算法笔记:KM算法(Kuhn-Munkres Algorithm)
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法笔记:KM算法(Kuhn-Munkres Algorithm)相关的知识,希望对你有一定的参考价值。
带权二分图的最优匹配问题
算法笔记:匈牙利算法_UQI-LIUWJ的博客-CSDN博客
- 匈牙利算法的一个问题是,找到的匹配不一定是最优匹配
- 因为算法将每个匹配对象的地位视为相同的,在这个前提下求解最大匹配
- 而很多时候,二部图连边是带权重的,在这个基础上的匹配才更贴近真实情况
1 KM算法举例
二部图的每条关系之间加入了权重
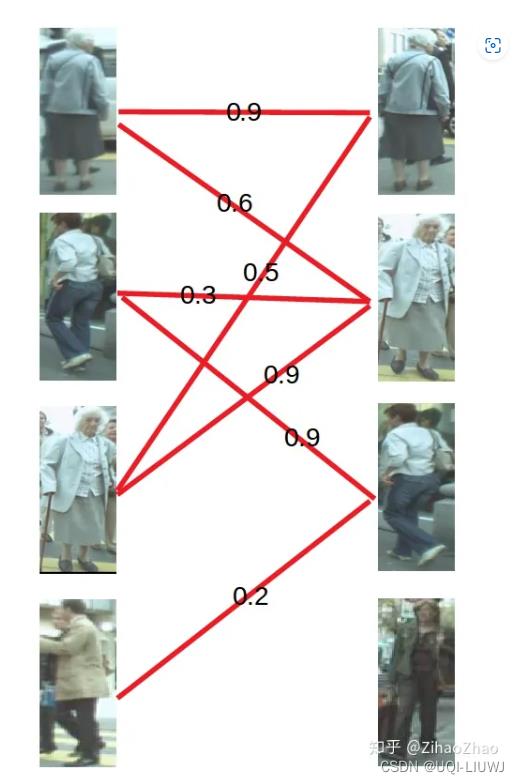
1.1 具体步骤
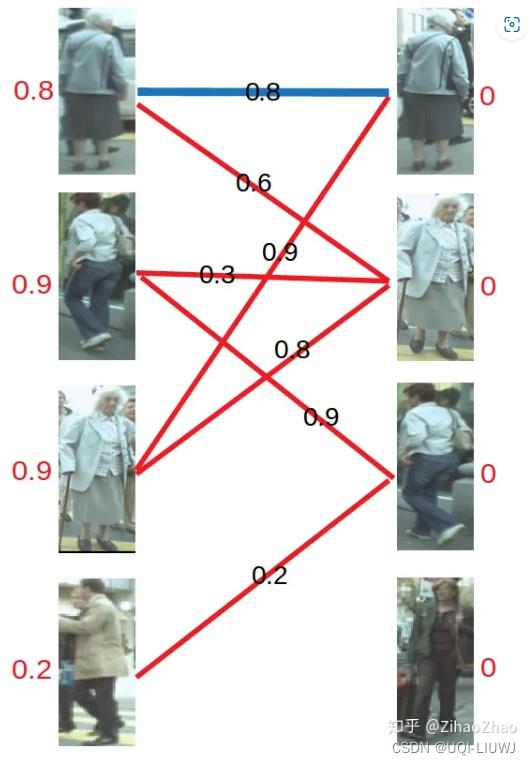
- 首先对每个顶点赋值,称为顶标,将左边的顶点赋值为与其相连的边的最大权重,右边的顶点赋值为0。
- 然后开始匹配
- 匹配的原则是:
- 只和权重与左边分数(顶标)相同(或比顶标大)的边进行匹配(边权重=左+右)
- 若找不到边匹配,对此条路径的所有左边顶点的顶标减d,所有右边顶点的顶标加d。参数d我们在这里取值为0.1。
- 匹配的原则是:
-
对于左1,与顶标分值相同的边先标蓝。
-
- 然后是左2,与顶标分值相同的边标蓝
- 然后是左3,发现与右1已经与左1配对。
- 首先想到让左3更换匹配对象
- 然而根据匹配原则,只有权值大于等于0.9+0=0.9(左顶标加右顶标)的边能满足要求。于是左3无法换边。
- 那左1能不能换边呢?
