轻量级网络论文精度笔记:《Searching for MobileNetV3》
Posted ZZY_dl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了轻量级网络论文精度笔记:《Searching for MobileNetV3》相关的知识,希望对你有一定的参考价值。
MobileNetV3
论文链接
谷歌在2019年5月在arxiv上公开了MobileNetV3的论文,最近是发表在了ICCV 2019上
论文地址: https://arxiv.org/abs/1905.02244.pdf
项目地址:https://github.com/d-li14/mobilenetv3.pytorch
论文名字
《Searching for MobileNetV3》
参考文献
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 1314-1324
1. 研究背景

随着神经网络的发展,高效的神经网络在移动应用中正变得无处不在,从而实现了全新的设备上体验。它们还是个人隐私的关键促成因素,使用户无需将其数据发送到要评估的服务器即可获得神经网络的好处。神经网络效率的提高不仅可以通过更高的准确性和更低的延迟来改善用户体验,还可以通过降低功耗来帮助延长电池寿命。
本文描述了作者的开发MobileNetV3大型和小型模型的方法,以提供下一代高精度高效的神经网络模型来驱动设备上的计算机视觉。新的网络推动了STOA,并展示了如何将自动化搜索与新的体系结构进步结合起来,以构建有效的模型。
本文的目标是开发最佳的移动计算机视觉架构,以优化在移动设备上的精度-延迟之间的权衡。
2. 创新贡献
- 通过互补的搜索技术和新颖的架构设计提出了适用于高/低资源使用场景的 MobileNetV3 神经网络,并在目标检测和语义分割等任务上达到了优秀的性能表现,具有重要的实际意义。
- 提出了新的h-swish激活函数,避免了在量化时造成的数值精度的损失。
- 针对语义分割(或任何密集像素预测)任务,提出了一种新的高效分割解码器 Lite reduce Atrous Spatial Pyramid Pooling(LR-ASPP)。实现了移动端分类,检测和分割的最新SOTA成果。
- 性能表现:MobileNetV3 大模型在 ImageNet 分类任务上比 MobileNetV2 更准确,计算延迟降低 20%;MobileNetV3 精简模型比 MobileNetV2 更准确且延迟相当;MobileNetV3-Large 相对于 MobileNetV2 在 COCO 检测任务上提高 25% 的检测速度,在 Cityscapes 语义分割任务上表现也有所提升。
3. 相关工作
近年来,设计深度神经网络架构以在精度和效率之间实现最佳折衷一直是一个活跃的研究领域。新颖的手工结构和算法神经体系结构搜索在推进该领域方面都发挥了重要作用。
SqueezeNet 广泛使用带有压缩和扩展模块的1x1卷积,主要侧重于减少参数数量。最近的工作将重点从减少参数转移到减少操作数(MAdds)和实际测量的延迟。 MobileNetV1 使用深度可分离卷积来显着提高计算效率。 MobileNetV2 通过引入具有反向残差和线性瓶颈的资源有效块来对此进行扩展。 ShuffleNet 利用组卷积和信道随机操作进一步减少了MAdds。 CondenseNet 在训练阶段学习群卷积,以保持各层之间有用的密集连接,以供特征重用。 ShiftNet 提出了与逐点卷积交错的移位运算,以取代昂贵的空间卷积。
为了使架构设计过程自动化,首先引入了强化学习(RL)来搜索具有竞争力的准确性的高效架构。完全可配置的搜索空间可以成倍增长并且难以处理。因此,架构搜索的早期工作集中在单元级别的结构搜索上,并且同一单元在所有层中都可以重用。最近,探索了一个块级分层搜索空间,该空间允许在网络的不同分辨率块上使用不同的层结构。为了减少搜索的计算成本,在中使用可微体系结构搜索框架进行基于梯度的优化。专注于使现有网络适应受限的移动平台,提出了更有效的自动化网络简化算法。
量化是通过降低精度算法来提高网络效率的另一项重要补充工作。最后,知识蒸馏提供了一种额外的补充方法,可以在大型“教师”网络的指导下生成小型准确的“学生”网络。
3.1 高效移动端构建块
移动端模型通常建立在更多更加高效的构建blocks上。MobileNetV1引入深度可分离卷积作为传统卷积层的高效替换。Depthwise separable convolutions通过将空间滤波与特征生成机制分离,有效地分解了传统卷积计算。Depthwise separable convolutions的定义由两个分开的layer定义:用于空间滤波的轻量深度卷积和用于特征生成计算量高的1 × 1逐点卷积。
MobileNetV2引入了线性bottleneck和inverted-residual结构来构造更加高效的layer结构,利用了此问题的低秩特性。此结构如图3所示,定义为1 × 1扩展卷积接depthwise-convolutions和一个1 × 1projection-layer。

