万字长文教会小师妹何为YOLO,并实战演练(附源码)
Posted 羽峰码字
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万字长文教会小师妹何为YOLO,并实战演练(附源码)相关的知识,希望对你有一定的参考价值。
大家好,我是羽峰,公众号:羽峰码字,欢迎来撩。
接下来本文要讲的是YOLOv1--YOLOv3算法的原理,及YOLOv3的实现,一文带你了解YOLO的来龙去脉。希望各位读完本文会有所收获。
目录
YOLOv1
YOLOv1算法是YOLO系列算法的基础,理解YOLOv1可以更好的理解YOLO系列算法。
YOLOv1结构
首先我们要理解的是yolo的网络结构,如图1所示。
其实网络结构比较简单,就是简单的CNN网络,池化操作,以及全连接网络。
我们主要理解输入与输出之间的映射关系,中间网络只是求取这种映射关系的一种工具。网络的输入是448*448*3的一个彩色图像,而网络的输出是7*7*30的多维向量。下面我们将详细的来解释这种映射关系,这种映射关系也是YOLOv1的根本。

图1
YOLO的输入与输出如图2所示,左边是一张图片,中间的圆形可看作是目标物体,当图片输入到网络中,YOLOv1首要做的是将图片分成7*7的网格,从中间图像中可以看出,红色代表的是网格,蓝色代表的是目标物体的中心,然后黄色代表的是真实的物体边框。
这里有个最重要的一个概念就是:当物体中心落在某个网格中心时,那么这个网格就负责预测这个物体,这是yolov1的一个基础。
每个网格预先都会生成两个预测框,这样YOLOv1一共生成7*7*2=98个预测框,相比于faster rcnn 成百上千的预测框来说,YOLO的预测框明显少了很多,这是YOLO非常快速的一个原因。
每个预测框都会对应一个30维的向量,这30维向量是2*5+20得来的,其中20是20个类别,这里之所以为20,是因为原论文所做的就是对20个物体进行分类。如果我们自己的数据集有n个类别,那么这里的20就可以改为n个类别。
然后2代表的是2个边框,因为最开始每个网格会生成两个预测框,而5则代表每个边框中有五个参量,分别是边框的中心坐标(x, y),边框的宽w和高h,还有一个是框的置信度,置信度公式计算如图公式所示,置信度大的那一个预测框就会被选为该网格的预测边框。
网络的输出就是7*7*30维的向量,与输入存在一个数学上的映射关系,而中间的yolo网络只是求这个映射关系的一种工具。接下来我们将重点研究一下yolo的损失函数。
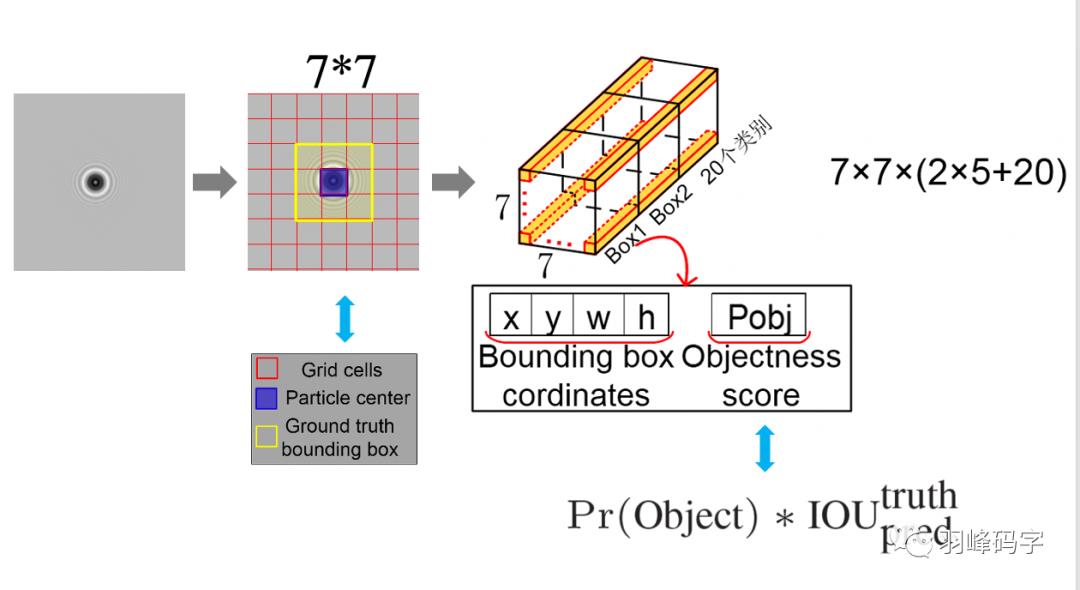
图2 输入与输出的映射关系
YOLOv1损失函数
损失函数大致分为3个部分,第一个是坐标的预测,分别是边框的x, y, w, h。
第二个是物体的置信度预测,
第三个是物体的类别预测,
损失函数与7*7*30维的向量相对应,是求取输入与输出之间映射关系误差的“数学表达式”。

