Vancouver Machine Learning 2019 参会记录
Posted sgyzetrov
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Vancouver Machine Learning 2019 参会记录相关的知识,希望对你有一定的参考价值。

VanML 2019 参会记录
紧接着 NeurIPS 2019 会议后面,就是 Vancouver Machine Learning: Genomics 会议。其实本次算是我第一次参加学术会议,
本科的时候也有一次机会,当时 Nature 的子会议 Agricultural Genomics 2017 在我农的作物遗传改良国家重点实验室开,我是可以去听的(如果我想的话),
但最后还是没有成行。大概是因为当时忙于准备数学建模竞赛,这两件事正好一前一后,所以国赛已结束我直接累的不想干任何事了。
言归正传,这个会议还是非常专业项的,而且是纯研讨性质。小而精的感觉。我学到了不少领域内别的大牛都在做什么方向,用了什么方法。收获颇多吧(而且吃的是真的不错 ԅ(¯﹃¯ԅ))
行程
15 日中午到达港口,乘渡轮到达温哥华。
去码头沿途风景

到达 Terminal
渡轮

途中
海上风景

到达温哥华

晚上真冷啊,街上都没几个人

正式会议

First session
Dr. Jennifer Listgarten, Professor in the Electrical Engineering and Computer Sciences department and the Center for Computational Biology at Berkeley.
Theme: Machine Learning in protein detection.
Major Problems and Objectives
- Protein we want to search
- Problem: massive search space, 10L space, and when L ~ 50 the amount is close to atoms in outer space. And yet, L gets larger.
- Protein we want to refine, e.g.
- Carbon fixation (RuBisCo)
- gene therapy virus-delivery