图1
当输入和输出的通道数相同时,由残差连接相连。这种结构在输入和输出处保持了紧凑表示,同时在内部扩展到更高维的特征空间,从而增加了每个通道非线性变换的表达能力。(“发散-集中”的应用)
MnasNet是基于MobileNetV2构建,将基于SE的注意力模块引入到bottleneck结构中,如图2所示。
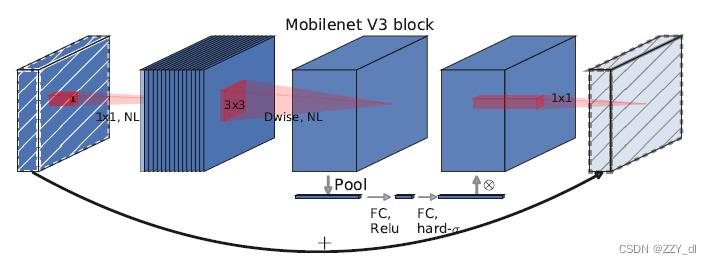
图2
对于MobileNetV3,本文使用这些层的组合作为构建块,以建立最高效的模型。这些层也使用了最新改进的Swish非线性算子。SE模块和Swish非线性算子都使用了Sigmoid函数,而Sigmoid函数计算效率较低,且难以在定点计算模式下保持精度,因此本文将其替换为Hard-Sigmoid函数,这一点将在章节5.2中探讨。
4. 网格搜索
平台感知NAS算法:是一种使用强化学习设计移动端模型的神经网络架构搜索算法。该算法整体流程包括一个基于递归神经网络(RNN)的控制器,一个获取模型精度的训练器及一个用于测量延迟基于手机的推理引擎。
对于MobileNetV3,我们首先使用平台感知NAS算法搜索全局网络架构,接着使用NetAdapt算法搜索每层卷积核个数。这两种算法相互补充,可以结合起来为给定硬件平台优化网络模型。 NAS算法流程图如图3所示。
 图3 NAS算法流程图
图3 NAS算法流程图
首先控制器会根据自身参数θ采样一系列超参𝛼_(1:𝑇) ,采样方法如下图所示,采样输入是来自上一次采样输出的结果。之后,训练器会根据超参生成网络并训练网络得到模型准确率ACC(m),同时模型也会被集成至目标移动平台测量推理延迟LAT(m)。将上述两指标相结合得到强化学习奖励信号:

搜索最佳神经网络架构的过程即最大化期望奖励的过程:

虽然奖励信号R不可微,但可以使用策略梯度去迭代更新θ:

本文使用MnasNet-A1(出自《Tan, M., & Le, Q. (2019). MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2820-2828)》)作为初始大移动端模型,结构如图4所示,然后在其之上使用NdetAdapt及其他算法进行优化。MnasNet-A1所使用的的奖励函数并没有针对小移动端模型进行优化。具体来说,MnasNet-A1使用多目标奖励函数ACC(m)×[LAT(m)/TAR]^w来逼近Pareto最优解。我们观察到,小模型的准确率对于延迟更加敏感,因此重新调整了权重系数w=−0.15(MnasNet-A1模型使用w=−0.07),以此来补偿延迟变换对准确率的影响。我们利用改进后的奖励函数进行网络架构搜索,然后使用NetAdapt及其他算法来优化MobileNetV3小模型。

图4 MnasNet-A1网络结构
作者在架构搜索中采用的第二个技术是NetAdapt算法。该算法是对平台感知NAS算法的补充:它对各层而非全局架构进行微调。该算法操作步骤如下:
- 利用平台感知NAS算法搜索种子网络架构。
- 本步骤包括以下三个部分:
- 生成一组建议。每个建议代表对网络架构的某种的修改,这种修改相对于上一个步骤,使模型在网络延迟上至少有δ的降低。
- 我们使用上一个步骤预训练好的模型,根据建议调整网络架构,并适当地截断及随机初始化丢失的权重。对于每个建议,我们使用T步进行模型微调,以此得到粗略的准确率估计。
- 根据某些指标选取最佳建议。
- 重复上一步,直至达到目标延迟。
对于本文实验,我们使用T = 10000 及δ = 0.1 |L|作为参数,其中L是种子模型的延迟。
5. 网络的改进
除网络搜索外,我们也引入了几种新组建用以优化最终模型。我们重新设计了网络输入输出中消耗运算资源较多的层。另外,我们也引入了新的非线性函数h−swish,它是swish的改进版,运算速度更快且对量化更友好。
5.1 重新设计计算复杂层
该方法的主要思路是将一些计算昂贵的层替换为更轻量级的替代层或者删减掉某些层,以降低模型的计算代价和模型大小。

图5 修改模块对比
作者首先改进了网络输出最后几层的结构。架构搜索的模型是基于MobileNetV2的倒瓶颈块及其变种组建,在最后一层使用了1×1卷积进行特征空间维度扩展。这一层用于丰富特征,对于模型预测至关重要,同时,它也会带来额外的延迟。
为了在减少延迟的同时保留高维度特征,我们将该层移动到平均池化层之外。最终,维度扩展是在1×1而非7×7的分辨率上进行。这样的设计与原始结构相比,特征扩展几乎不消耗运算资源及造成延迟。
通过Efficient Last Stage模块的设计使得模型在不损失精度的情况下,在网络的末端减少了三个计算复杂的层,极大的减少了计算量。具体来说,一旦降低了特征扩展的运算成本,那么之前瓶颈结构中的用于降低运算量的投影层也不再被需要。我们将上一个瓶颈结构的投影及滤波层同时移除,这样可以更进一步地降低运算复杂度。原始及优化后的结构如图5所示。优化后的模型,其延迟减少了7ms,大约是运行时间的11%,同时也减少了3000万次乘加操作,并且几乎没有损失准确率。详细结果见第6节。
另一个消耗运算资源较多的层是网络输入层。当前移动端模型的输入层倾向于使用32个3×3的全卷积滤波器进行图像边缘检测。我们实验了减少滤波器数目及使用不同非线性函数对模型的影响。最终,我们选择hard swish函数作为非线性函数,它与其他非线性函数具有同样优秀的性能。同时我们也发现,不管使用ReLU还是swish,在输入层使用16个滤波器与使用32个滤波器相同的准确率。这样可以减少2ms延迟及1000万次乘加操作。
5.2 设计Hard-Swish
swish作为ReLU的替代品可以显著地提高神经网络的准确率。该非线性函数定义如下:

尽管提高了准确率,但是在移动设备上运算sigmoid函数却需要消耗很多的运算资源。我们有两种方式来处理这个问题。
第一种:使用ReLU(x+3)/6来代替sigmoid
第二种:由于分辨率逐层减小,网络层次越深,非线性函数的运算资源消耗越低。我们实验发现,仅在更深的网络层中使用swish函数即可实现其大部分收益。因此,我们仅在模型的后半段使用h−swish函数。
 图6 Sigmoid和swish非线性和它的变体对比情况
图6 Sigmoid和swish非线性和它的变体对比情况
5.3 Large squeeze-and-excite
我们将瓶颈结构中压缩及激发的尺寸固定为扩展层通道数的1/4。这样做可以在不增加参数量的情况下提高准确率,并且几乎不会增加网络延迟。
5.4 MobileNetV3 Definitions
MobileNetV3有两种定义版本:MobileNetV3-Large及MobileNetV3-Small。这两种模型分别针对高资源及低资源的应用而设计。模型通过平台感知NAS算法及NetAdapt算法搜索而来并且结合了本节中所提出的改进方法。具体网络完整规格请参见表2和表3。
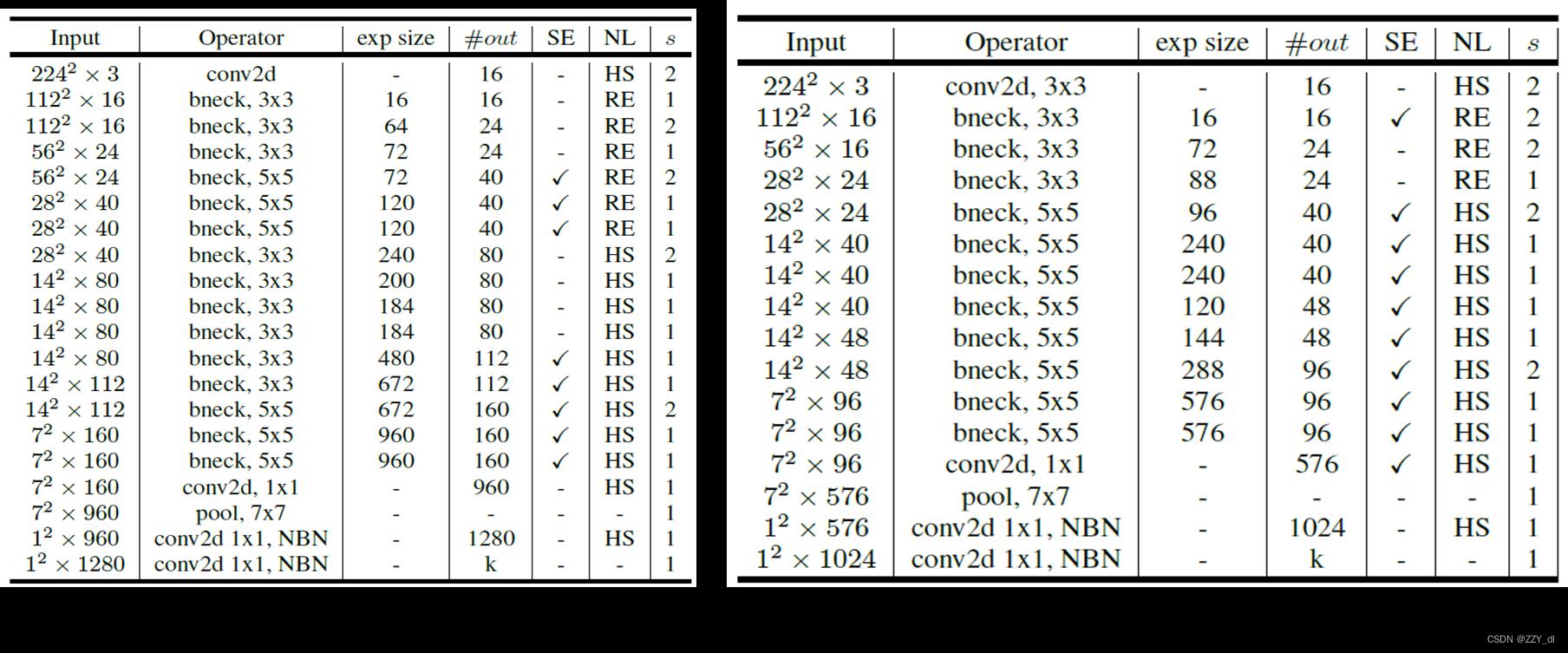 其中SE表示该块中是否存在挤压-激发。NL表示所使用的非线性类型。其中HS表示h-swish, RE表示ReLU。NBN表示没有批归一化。S表示步幅。exp size升维维数
其中SE表示该块中是否存在挤压-激发。NL表示所使用的非线性类型。其中HS表示h-swish, RE表示ReLU。NBN表示没有批归一化。S表示步幅。exp size升维维数
6.仿真分析
我们的实验结果证明了MobileNetV3的高效性。我们报告了有关分类,检测和分割任务的实验结果。同时也进行了控制变量分析,以研究不同设计决策对模型测试结果的影响。
6.1 分类
我们以ImageNet数据集为分类实验标准,比较了各种模型的准确率及资源消耗(例如延迟和乘加操作)。
6.1.1 训练设置
我们在4×4 TPU Pod上利用tensorflow框架同步训练模型,采用的优化器为0.9动量的RMSProp。我们使用的初始学习速率为0.1,批大小为4096(每个芯片处理128张图片),学习速率每3个epcho会减小0.01。我们也使用0.8比例的dropout并且在损失函数中加入了1e−5比例的l2正则化,然后采用Inception中相同的图像预处理方法。最后,我们对权重使用衰减系数为0.9999的指数滑动平均。所有的卷积层都使用了平均衰减系数为0.99的批标准化。
TPU Pod:是一组运行在谷歌数据中心中的服务器机架,每个机架都配备了谷歌的Tensor处理器单元(TPU)。
6.1.2 测量设置
我们在谷歌Pixel手机上,利用TFLite基准工具进行模型延迟测量。因为我们发现多核网络推理对于移动应用来说并不太实用,所以所有的测量都是在单线程大核中进行的。
6.2 仿真分析
6.2.1 仿真分析一

