美团一面阿里一面复盘总结
Posted Dreamchaser追梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了美团一面阿里一面复盘总结相关的知识,希望对你有一定的参考价值。
文章目录
前言
美团一面3月22日,阿里一面是在3月24日。
这两面的面试官风格截然不同,美团一面主要想看我基础知识到底扎不扎实,并不会继续进行深层次的追问,觉得我原理掌握的差不多就直接跳到另一个问题。而阿里一面给我的感觉就是思路很跳脱,面试官会不断根据我说的追问下去,而且问题往往不是那种标准的问法。
相对而言,我美团一面表现的还不错,问题基本都答上来了,而且做了很多延伸,很多时候都是面试官打断我说可以了。而阿里面试官不会听我太多bb(hh,因为我回答问题都是根据我自己的理解然后用口语化的表达出来的,所以能讲很长时间),往往会在我提到一个点的时候打断我根据这个点不断深入下去。
美团一面面了一个小时,阿里一面面了一个半小时,因为也没太多相关面试经历,我也不知道面试官问我的这些是不是普遍的难度。
PS:本人23届双非本,找暑期实习
一、面试内容
先放面试内容
美团一面
自我介绍
平时的学习方法
jvm内存区域和垃圾回收
CMS垃圾回收器回收流程
Spring IOC,对象初始化(生命周期)
项目是否用到了分布式
redis 数据类型
redis 持久化方式
redis 部署方式
线程使用
线程池原理
mysql 聚簇索引和非聚簇索引
B+树原理,如何实现数据存储和查找
主键自增和自定义
如何处理慢sql
问了一些竞赛内容
编程题——40亿个数里寻找未出现的整数(说思路即可)
有什么问题想问吗?
PS:整体而言,中规中矩吧,问的都是常见面试题,问法也很标准
阿里一面
自我介绍
Java内存模型(自由发挥)
高速缓存在哪(介绍硬件时被打断,追问了高速缓存)
为什么要提出CAS,如何实现变更高速缓存时的同步(其实就是问高速缓存的具体步骤)
CAS具体步骤
CAS为什么要compare的过程
CAS的ABA问题(自己延伸的)
有哪几种线程池类型?
ThreadPoolExcutor参数
有界队列和无界队列的场景
hashmap 1.7和1.8的区别
hashmap导致死循环的bug在什么场景下产生?
mysql insert buffer(change buffer)有什么用?
double write(双写)是干什么的?
mysql为什么要写日志,为什么不直接写进数据? 你不觉得保存数据那一刻数据库宕机了,也没写到硬盘里啊。
四个commit知道吗?(七绕八绕原来是问事务隔离级别,后面也问了默认的隔离级别)
事务隔离级别原理(MVCC)
mysql里面的索引(说了一点紧接着又提问下一个问题)
B+树和B树有什么区别?
mysql中联合索引是怎么搜索的?
