MQkafka——生产者写入为什么这么快?为什么吞吐这么高?
Posted 你个佬六
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MQkafka——生产者写入为什么这么快?为什么吞吐这么高?相关的知识,希望对你有一定的参考价值。
一、前言
前面一篇博客,小编向大家宏观介绍了kafka是什么,在系统中干什么,以及一些kafka相关的名词介绍。
这篇博客呢,小编就向大家介绍一下,生产者怎么把消息发到broker的?以及生产者发送的方法为什么吞吐量这么高?
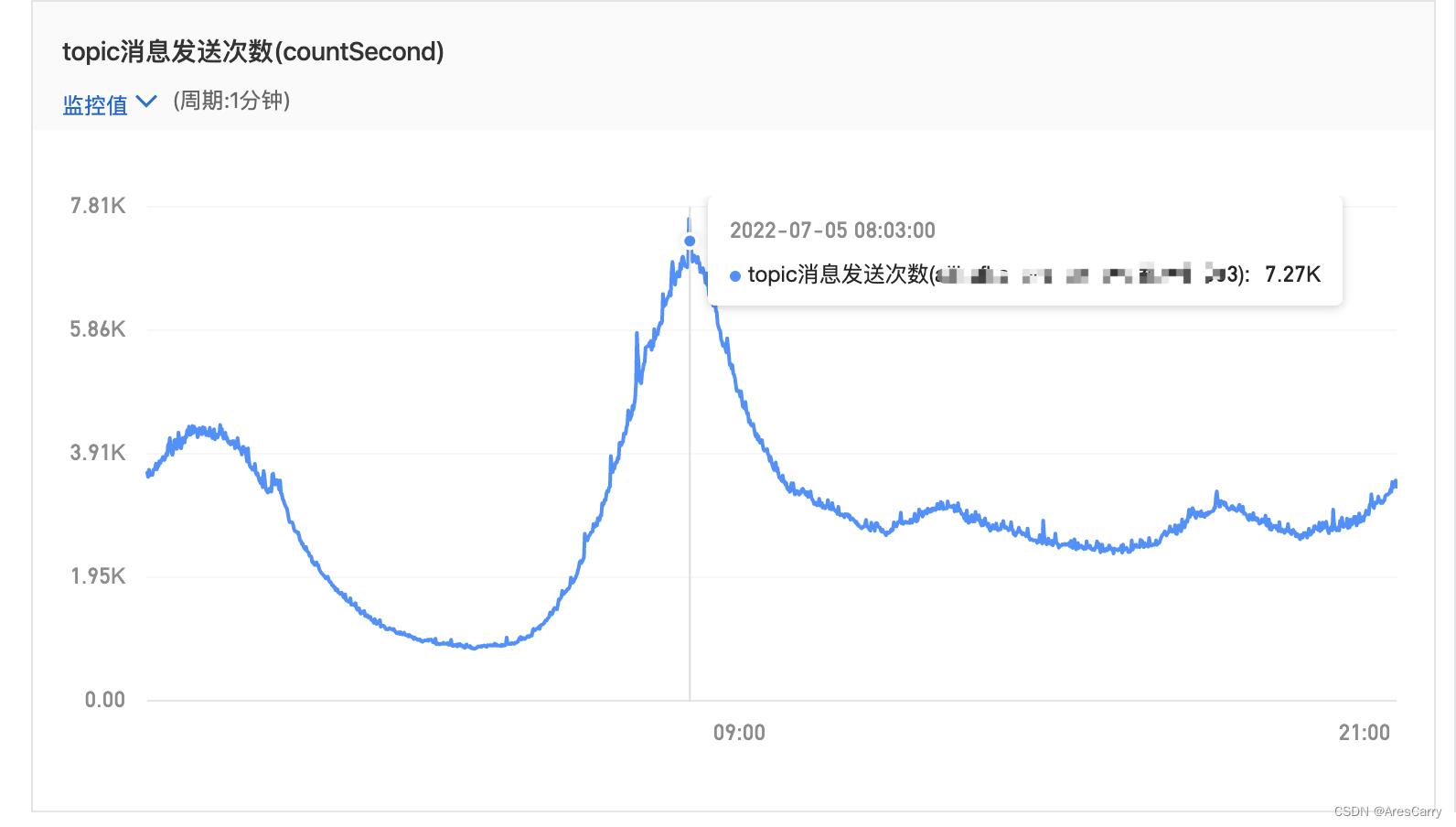
二、吞吐真的很高?有多高?