在表4中,作者分别对比了各个模型在不同Pixel系列手机上的浮点性能及量化性能。1.0为尺度因子,类似shfflenet,在0.5-1.0之间。Madds代表每百万次加法运算。P-1是对应的延迟。所有的延迟时间以毫秒计,并且使用单个大核心和批处理大小为一来进行测量。
6.2.2 仿真分析二

作者对比了各个模型在不同Pixel系列手机上的量化性能。所有的延迟都以毫秒为单位。推理延迟是使用相应的Pixel 1/2/3设备上的单个大核心进行测量的。
6.2.3 仿真分析三

在图7中,我们展示了MobileNetV3在不同乘数和分辨率下的性能权衡。注意到MobileNetV3-Small在乘数调整到几乎相同性能时比MobileNetV3-Large表现更好,性能提升近3%。另一方面,分辨率比乘数提供了更好的权衡。然而,需要注意的是,分辨率通常由问题所确定(例如,分割和检测问题通常需要更高的分辨率),因此不能总是用作可调参数。
6.2.4 仿真分析四

在h-swish@N中,N表示第一层启用h-swish的通道数。No-opt是指没有使用任何优化技术或加速方法。只使用了最基本的计算方式来计算卷积和非线性函数。这些优化技术可能包括降低数据精度、使用分组卷积、深度可分离卷积、使用线性瓶颈以及使用h-swish等。我们研究了h−swish函数在模型中的插入位置及优化实现方式对准确率和延迟的影响,结果表6所示,h−swish@N表示从通道数为N的层开始使用h−swish作为激活函数的MobileNetV3-Large 1.0模型。从表中我们可以看到,优化h−swish函数后,模型延迟降低了6ms(超过10%的运行时间)。优化h−swish函数的模型仅比传统ReLU函数的模型慢3ms。
6.2.5 仿真分析五
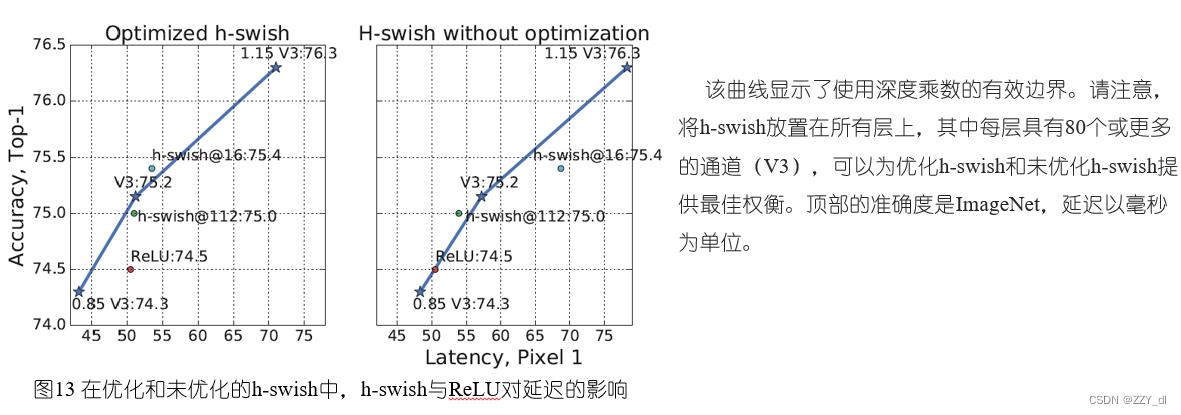
图13展示了基于非线性函数的选择和网络宽度所形成的有效边界。MobileNetV3在网络的中间层使用h-swish,并且明显优于ReLU。有趣的是,将h-swish添加到整个网络中都会稍稍优于插值的边界来扩展网络。
6.2.6 仿真分析六

在图14中展示了不同组件的引入如何沿着延迟/准确性曲线移动。
Compact相当于通过很多轻量级方法的汇总融合成一个轻量化网络,比如说将1×1卷积和3×3深度可分离卷积结合使用,或者使用一些本文设计的Efficient last stage等方法。所有的方法导致了V3优异的性能。
6.2.7 仿真分析七

