MapReduce进阶:多路径输入输出
Posted Q-WHai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce进阶:多路径输入输出相关的知识,希望对你有一定的参考价值。
前言
当我们得意于 MapReduce 从一个数据输入目录,把数据经过程序处理之后输出到另一个目录时。可能你正在错过一些更好的方案,因为 MapReduce 是支持多路径的输入与输出的。比如,你一个项目中的多个 Job 产生了多个输出路径,后面又需要另一个 Job 去处理这些不路径下的数据。你要怎么办?暂停程序后,手动处理?看完本文,我想你会给你的这种想法来上一记耳光。(说笑了,别当真)
版权说明
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
本文作者:Q-WHai
发表日期: 2016年6月18日
本文链接:https://qwhai.blog.csdn.net/article/details/51707283
来源:CSDN
更多内容:分类 >> 大数据之 Hadoop
多路径输入
写了这么多的 MapReudce 的程序,我想你一定已经了解了 MapReduce 是如何将输入的数据加载到程序中进行计算的了。一般情况下,我们是通过 FileInputFormat 类的 addInputPath 方法。看到这个 add 关键字,就可能产生很多联想,事实上这种联想是正确的。我们的确可以使用多个目录共同输入数据,并且还不止一种方式。
方式一
可以多添加几个输入目录,只要按照之前添加一个目录的方式,继续添加就 ok 了。就像下面这样:
FileInputFormat.addInputPath(job, new Path(inputPath_1));
FileInputFormat.addInputPath(job, new Path(inputPath_2));
FileInputFormat.addInputPath(job, new Path(inputPath_3));
这里如果你是一个重视代码细节的人,你肯定会重构这段代码:
private void setInputPathMothed1(Job job) throws IOException
FileInputFormat.addInputPath(job, new Path(inputPath_1));
FileInputFormat.addInputPath(job, new Path(inputPath_2));
FileInputFormat.addInputPath(job, new Path(inputPath_3));
方式二
如果你嫌上面的代码太多了,你还有另外一种选择:
FileInputFormat.addInputPaths(job, String.join(",", inputPath_1, inputPath_2, inputPath_3));
通过上面的代码,你可以一次性全部加载这些不同的目录,很方便。
当我们打开 FileInputFormat.addInputPaths() 的源码,看到 addInputPaths() 的代码:
/**
* Add the given comma separated paths to the list of inputs for
* the map-reduce job.
*
* @param job The job to modify
* @param commaSeparatedPaths Comma separated paths to be added to
* the list of inputs for the map-reduce job.
*/
public static void addInputPaths(Job job,
String commaSeparatedPaths
) throws IOException
for (String str : getPathStrings(commaSeparatedPaths))
addInputPath(job, new Path(str));
这里看似方便的 FileInputFormat.addInputPaths(),其实只是 hadoop 给我们这些懒惰的开发者的进一层封装罢了。
方式三:
这种方式有一些特殊,也是我推荐你去使用的一种方式。你可以先看代码感受一下。
private void setInputPathMothed3(Job job) throws IOException
MultipleInputs.addInputPath(job, new Path(inputPath_1), TextInputFormat.class, CoreComputer.CoreMapper.class);
MultipleInputs.addInputPath(job, new Path(inputPath_2), TextInputFormat.class, CoreComputer.CoreMapper.class);
MultipleInputs.addInputPath(job, new Path(inputPath_3), TextInputFormat.class, CoreComputer.CoreMapper.class);
上面的代码中使用一个新的类 MultipleInputs。从类的命名上就可以看到这是一个专门处理多路径输入的问题的。在上面的代码中,我们看到 MultipleInputs.addInputPath() 多了两个不同的参数。进入源码可以看到他们分别是输入数据的格式,以及数据处理的 Mapper。
其实这两个参数是可以让你通过更加灵活的方式来处理数据。inputFormatClass 是可以让你输入不同类型的数据,mapperClass 是可以让你使用不同的 Mapper 来处理不同的数据。正因为这种可选择性,你的程序就更加的灵活了。不过上面的代码中,我并没有采用不同的 Mapper,如果你感兴趣,可以尝试一下。
小结
