《啊哈!算法》的笔记
Posted OIqng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《啊哈!算法》的笔记相关的知识,希望对你有一定的参考价值。
本文作为《啊哈!算法》里面的内容,作者整理了部分知识供大家参考,如有侵权联系删除。
一大波数正在靠近——排序
最快最简单的排序——桶排序
简单介绍一下下图的主人公小哼

小哼的班上只有5个同学,这5个同学分别考了5分、3分、5分、2分和8分(满分为10分),按从大到小排序,排序后是 8 5 5 3 2。
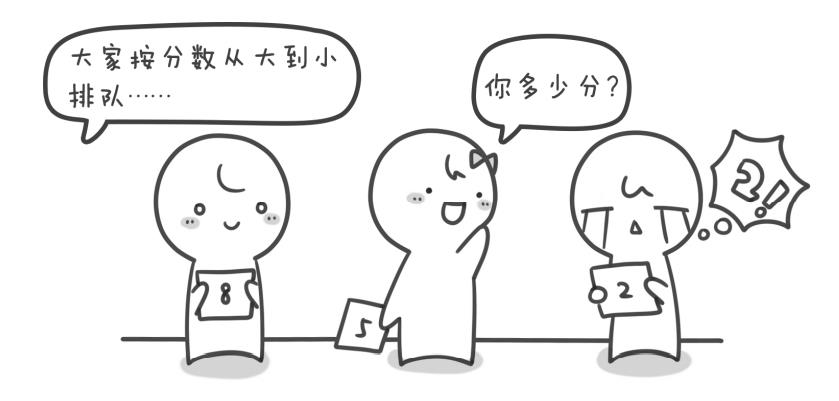
我们只需申请一个大小为11的数组 int a[11],现在我们有编号从a[0]到a[10],我们将a[0]~a[10]初始为0,表示这些分数没人得到。如:a[0]=0表示目前没人0分。
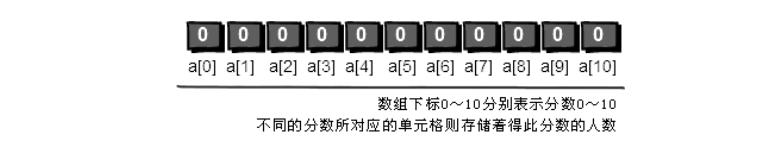
根据小哼班里的成绩可得到最终结果如下图:

因此我们只需将出现过的分数打印处理就可以了。
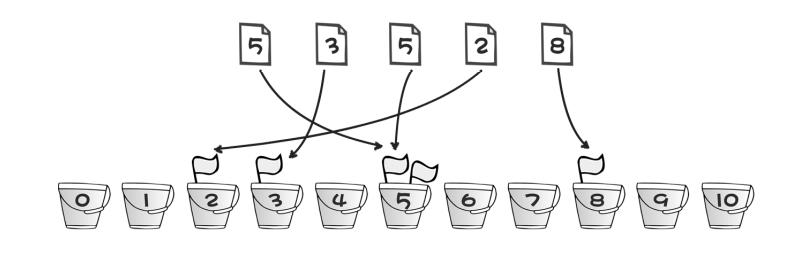
简化版桶排序:有11个桶,编号从0~10,每出现一个数,就在对应编号的桶中放一个小旗子,最后数出每个桶中有几个小旗子。如下图:
代码实现:
#include <stdio.h>
int main()
int a[11], i, j, t;
for(i = 0; i <= 10; i++)
a[i] = 0; // 初始化为0
for(i = 1; i <= 5; i++)
scanf("%d", &t); // 读入5个数到变量
a[t]++; // 计数
for(i = 10; i >=0; i--)
for(j = 1; j <= a[i]; j++)
printf("%d", i);
getchar();getchar(); // 暂停程序
return 0;
该算法的时间复杂度是 O ( M + N ) O(M+N) O(M+N).
邻居好说话——冒泡排序
简化版的桶排序的缺点:浪费空间!