图3 YOLOv1的损失函数
首先我们看一下坐标损失函数,如图4所示。
每个参数的意义如图所示,之所以采用根号来计算物体的长和宽,是因为根号后的大物体的长宽损失与小物体的长宽损失相近,这样整个损失函数不会被大物体所操纵。若不采用根号计算,那么大物体的损失要比小物体损失大很多,那么这个损失函数会对大物体比较准确而忽略了小物体。
公式前的系数是一个超参数,这是设置为5,因为物体检测过程中,我们所要检测的物体相对与背景来说要少的很多,所以加入这个超参数是为了平衡“非物体”对结果的影响。
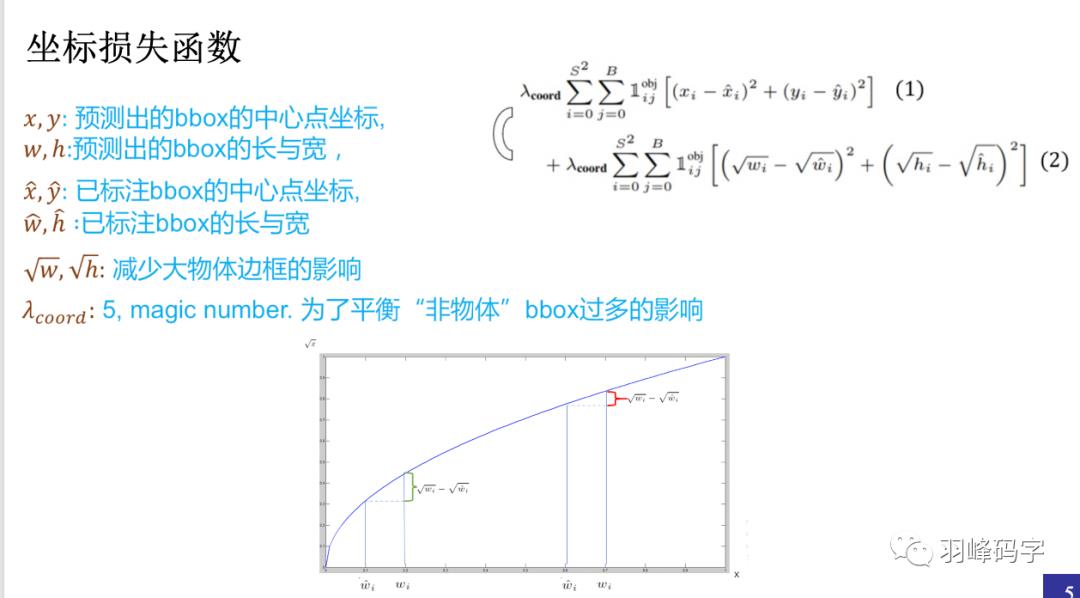
图4 坐标损失函数
置信度的损失函数如图5所示,每个参数的意义如图所示。
这里为什么要加入“非物体”的置信度呢,是因为网络要想学习分类n个物体,那他实际要学n+1个类别,那多出的“1”是背景或者就是真实意义上的非物体,这一类是占有很大一部分比例的,所以必须要学习这一类,才能保证网络的准确性。
那这里为什么要在“非物体”的置信度前边加上超参数呢?
也是因为我们所检测的目标物体相对于“非物体”是很少的,如果不加入这个超参数,那么“非物体”的置信度损失就会很大,所占权重比较大,这样会导致网络只学习到了“非物体”特征,而忽略了目标物体特征。