- 对于左1来说,只有权值大于等于0.8+0=0.8的边能满足要求,无法换边。
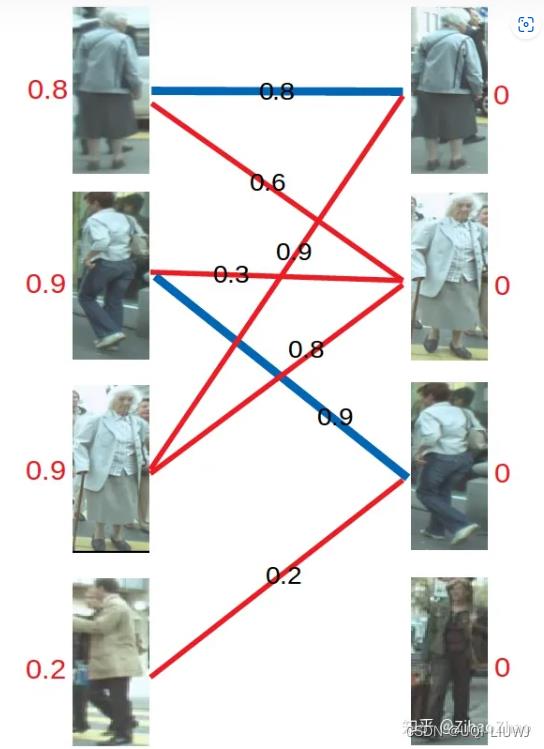
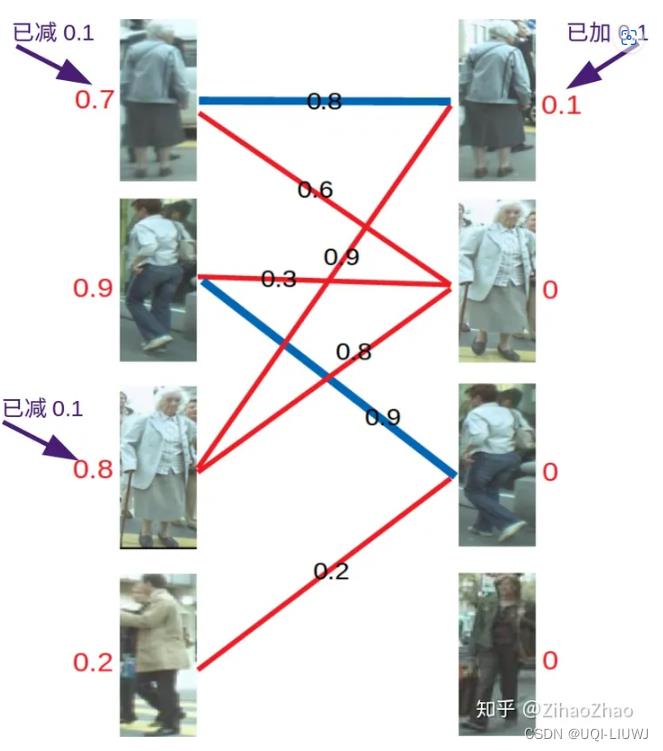
- 此时根据KM算法,应对所有冲突的边的顶点做加减操作,令左边顶点值减0.1,右边顶点值加0.1。
-
再进行匹配操作,发现左3多了一条可匹配的边,因为此时左3对右2的匹配要求只需权重大于等于0.8+0即可,所以左3与右2匹配!
