(十七)迭代器模式详解(foreach的精髓)
Posted 左潇龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(十七)迭代器模式详解(foreach的精髓)相关的知识,希望对你有一定的参考价值。
作者:zuoxiaolong8810(左潇龙),转载请注明出处。
各位好,很久没以LZ的身份和各位对话了,前段时间为了更加逼真的解释设计模式,LZ费尽心思给设计模式加入了故事情节,本意是为了让各位在看小说的过程中就可以接触到设计模式,不过写到现在,LZ最深的感触就是,构思故事的时间远远超过了LZ对设计模式本身的研究。
本章介绍迭代器模式,不再采用故事嵌入的讲解方式,主要原因是因为迭代器模式本身有更多需要介绍的东西,如果嵌入到小说当中,会不太方便去阐述这些内容。
另外,由于LZ的大部分设计模式文章主要针对的人群是对设计模式已经有一定了解,希望更加深入理解的程序猿们。所以LZ希望各位在看本篇文章时,可以打开一个初步介绍迭代器模式的文章,对比观看。下面进入正题,我们先来看看百度百科或者说GOF对迭代器模式的定义。
定义:提供一种方法顺序访问一个聚合对象中各个元素,而又不需暴露该对象的内部表示。
从定义中可以看出,迭代器模式是为了在不暴露该对象内部表示的情况下,提供一种顺序访问聚合对象中元素的方法。这种思想在JAVA集合框架中已经体现的淋漓尽致,而且LZ相信每一个接触JAVA的同学都难免要去触碰。
所以LZ这次先不给出迭代器的类图与标准实现,我们先来看看迭代器模式解决了JAVA集合框架中的哪些问题。
为了更加清晰,LZ斗胆写了几个简单的集合类(向JDK类库的缔造者致敬),我们从这几个简单的集合类出发,去仔细体会下定义的意思,下面是LZ分别写的缩小版的ArrayList、LinkedList和HashSet。
package com.iterator;
public class ArrayList<E>
private static final int INCREMENT = 10;
private E[] array = (E[]) new Object[10];
private int size;
public void add(E e)
if (size < array.length)
array[size++] = e;
else
E[] copy = (E[]) new Object[array.length + INCREMENT];
System.arraycopy(array, 0, copy, 0, size);
copy[size++] = e;
array = copy;
public Object[] toArray()
Object[] copy = new Object[size];
System.arraycopy(array, 0, copy, 0, size);
return copy;
public int size()
return size;
package com.iterator;
public class LinkedList<E>
private Entry<E> header = new Entry<E>(null, null, null);
private int size;
public LinkedList()
header.next = header.previous = header;
public void add(E e)
Entry<E> newEntry = new Entry<E>(e, header, header.next);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
public int size()
return size;
public Object[] toArray()
Object[] result = new Object[size];
int i = size - 1;
for (Entry<E> e = header.next; e != header; e = e.next)
result[i--] = e.value;
return result;
private static class Entry<E>
E value;
Entry<E> previous;
Entry<E> next;
public Entry(E value, Entry<E> previous, Entry<E> next)
super();
this.value = value;
this.previous = previous;
this.next = next;
package com.iterator;
import java.util.HashMap;
import java.util.Map;
public class HashSet<E>
private static final Object NULL = new Object();
private Map<E, Object> map = new HashMap<E, Object>();
public void add(E e)
map.put(e, NULL);
public int size()
return map.size();
public Object[] toArray()