冒泡排序的基本思想:每次比较两个相邻的元素,如果它们顺序错误就把它们交换过来。
如 12 35 99 18 76 这5个数按从大到小排序,即越小的越靠后。首先比较第1位和第2位的大小,发现 12 比 35 小,交换这两个数的位置,交换后的顺序是 35 12 99 18 76,经过4次比较,得到 35 99 18 76 12。
我们刚刚将5个数中最小的一个归位了,每个将一个数归位我们称其位“一趟”。

总结:如果有n个数进行排序,只需将 n-1 个数归位(即n-1趟),每次都需从第1位开始进行比较,将较小的一个数放后面,比较完后向后挪一位继续比较下面两个相邻数的大小。
代码实现
#include <stdio.h>
int main()
int a[100], i, j, t, n;
scanf("%d", &a[i]);
for (i = 1; i <= n; i++)
scanf("%d", &a[i]);
for (i = 1; i <= n - i; j++)
for (j = 1; j <= n - i; j++)
if (a[j] < a[j + 1])
t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
for (i = 1; i <= n; i++)
printf("%d", a[i]);
getchar(); getchar();
return 0;
冒泡排序核心是双重嵌套循环,时间复杂度是 O ( N 2 ) O(N^2) O(N2)。
最常用的排序——快速排序
我们对 6 1 2 7 9 3 4 5 10 8 这10个数进行排序,首先在这个序列中找一个数作基准数(用来做参照的数)。我们让6作基准数,将这个序列中所以大于基准数放6的右边,小于基准数的放6的左边。
方法:先从右往左找一个小于6的数,再从左往右找一个大于6的数然后交换。所以我们使用两个变量i 和j,分别指向序列最左边和最右边。我们为这两个变量取个名字“哨兵i"和”哨兵j“,刚开始让哨兵i指向序列最左边(i=1),指向数字6,让哨兵j指向序列最右边(j=10),指向数字8.
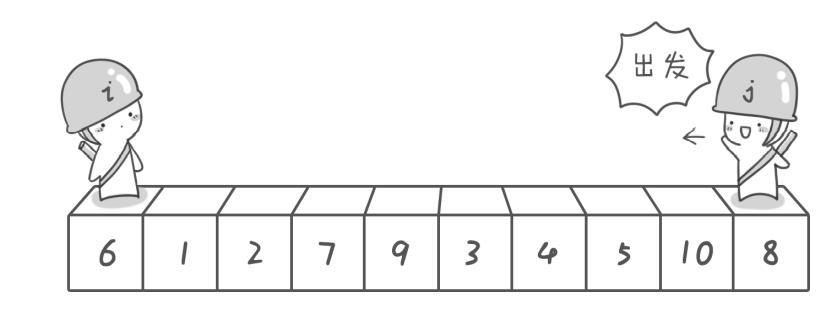
首先哨兵j开始出动,哨兵j向左移动(j–)直到找到一个小于6的数才停下来,接下来哨兵i向右移动(i++),直到找到一个大于6的数才停下来,最后哨兵j停在数字5,哨兵i停在数字7。
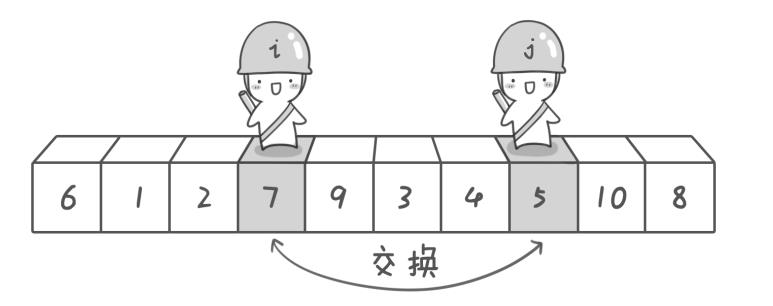
交换哨兵i和哨兵j所指向的元素的值

第一次交换结束,哨兵j继续向左移动,到数字4停下,哨兵i继续向右移动,到9停下,再次进行交换

第二次交换结束,哨兵j继续向左移动,到3停下哨兵i继续向右移动,哨兵i走到数字3与哨兵j相遇了
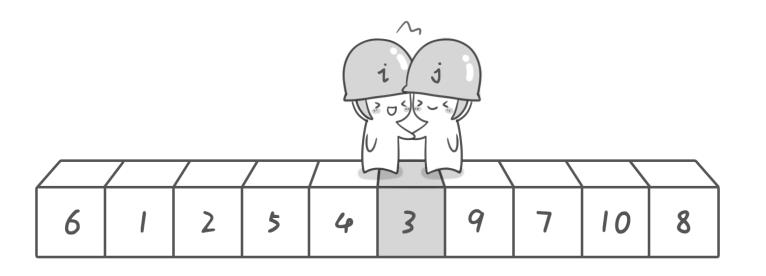
此时探测结束,我们将基准数6和3进行交换
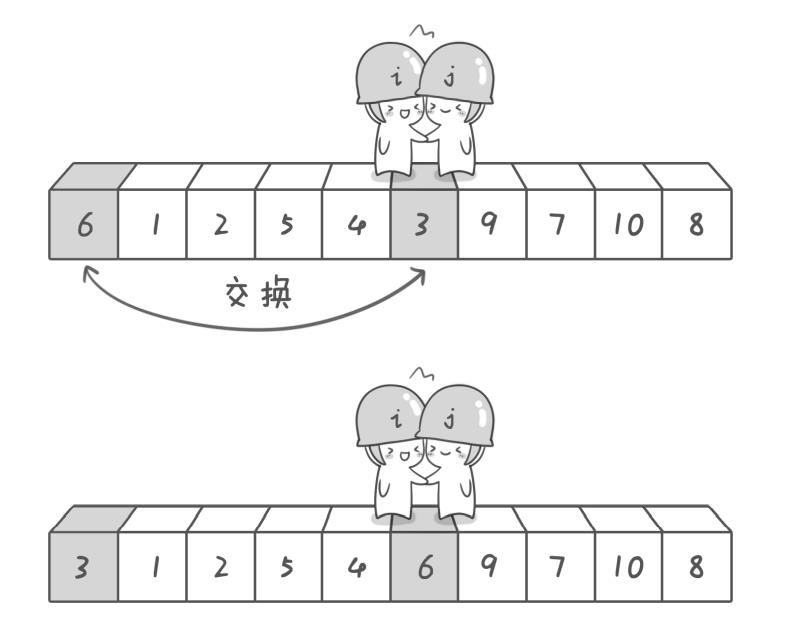
整个算法的处理过程图
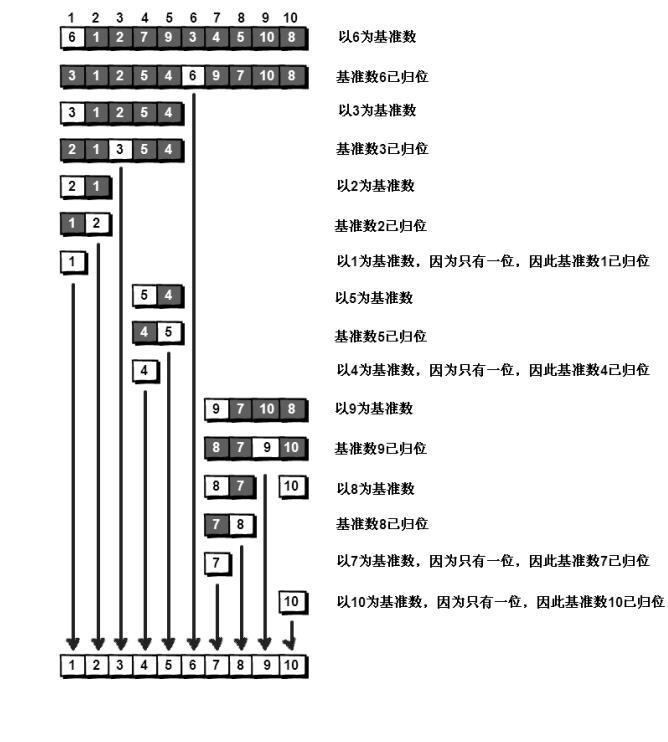
快速排序相比于冒泡排序,每次交换是跳跃式的,基于二分的思想。每次排序的时候设置一个基准点,将小于等于基准点的数放基准点左边,将大于等于基准点的数放基准点右边。