我们使用MobileNetV3替代SSDLite中的主干特征提取器(VGG16),并在COCO数据集上与其他主干网络的SSDLite进行了比较。
+代表了在C4和C5之间的块中的通道数量减少了2倍,这是因为MobileNetV3的后几层是为1000种类别ImageNet数据集而设计,这对于90种类别的COCO数据集来说是冗余的。对于MobileNetV3-Large,C4是第13个瓶颈块的扩展层。对于MobileNetV3-Small,C4是第9个瓶颈块的扩展层。对于这两个网络,C5是紧接着池化层之前的层。
在COCO测试集上的结果在表7中给出。随着通道减少,MobileNetV3-Large比MobileNetV2快27%,mAP近乎相同。通过通道缩减,MobileNetV3-Small的mAP比MobileNetV2和MnasNet分别提高了2.4和0.5,同时比它们快35%。对于两个MobileNetV3模型,通道减少技巧导致延迟减少约15%,没有mAP损失,这表明Imagenet分类和COCO目标检测可能更喜欢不同的特征提取器形状。
6.2.8 仿真分析八
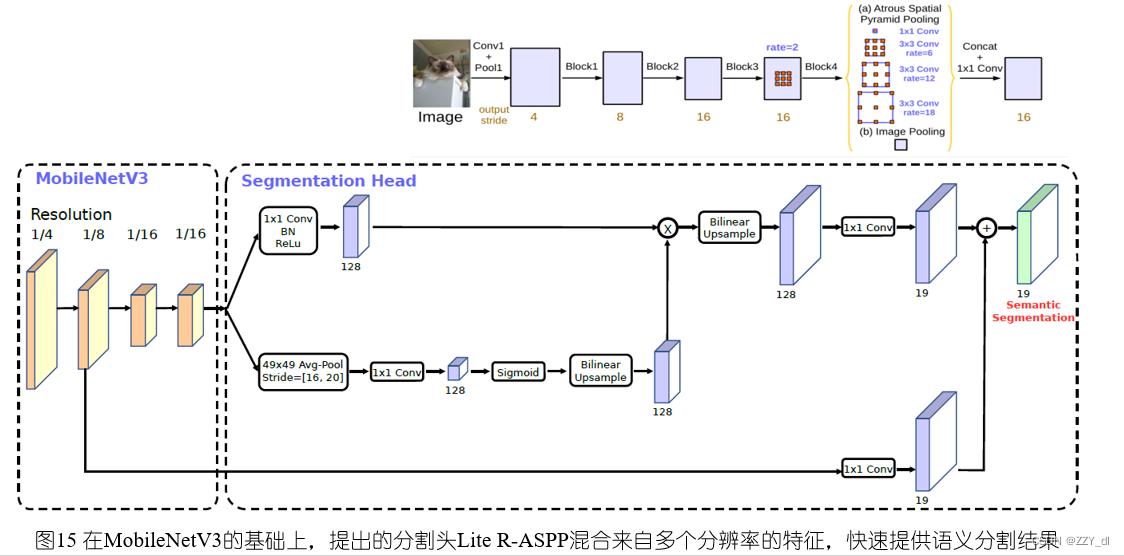
我们对比使用MobileNetV2及MobileNetV3作为主干网络的移动端语义分割模型。此外,我们还比较了两种分割头。第一种被称为R-ASPP,是ASPP的简化设计,仅包含1×1卷积及全局平均池化两个分支。在本文中,我们提出了另一种轻量级分割头,被称为Lite R-ASPP(或LR-ASPP),如下图所示。Lite R-ASPP是对R-ASPP的改进,它在全局平均池化分支中添加了类似压缩及激励的模块。我们在MobileNetV3的最后一个构建块中使用空洞卷积来提取更稠密的特征,并且在低级特征中添加跳接连线来捕获更详细的信息。
6.2.9 仿真分析九

在Cityscapes验证集上进行的语义分割结果。 RF2:将最后一个块中的过滤器数量减少一半。V2 0.5和V2 0.35分别是深度系数为0.5和0.35的MobileNetV2。SH:分割头部,其中采用R-ASPP,而X采用了提出的LR-ASPP。F:分割头部使用的过滤器数量。CPU(f):相对于完整分辨率输入(即1024×2048),在Pixel 3的单个大核心上测量的CPU时间(浮点数)。CPU(h):相对于一半分辨率输入(即512×1024)测量的CPU时间。第8行和第11行是我们的MobileNetV3分割候选项。
我们在表8中报告了Cityscapes的验证集结果。如表所示,我们观察到(1)将网络骨干最后一个块的通道数减少2倍可以显著提高速度,同时保持类似的性能(行1与行2,行5与行6),(2)提出的分割头LR-ASPP比R-ASPP略快,但性能提高了(行2与行3,行6与行7),(3)将分割头中的滤波器从256减少到128可以提高速度,但代价是略劣的性能(行3与行4,行7与行8),(4)在相同的设置时,MobileNetV3模型变体实现类似的性能,而比MobileNetV2略快(行1与行5,行2与行6,行3与行7,行4与行8),(5)MobileNetV3-Small实现了与MobileNetV2-0.5类似的性能,但更快,(6)MobileNetV3-Small比MobileNetV2-0.35显著更好,并带来类似的速度。
6.2.10 仿真分析十