为什么我查中间字段联合索引就没用了
场景题——真实场景里的一个舆情分析问题,他们自己也在做(100w+文本 5-100字 每小时产生20W+数据 有相似度(可以使用标签,地点,时间(24小时)) 要求对数据进行去重)
算法题——字符串里寻找所有“叠词”
优化一下(直接改题目…)
PS:这里回答的不好的地方就比较多了,也暴露出我的一些知识盲区,也正是阿里一面才萌生了写篇博文的念头
二、回答不好的地方
1.美团一面
1.1 CMS垃圾回收器回收流程
这个我就直接说不了解了,面试后也去整理了相关知识点

1.2 Spring的对象创建
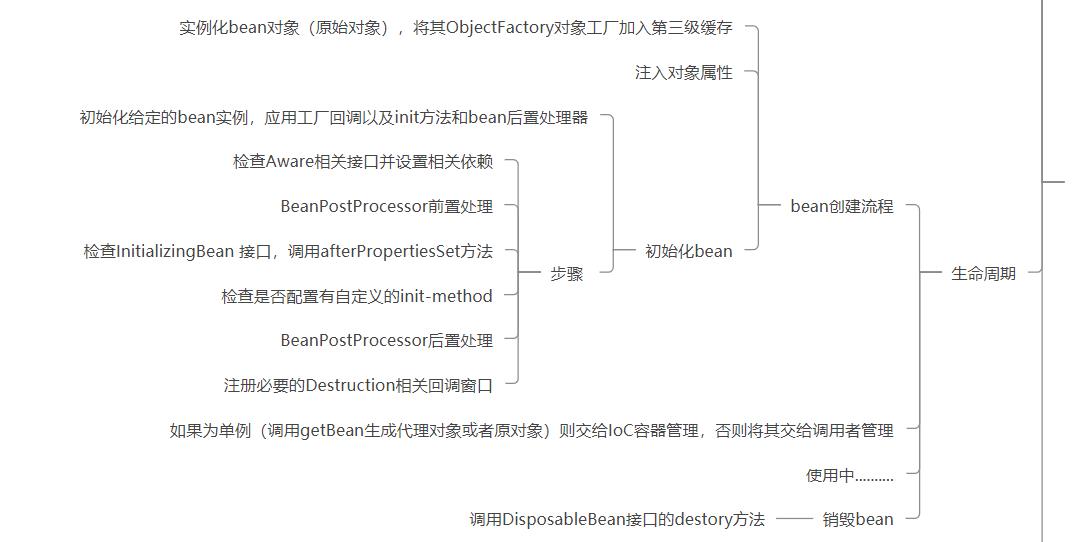
我猜测面试官应该是想问ioc的生命周期的。
对于Spring的对象创建应该回答三级缓存那套

在确认后我还是回答了生命周期,不过对于初始化bean的流程,我实在记不住,只大致回答了几个,然后说主要是spring功能上的一些初始化操作。因为确实没有相关的实践操作,而我记忆力奇差,除非能理解这些具体细节和为什么,否则我真的是记不住。
1.3 B+树原理
那时候还比较模糊,心里只有一张图,所以回答的并不是很好。
面试后我花了半个晚上去搞懂了B+树,并整理到了我的知识脑图里

2.阿里一面
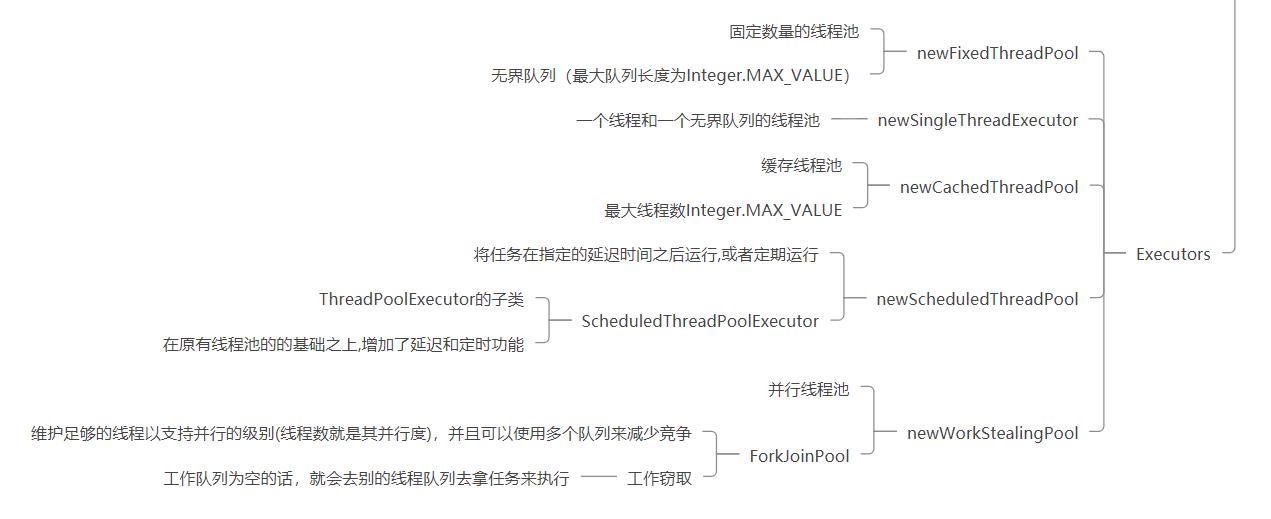
1.1 有哪几种线程池
之前知道Executors类下面有不同的方法封装了不同的线程池创建,但我知道的仅此而已,并不知道具体的,面试后去整理了下。
大多数也是对于ThreadExecutorPool的封装。
1.2 hashmap导致死循环的bug在什么场景下产生?