- genetic scissors (CRISPR)
- Similar story for small molecules for drug desig(Cnopyright © https://blog.csdn.net/s_gy_zetrov. All Rights Reserved)
How exactly do we do protein design/optimization?
Traditionally, we use lab-based measurement, introducing Frances Arnold, winner of the Nobel Prize in Chemistry 2018. The process is as follows:
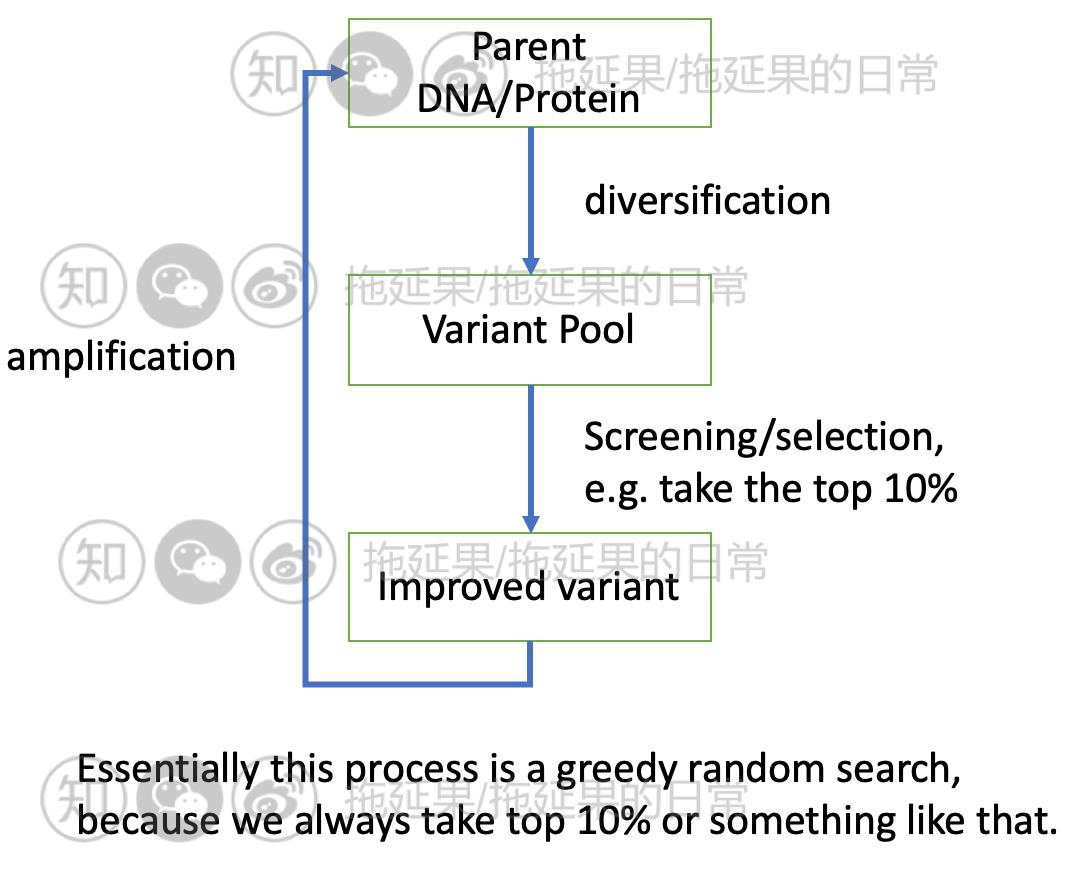
We can use machine learning to improve this greedy random search!
- Replace lab measurement with predictive model
- Replace random greedy search with intelligence search
A normal predictive model (a.k.a stochastic oracle):
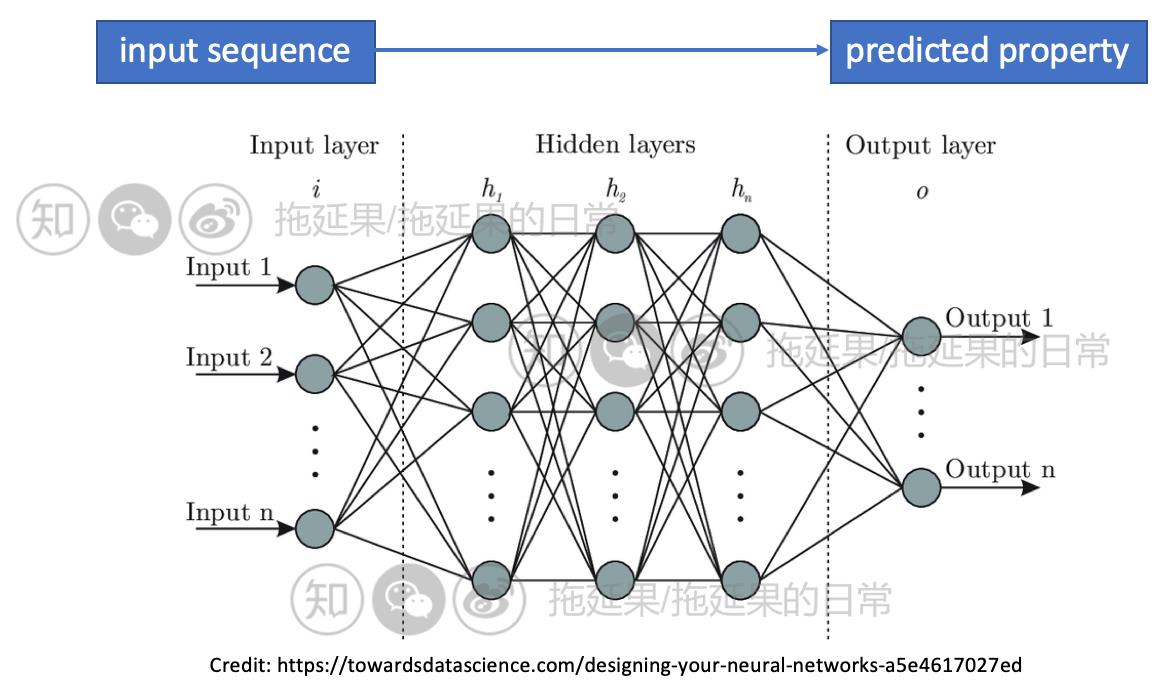
Assumptions: ”Black Box” oracle (given the ability to predict a property from a sequence), we want a method that will tell you what sequence to choose to either maximum or specify the property. (Copyright © https://blog.csdn.net/s_gy_zetrov. All Rights Reserved)
Introducing solution based on model-based optimization (MBO)
Related paper:

https://arxiv.org/pdf/1905.10474.pdf
We replace search over x with search over 𝜃 in P(x|𝜃).