OS:输出步幅,即输入图像空间分辨率与骨干输出分辨率的比率。当OS = 16时,在骨干的最后一个块中应用扩张卷积。当OS = 32时,不使用扩张卷积。MAdds(f):以全分辨率输入(即1024×2048)为参考,测量乘法-加法运算的数量。MAdds(h):以半分辨率输入(即512×1024)为参考,测量乘法-加法运算的数量。CPU(f):使用Pixel 3的单个大型核心(浮点)测量与全分辨率输入(即1024×2048)相关的CPU时间。CPU(h):与半分辨率输入(即512×1024)相关的CPU时间。ESPNet [31、32]和CCC2 [34]采用半分辨率输入,而我们的模型直接使用全分辨率输入。
表9显示了我们在Cityscapes测试集上的结果。我们的MobileNetV3作为网络骨干的分割模型在MAdds方面更快,比ESPNetv2,CCC2 和ESPNetv1 分别优于6.4%,10.6%和12.3%。当不使用扩张卷积来提取MobileNetV3最后一个块中的密集特征映射时,性能略有下降0.6%,但速度提高到1.98B(对于半分辨率输入),比ESPNetv2,CCC2和ESPNetv1分别快1.36,1.59和2.27倍。此外,我们的MobileNetV3-Small作为网络骨干的模型仍然优于它们所有,至少优于2.1%。
7.论文总结
本文介绍了MobileNetV3大型和小型模型,展示了移动分类、检测和分割的新的技术水平。本文描述了利用多种网络架构搜索算法以及网络设计的先进技术,实现下一代移动模型的交付。还展示了如何以量化友好且高效的方式调整swish等非线性,并应用挤压和激励,将它们引入移动模型域作为有效工具。本文还介绍了一种新型的轻量级分割解码器,称为LR-ASPP。虽然如何将自动搜索技术与人类直觉最好地融合仍是一个未解决的问题,但作者展示这些积极的初步结果,并将继续完善这些方法作为未来的工作,这是一个非常经典且值得借鉴的论文和工作。
论文笔记系列:轻量级网络-- RepVGG
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,通俗易懂,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。
RepVGG笔记
论文名称:RepVGG: Making VGG-style ConvNets Great Again
论文下载地址:https://arxiv.org/abs/2101.03697
参考代码:GitHub - DingXiaoH/RepVGG: RepVGG: Making VGG-style ConvNets Great Again
RepVGG概念介绍
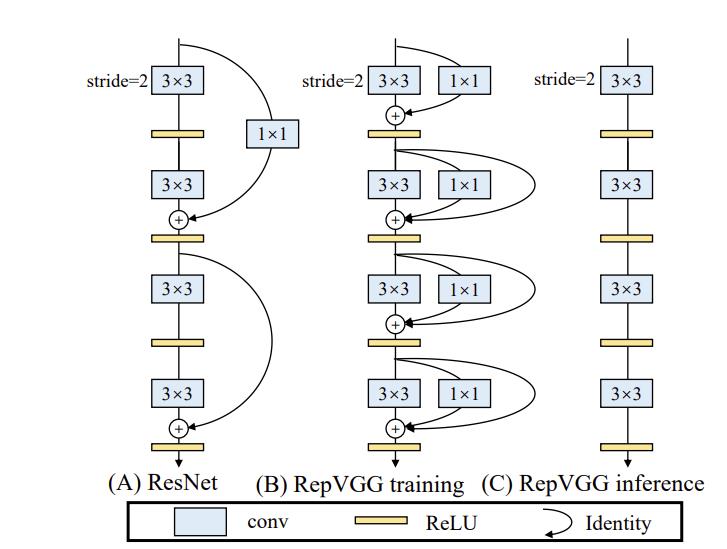
- RepVGG是一种简单的VGG式结构,大量使用3x3卷积,BN层,Relu激活函数,利用重参数化提升性能,准确率直逼其他SOTA网络,特点是训练时使用多分支网络,推理时融合多分支为单分支。主要解决原始VGG网络模型较大,不便于部署及性能较差提出VGG升级版本。
- 论文提出一种简单高效的卷积神经网络,该模型的推理结构类似于V G G \\rm VGGVGG,训练模型使用多分支结构。通过结构再参数化技术实现训练结构和推理结构的解耦,得到模型RepVGG。