-
- 首先想到让左3更换匹配对象
- 最后进行左4的匹配,由于左4唯一的匹配对象右3已被左2匹配,发生冲突。进行一轮加减d操作,再匹配,左四还是匹配失败。两轮以后左4期望值降为0,放弃匹配左4。

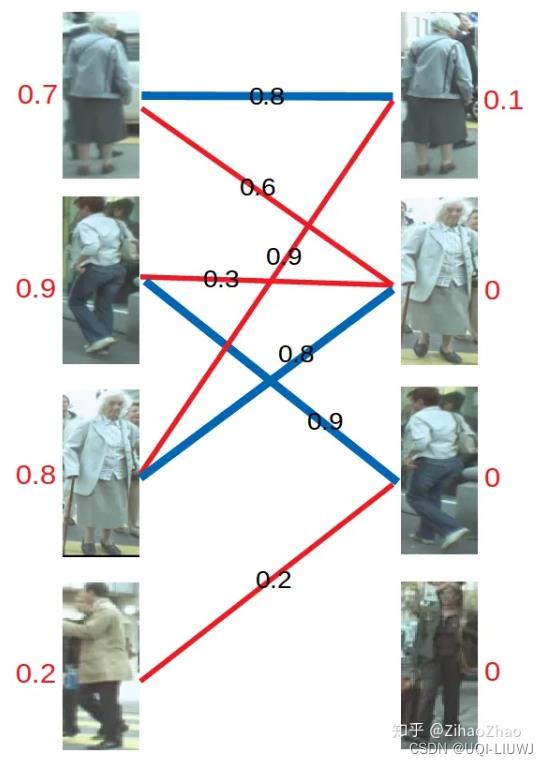
参考内容:带你入门多目标跟踪(三)匈牙利算法&KM算法 - 知乎 (zhihu.com)
KM(Kuhn-Munkres)算法求带权二分图的最佳匹配
KM(Kuhn-Munkres)算法求带权二分图的最佳匹配
相关概念
这个算法个人觉得一开始时有点难以理解它的一些概念,特别是新定义出来的,因为不知道是干嘛用的。但是,在了解了算法的执行过程和原理后,这些概念的意义和背后的作用就渐渐的显示出来了。因此,先暂时把相关概念列出来,看看,有个大概印象就好,等到了解了算法的流程后,在看原理中会有这些概念,那个时候回来细看就好了。
完备匹配:定义 设G=<V1,V2,E>为二部图,|V1|≤|V2|,M为G中一个最大匹配,且|M|=|V1|,则称M为V1到V2的完备匹配。 也就是说把一个集合中的点全部匹配到另一个集合中。(之所以先介绍这个概念,是因为当时看了很久,好多概念里都有提到完备匹配,但是我并不知道什么是完备匹配。)在上述定义中,若|V2|=|V1|,则完备匹配即为完美匹配,若|V1|<|V2|,则完备匹配为G中最大匹配。
二分图最优匹配:对于二分图的每条边都有一个权(非负),要求一种完备匹配方案,使得所有匹配边的权和最大,记做最优完备匹配。(特殊的,当所有边的权为1时,就是最大完备匹配问题)
二分图带权匹配与最优匹配:什么是二分图的带权匹配?二分图的带权匹配就是求出一个匹配集合,使得集合中边的权值之和最大或最小。而二分图的最优匹配则一定为完备匹配,在此基础上,才要求匹配的边权值之和最大或最小。二分图的带权匹配与最优匹配不等价,也不互相包含。
以下是一些转换的思路:
KM算法是求最大权完备匹配,如果要求最小权完备匹配怎么办?方法很简单,只需将所有的边权值取其相反数,求最大权完备匹配,匹配的值再取相反数即可。
KM算法的运行要求是必须存在一个完备匹配,如果求一个最大权匹配(不一定完备)该如何办?依然很简单,把不存在的边权值赋为0。
KM算法求得的最大权匹配是边权值和最大,如果我想要边权之积最大,又怎样转化?还是不难办到,每条边权取自然对数,然后求最大和权匹配,求得的结果a再算出e^a就是最大积匹配。至于精度问题则没有更好的办法了。
下面是算法需要而建立的概念:
顶标:每个节点与另一个集合中节点之间的最大权值
可行顶标:对于原图中的任意一个结点,给定一个函数L(node)求出结点的顶标值。我们用数组lx(x)记录集合X中的结点顶标值,用数组ly(y)记录集合Y中的结点顶标值。 并且,对于原图中任意一条边\\(edge(x,y)\\),都满足\\(lx(x)+ly(x)>=weight(x,y)\\)。
相等子图:设 G(V,E) 为二部图, G‘(V,E‘) 为二部图的子图。如果对于 G‘ 中的任何边<x,y> 满足, \\(lx(x)+ ly(y)== weight(x,y)\\),我们称 G‘(V,E‘) 为 G(V,E) 的等价子图或相等子图(是G的生成子图)。
算法流程
这里有一篇比较好的男女找对象指南博客讲解了KM算法的执行过程,生动而又形象。主要理解过程中是怎么满足配对条件的,不满足后怎么办,过程中降低期望值d是怎么求得的,在配对失败期望值进行更改以后发生了那些变化,这些变化为新的一轮的匹配带来了什么?
