






 18、可选择”简体中文“,也可选择”English“
18、可选择”简体中文“,也可选择”English“
 20、选择”汉语“
20、选择”汉语“
 22、主机名随意
22、主机名随意
 26、用户名随意
26、用户名随意
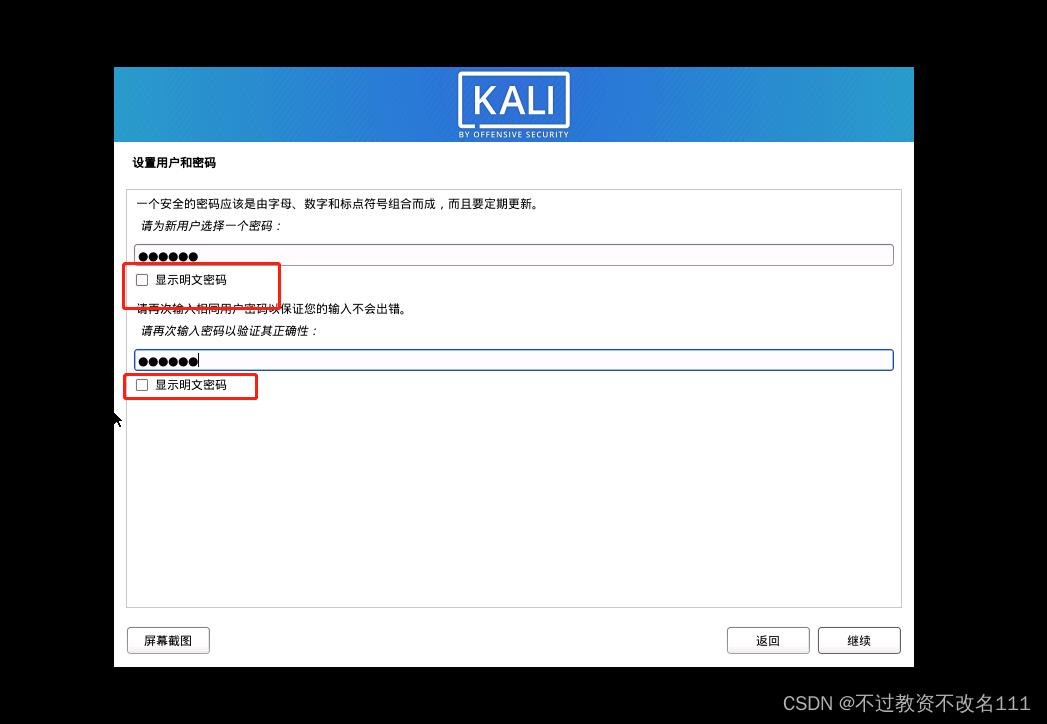
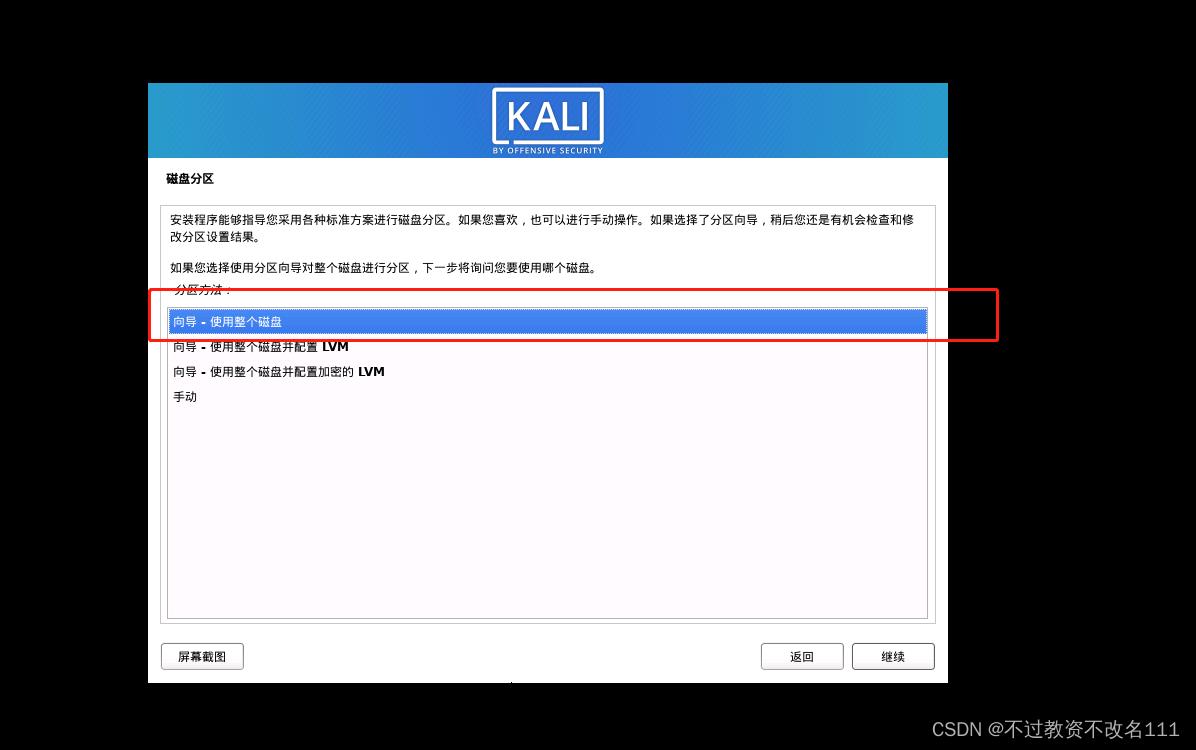
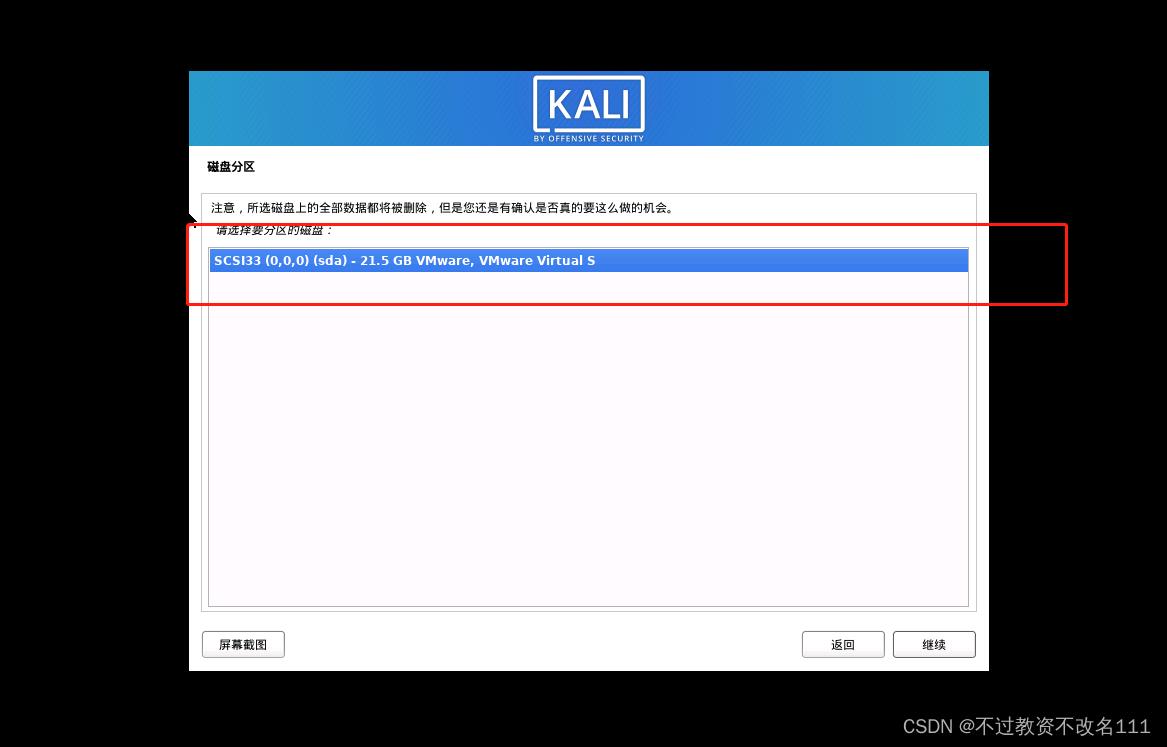

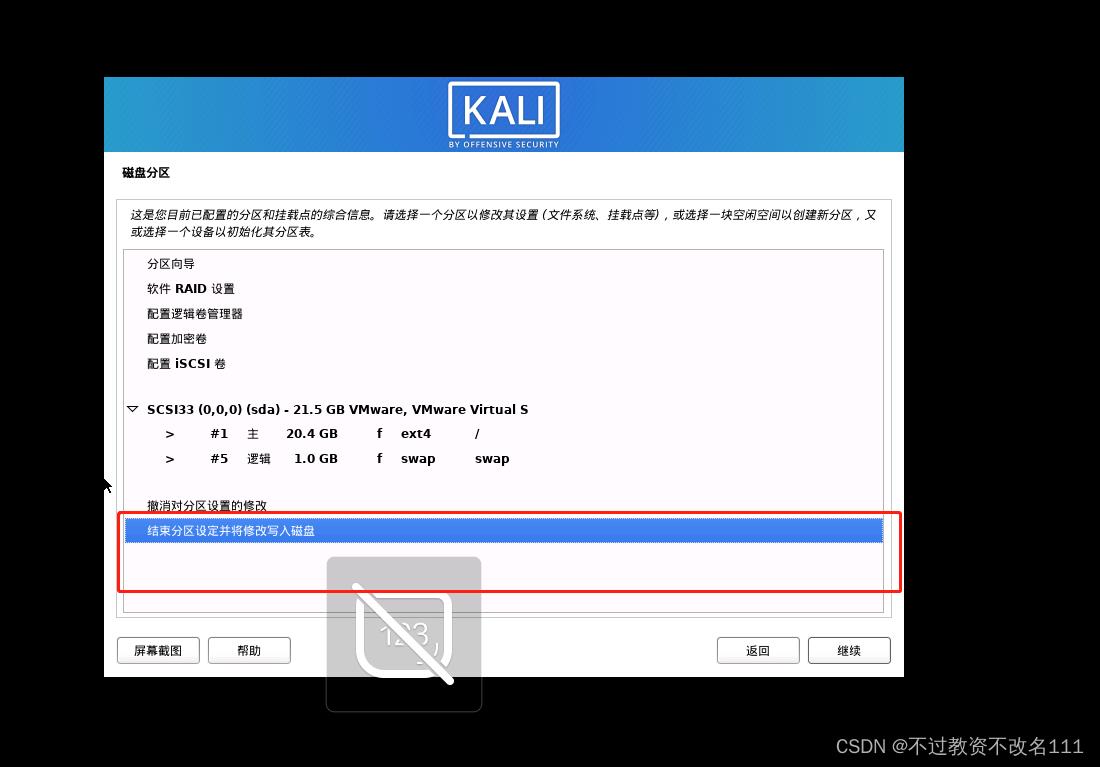 32、选择”是“
32、选择”是“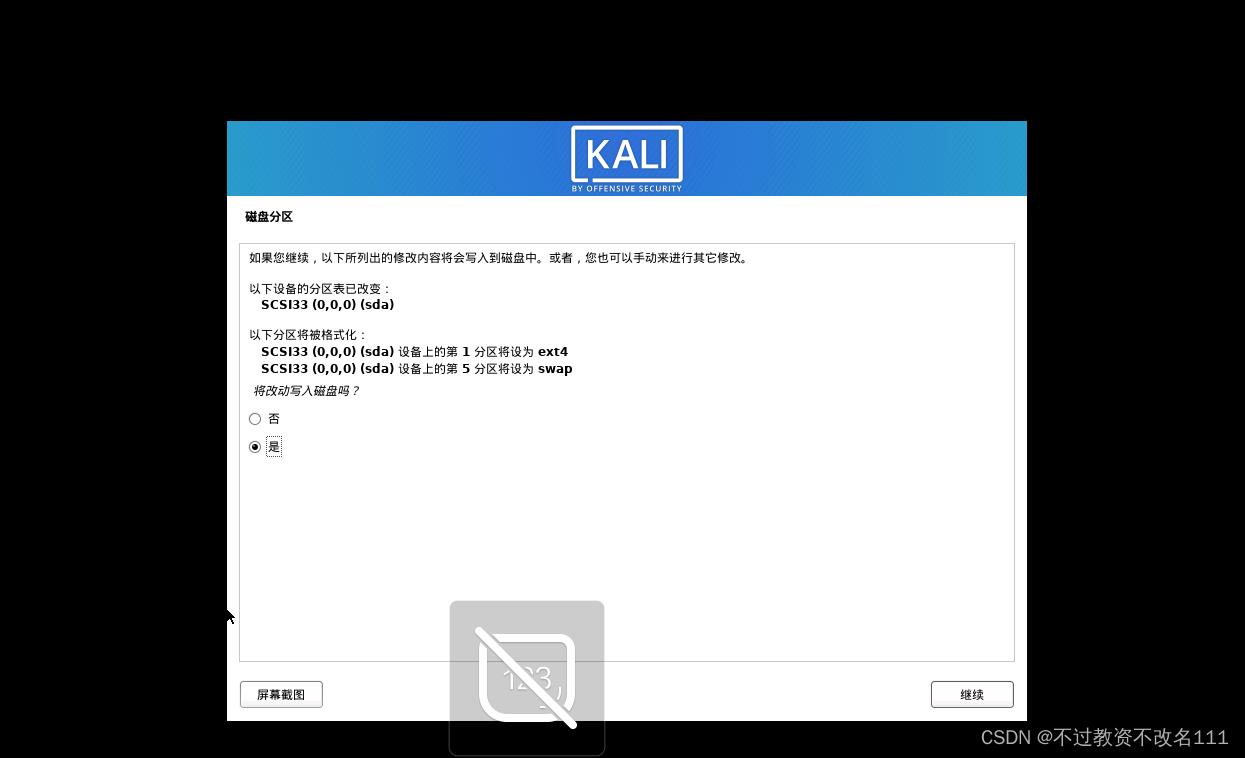
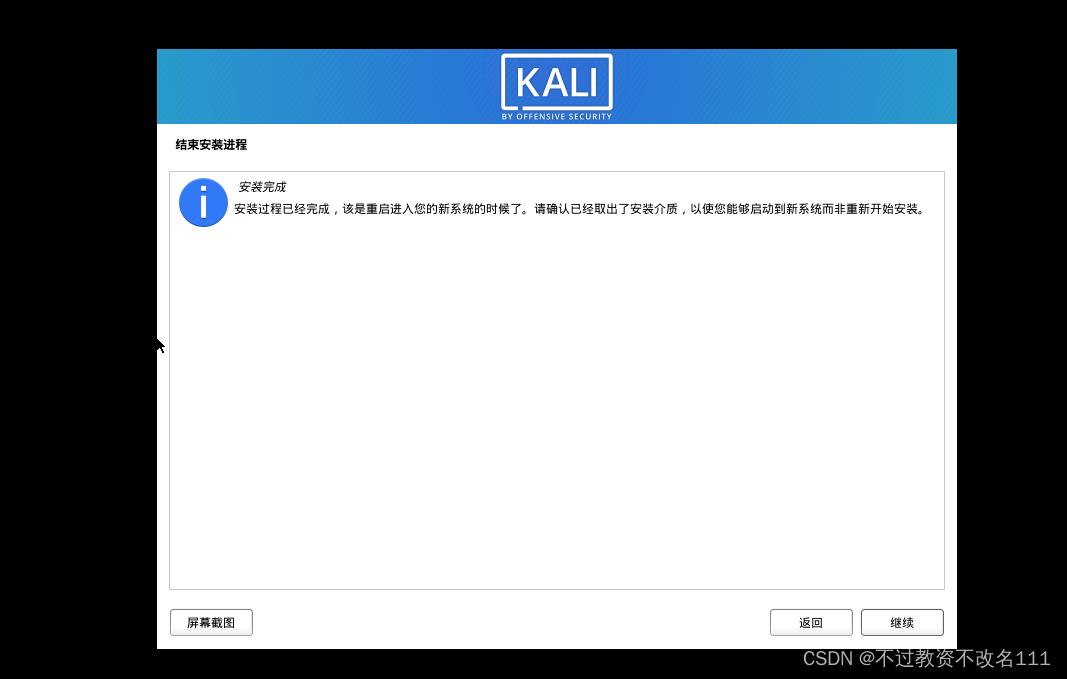
 35、稍等一小会
35、稍等一小会



 繁华落尽and曲终人散
繁华落尽and曲终人散 

好了,废话不多说,学习代码就是要学以致用的。不能写了一遍代码就让代码吃灰。下面就跟我一起来搞吧。
小草网站是个好网站,我们这次实战的结果,是要把“达盖尔旗帜”里面的帖子爬取下来,将帖子的图片保存到本地,同时将帖子的一些相关信息,写入到本地的MongoDB中。这么乍一听,感觉我们做的事情好像挺多的,别慌,我带你慢慢的一步一步来搞起,问题不是很大。