小编遇到的项目中,一般高峰期的时候,速度是7300条/秒,当搞活动的时候,速度会更高。

三、生产者怎么发的数据?这么快?
生产者写入数据流程
我们先来看一下生产者写入数据的流程,然后再来分析一下生产者的内存模型。
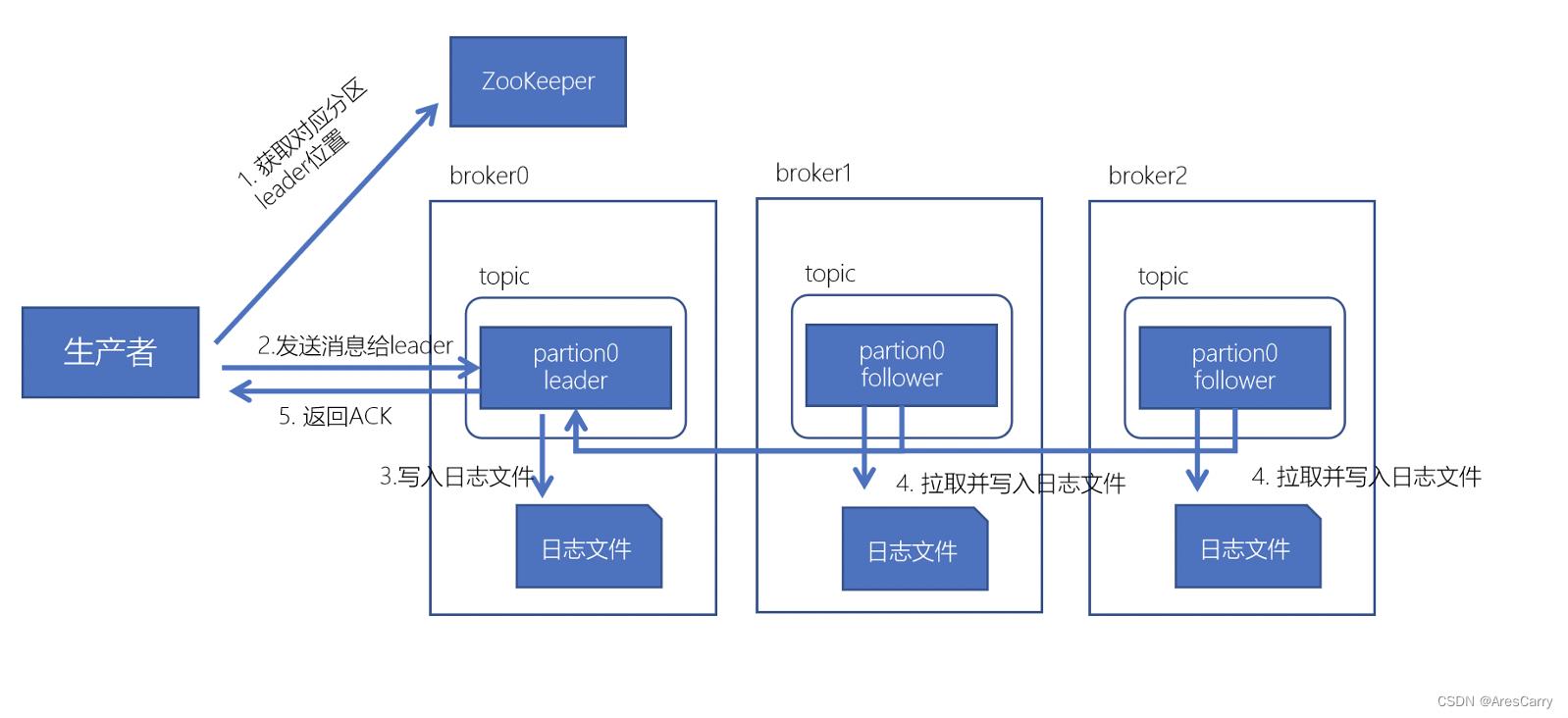
这里如果我们开启了acks = -1 的情况下, 要等所有的follower都要拉去日志完毕后,leader才会返回ack。
生产者的内存结构,为什么会有如此高的吞吐量
其他问法:
Kafka生产者 为什么能够避免过多的jvm 的GC操作?
kafka生产者的内存结构?
kafka生产者是如何发送消息的?