算法原理:
搞清楚算法流程后对算法的原理就会很好奇(可能吧~),为什么要这样做,这样做后为什么会产生这些改变,为什么利用这些改变就可以得出最终结果?
在详细介绍原理前,可以先看一下这篇博客(有图),根据算法流程介绍原理,可以直观感受一下,写的还是很清晰的,就是字有点小
算法的正确性基于以下定理:(相关概念就可以倒回去看了)
若由二分图中所有满足\\(lx(x)+ly(y)==weight(x,y)\\)的边(x,y)构成的子图(称做相等子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。
因为对于二分图的任意一个匹配,如果它包含于相等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那么它的边权和小于所有顶点的顶标和(即不是最优匹配)。所以相等子图的完备匹配一定是二分图的最大权匹配。
? 初始时为了使\\(lx(x)+ly(y)>=weight(x,y)\\)恒成立,令lx(x)为所有与顶点Xi关联的边的最大权,ly(y)=0。如果当前的相等子图没有完备匹配,就按下面的方法修改顶标以使扩大相等子图,直到相等子图具有完备匹配为止。
? 我们求当前相等子图的完备匹配失败了,是因为对于某个X顶点,我们找不到一条从它出发的交错路。这时我们获得了一棵交错树,它的叶子结点全部是X顶点(因为没法跟Y匹配下去了,终止在X)。现在我们把交错树中X顶点的顶标全都减小某个值d,Y顶点的顶标全都增加同一个值d(注意是交错树中的顶点,也就是匹配的女生和被访问的男生),那么我们会发现:(这个过程就对应于男女生配对中女生配对失败后的情况)
?
? 1)两端都在交错树中的边(x,y),lx(x)+ly(y)的值没有变化。也就是说,它原来属于相等子图,现在仍属于相等子图。
2)两端都不在交错树中的边(x,y),lx(x),ly(y)都没有变化。也就是说,它原来属于(或不属于)相等子图,现在仍属于(或不属于)相等子图。
3)X端不在交错树中,Y端在交错树中的边(x,y),它的lx(x)+ly(y)的值有所增大。它原来不属于相等子图,现在仍不属于相等子图。
4)X端在交错树中,Y端不在交错树中的边(x,y),它的lx(x)+ly(y)的值有所减小。也就说,它原来不属于相等子图,现在可能进入了相等子图,因而使相等子图得到了扩大。
? 现在的问题就是求d值了。为了使\\(lx(x)+ly(y)>=weight(x,y)\\) 始终成立,且至少有一条边进入相等子图,d应该等于:\\(Minlx(x)+ly(y)-weight(x,y)|x在交错树中,y不在交错树中\\)。
以上是KM算法的基本思想。但是朴素的实现方法,时间复杂度为O(n4)——需要找\\(O(n)\\)次增广路,每次增广最多需要修改\\(O(n)\\)次顶标,每次修改顶标时由于要枚举边来求d值,复杂度为\\(O(n^2)\\)。实际上KM算法的复杂度是可以做到\\(O(n^3)\\)的。我们给每个Y顶点一个“松弛量”函数slack,每次开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边(x,y)时,如果它不在相等子图中,则让slack[y]变成原值与weight(x,y)-lx(x)-ly(y)的较小值(就是男生女生配对的求d的过程)。这样,在修改顶标时,取所有不在交错树中的Y顶点的slack值中的最小值作为d值即可。但还要注意一点:修改顶标后,要把所有的不在交错树中的Y顶点的slack值都减去d(对应就是未被访问的男生离女生更近了一步)。
代码
以下代码基于HDU2255奔小康赚大钱
#include <iostream>
#include <cstdio>
#include <memory.h>
#define max_n 305
#define INF 0x3f3f3f3f
using namespace std;
int n;//一个集合中的顶点数
int love[max_n][max_n];//两个不同集合点之间的权值,即男女好感度
int ex_girl[max_n];//女生顶标
int ex_boy[max_n];//男生顶标
int vis_girl[max_n];//记录女生是否参与匹配
int vis_boy[max_n];//记录男生是否被尝试匹配
int slack[max_n];//松弛函数,以求出顶标的最小改变量d