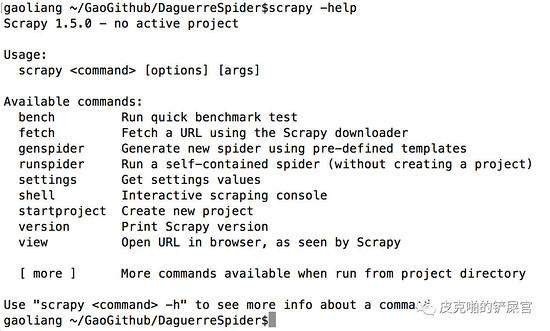
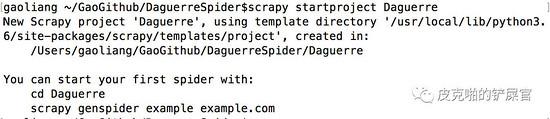
看到,创建scrapy的工程的命令是 $ scrapy startproject <name> 创建完的结果如下:
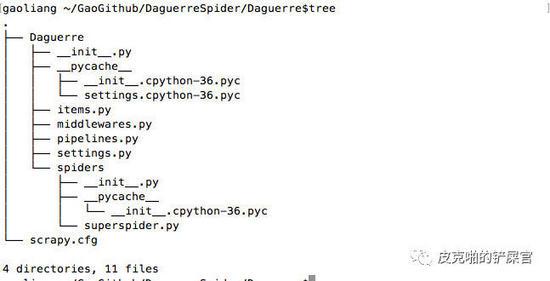
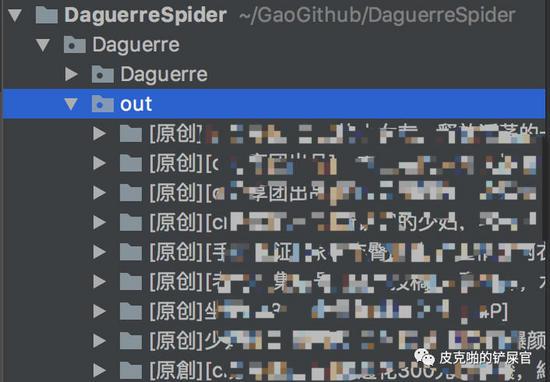
OK,这个时候,我们的目录内容变成了如下结构:

下一步就是创建我们的爬虫,还是依靠Scrapy本身自带的命令来创建。输入Scrapy自带四种爬虫模板: basic , crawl , csvfeed 和 xmlfeed 四种。我们这里选择basic。
$ scrapy genspider --template=basic superspider bc.ghuws.men创建成功,会出现以下提示:

这时候我们的工程目录就变成了这个样子:
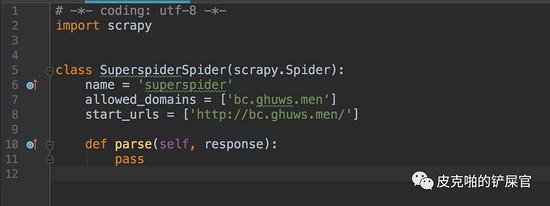
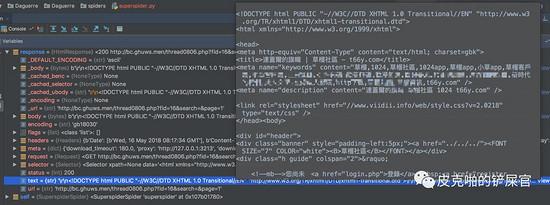
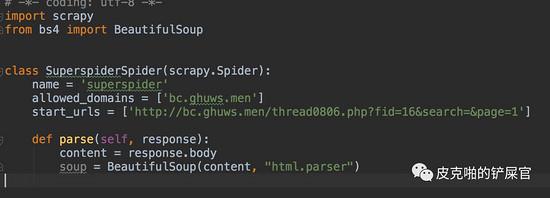