额,属实不知,跟面试官说没遇到过这个bug。
后面我也去查阅很多博文,并用我理解的话更新进我的知识脑图中

1.3 mysql insert buffer(change buffer)有什么用?
这个我确确实实是不知道的,只能怪自己太菜了。因此恶补了一波数据库,查阅了好多好多博文。
当时面试官问我的时候,我确实不知道insert buffer ,但是听这个名字有点像数据库缓存的味道,便反问了面试官是不是数据库缓存。
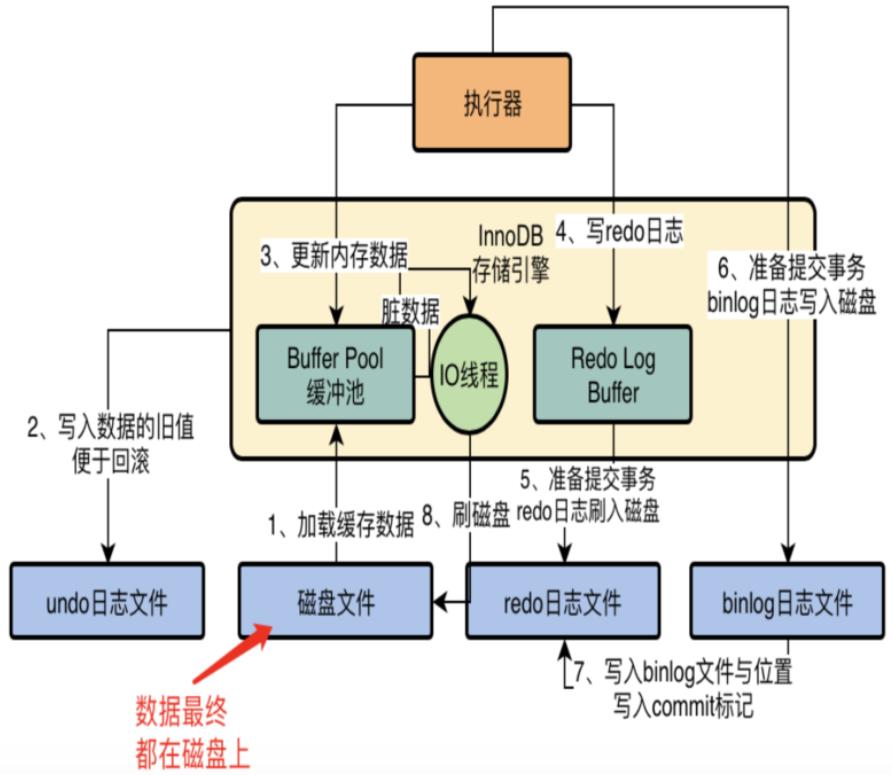
其实这两者差别很大,但也确实功能上有一些类似,主要都是利用缓存来加快读写效率,不过insert buffer是在引擎层面用来防止过多的随机io而设置的,而数据库缓存(query cache)是在Server层,用于减少重复的数据库查找(8版本因为太鸡肋而移除)
总结来说,insert buffer 在buffer pool中,主要是通过类似高速缓存的思路来降低磁盘io次数,将非唯一索引的更新放在内存(insert buffer对象),再在合适时机取出对应索引页进行合并,同时再找合适时机写入磁盘,此时就将随机写变为数据页刷入的顺序写,这点对于机械硬盘来说,效果尤为明显。
在各种文章,Mysql buffer pool详解 - 奕锋博客 - 博客园 (cnblogs.com)这篇讲的非常好。

查阅很多文章后,最终将其整理了下来。


从这里也纠正一下我对redo log的理解,之前一直以为它是起到的是一个事务和加快写效率的作用。我有时也确实会疑惑一点——当过多redo log积压(在极客时间中MySQL实战45讲中提到最大会有4G),如此大的数据量,那真实存储时的数据不是要落后好几个版本?那MVCC读取版本链的时候读到的数据都是多久之前的?在复习的时候确实有这种疑惑,印象里我确实也在某些文章中读到过有这种缓冲区的存在,但是始终无法融入到我的知识体系中,也就没过多在意,直到这次被面试官问懵了。
redo log确实有确保事务的能力,但他最初的作用只是保证一个crash-safe的能力,即保证数据库发生异常重启时,之前提交的记录都不会丢失。
而我其实也一直很疑惑undo log 和redo log在具体事务的写顺序和持久化方式。
最终通过查阅各种文章发现,undo log是在事务之前,在具体更新之前操作的,redo log是在之后记录的,而更有意思的一点是——在mysql看来 undo log也是数据,在undo log生成时,也会生成一条额外的redo log,因此undo log本身是不做持久化的,其持久化是依赖于 redo log。