return map.keySet().toArray();
package com.iterator;
public class Main
public static void main(String[] args)
ArrayList<Integer> arrayList = new ArrayList<Integer>();
for (int i = 1; i <= 11; i++)
arrayList.add(i);
System.out.println("arrayList size:" + arrayList.size());
Object[] arrayListArray = arrayList.toArray();
for (int i = 0; i < arrayListArray.length; i++)
System.out.println(arrayListArray[i]);
System.out.println("----------------------------------------------");
HashSet<Integer> hashSet = new HashSet<Integer>();
for (int i = 1; i <= 11; i++)
hashSet.add(i);
System.out.println("hashSet size:" + hashSet.size());
Object[] setArray = hashSet.toArray();
for (int i = 0; i < setArray.length; i++)
System.out.println(setArray[i]);
System.out.println("----------------------------------------------");
LinkedList<Integer> linkedList = new LinkedList<Integer>();
for (int i = 1; i <= 11; i++)
linkedList.add(i);
System.out.println("linkedList size:" + linkedList.size());
Object[] linkedListArray = linkedList.toArray();
for (int i = 0; i < linkedListArray.length; i++)
System.out.println(linkedListArray[i]);
各位思考一下,我们这里的遍历是如何做到的。很明显,我们是通过一个通用的方法,toArray做到的。当然,为了迎合面向接口的思想,你可以添加一个接口规定toArray的行为,让三个类去实现它。
但是在这里有一个很大的弊端,不知道各位注意到没有,那就是不论我们的集合类是如何实现的(比如链表,数组,散列),在使用数组遍历集合类的时候,我们其实遍历了两次。
在这三个类中,由于System的arraycopy和set的toArray方法是黑箱子,所以最明显的便是LinkedList的实现,它是先遍历了一遍链表,做出来一个数组,然后当客户端获得到这个数组的时候,则需要再来一次循环,去遍历每一个元素。
为何会是这种情况呢?
很简单,因为我们的集合类本身就不是一个数组,所以自然要多一步从集合类到数组的过渡。哪怕是本身由数组实现的ArrayList,也避免不了多这一步,各位可以试一下在ArrayList中直接返回array属性,结果中会出现一堆null值,而且这样做的话,对于array的改变会直接影响到ArrayList本身,这并不是我们所希望看到的,所以我们返回的只是一个拷贝。
当然,为了解决这个问题,我们并不是没有办法,比如给LinkedList和ArrayList加入get方法,而这个方法有一个参数index,这是我们常用的遍历方法。如此一来,便解决了二次遍历的问题。
但是问题又来了,那就是我们无法给HashSet提供一个根据索引获取元素的方法,由于散列特性的缘故,set中的元素是无序的,或者说顺序是不被保证的。那么这个get方法,在HashSet中便无法提供,因为这里没有我们通俗意义上的索引的概念。
可以看到,上面LZ粗浅的分析,得出一个结论。三个集合类,如果统一提供数组给客户端遍历,那么在遍历过程中会出现重复遍历的现象。而如果消除这种重复遍历,则由于内部数据结构的不同,三个集合类无法做到像提供数组一样,给客户端提供统一的遍历方式。
为了解决上面的问题,迭代器模式就随之出现了。我们先来看看迭代器模式在百度百科中的类图,稍后各位可以自己体会下,迭代器模式是否解决了上面的问题,以及是否提供了额外的一些好处。

看着上面的类图,我们可以分析出来,上面我们所写的ArrayList等三个类都属于ConcreteAggregate的位置。如果我们刚才设计一个数组接口让三个类去实现的话,其实已经和迭代器模式十分相似了。他们的类图会是下面这样的。
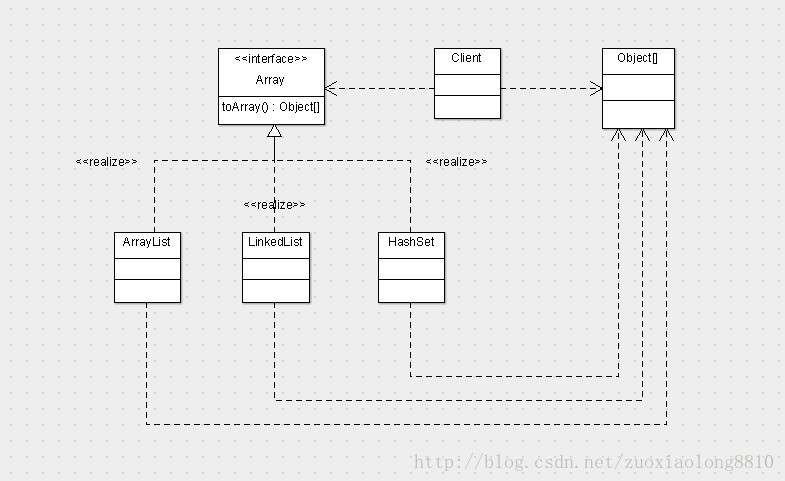
在上述类图中,我们从面向对象的角度思考,将Object[]当做一个对象对待,我们对比下两个类图,他们其实是非常相似的,其中最大的区别在于,第二个类图当中,没有抽象数组接口这个概念,而在迭代器模式的类图中,是有迭代器接口这个概念的。