看到我们的工程里面多了一个spiders文件夹,里面有一个 superspider.py 文件,这个就是我们这次程序的主角。我们来看,这个可爱的小虫子刚生下来是长这个样子的:


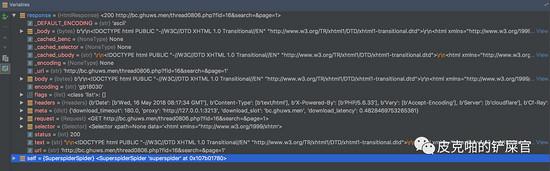


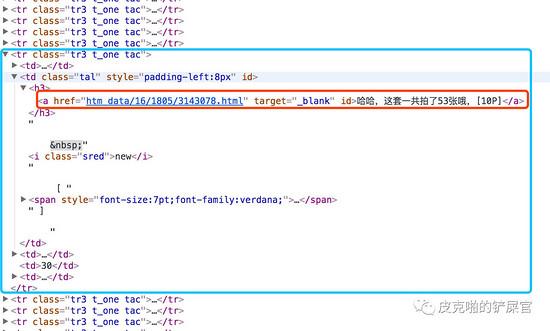
目前网页已经解析好了,下一步就是要在html文件中,找到每一个帖子的信息。我们回头来看html文件的源码,可以看到,每一个帖子其实都是在一个 <tr> tag里面,其实我们需要的东西,就是下图红色框框里面圈的 <a> tag。

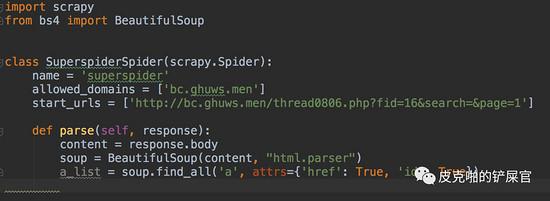
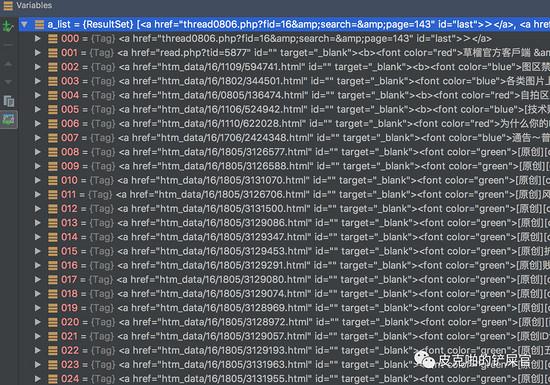

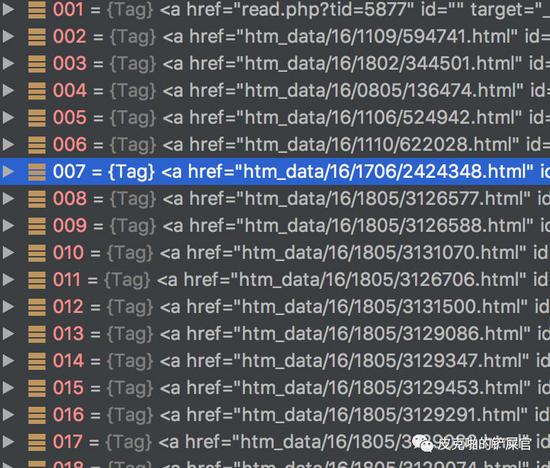
第二个数字“1805”,应该就是“年份+月份”。如果不信,则可以跳到比如论坛100页,看到的是16年3月份的帖子,这里面随便检查一个连接的href值,是“1603”。这就印证了我们的想法是正确的。好,按照这个筛选18年的帖子的思路,我们来筛选一下 a_list 。