看到这里,你可能会有疑惑,难道在 Mapper 和 Reducer 里面就不用设置了么?是的,我们不需要调整 Mapper 和 Reducer 的核心代码就可以实现多路径输入。
多路径输出
核心代码修改
多路径的输出没有多路径输入那么多可选择的方案,且在多路径输出中,需要编写的代码量也比多路径输入要多一些。其中还包括了对 Reducer 的修改。详细的参考下面的代码。
public static class CoreReducer extends Reducer<Text, IntWritable, Text, IntWritable>
private MultipleOutputs<Text, IntWritable> multipleOutputs = null;
@Override
protected void setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException
multipleOutputs = new MultipleOutputs<Text, IntWritable>(context);
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException
( ... 省略无关的 N 行 ... )
multipleOutputs.write(splitKeys[1], new Text(splitKeys[0]), count);
@Override
protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException
multipleOutputs.close();
上面的代码中,setup() 与 cleanup() 模块只是对 MultipleOutputs 的初始化与关闭操作,需要说明的地方不多。主要有以下两点:
- 将 MultipleOutputs 的初始化放在 setup() 中,因为在 setup() 只会被调用一次,如果放在 reduce() 中,则 MultipleOutputs 可能被 reduce 方法初始化 N 次,而你全然不知;
- 你需要在 cleanup() 方法中关闭 MultipleOutputs。通过源码我们了解到,关闭 MultipleOutputs,也就是关闭 RecordWriter,并且是一堆 RecordWriter,因为这里会有很多 reduce 被调用。
/**
* Closes all the opened outputs.
*
* This should be called from cleanup method of map/reduce task.
* If overridden subclasses must invoke <code>super.close()</code> at the
* end of their <code>close()</code>
*
*/
@SuppressWarnings("unchecked")
public void close() throws IOException, InterruptedException
for (RecordWriter writer : recordWriters.values())
writer.close(context);
还有一个是你需要重点关注的,那就是 reduce() 方法里的 multipleOutputs.write(…)。你需要把以前的 context.write(…) 替换成现在的这个。
调用代码修改
客户端调用方面,只需要在代码
FileOutputFormat.setOutputPath(job, new Path(outputPath));
之前添加多路径的设置,即可。如下:
public class ComputerClient
public static void main(String[] args) throws Exception
( ... 省略无关的 N 行 ... )
private void execute() throws Exception
runFirstJob();
private int runFirstJob() throws Exception
( ... 省略无关的 N 行 ... )
addNamedOutput(job);
FileOutputFormat.setOutputPath(job, new Path(outputPath));
return job.waitForCompletion(true) ? 0 : 1;
private void addNamedOutput(Job job)
addNamedOutput(job, "android");
addNamedOutput(job, "hadoop");
addNamedOutput(job, "ios");
addNamedOutput(job, "java");
addNamedOutput(job, "python");
private void addNamedOutput(Job job, String pathName)
MultipleOutputs.addNamedOutput(job, pathName, TextOutputFormat.class, Text.class, IntWritable.class);
效果展示
通过上面的学习并编写正确的程序,这样就可以获得如下的效果。
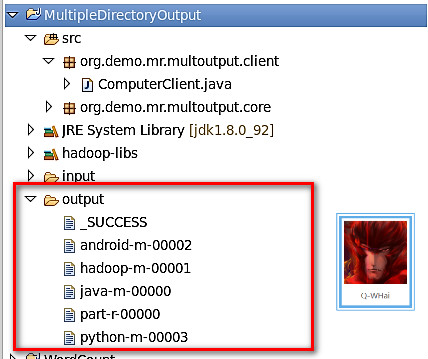
工程源码下载
- http://download.csdn.net/detail/u013761665/9553523
征集
如果你也需要使用ProcessOn这款在线绘图工具,可以使用如下邀请链接进行注册:
https://www.processon.com/i/56205c2ee4b0f6ed10838a6d
以上是关于MapReduce进阶:多路径输入输出的主要内容,如果未能解决你的问题,请参考以下文章