最坏的情况是相邻的两数进行交换,此时快速排序的时间复杂度是 O ( N 2 ) O(N^2) O(N2)(最差时间复杂度),平均时间复杂度是 O ( N l o g N ) O(Nlog_N) O(NlogN)
#include <stdio.h>
int a[101], n;
void quicksort(int left, int right)
int i, j, t, temp;
if (left > right)
return;
temp = a[left];
i = left;
j = right;
while (i != j)
while (a[j] >= temp && i < j)
j--;
while (a[i] <= temp && i < j)
i++;
if (i < j)
t = a[i];
a[i] = a[j];
a[j] = t;
a[left] = a[i];
a[i] = temp;
quicksort(left, i - 1);
quicksort(i + 1, right);
int main()
int i, j, t;
scanf("%d", &n);
for (i = 1; i <= n; i++)
scanf("%d", &a[i]);
quicksort(1, n);
for (i = 1; i <= n; i++)
printf("%d", a[i]);
getchar(); getchar();
return 0;
小哼买书
小哼的学校要建一个图书角,老师派小哼去找同学做调查,每本书有唯一的ISBN号,小哼需要完成去重和排序的工作。
输入2行,第1行表示有多少个同学参加调查(1 ~ 100),第2行表示图书的ISBN号(1 ~ 1000)。
输出2行,第1行表示需要买多少书,第2行表示从小到大已排序好的图书的ISBN号。
方法一:去重后排序
#include <stdio.h>
int main()
int a[1001], n, i, t;
for (i = 1; i <= 1000; i++)
a[i] = 0; // 初始化
scanf("%d", &n); // 读入n
for (i = 1; i <= n; i++)
scanf("%d", &t);
a[t] = 1; // 标记
for (i = 1; i <= 1000; i++)
if (a[i] == 1)
printf("%d", i);
getchar(); getchar();
return 0;
桶排序的时间复杂度: O ( N + M ) O(N+M) O(N+M)
方法二:排序后去重
#include <stdio.h>
int main()
int a[1001], n, i, t;
for (i = 1; i <= n; i++)
scanf("%d", &a[i]);
for (i = 1; i <= n - 1; i++)
for (j = 1; j <= n - i; j++)
if (a[j] > a[j + 1])
t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
printf("%d", a[i]);
for (i = 2; i <= n; i++)
if (a[i] != a[i - 1])