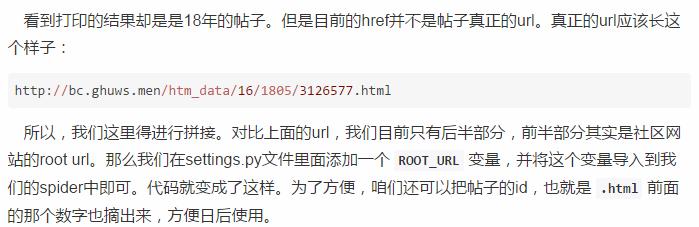
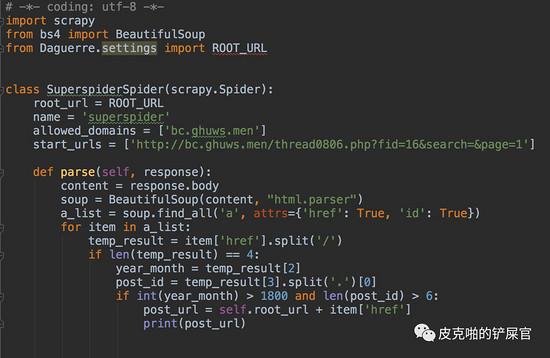
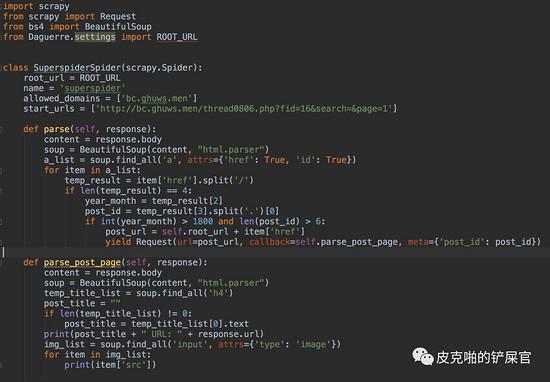
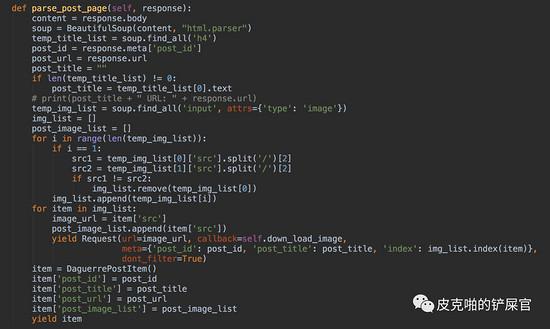
目前为止,我们拿到了帖子的id和帖子的url。我们的最终目的是要下载图片,所以,我们得让爬虫去按照帖子的url去爬取他们。爬虫需要进入第二层。这里,我们需要使用 yield函数,调用scrapy.Request 方法,传入一个callback,在callback中做解析。
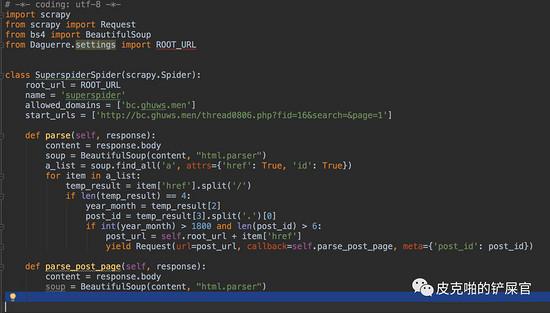
现在我们已经进入了每一个帖子的内部,我们现在还没有拿到的信息有帖子的标题和帖子的图片。还是和parse()的步骤一样,这个时候,我们就该分析帖子的html文件了。
我们先找标题。看到html文件中,标题对应的是一个 <h4> 标签。
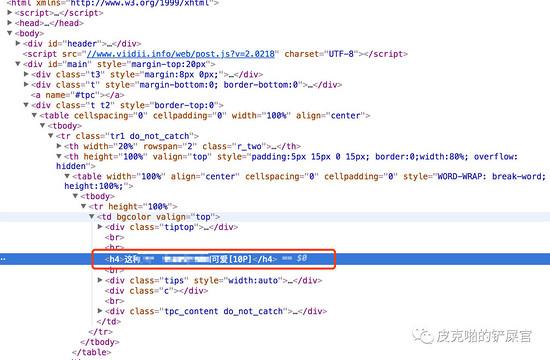
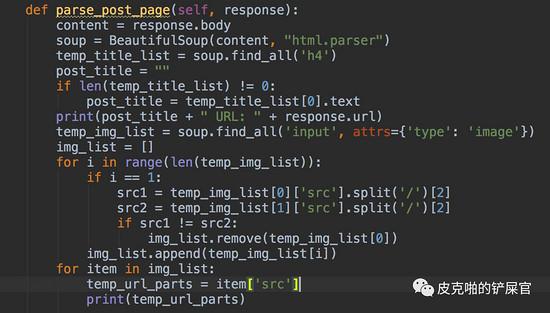
那这就简单了,我们只需要找到所有的 <h4> 标签,然后看标题是第几个就好。接下来是图片了。每个帖子用的图床都不一样,所以图片部分,我们先来看一下结构:
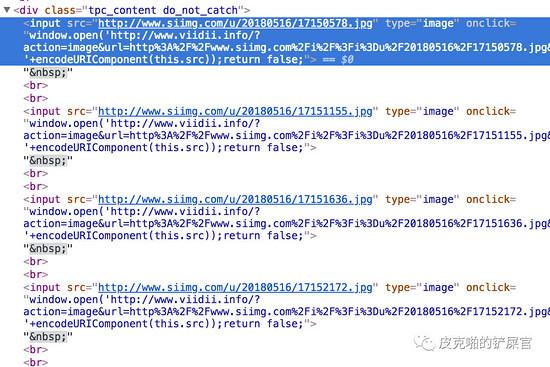
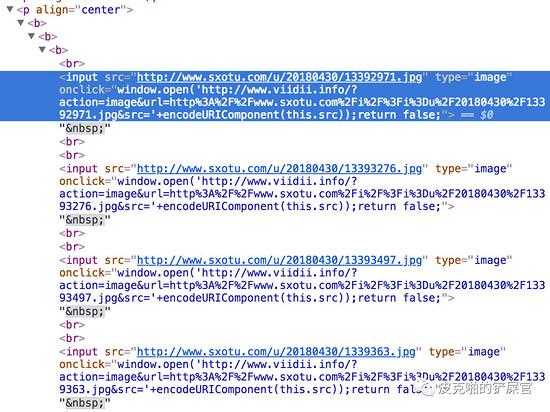
大概就是这两种,我们看到,图片的标签是 <input> ,关键点就在 type=image 上面,所以我们尝试着看看能不能根据这个来找到图片的地址。
我们简单测试一下,看看运行效果:
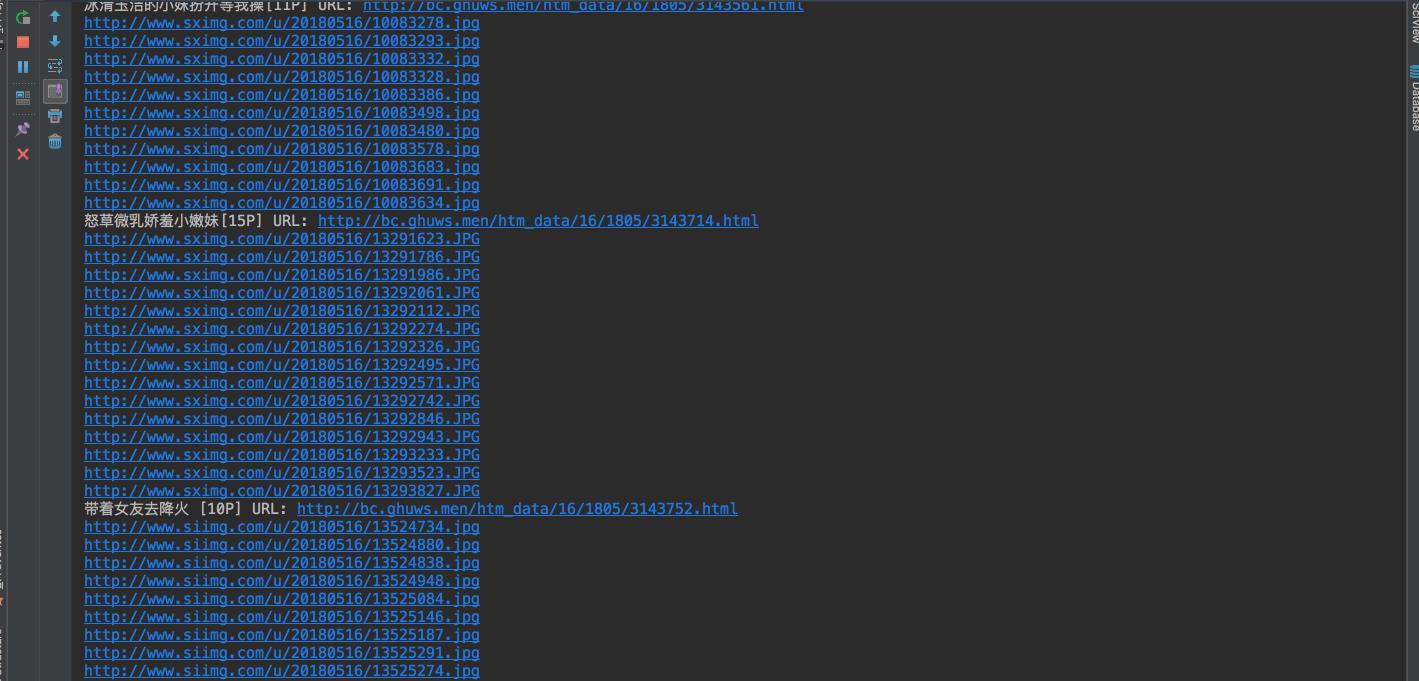
完全没有问题,看着好爽。这时候,我们看结果,会发现,我们抓取到的image,会有一两个的图床是不一样的。
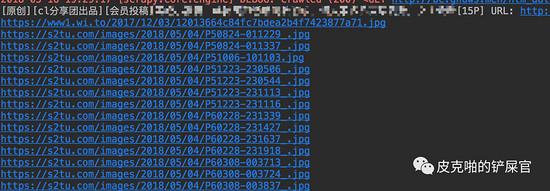
打开也会看到这个图片,里面的内容也和其他的图片不一样,并且这个图片不是我们想要的。所以,这里我们得做一下过滤。我这里的方法就是要从找到的 image_list 里面,把少数图床不一样的图片url给过滤掉。一般看来,都是找到的第一个图片不是我们想要的,所以我们这里只是判断一下第一个和第二个是否一样就可以。
这样打印出来的结果就没有问题喽。
哈哈,现在我们已经拿到了帖子的id,标题,帖子的url地址,还有帖子里面图片的url地址。离我们的目标又近了一步。我之前说过,我们的目标是要把每张图片都保存在本地,目前我们只是拿到了每张图片的url。所以,我们需要把图片都下载下载下来。