但到这里还没有结束,我依旧无法将buffer pool 和undo log、redo log联系在一起,在我的知识体系中两者是分裂的。
由此带来一些问题,比如,我会疑惑——为什么undo log需要持久化?
因为在我原先的认知中,数据没有提交之前是不会落盘的,是在内存中的,因此没必要进行落盘。
最终我在一个知乎回答中找到了答案。undo log 为什么需要落盘? - 知乎 (zhihu.com)
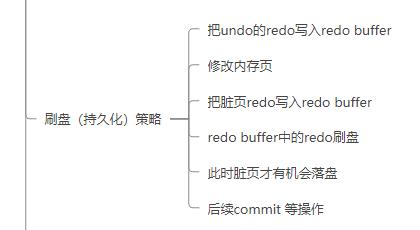
undo log持久化步骤如下:
1 把undo的redo写入redo buffer
2 修改内存页
3 把脏页redo写入redo buffer
4 redo buffer中的redo刷盘
5 此时脏页才有机会落盘
6 后续commit 等操作
所以 undo log为什么要落盘(持久化)?
- 在事务未提交之前,数据页是有可能被刷盘的,所以我们在宕机时,我需要undo log持久化来确保事务被正确回滚
- 当内存不够时,undo log会先换到磁盘中



1.4 mysql为什么要写日志,为什么不直接写进数据? 你不觉得保存数据那一刻数据库宕机了,也没写到硬盘里啊?
之前由于不知道buffer pool的存在以及对redo log的误解,所以没有回答好。
这里再回答一下,
写redo log,主要是为了保证crash-safe,即保证数据库宕机时,之前提交的记录依旧不会丢失。
在写入数据的那一刻,脏页确实没有被flush到硬盘,但是在数据修改之前,相对应的undo log和redo log都已经被顺序写入redo log 文件(除非你修改了默认的数据库redo log持久化策略,会导致丢失1s内的记录),所以在数据库恢复时,mysql会重做redo log来保证数据的正确性,最终数据并不会丢失。
1.5 四个commit知道吗?
后面才知道是read commit,read uncommitted ,这英文第一时间没反应过来是事务隔离级别,后面描述的时候事务提交的阶段(事务的几个状态),我就想歪了,以为是我不知道的某些事务提交方式,最后叫我说事务隔离级别我才反应过来。
具体我也回答了,就不多写了。
1.6 为什么我查中间字段联合索引就没用了
原理是答出来了,但是很难用语言准确表达那个意思。面试官也知道我理解就继续问下个问题了。
事后诸葛亮一波,因为联合索引是根据字段顺序排序的,所以只有前面字段相等时,后面字段排序才有意义。mysql会优先排序之前的字段,只有相等的时候才会根据后面的字段排序。(感觉和面试时候回答的差不多是怎么回事~ _ ~ !)