图5 置信度损失函数
最后则是类别损失函数,如图6所示,类别损失是一个很粗暴的两个类别做减法,这是YOLOv1不可取的一部分,当然后续就改掉了。

图6 类别损失函数
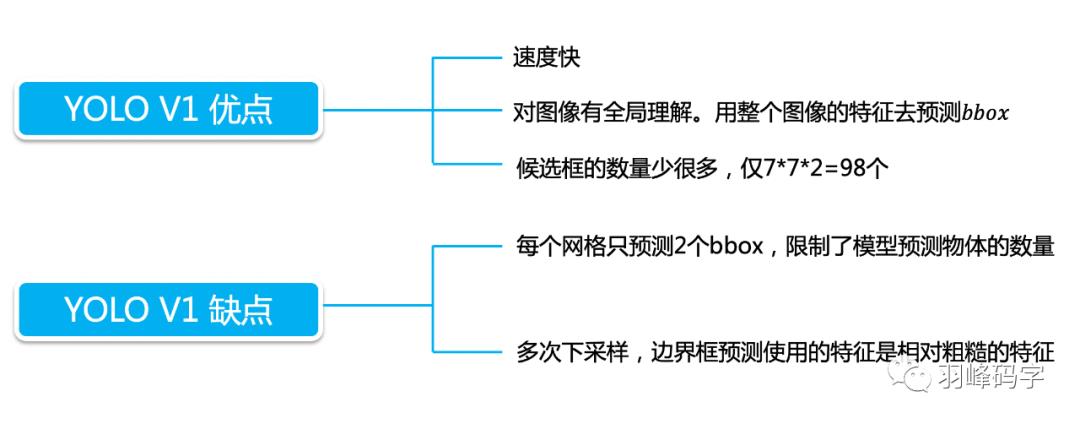
最后我们来做个总结,YOLO的优点就是速度快,YOLOv1缺点也很明显,
-
对拥挤物体检测不太好:因为拥挤物体的中心有可能都落在一个网格中心,那么这个网格可能就要预测两个物体,这是很不好的。
-
对小物体检测效果不好,小物体损失虽然使用的超参数或者根号进行了平衡,但小物体的损失占比还是小,网络主要学习的还是大物体特征。
-
对非常规的物体形状或者比例,检测效果不好
-
没有batch normalize.
YOLOv2
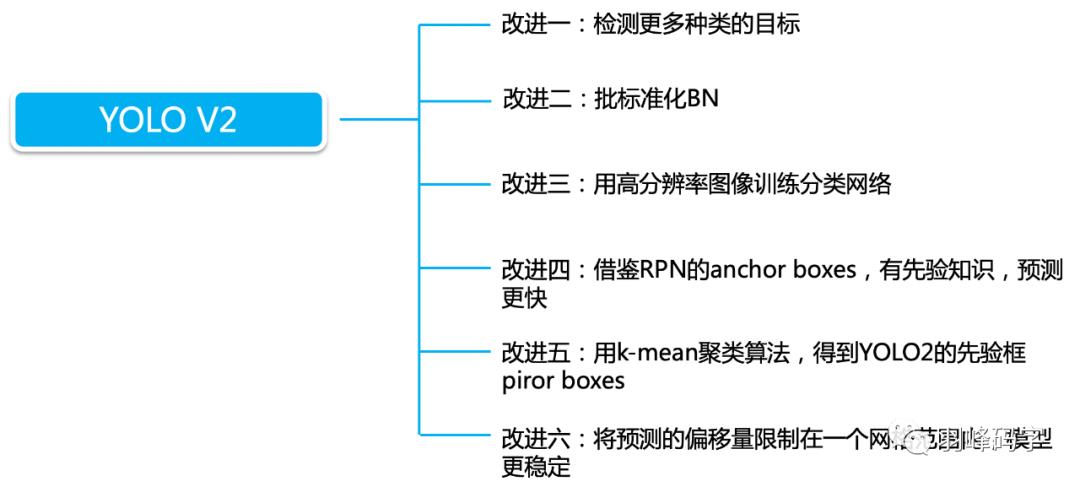
YOLOv2相对于YOLOv1的主要改进
YOLOv2的第一个改进就是网络的改进,使用DarckNet19代替了YOLOv1的GoogLeNet网络,这里主要改进是去掉了全连接层,用卷积和softmax进行代替。
YOLOv2的第二个改进是在网络中加入了Batch Normalization,使用Batch Normalization对网络进行优化,让网络提高了收敛性,同时还消除了对其他形式的正则化(regularization)的依赖。
YOLOv2的第三个改进是增加了HighResolution Classifier,具体做法是:首先在448×448的全分辨率下在ImageNet上微调分类网络的10个epoch。这使网络有时间调整其过滤器,使其在更高分辨率的输入上更好地工作。然后,我们根据检测结果对网络进行微调。这种高分辨率分类网络使我们的mAP几乎提高了4%。
YOLOv2的第四个改进是Multi-ScaleTraining,让网络在不同的输入尺寸上都能达到一个很好的预测效果,同一网络能在不同分辨率上进行检测。当输入图片尺寸比较小的时候跑的比较快,输入图片尺寸比较大的时候精度高。
Anchor 机制
YOLOv2的第五个改进是加入了Anchor机制,这个是最重要的一个改进,也是本文将重点讲解的一个改进。
首先我们要了解什么是Anchor机制,Anchor首先要预设好几个虚拟框,在用回归的方法确定最终的预测框。
在YOLOv2中,使用K-means算法来生成Anchor bbox,如图7所示,当k=5时,模型的复杂度与召回率达到了一个比较好的平衡,所以YOLOv2使用了5个Anchor bbox 。

