",
"clock",
"vase",
"scissors",
"teddy bear",
-
"hair drier",
"toothbrush"]
-
-
# a YoLov5TRT instance
-
yolov5_wrapper = YoLov5TRT(engine_file_path)
-
cap = cv2.VideoCapture(
0)
-
while
1:
-
_,image =cap.read()
-
img=yolov5_wrapper.infer(image)
-
cv2.imshow(
"result", img)
-
if cv2.waitKey(
1) &
0XFF ==
ord(
'q'):
# 1 millisecond
-
break
-
cap.release()
-
cv2.destroyAllWindows()
-
yolov5_wrapper.destroy()

②v5.0代码
-
"""
-
An example that uses TensorRT's Python api to make inferences.
-
"""
-
import ctypes
-
import os
-
import shutil
-
import random
-
import sys
-
import threading
-
import time
-
import cv2
-
import numpy
as np
-
import pycuda.autoinit
-
import pycuda.driver
as cuda
-
import tensorrt
as trt
-
import torch
-
import torchvision
-
import argparse
-
-
CONF_THRESH =
0.5
-
IOU_THRESHOLD =
0.4
-
-
-
def
get_img_path_batches(
batch_size, img_dir):
-
ret = []
-
batch = []
-
for root, dirs, files
in os.walk(img_dir):
-
for name
in files:
-
if
len(batch) == batch_size:
-
ret.append(batch)
-
batch = []
-
batch.append(os.path.join(root, name))
-
if
len(batch) >
0:
-
ret.append(batch)
-
return ret
-
-
def
plot_one_box(
x, img, color=None, label=None, line_thickness=None):
-
"""
-
description: Plots one bounding box on image img,
-
Jetson AGX Xavier上查看版本
刷机后在Xavier上安装了python,CUDA,cudnn,OpenCV和TensorRT,查看他们的版本。
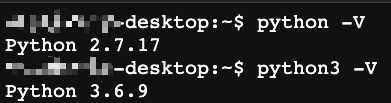
1. python
Xavier上python2和python3都有。
#查看python2版本
python -V
#查看python3版本
python3 -V
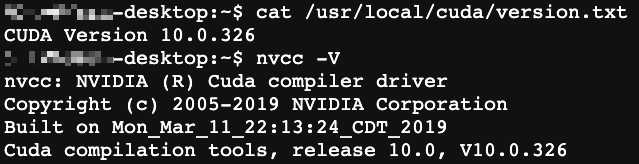
2. CUDA
下面这两种方法都可以的。
cat /usr/local/cuda/version.txt
nvcc -V
3. cudnn
cudnn在Xavier上的位置与一般Ubuntu上的位置是不同的。
cat /usr/include/cudnn.h | grep CUDNN_MAJOR -A 2

4. OpenCV
pkg-config --modversion opencv

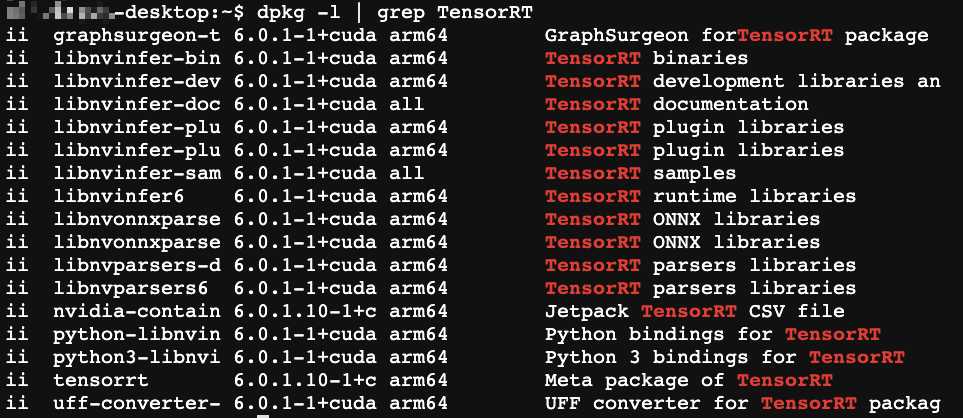
5. TensorRT
dpkg -l | grep TensorRT
以上是关于Jetson AGX Xavier实现TensorRT加速YOLOv5进行实时检测的主要内容,如果未能解决你的问题,请参考以下文章
NVIDIA Jetson AGX Xavier YOLOv5应用与部署
Jetson AGX Xavier JetPack 4.2环境配置