1.7 场景题——真实场景里的一个舆情分析问题,舆情去噪
100w+文本 5-100字(猜测是文章标题) 文本有一定相似度,“杭州发生疫情”、“原标题:杭州发生疫情”、“杭州发生疫情”是一件事。
文本里面可以提出标签,比如“杭州”,“疫情”。所有的疫情都会提两个纬度——标签和地点
数据以小时级别新增,每小时产生20W+数据 ,这20W+数据中有很大量的重复数据
请问如何进行去重?
其实乍一听到这个题目,我便想知道一个问题——如何判断重复?
虽然他给了例子——“杭州发生疫情”、“原标题:杭州发生疫情”、“杭州发生疫情”,但是并没有一个明确的标准。
于是我追问了“如何定义重复?”
面试官补充了一个标准就是时间(天级别或者小时级别),这个时间相当于该文本的一个属性,重复的定义就是——“标签、地点和时间要一致”,并举了一个例子,“3月21日 杭州发生了疫情”和“3月27日 杭州发生疫情”这是两个不同的事件。
于是我向面试官确认重复的定义——“标签、地点和时间要一致,隔天发生的事件算两件事情”。
面试官说“也不一定,这里有个去重比例、漏去重和过度去重的比例。”
PS:这里双方都有些不好的地方。作为做题者的我,需要明确题目的边界,就比如这里的对于重复的定义,这样我才能根据面试官的意思去找到解决方案,同时也是为自己争取一些思考的时间。但其实如果在真实做项目的过程中,这个问题并不该问,因为真实场景中,比如面试官在最后也说到了这是一个舆情去重的场景。在这个场景下,重复的定义我们应该是明白的,但是如何去用计算机语言,用一个可以量化的指标去定义重复,这本身就是我们该思考、该解决的一个问题。
但是在面试的这个场景下,我们并不知道这个问题在解决什么场景下的问题,虽然在举例的过程中大概也能猜出来,但是边界、可使用的条件也很模糊。面试官采用的方式确实是限定条件,并且提示了可以使用标签、地点、时间来判断重复,相当于在一个特定场景下去重,简化了原本的问题,那么这里问的便是一个具体的解决实现。
其实这时我也差不多能猜到——重复不重复其实本身是一个设计者应该思考的问题,并没有一个绝对正确的答案。这里面试官对这个问题的理解就是标签、地点和时间一致,但我向面试官确认这个条件时,面试官的回答是——“也不一定”,这就说明,面试官其实也知道也会有例外发生,这并不能作为一定正确的判断标准。
这也是为什么我后面向面试官确认——“重复不重复是一个有点主观的事情,我们需要用一个计算机的方式去进行判断,至于评价标准是一个比较主观的事”。
其实这里主观一词用的并不恰当。
我们这里仔细想一下,两条新闻的标题,或者是不知道哪里爬来的句子(这里因为不知道获取数据的手段,就随便假设一下),真正能判断他们说的是否是一件事情的标准是什么?是不是很难界定?如果用我们人的角度去思考,这个实际上需要理解这个句子它在讲什么,这个就涉及语义的问题,这样是不是又联想到人工智能那边了?