其实,当拿到图片的URL进行访问的时候,通过http返回的数据,虽然是字符串的格式,但是只要将这些字符串保存成指定的图片格式,我们在本地就可以按照图片的解析来打开。这里,我们拿到帖子的 image_list ,就可以在yield出一层请求,这就是爬虫的第三层爬取了。
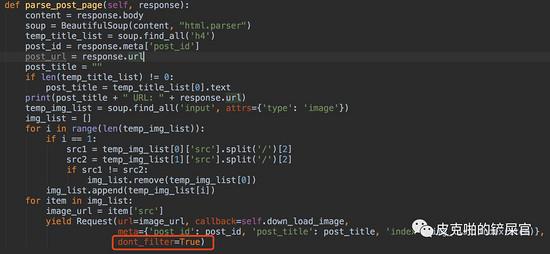
同时,在第三层爬虫里面,我们还需要将访问回来的图片保存到本地目录。那么代码就长这个样子:
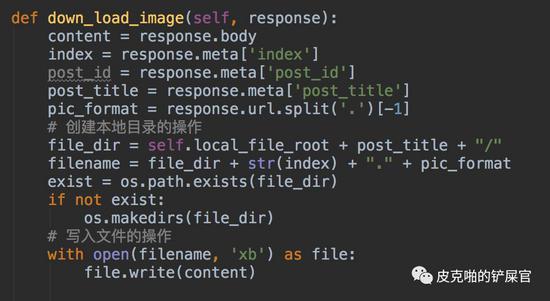
在上面第二次爬取函数的最后,有个地方需要注意一下,就是上图中红色框框圈出来的地方。这里需要加上 dont_filter=True 。否则就会被Scrapy给过滤掉。因为图床的地址,并未在我们刚开始的 allow_domain 里面。加上这个就可以正常访问了。
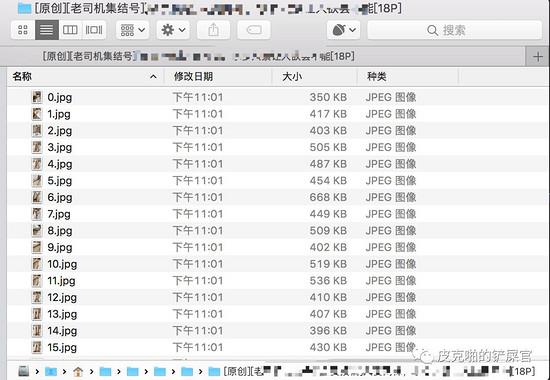
这样运行一遍,我们的本地目录里面就会有保存好的下载照片了。
我们还有个问题,就是我们需要将每个帖子的信息( id,title,url, 和 image )都保存到本地的数据库中。这个该怎么做?