int match[max_n];//记录匹配关系
int dfs(int girl)
vis_girl[girl] = 1;
for(int boy = 0;boy<n;boy++)
if(vis_boy[boy]) continue;//每次dfs每个男生都只能被访问一次
int gap = ex_girl[girl]+ex_boy[boy]-love[girl][boy];//看看L(x)+L(y)-weight(x,y)的值
if(gap==0)//如果满足匹配规则
vis_boy[boy] = 1;//当前男生已被访问
if(match[boy]==-1||dfs(match[boy]))//如果男生无主或者他的女生可以抛弃他
match[boy] = girl;//就给男生匹配新的女生
return 1;//配对成功
else
slack[boy] = min(gap,slack[boy]);//如果无法满足匹配规则,看男生要能跟女生匹配还差多少,不断更新这个差值
return 0;
int KM()
memset(match,-1,sizeof(match));//全部标记为未匹配
memset(ex_boy,0,sizeof(ex_boy));//男生顶标初始化为零
for(int i = 0;i<n;i++)//求出女生顶标,即这个女生与男生好感度的最大值
ex_girl[i] = love[i][0];
for(int j = 1;j<n;j++)
ex_girl[i] = max(ex_girl[i],love[i][j]);
for(int i = 0;i<n;i++)//对每个女生开始匹配
fill(slack,slack+n,INF);//松弛函数初始化为无限大
while(1)
memset(vis_girl,0,sizeof(vis_girl));//每次dfs前清除标记数组
memset(vis_boy,0,sizeof(vis_boy));
if(dfs(i)) break;//当前女生匹配成功
int d = INF;//若未成功
for(int j = 0;j<n;j++)
if(vis_boy[j]==0)
d = min(d,slack[j]);//看最小需要将第多少期望值能够匹配成功
for(int j = 0;j<n;j++)
if(vis_girl[j])
ex_girl[j] -= d;//对参与匹配的女生降低期望值
if(vis_boy[j])
ex_boy[j] += d;//对被访问的男生提高期望值,上面两个步骤使得
//1.参与匹配的女生跟满足匹配规则匹配的男生仍然可匹配
//2.参与匹配的女生跟本未被访问的男生可能满足规则,扩大了匹配范围
//3.未参与匹配的女生跟更不可能匹配被访问的男生
//4.未参与匹配的女生跟未被访问的男生依然不能匹配
else
slack[j] -= d;//未被访问的男生离女生跟进了一步
int ans = 0;
for(int i = 0;i<n;i++)
if(match[i]>-1)
ans += love[match[i]][i];
return ans;
int main()
while(~scanf("%d",&n))
for(int i = 0; i<n; i++)
for(int j = 0; j<n; j++)
scanf("%d",&love[i][j]);
printf("%d\\n",KM());
return 0;
参考文章
x_y_q_ ,带权二分图的最佳匹配(KM算法), https://blog.csdn.net/x_y_q_/article/details/51927054 (偏向原理)
SixDayCoder,二分图的最佳完美匹配——KM算法,https://blog.csdn.net/sixdaycoder/article/details/47720471 (概念向)
wenr,KM算法详解+模板,https://www.cnblogs.com/wenruo/p/5264235.html (算法流程介绍)
kuangbin, Kuhn-Munkres算法(二分图最大权匹配),https://www.cnblogs.com/kuangbin/archive/2012/08/19/2646535.html (总结向)
以上是关于算法笔记:KM算法(Kuhn-Munkres Algorithm)的主要内容,如果未能解决你的问题,请参考以下文章