图7
将YOLOv1的输出与YOLOv2输出进行对比,如图2所示。
YOLOv1是的输出7*7*30的多维向量,其中7*7是分辨率,对原图进行了7*7的分割,每个网格对应一个包含30个参数的向量,每个向量中包含两个bbox,每个bbox中包含5个向量,分别是bbox的质心坐标(x,y)和bbox的长和宽,还有一个bbox的置信度,剩下20个则是类别概率。
而YOLOv2对此进行了修改,YOLOv2输出的是13*13*5*25的一个多维向量,其中13*13是分辨率,也就是说网络将输入图片分成了13*13的网格,每一个网格对应一个包含5*25=125个参数的一维向量,其中5代表5个Anchor bbox,每个Anchor bbox中包含25个参数,分别是bbox的质心坐标(x,y)和bbox的长和宽,还有一个bbox的置信度,剩下20个则是类别概率。
这样的好处是YOLOv2可以对一个区域进行多个标签的预测,比如一个“人”的目标物体,他可以属于“人”这个标签,也可以属于“男”或者“女”这个标签,也可以是“老师”,“学生”或者“职工”等这些标签,而YOLOv1只能预测目标物体的一个类别。这里所做的最主要的改变是:bbox的四个位置参数的损失函数计算方法发生了改变。
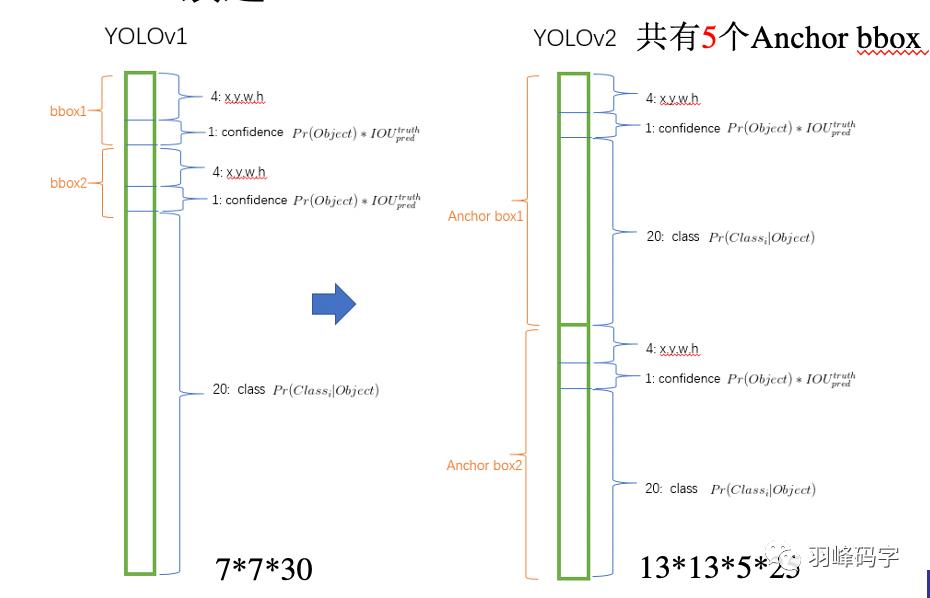
图8 输出对比
首先我们来认识一下Anchor bbox, Predicated bbox以及Ground truth bbox 三者之间的关系。
如图9所示,红色框代表了Anchor bbox,蓝色框代表了 Predicated bbox,绿色框则代表了Ground truth bbox。
我们希望的是Anchor bbox 接近于Ground truth bbox,但Anchor bbox是预先设定好的,不可以更改。
但Anchor bbox可以生成不同的Predicated bbox,所以我们将我们目标转化为:Predicated bbox更接近于Ground truth bbox, 将这个目标转化为数学表达式就是f(x),具体如图所示,那么我们的目标就变成了数学上的 tp 更加接近于tg。式子中都做了归一化,防止大物体干扰整个计算结果。