printf("%d", a[i]);
getchar(); getchar();
return 0;
时间复杂度: O ( N 2 ) O(N^2) O(N2)
栈、队列、链表
解密QQ号——队列
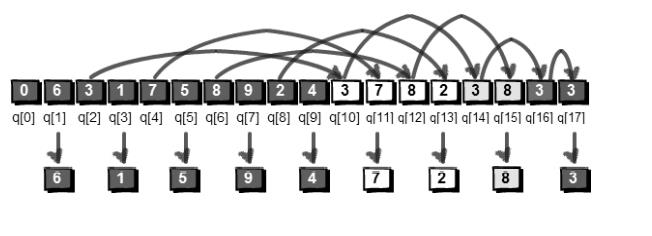
小哼向新同桌小哈询问QQ号,小哈给小哼一串加密过的数字6 3 1 7 5 8 9 2 4,解密规则是:首先将第1个数删除,接着将第2个数放到这串数的末尾,直到剩下最后一个数,将最后一个数也删除,按刚才删除的顺序,把这些删除的数连在一起就是小哈的QQ号了。

如何在数组中删除一个数?
最简单的方法:将后面的数都往前移动一位。
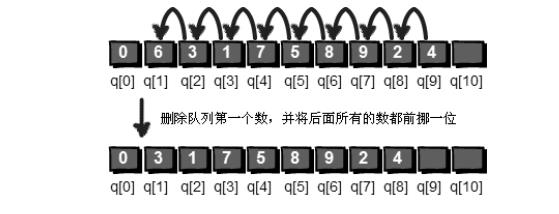
我们引入两个整型变量head和tail,head用来记录队列的队首(第一位),tail用来记录队列的队尾(最后一位)的下一个位置。我们这里规定队首和队尾重合时,队列为空。
我们将这9个数全部放入队列,head=1;tail=10;在队首删除一个数的操作是head++
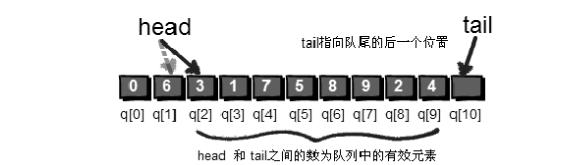
在队尾增加一个数x的操作是q[tail]=x;tail++
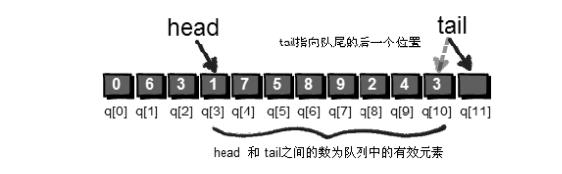
整个解密过程图
#include <stdio.h>
int main()
int q[102] = 0, 6, 3, 1, 7, 5, 8, 9, 2,4 , head, tail;
int i;
head = 1;
tail = 10;
while (head < tail) // 队列不为空
printf("%d", q[head]); // 打印队首并出队
head++;
q[tail] = q[head]; // 将队首贴加到队尾
tail++;
head++; // 再将队首出队
getchar(); getchar();
return 0;
队列:一种特殊的线性结构,只允许在队列的首部(head)进行删除操作,称为出队,队列的尾部(tail)进行插入操作,称为入队,当队列中没有元素是(head=tail)队列为空队列。
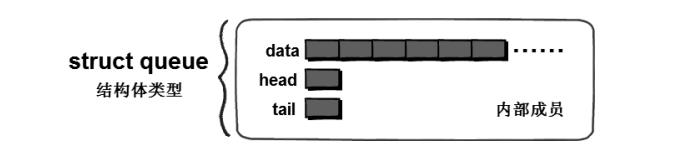
队列是我们今后学习广度优先搜索以及队列优化的Bellman-Ford 最短路算法的核心数据结构,我们将队列的三个基本元素(一个数组,两个变量)封装为一个结构体类型。
struct queue
int data[100]; // 队列的主体
int head; // 队首
int tail; // 队尾
;
定义结构体变量:
struct queue q;
访问结构体变量的内部成员
q.head = 1;
q.tail = 1;
scanf("%d", &q.data[q.tail]);
结构体实现的队列操作
#include <stdio.h>
struct queue
int data[100]; // 队列的主体
int head; // 队首
int tail; // 队尾
;
int main()
struct queue q;
int i;
q.head = 1;
q.tail = 1;
for (i = 1; i <= 9; i++)