RepVGG主要思路
(1)在VGG网络Block块中加入Identity和残差分支,相当于ResNet网络精华应用到VGG网络中;
(2)模型推理阶段,通过Op融合策略将所有的网络层都转换为Conv3*3,便于网络部署和加速。
RepVGG模型
RepVGG模型的整体结构:将20多层3x3卷积堆起来,分成5个stage,每个stage的第一层是stride=2的降采样,每个卷积层用ReLU作为激活函数。
RepVGG模型的详细结构:RepVGG-A的5个stage分别有[1, 2, 4, 14, 1]层,RepVGG-B的5个stage分别有[1, 4, 6, 16, 1]层,宽度是[64,128, 256, 512]的若干倍。
训练时,为每一个3x3卷积层添加平行的1x1卷积分支和恒等映射分支,构成一个RepVGG Block。借鉴ResNet的做法,区别在于ResNet是每隔两层或三层加一分支,RepVGG Block是每层都加。
部署时,我们将1x1卷积分支和恒等映射分支以及3x3卷积融合成一个3x3卷积达到单路结构的目的。
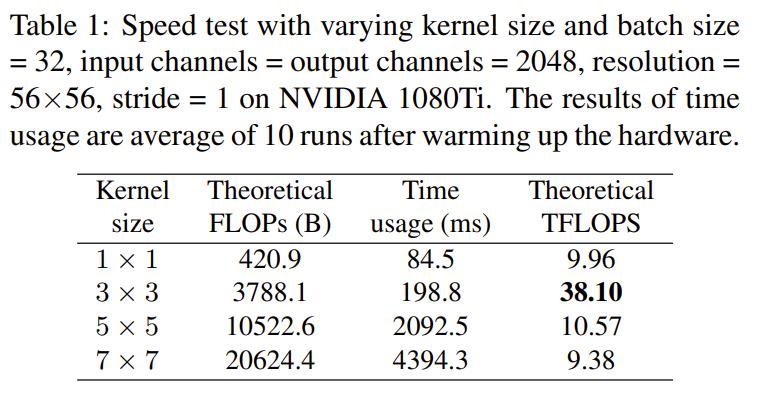
现有的计算库(如CuDNN,Intel MKL)和硬件针对3x3卷积有深度的优化,相比其他卷积核,3x3卷积计算密度更高,更加有效。
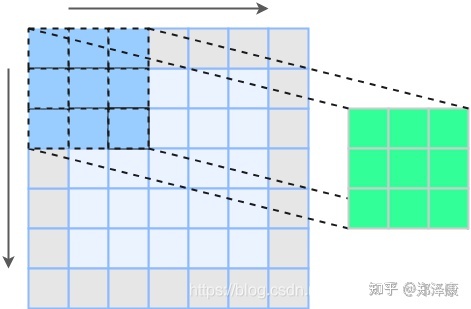
以残差块结构为例子,它有2个分支,其中主分支经过卷积层,假设前后张量维度相同,我们认为是一份显存消耗,另外一个旁路分支需要保存初始的输入结果,同样也是一份显存消耗,这样在运行的时候是占用了两份显存,直到最后一步将两个分支结果Add,显存才恢复成一份。而Plain结构只有一个主分支,所以其显存占用一直是一份。RepVGG主体部分只有一种算子:3x3卷积接ReLU。在设计专用芯片时,给定芯片尺寸或造价,我们可以集成海量的3x3卷积-ReLU计算单元来达到很高的效率。单路架构省内存的特性也可以帮我们少做存储单元.

多分支结构会引入网络结构的约束,比如Resnet的残差结构要求输入和卷积出来的张量维度要一致(这样才能相加),这种约束导致网络不易延伸拓展,也一定程度限制了通道剪枝。对应的单路结构就比较友好,剪枝后也能得到很好的加速比。
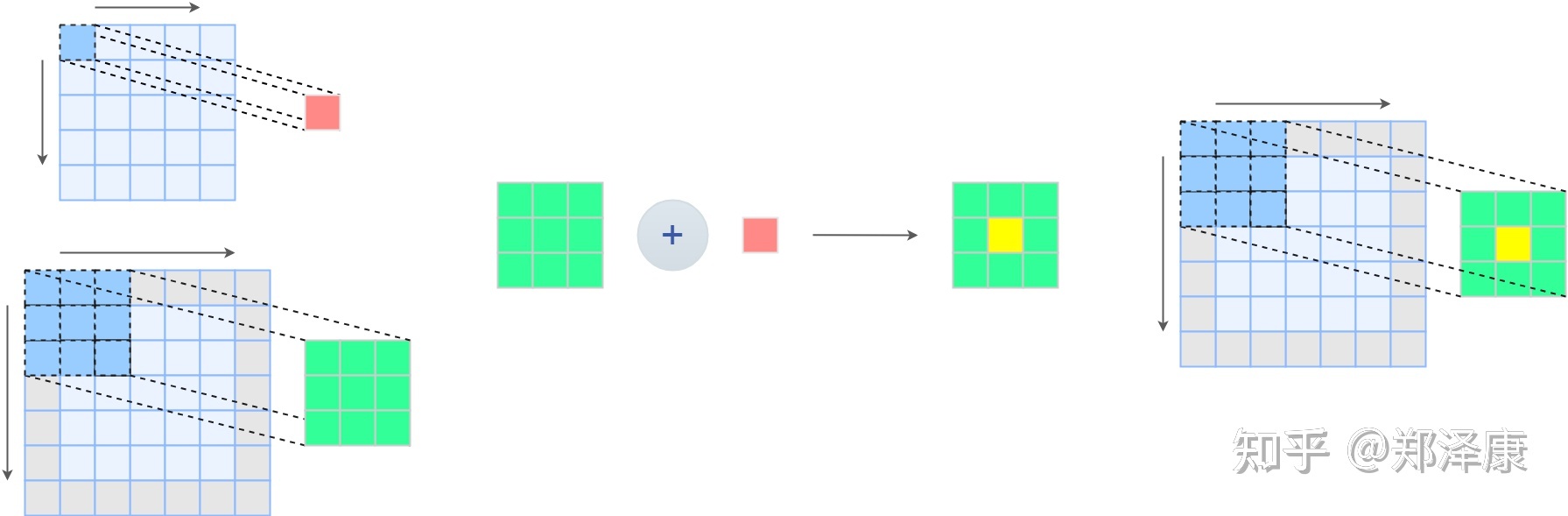
方法论:多分支融合
假设输入是5x5,stride=1
1x1卷积前后特征图大小不变

3x3卷积在原特征图补零,卷积前后特征图大小不变
将1x1卷积核加在3x3卷积核中间,就能完成卷积分支融合
融合示例图如下:
我们试想一下,输入与输出要相等,假设输入输出都是三通道
即每一个卷积核的通道数量,必须要求与输入通道数量一致,因为要对每一个通道的像素值要进行卷积运算,所以每一个卷积核的通道数量必须要与输入通道数量保持一致。