上述区别最终所造成的结果就是,由于数组是以固定的排列方式存在的,即数组必须是一组连续的内存区域(逻辑上连续),故而以数组为基础的遍历方式只能是按照索引遍历。而迭代器则不限制,我们注意到,在迭代器模式的类图中,具体的迭代器是有一条到具体聚合对象的关联线的,这就意味着迭代器的实现是与具体的聚合对象息息相关的,也就是说迭代器满足了多种迭代方式。
好了,截止到目前,我们前面所讨论的都是为何要使用迭代器模式,或者说迭代器模式解决了哪些问题。我们来稍微总结一下。
1、迭代器模式可以提供统一的迭代方式,这个要归功于Iterator接口。
2、迭代器模式可以在对客户透明的前提下,做出各种不同的迭代方式。
3、在迭代的时候不需要暴露聚合对象的内部表示,我们只需要认识Iterator即可。
4、在第1条的前提下,解决了基于数组的迭代方式中重复遍历的问题。
这里LZ就不再给出迭代器模式的标准代码实现了,如果各位看过LZ的前十几篇设计模式,会发现,LZ其实很多时候是不写标准实现的,一个是因为网上的这种资料很多,很容易找到,LZ不想重复造轮子。还有一个重要的原因是,标准实现总难免给人死板硬套的感觉,很难让人理解,至少LZ个人当时是这种感觉。
这里LZ直接使用迭代器模式,将我们上面的三个集合类稍微优化一下,首先我们应该写一个迭代器接口,它大概会有类图中的那几个方法。为了简单起见,我们直接利用JDK提供的Iterator接口,源码如下。
public interface Iterator<E>
boolean hasNext();
E next();
void remove();
public interface Iterable<T>
Iterator<T> iterator();
下面我们就让三个集合类全部提供一个方法,可以返回一个Iterator实例,并且实现Iterable接口。
package com.iterator;
import java.util.Iterator;
public class ArrayList<E> implements Iterable<E>
private static final int INCREMENT = 10;
private E[] array = (E[]) new Object[10];
private int size;
public void add(E e)
if (size < array.length)
array[size++] = e;
else
E[] copy = (E[]) new Object[array.length + INCREMENT];
System.arraycopy(array, 0, copy, 0, size);
copy[size++] = e;
array = copy;
public Object[] toArray()
Object[] copy = new Object[size];
System.arraycopy(array, 0, copy, 0, size);
return copy;
public int size()
return size;
public Iterator<E> iterator()
return new Itr();
private class Itr implements Iterator<E>
int cursor = 0;
public boolean hasNext()
return cursor != size();
public E next()
return array[cursor++];
public void remove()
package com.iterator;
import java.util.Iterator;
public class LinkedList<E> implements Iterable<E>
private Entry<E> header = new Entry<E>(null, null, null);
private int size;
public LinkedList()
header.next = header.previous = header;
public void add(E e)
Entry<E> newEntry = new Entry<E>(e, header, header.next);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
public int size()
return size;
public Object[] toArray()
Object[] result = new Object[size];
int i = size - 1;
for (Entry<E> e = header.next; e != header; e = e.next)
result[i--] = e.value;
return result;
private static class Entry<E>
E value;
Entry<E> previous;
Entry<E> next;
public Entry(E value, Entry<E> previous, Entry<E> next)
super();
this.value = value;
this.previous = previous;