别慌,这个其实很简单。
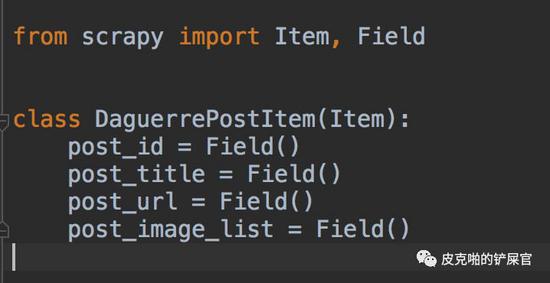
首先,我们得针对每个帖子,建立一个Scrapy的item。需要在items.py里面编写代码:
写好之后,我们需要在爬虫里面引入这个类,在第二层解析函数中,构建好item,最后yield出来。这里,yield出来,会交给Scrapy的 pipeline 来处理。
yield出来的item会进入到pipeline中。但是这里有个前提,就是需要将pipeline在settings.py中设置。

pipeline中我们先打印帖子的id,看看数据能不能够传入到这里
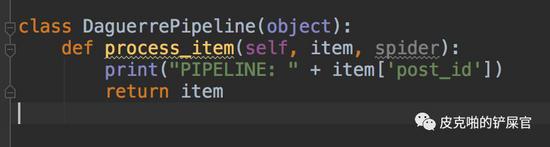
运行:
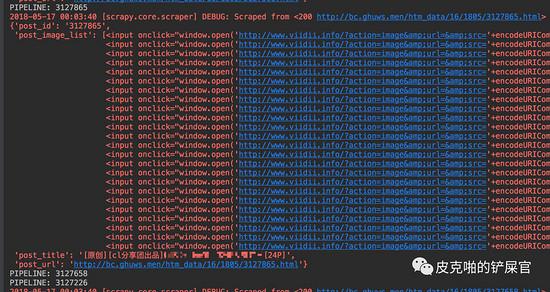
看到数据是完全可以过来的,而且在Scrapy的log中,会打印出来每一个item里面的信息。
我们如果想把数据保存到 MongoDB 中,这个操作就应该是在pipeline中完成的。Scrapy之所以简历pipeline就是为了针对每个item,如果有特殊的处理,就应该在这里完成。那么,我们应该首先导入 pymongo 库。然后,我们需要在pipeline的 __init__() 初始化进行连接数据库的操作。整体完成之后,pipeline应该长这个样子:
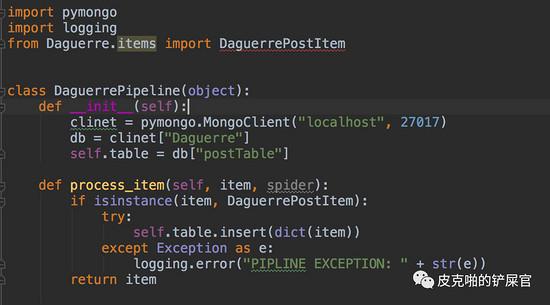
那么我们来测试一下数据是否能够存入到MongoDB中。首先,在terminal中,通过命令 $ sudo mongod 来启动MongoDB。
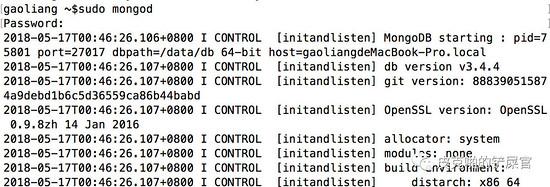
那么运行一下,看一下效果:
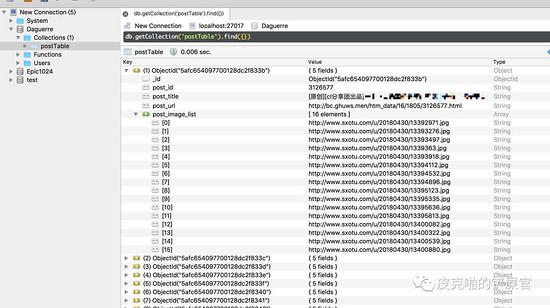
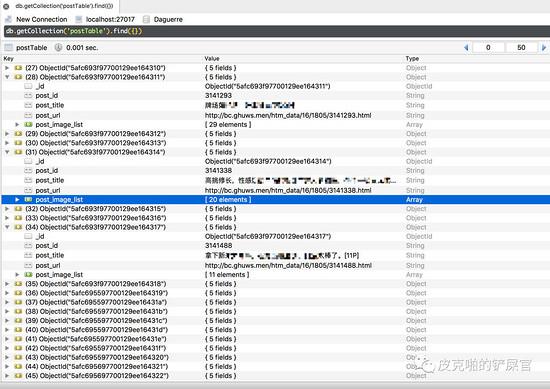
可以看到,左侧,有名为 Daguerre 的数据库,里面有名为 postTable 的表,而且我们的数据成功的写入了数据库中。数据的格式如图所展示,和我们预期的结果是一样的。
目前为止,我们完成了:从一页page中,获得所有帖子的url,然后进入每个帖子,再在帖子中,爬取每个帖子的图片,下载保存到本地,同时把帖子的信息存储到数据库中。
但是,这里你有没有发现一个问题啊?我们只爬取了第一页的数据,那如何才能爬取第二页,第三页,第N页的数据呢?