图9三者之间关系
其次我们要了解一下坐标转换的概念,YOLOv1的坐标是相对于整个图像的,而YOLOv2的坐标是相对于每个网格的,那如何得到相对网格的这个坐标呢,又是如何计算loss值的呢?
如图10所示,最开始我们会生成Anchor bbox,这时候的这个bbox是相对于整个图像来说的,所以此时我们要进行归一化,归一到[0,1]之间。
YOLOv2的分辨率是13*13,所以我们要将这个[0,1]之间的坐标乘上13,使得bbox的坐标是相对于13个网格的,此时坐标范围在[0,13]之间。此时我们在进行归一化操作,使得此时的坐标是相对于单独一个网格的,归一化计算公式是xf = x-i, yf = y-j, wf = log(w/anchors[0]),hf = log(h/anchors[1]),这里我们可以举个粒子,加入x = 9.6(x的范围是[0,13]),那么此时的i是x的整数部分,也就是i = 9, 所以xf = 0.6,此时这个0.6就是相对于轴向第10个网格的x轴坐标。

图10 坐标变换
最后就是的loss 计算,如图11所示,图片中间的公式就是YOLOv2 loss的计算公式,这个计算公式坐标计算是相对于网格的,而其对应的f(x)则是相当于整个图像的。
网络会计算得到δ(tx),δ(ty),其中δ是sigmoid函数,将网络输出归一化到[0,1]之间,这样就会得到相对于某个网格的质心位置,加上该网格相对于整个13*13网格的偏移值,就会得到预测bbox的质心位置,高和宽,调整这个值,使其更加接近于真实的bbox。

图11 总结
YOLOv3
YOLOv3的改进
YOLOv3的第一个改进是网络的结构的改变,引入了ResNet思想,但是如果将ResNet模块完全引进是整个模型就很大,所以直接将ResNet模块的最后一层1*1*256去掉,而且将倒数第二层3*3*64直接改成3*3*128。整个网络结构如图所示,输入的是416*416*3的RGB图像,网络会输出三种尺度的输出,最后输出每个目标物体的类别和边框。


YOLOv3的第二个改进是多尺度训练,是真正的多尺度,一共有3种尺度,分别是13*13,26*26,52*52三种分辨率,分别负责预测大,中,小的物体边框,这种改进对小物体检测更加友好。

YOLOv3多尺度训练的原理如图所示,首先一个图像输入,被YOLOv3分割成13*13,26*26,52*52的网格,每种分辨率的每个网格分别对应一个多维向量,每个向量包括三个边框,每个边框中包含85个参数,分别是边框的中心位置(x,y),边框的置信度,还有80个类别概率。最后输出每个物体的类别概率和边框。