this.next = next;
public Iterator<E> iterator()
return new Itr();
private class Itr implements Iterator<E>
Entry<E> current = header;
public boolean hasNext()
return current.previous != header;
public E next()
E e = current.previous.value;
current = current.previous;
return e;
public void remove()
package com.iterator;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class HashSet<E> implements Iterable<E>
private static final Object NULL = new Object();
private Map<E, Object> map = new HashMap<E, Object>(7,1);
public void add(E e)
map.put(e, NULL);
public int size()
return map.size();
public Object[] toArray()
return map.keySet().toArray();
public Iterator<E> iterator()
return map.keySet().iterator();
package com.iterator;
import java.util.Iterator;
public class Main
public static void main(String[] args)
ArrayList<Integer> arrayList = new ArrayList<Integer>();
for (int i = 1; i <= 11; i++)
arrayList.add(i);
System.out.println("arrayList size:" + arrayList.size());
Iterator<Integer> arrayListIterator = arrayList.iterator();
while(arrayListIterator.hasNext())
System.out.println(arrayListIterator.next());
System.out.println("----------------------------------------------");
HashSet<Integer> hashSet = new HashSet<Integer>();
for (int i = 1; i <= 11; i++)
hashSet.add(i);
System.out.println("hashSet size:" + hashSet.size());
Iterator<Integer> hashSetIterator = hashSet.iterator();
while(hashSetIterator.hasNext())
System.out.println(hashSetIterator.next());
System.out.println("----------------------------------------------");
LinkedList<Integer> linkedList = new LinkedList<Integer>();
for (int i = 1; i <= 11; i++)
linkedList.add(i);
System.out.println("linkedList size:" + linkedList.size());
Iterator<Integer> LinkedListIterator = linkedList.iterator();
while(LinkedListIterator.hasNext())
System.out.println(LinkedListIterator.next());
package com.iterator;
public class Main
public static void main(String[] args)
ArrayList<Integer> arrayList = new ArrayList<Integer>();
for (int i = 1; i <= 11; i++)
arrayList.add(i);
System.out.println("arrayList size:" + arrayList.size());
for (Integer i : arrayList)
System.out.println(i);
System.out.println("----------------------------------------------");
HashSet<Integer> hashSet = new HashSet<Integer>();
for (int i = 1; i <= 11; i++)