答:消息暂时缓存,批量发送。
发送者 中有一个 RecordAccumulator.class,专门缓冲kafka消息。
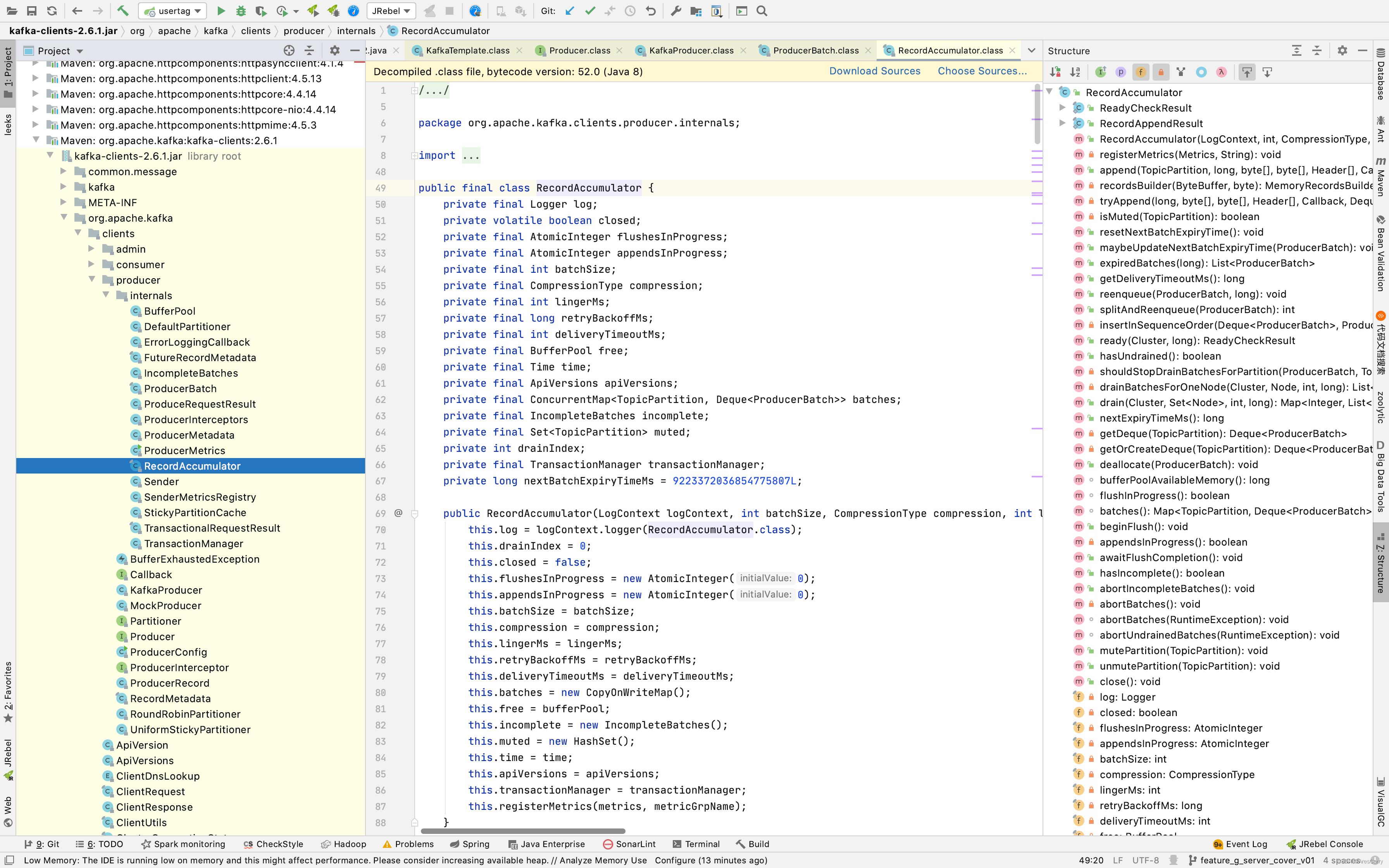
看看这个类的结构,缓冲内存分成了已使用和未使用的内存,总共一起默认是32mb,也可以通过spring.kafka.producer.buffer-memory = 33554432 设置,33554432/1024=32768。这个是默认值。
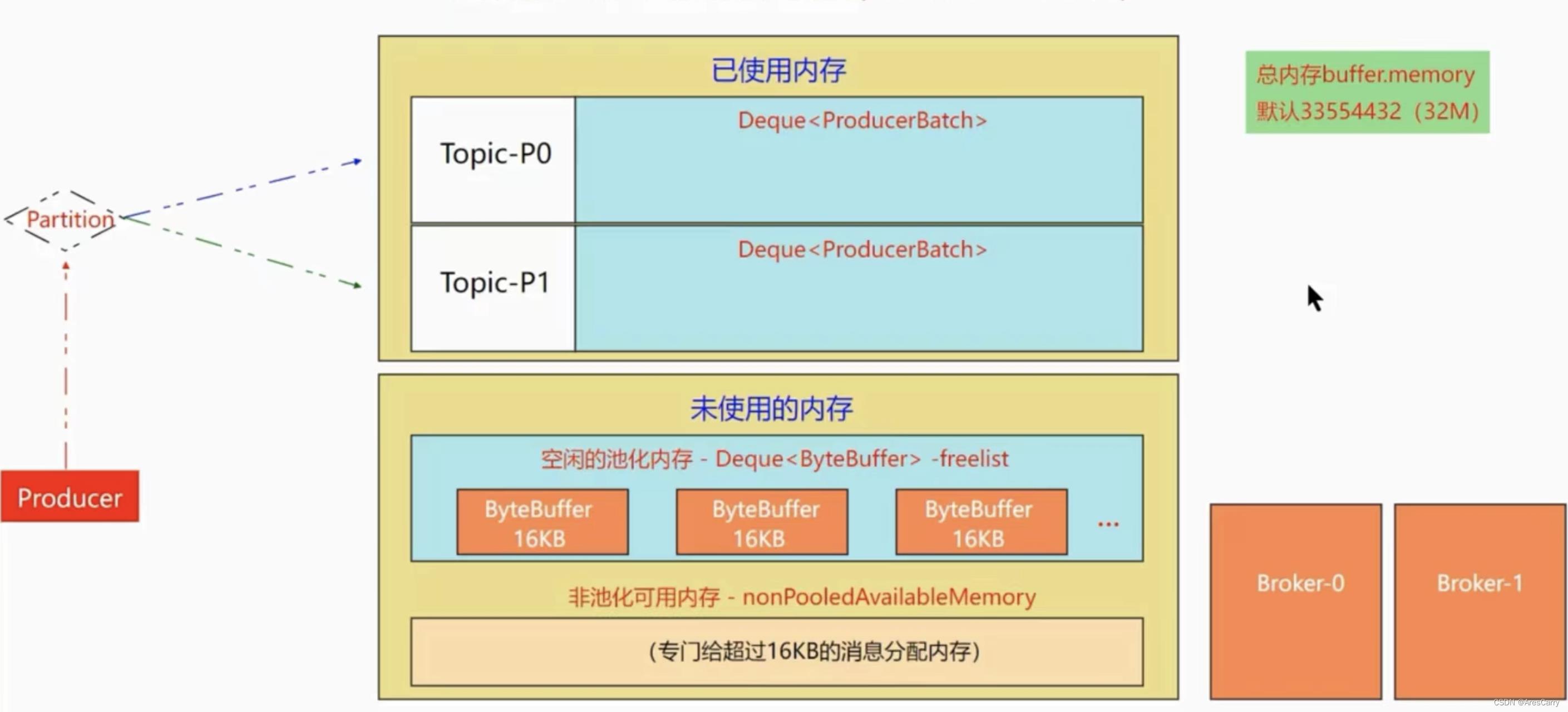
-
已使用内存
消息使用的内存,使用的内存中,包含很多Deque< ProducerBatch >,这个是一批次消息,大小为16kb,具体一批次有多少消息,要看一条消息的大小。按照批次发给broker。这里就可以看到消息的打包,批量发送。 -
未使用内存 ——池化内存