别慌,只需要简单的加几行代码即可。在我们的spider文件中的 parse() 方法地下,加一个调用自己的方法即可,只不过,传入的url得是下一页的url,所以,我们这里得拼凑出下一页的url,然后再次调用 parse() 方法即可。这里为了避免无限循环,我们设定一个最大页数 MAX_PAGES为3,即爬取前三页的数据。
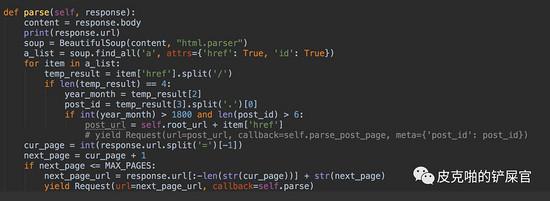
OK,这样就完事儿了,这个达盖尔旗帜的爬虫就写好了。我们运行一下瞅瞅效果:
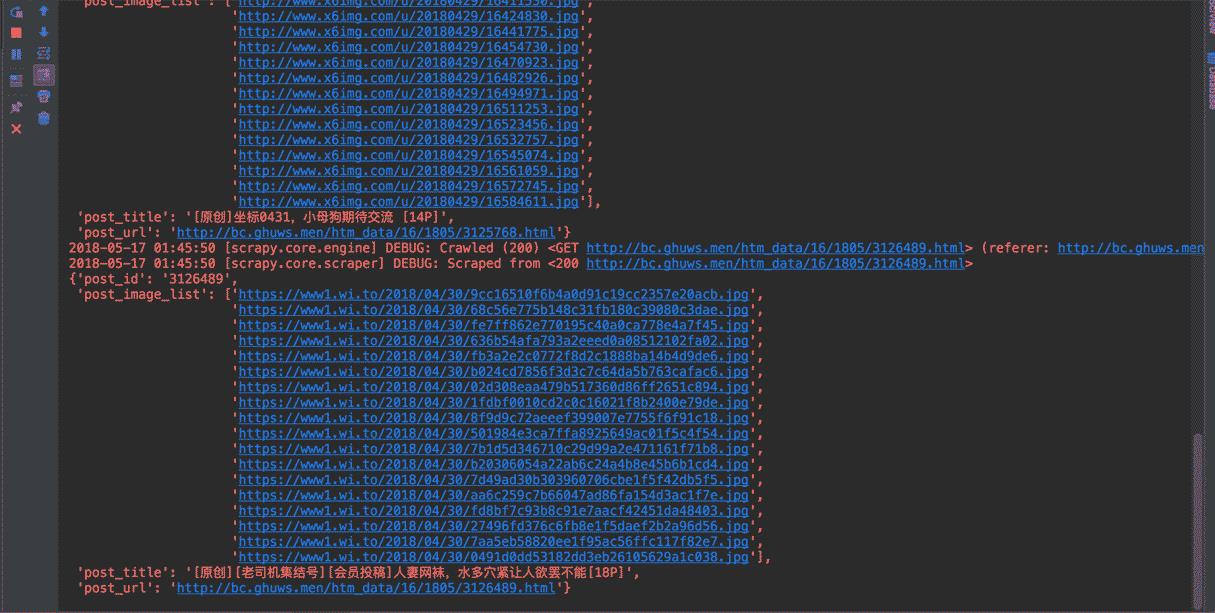
是不是非常的酷炫?再来看看我们的运行结果:
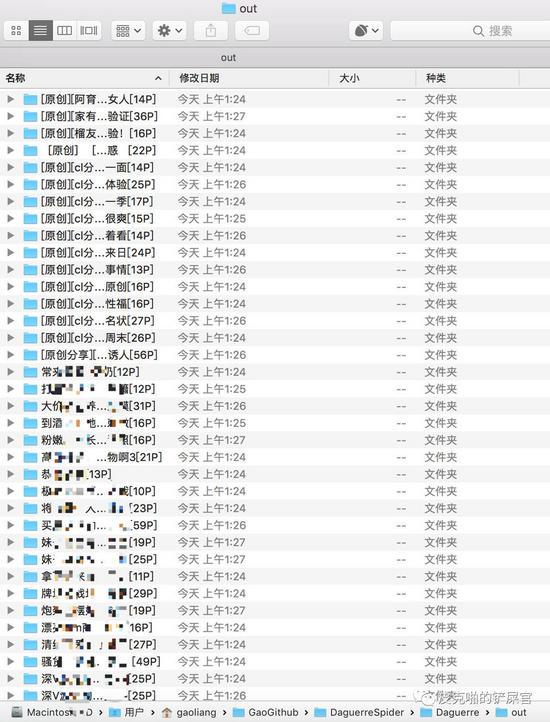
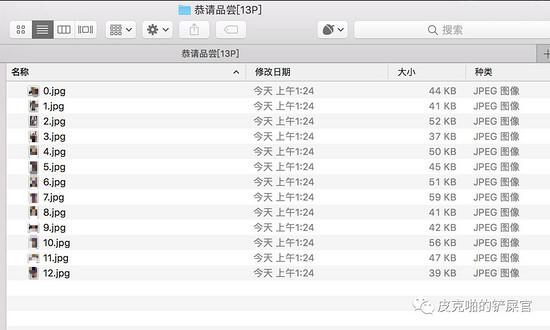
只能说,战果累累,有图有真相。
其实,这个程序,可以加入middleware,为http请求提供一些Cookie和User-Agents来防止被网站封。同时,在settings.py文件中,我们也可以设置一下 DOWNLOAD_DELAY来降低一下单个的访问速度,和 CONCURRENT_REQUESTS 来提升一下访问速度。


就像之前EpicScrapy1024项目里面一样。喜欢的同学,可以去借鉴那个项目代码,然后融会贯通,自成一派,爬遍天下网站,无敌是多么的寂8 寞~~~~
好啦,能看到这里说明少年你很用心,很辛苦,是一个可塑之才。
废话不说,看到这里是有奖励的。关注“ 皮克啪的铲屎官 ”,回复“ 达盖尔 ”,即可获得项目源码和说明文档。同时,可以在下面的菜单中,找到“ Python实战 ”按钮,能够查看以往文章,篇篇都非常精彩的哦~
扯扯皮,我觉得学习编程最大的动力就是爱好,其实干什么事情都是。爱好能够提供无线的动力,让人元气满满的往前冲刺。代码就是要方便作者,方便大家。写出来的代码要有用处,而且不要吃灰。这样的代码才是好代码。欢迎大家关注我的公众号,“皮克啪的铲屎官”,之后我会退出Python数据分析的内容,可能会结合量化交易之类的东西。
最后,来贴一张达盖尔的图片,纪念一下这位为人类做出杰出贡献的人。

欢迎大家关注我的博客:https://home.cnblogs.com/u/sm123456/