但其实在这个问题场景下,我们并不需要准确分析句子的语义,并不需要精准的去重。作为工程师,我们需要做的就是权衡效果和代价去设计解决方案。
好了,扯了一堆,上述也都是面后的思考,纯属马后炮行为。
至于方案,我确实没有什么特别好的判断重复的手段和标准,面试官给的条件确实是一个不错的解决思路。
当时我的回答思路并不好,毕竟在有限时间里想一个没有接触过的场景,而且很多东西我也没有接触过,比如打标签是通过nlp模型识别出来的,这意味着打标签的过程其实也会有性能消耗,这我是根本没有考虑到的。
不过面试官人挺好的,在我不断确认下,也透露了很多信息给我,包括了一部分他的解决思路。
注意,以下纯属马后炮,是我面后重新梳理思路写的,就当看个乐呵吧。
首先,对于方案的设计,尤其是针对这种大数据的处理方案,首先要做的就是观察数据特征,这就像我之前参加华为软件精英挑战赛,也是需要针对数据的特征去找到思路并对症下药设计方案的。
如果样本数据出现很多重复的,比如说有很多条数据都是一字不差的“杭州发生疫情”,那么我们有必要对其进行第一步去重,首先去除完全一样的。但如果这种数据很少很少,那我们就没必要去进行去重,因为内存中维护一个这样的数据结构(比如Map)代价是很大的,尤其是在数据量如此之大的场景下。
通过标签来进行去重,这是一个很好的方法,得益于npl模型。但是这里我们也需要知道一个信息——通过npl模型获得标签的效率高不高?如果高的话,我们完全可以把它摆到前面来去重,因为很多时候文本重不重复很大程度上取决于标签;但是如果效率不高,这时候我们需要把取标签的操作放到后面,在前面先过滤掉一部分,比如地点、时间(但其实这种过滤掉的数据应该很少,当然这个具体得看数据集的特征,我觉得少没用)。
对于具体设计而言,我们可以大致知道——标签、地点一致,时间在一个范围内的都可能是同一件事情。换言之,我们可以把一个文本看做是标签和地点的排列组合(地点也可以当做标签处理),而重复则意味着组合相同。
为了处理方便,我们可以把标签和地点加上相应的编号,之后组合时按序号排序,以“,”隔开,比如“杭州发生了疫情”则可以变为“3,9”,3是杭州的编号,9表示疫情这个标签。然后将其放在一个map中进行去重,key是转换后“序列号”,value为具体的文本(便于后续查询不重复的文本)。
又或者可以利用字典树的方式,和往常处理不同的是,添加数据时我们依旧要对编号排序,因为我们只需要组合相同即可,而不是排列。
以上便解决地点和标签的去重。
接下来是时间的处理,因为我们无法确定不同时间报道的新闻是不是同一个新闻,时间纬度很大程度上只是一个参考,所以并不能作为一个决定性的因素,因此这里的设计要考虑我们究竟想要达到什么样的效果。是宁可错杀一千也不放过一个?还是追求最大程度上的不重复?
为了通用性考虑,我们在设计时间去重时可以设置有效时间,这个时间意味着两个新闻都是“杭州发生疫情”的情况下,相差多久报道才不算是一个新闻。
亦或者我们可以设计得更复杂一点,借鉴老化算法的思路,为每天/每小时设置一个map/字典树,时间越久的map/字典树权重越低,越容易被判成不同新闻。每次去重需要按照时间先后去判断有没有重复。
…
总之呢,在这里空讲意义其实并不大,说得再多也只是纸上谈兵,具体还得看数据集的特征,很多思路都是从数据集的特征上来的。
总结
首先,很感谢美团和阿里给我这个双非本科生面试的机会,让我认识到了自己的不足。其次,很感谢阿里面试官对我的建议——多思考,找准一个方向。
很多时候我确实很难静下心来去思考问题,尤其是在做项目赶工期的时候,尽管遇到了很多难题,但也只是追求达到需求就好。但其实我自认为我对于学习的思考还是比同龄人做的好的,我写的很多博文也会记录我自己的思考和总结,不过这还是不够,学习应该是个不断试错、终身探索的过程。
回顾我这一路自学之旅,其实我也知道我自己并不聪明,我并不比别人强,我有的只不过是那份坚持、那份倔强,我可以在实验室一天到晚的学习探索,享受知识、项目带给我的乐趣和充实感,而这是别人所达不到的,仅此而已。
整理于2022.3.26 晚
愿我们以梦为马,不负青春韶华
与君共勉!
以上是关于美团一面阿里一面复盘总结的主要内容,如果未能解决你的问题,请参考以下文章