分成了很多大小为16kb的内存bytebuffer,已使用的ProducerBatch发送到broker后,ProducerBatch占用的内存会放到池化内存队列尾部,然后调用ByteBuffer.clear方法,清空数据。这里没有涉及到JVM的gc,所以效率很高。并且bytebuffer还可以重复利用。 -
未使用内存 —— 非池化内存
一整块内存,在需要的时候进行切割
这里有两个参数:
batch.size:ProducerBatch 只有数据累积到batchsize后,sender才会发送数据,默认16kb
linger.ms:如果数据迟迟未达到batch.size,sender会等待linger.ms后发送数据,单位ms,默认 是0ms,表示没有延迟。
我们分四种情况来看
-
消息小于 16k,池化内存有
○ 从池化申请一个 16kb的byteBuffer ,去使用。 -
消息小于16k,池化内存不够
○ 从非池化内存申请一个 16kb的byteBuffer,去使用,使用完成后,内存归还给池化内存。原因是:系统感觉内存不够用,主动放到池化中使用,减少切割,如果还给非池化内存,要经过jvm的gc。 -
消息大于16k,池化和非池化内存都充足
○ 只能从非池化内存申请,使用完后,还要还给非池化内存,要jvm的gc。原因:池化都是16kb以下的。 -
消息大于16k,非池化内存不够
○ 非池化会向池化内存借用,池化每次给16kb,看非池化是否够用。使用完成后返给非池化内存,要jvm的gc。
四、小结
从上面的介绍,我们可以知道生产者是通过 内存缓冲消息,批量发送给broker,这个设计也很巧妙,减少了操作次数。一通百通。
其实很多业务我们也是可以借鉴这个思路的,比如,秒杀场景,压力在我们的数据库,访问量大的时候,就会有很多次请求。
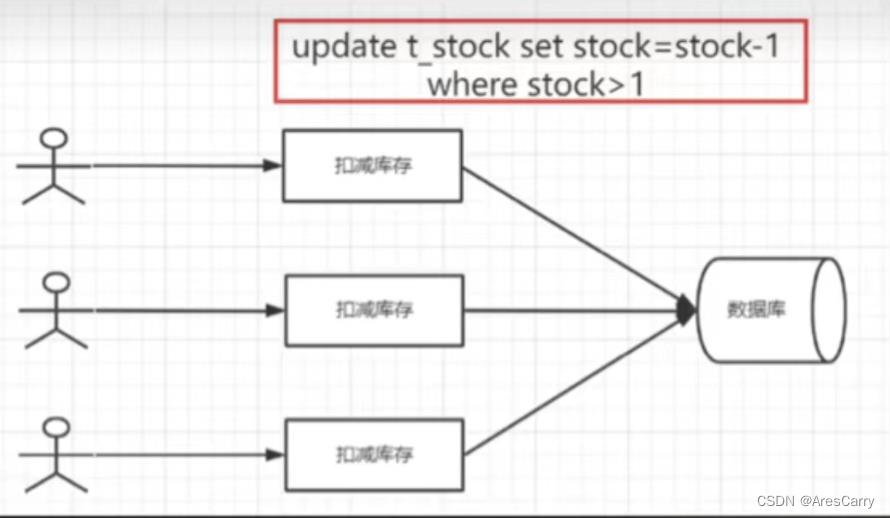
我们就可以借鉴kafka的请求合并,批量发送的思想。把请求合并后,组成一条sql,在执行,这样数据库的压力就小很多了。
以上是关于MQkafka——生产者写入为什么这么快?为什么吞吐这么高?的主要内容,如果未能解决你的问题,请参考以下文章