hashSet.add(i);
System.out.println("hashSet size:" + hashSet.size());
for (Integer i : hashSet)
System.out.println(i);
System.out.println("----------------------------------------------");
LinkedList<Integer> linkedList = new LinkedList<Integer>();
for (int i = 1; i <= 11; i++)
linkedList.add(i);
System.out.println("linkedList size:" + linkedList.size());
for (Integer i : linkedList)
System.out.println(i);

从类图中可以清楚的看出,与迭代器模式的类图是一模一样的,当然,客户端与Iterable的依赖关系有待商议,之前我们已经提到过,JAVA集合框架的工厂方法模式是非透明的处理方式,所以我们很多时候不会使用Iterable,不过这并不影响我们对迭代器模式的理解。
然而迭代器模式所带来的好处已经不言而喻,上面分析的过程中已经提到过,LZ这里不再赘述。
值得注意的是,LZ全部采用的内部类作为各个集合类迭代器的实现,这在LZ之前的文章中已经提到过,当时的解释是说内部类是为了完全杜绝客户端对迭代器实现类的依赖,而进行到现在,我们可以更深一步讨论。
这里我们的理解是,内部类在这里目的是为了隐藏实现细节,并且如此一来,迭代器的实现类可以自由的使用集合类的各个属性,而不需要集合类提供自己属性访问的接口以及建立二者的关联关系,这种感觉十分像C/C++中的友元类。
不过缺点也接踵而至,由于具体的集合类与具体的迭代器是绑定的关系,所以这种实现方式在复用的过程中会有很大的限制甚至是不能复用,这个缺点对于C/C++中的友元类来说,是不存在的。
到此,迭代器模式的介绍就基本结束了,希望各位可以从LZ的分析当中得到一点益处,LZ便十分知足了。下面是对于foreach语法的深入讨论,新手或者已经了解的同学们可以忽略,当然,如果新手们有耐心,也可以继续看下去。
JAVA的foreach语法中,冒号后面的变量可以是两种,一个是数组,一个便是实现了Iterable接口的任何类,数组的迭代方式本次不在讨论之列,我们主要关注实现了Iterable接口的类,是如何使用foreach遍历的。
我们使用JDK中自带的一个工具javap,去获得刚才Main类的class文件描述,去看看遍历的过程。我们在命令行模式下,进入到Main类class文件的目录中,然后执行下面的命令,为了更加清晰,我们只保留ArrayList的代码片段,将其余两部分删掉或者注释掉。

执行这个命令,我们可以看到在main函数中有关foreach的JVM指令,我们来看下JVM是怎么执行foreach的,生成的有关内容如下。
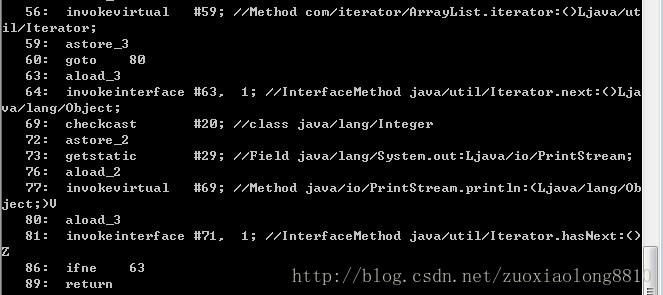
各位的行数不一定会和LZ一样,不过总能找到和LZ一样的JVM指令片段,下面LZ直接按照上面的行号去解释每一行都做了什么事情。
56:执行arrayList的iterator方法。
59:将返回值从值栈赋给第四个引用变量,这个是在解释执行过程中自动加入的临时变量。
60:跳到80行。
80:将第四个引用变量压入值栈,这个引用变量是个迭代器,也就是iterator方法的返回值。
81:执行接口方法hasNext。
86:当hasNext方法返回的值不等于0时,也就是不为false时,跳到63行。
63:将第四个引用变量压入值栈。
64:执行接口方法next。
69:检查强转,不成功将ClassCastException。
72:将next返回的值强转后赋给第三个引用变量,在代码里相当于i。
73:获取out输出流静态属性,压入值栈。
76:将i压入值栈。
77:执行println方法,打印i。
80:同上面的80行。
到这里,可以看到,JVM对于foreach的执行过程,其实相当于下面的代码。
//其中iterator这个变量就是第四个引用变量,i是第三个。
for (Iterator iterator = arrayList.iterator(); iterator.hasNext();)
Integer i = (Integer) iterator.next();
System.out.println(i);
对于foreach的语法就分析到这里了,最后我们再对迭代器模式进行一下总结。
迭代器模式是为了在隐藏聚合对象的内部表示的前提下,提供一种遍历聚合对象元素的方法。这在之前的例子当中已经有体现,我们给三个集合类提供了统一的遍历方式,消除了重复遍历,最终还使用内部类将细节包装在集合类内部隐藏起来,使得外部无法访问集合类的任何一个属性。
这当中还使用到了工厂方法模式,这个在工厂方法模式一章中,LZ已经提到过,对于迭代器的产生,是工厂方法模式处理的。两个设计模式互相结合,让JAVA的集合框架更加优美、健壮。
LZ如此诠释迭代器模式,希望对大家有帮助,好了,咱们下期再见吧。
以上是关于(十七)迭代器模式详解(foreach的精髓)的主要内容,如果未能解决你的问题,请参考以下文章