YOLOv3代码实战
1. 数据集标注
训练YOLOv3首先要进行LabelImg标注,
LabelImg的网址为:https://github.com/tzutalin/labelImg,
安装程序如图所示:

安装好之后,界面如图所示:
首先点击”open”打开图片,如图所示,打开的是一个狗和猫的图片,然后选择边框进行标注。
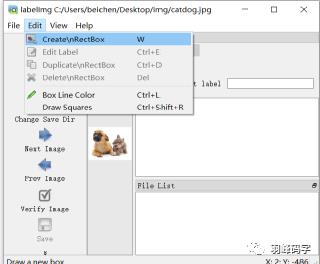
标注好之后应该,应该备注目标物体类别,如图所示:

标注好之后会生成“catdog.xml”文件,
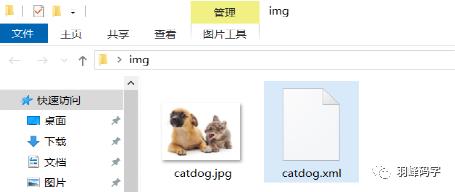
文件内容如图所示:

最后分别将图片(catdog)放入 ./VOCdevkit/VOC2007/JpegImages, LabelImg标注图像放进“Annotations”中。如图所示:

2. 数据预处理
当图片和xml文件都准备好之后 ,运行“voc2yolo3.py”程序,生成数据集列表文件,将图片上对应的”voc_classes.txt”换成你自己的分类标签,如果有多个类别,请将每个类别单独放一行。
为了方便展示,我这里是临时加入了一些图片数据,不是本YOLOv3所执行的。后边图片中的数据都是原yolov3的数据,所以有些数据对应不上,但执行整个过程是接下来要说的。如果训练自己的数据集,需要将自己的数据粘贴到对应位置。

之后在运行“voc_annotation.py”程序,运行之前,首先将程序中的类别改成你自己的类别,我这里类别只有一个“particle”。
之后在运行“kmeans.py”程序,运行好之后会生成k anchor,这些数字代表了你的预生成的标注框大小,将这些标注框数据首先放入如图所示的位置,并按照“yolo_anchors.txt”原有格式进行修改。
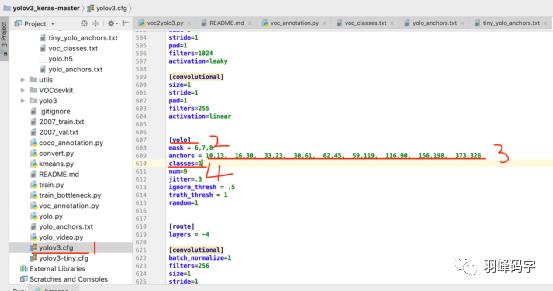
接下来在复制这些数字到“yolov3.cfg”中,搜索”yolo”将对应的anchors 和classes 进行修改,classes选择你要分类的类别,我这里只有1个类别,就改成了1。一共有3个“yolo”,都要修改。
3. 训练和测试
当所有工作都做好之后,就可以训练了,直接执行 “train.py”就可以了。注意权重的保存路径和一些参数的调整就可以了。
训练完成之后,执行“yolo_video.py”进行测试就行。如果是从我公众号下载的yolov3,需要将yolo_video.py做如下修改:


YOLO系列总结


以上 就是我今天要分享的内容,谢谢各位。如有错误,欢迎批评指正。
如果想要YOLOv3代码,欢迎关注“羽峰码字”公众号,并回复“YOLOv3”获取相应代码。
我是羽峰,公众号:羽峰码字,我们下期见。
以上是关于万字长文教会小师妹何为YOLO,并实战演练(附源码)的主要内容,如果未能解决你的问题,请参考以下文章
Tableau实战系列Tableau基础概念全解析 -万字长文解析数据类型及数据集
Python数据可视化实战应用万字长文从入门到高端(建议收藏)
深度2万字好文:图像处理-基于 PyTorch 的 YOLO v5 表情识别(附源代码)