scanf("%d", &q.data[q.tail]);
while (head < tail) // 队列不为空
printf("%d", q[head]); // 打印队首并出队
head++;
q[tail] = q[head]; // 将队首贴加到队尾
tail++;
head++; // 再将队首出队
getchar(); getchar();
return 0;
解密回文——栈
后进后出的数据结构——栈
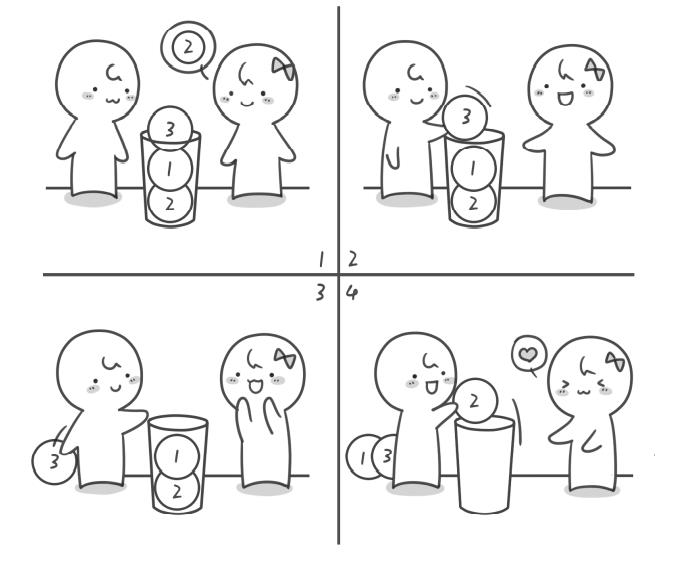
栈限定为只能在一端进行插入和删除操作,如:有一个小桶直径只能放一个小球,我们依次放入2、1、3号小球,如果你想要拿出2号小球,必须先将3号小球拿出,再拿出1号小球,最后才能将2号小球拿出。
栈的实现:一个一维数组和一个指向栈顶的变量top,我们通过top来对栈进行插入和删除操作。
如:xyzyx 是一个回文字符串,所谓回文字符是正读反读均相同的字符序列。
读取这行字符串,求出这个字符串的长度
char a[101];
int len;
gets(a);
len = strlen(a);
如果一个字符串是回文字符,那么它必须是中间对称的,所以我们求中点
mid = len / 2 - 1;
我们先将mid之前的字符全部入栈,char s[101]; ,初始化栈 top=0;。入栈的操作是top++;s[top]=x;(入栈的字符暂存字符变量x中),可简写s[++top]=x;。
for(i = 0; i <= mid; i++)
s[++top] = x;
代码实现
#include <stdio.h>
#include <string.h>
int main()
char a[101], s[101];
int i, len, mid, next, top;
gets(a); // 读入一行字符
len = strlen(a); // 求字符串长度
mid = len / 2 - 1; // 求字符串中点
top = 0; // 栈的初始化
for (i = 0; i <= mid; i++)
s[++top] = a[i];
if (len % 2 == 0) // 判断字符串长度是奇数还是偶数
next = mid + 1;
else
next = mid + 2;
for (i = next; i <= len - 1; i++)
if (a[i] != s[top])
break;
top--;
if (top == 0) // top为0,表示栈内所以字符都被一一匹配
printf("YES");
else
printf("NO");
getchar(); getchar();
return 0;
链表
如果需要在8前面插入一个6,无需像数组一样将8及后面的数都依次往后移一位,只需像下图一样

C语言中可以使用指针和动态分配内存函数 malloc来实现。
int *p; // 定义一个整型指针变量
指针作用:存储一个地址,存储一个内存空间的地址
p = &a; // &取地址符,整型指针p指向了整型变量a
通过指针p来输出变量a的值
#include <stdio.h>
int main()
int a = 10;
int *p;
p 以上是关于《啊哈!算法》的笔记的主要内容,如果未能解决你的问题,请参考以下文章