Advantages:
- Model can sample broad areas of sequence space
- Does not require gradients of f
- Can incorporate uncertainty(Copyright © https://blog.csdn.net/s_gy_zetrov. All Rights Reserved)
- Provide set of candidate solutions, not just one
- Search is now augmented into the language of probability
Detail algorithmic solutions:
- sampling from “search model” P(x|𝜃)
- Evaluate samples on f(x)
- Adjust 𝜃t+1 <- 𝜃t s.t. the generative model favors sequences with large value for f(x)
Based on MBO, introducing Design by adaptive sampling (DbAS)
Related paper:

https://arxiv.org/pdf/1810.03714.pdf
This method aims to solve the MBO Objective:
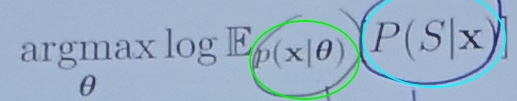
The gree circle can be solved using Estimation of Distribution Algorithms (EDAs), which is a widely-used approach to solving the MBO objective. And one important aspect of any EDA is to choose search model. In this scenario, we can choose Variational Autoencoder (VAE), Hidden Markov model (HMM), etc.(Copyright © https://blog.csdn.net/s_gy_zetrov. All Rights Reserved)
In the blue circle, S is the desired set of property values (e.g. fluorescence > α)
The blue circle is known as the stochastic predictive model (“Oracle”) that maps input sequence to set of property values (e.g. CDF).
DbAS is intimately related to EDAs:

Problems of this all
We just assumes oracle is unbiased and has good uncertainty estimates. There is “black holes” in these models (Neural Networks), for example: adversarial noise made image misclassified.
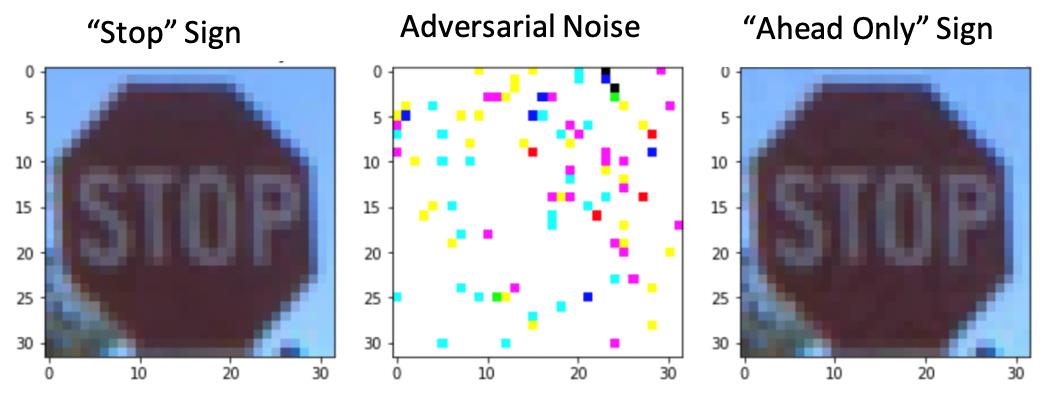
Credit: https://www.ibm.com/developerworks/community/blogs/Analytics4Gov/entry/Adversarial_Robustness_Toolbox_How_IBM_protects_your_Neural_Network_against_adversarial_attacks?lang=en
(Copyright © https://blog.csdn.net/s_gy_zetrov. All Rights Reserved)
So, in fact, models are not intelligent at all! Just works on some problem better!
Second session

Dr. Sharon Browning, Professor in the Department of Biostatistics at the University of Washington. Co-developed the popular BEAGLE software in collaboration with Dr. Brian Browning. Recent work includes investigations of the contribution of archaic humans to current-day human genomics, and extensions to the BEAGLE software involving identity-by-descent.
Finding Identity by Descent (IBD) segment in population samples
Tested on the UK Biobank dataset (500K individuals)
(Copyright © https://blog.csdn.net/s_gy_zetrov. All Rights Reserved)
Identity by Descent (IBD): segments of DNA that descents share with one ancestor.
Related paper:

https://www.biorxiv.org/content/10.1101/2019.12.12.874685v1
The smaller the population, the more IBD
(Copyright © https://blog.csdn.net/s_gy_zetrov. All Rights Reserved)
Third session
Dr. David Aanensen, the Director of the Centre for Genomic Pathogen Surveillance at the Wellcome Sanger Institute, Senior Group Leader in Genomic Surveillance at the Big Data Institute at the University of Oxford, the Director of the NIHR funded Global Health Research Unit on Genomic Surveillance of Antimicrobial Resistance.
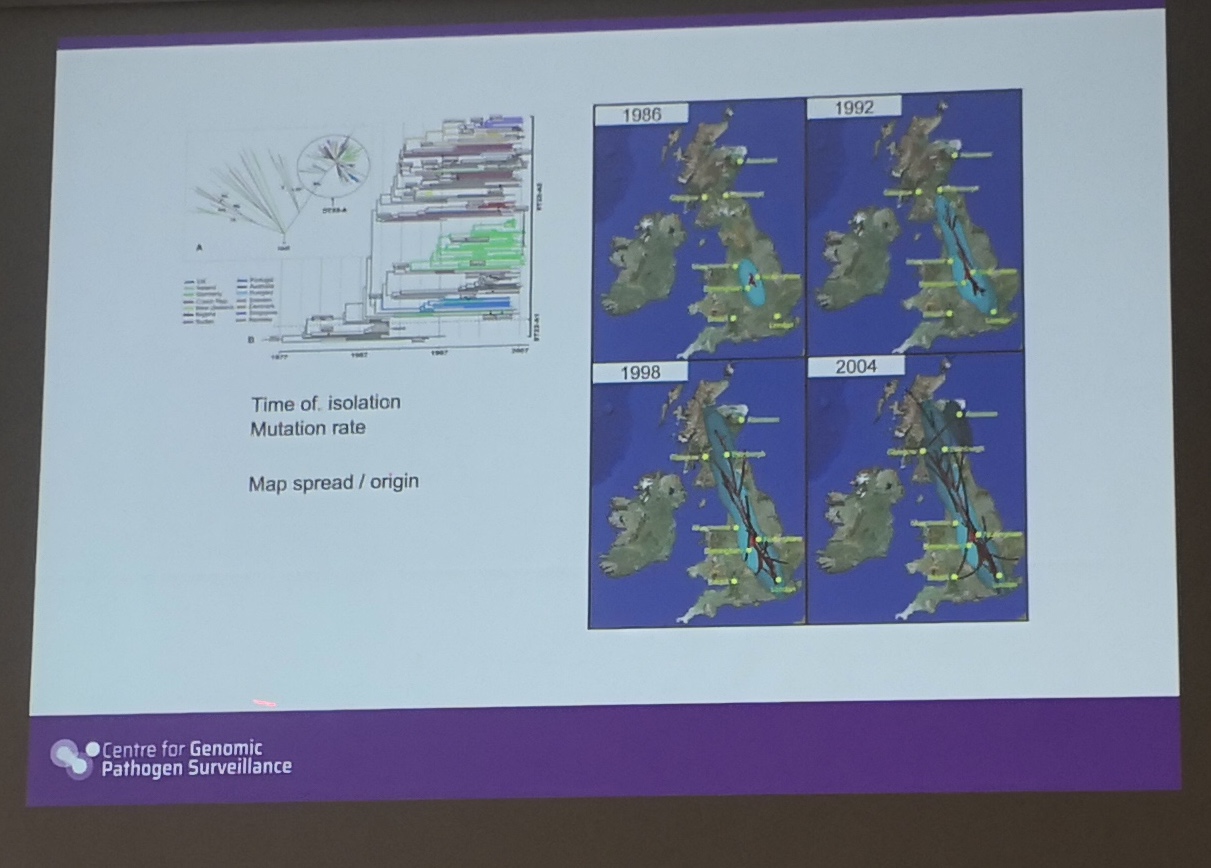
Online platform for visualizing and identifying pathogen
Example of disease outbreak: note that trees shape were similar, first there are some branches then there is an outbreak.
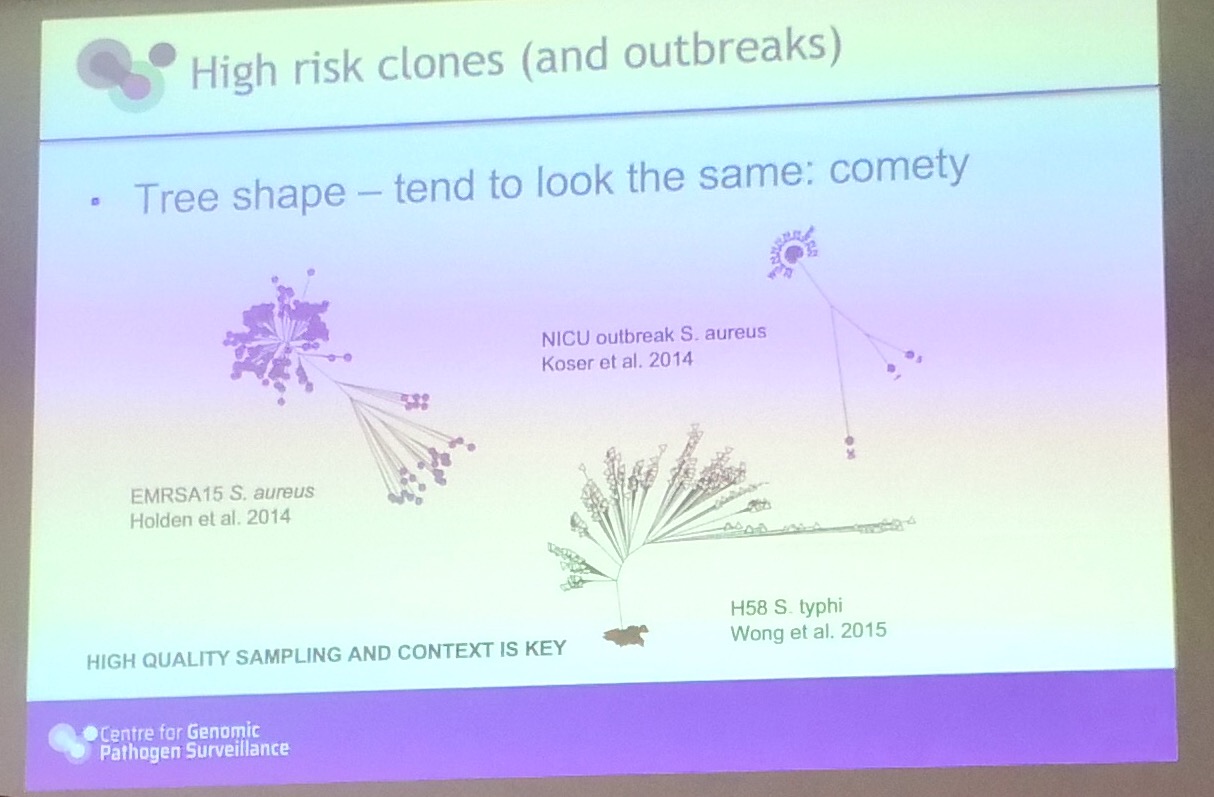
Online platform

https://microreact.org/showcase
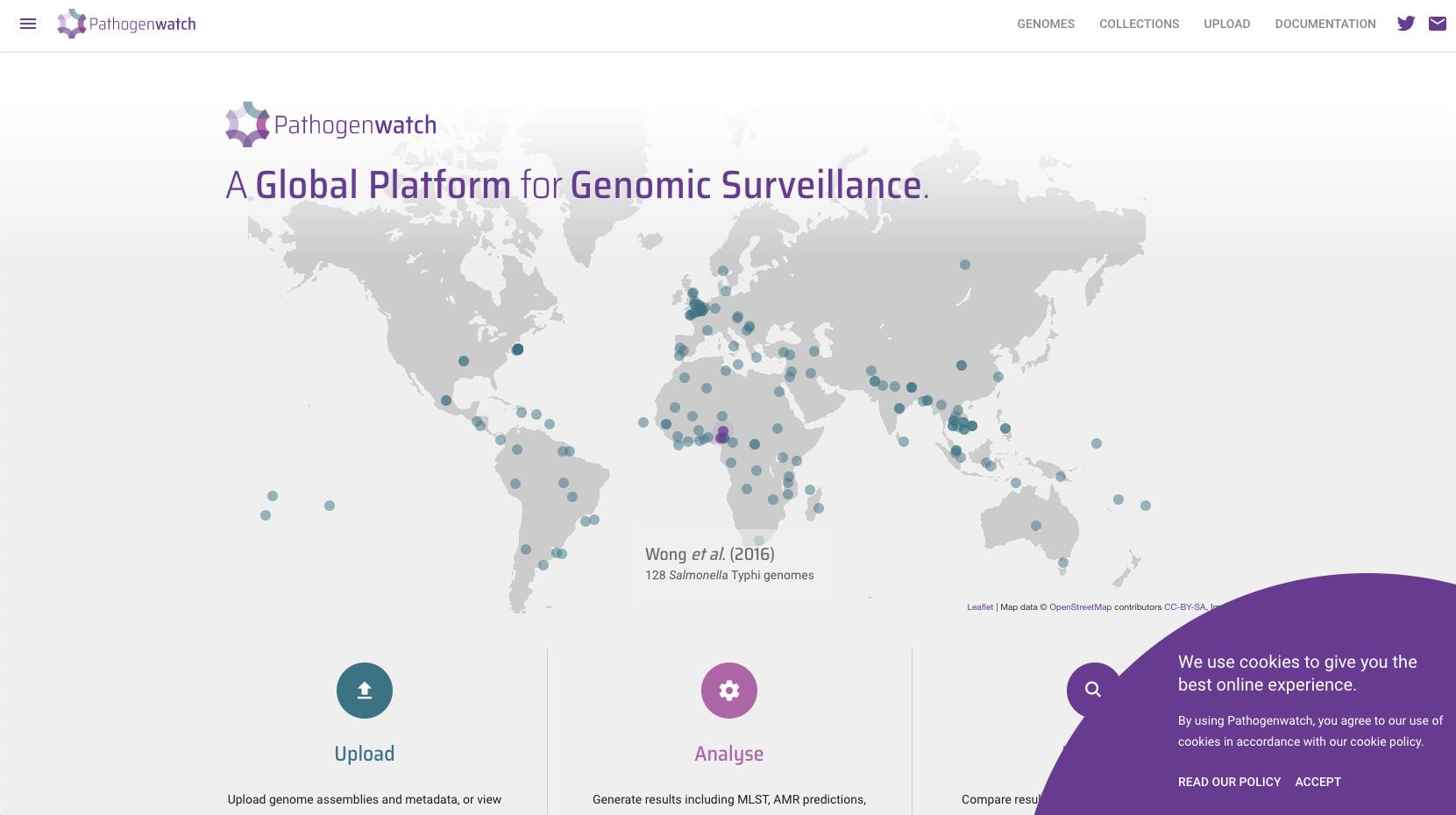
https://pathogen.watch/
Forth session
(Copyright © https://blog.csdn.net/s_gy_zetrov. All Rights Reserved)
Dr. Alexander Bouchard-Côté, Professor of Statistics at the University of British Columbia. Research focuses are computational statistics and machine learning, with applications to linguistics and biology.
Bayesian method to reconstruct single cell phylogenetic trees from copy number events such as those that arise in cancers with high genomic instability
The method is motivated by low-depth genome-wide data which can be obtained for increasingly large numbers of cells thanks to technologies such as Direct Library Preparation or 10x Single Cell Genomics. Computing the posterior distribution in this model at scale is challenging. Recent advances in the field of Bayesian computational statistics can be used to parallelize the posterior inference computation to an arbitrary number of cores, touching on topics such as non-reversible methods and change of measure approaches. The posterior inference methods described are available through an open source Bayesian modelling language called Blang, which can be used for a range of phylogenetic problems including more traditional phylogenetic models, as well as other Bayesian analysis problems. The motivating copy-number-based phylogenetic model is implemented in Blang and available in a cancer Bayesian phylogenetics and population genetics library which are actively developing. This library has been used to infer phylogenetic trees on over 4000 cells using over 60 cores.
https://www.stat.ubc.ca/~bouchard/blang/

(Copyright © https://blog.csdn.net/s_gy_zetrov. All Rights Reserved)
visitor tracker
以上是关于Vancouver Machine Learning 2019 参会记录的主要内容,如果未能解决你的问题,请参考以下文章