那么要保持原有三通道数据各权重应该如何初始化呢?
一个卷积核的尺寸为3x3x3,将对应通道的权重设为1其他为零,就能完好的保证输出原有值。
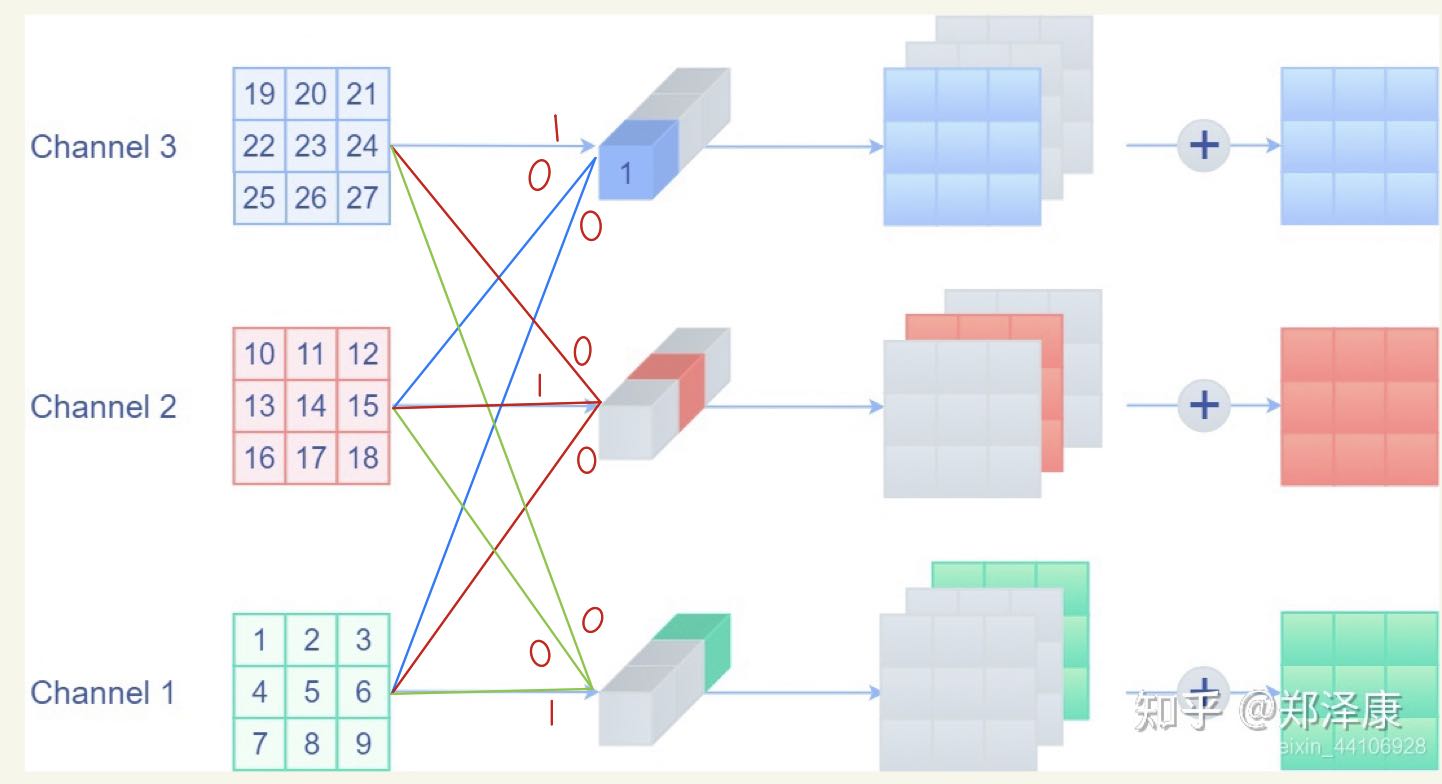
卷积+BN融合
在将identity分支和1x1卷积融合到3x3卷积后,我们将BN层融到卷积中去
Batch-Normalization (BN)是一种让神经网络训练更快、更稳定的方法(faster and more stable)。它计算每个mini-batch的均值和方差,并将其拉回到均值为0方差为1的标准正态分布。BN层通常在nonlinear function的前面/后面使用。
RepVGG的再参数化:

经过上述转换,我们可以得到一个3×3卷积,两个1 × 1 卷积和三个表示偏置的向量。然后,将三个偏置向量相加得到最后的偏置参数,然后使用零填充将1 × 1 卷积填充为3 × 3 大小,最后将所有3 × 3 大小的卷积相加,得到最后的卷积参数。

Architectural Specification

上图中的a和b 表示通道的缩放系数。
实验部分

基于不同a和b得到的RepVGG.
RepVGG for ImageNet Classification

Structural Re-parameterization is the Key

Ablation Studies

Comparison with variants and baselines

PyTorch实现RepVGG
RepVGG模块构建:
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
# 根据deploy决定构建训练模型还是推理模型
if deploy:
# 推理时仅有一个3x3卷积
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
else:
# 训练时包含一个恒等连接、一个3x3卷积核一个1x1卷积
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
print('RepVGG Block, identity = ', self.rbr_identity)
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
# 核和偏置的转换,具体实现在_fuse_bn_tensor函数
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
# 核和偏置合并
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1,1,1,1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
# 卷积层权重
kernel = branch.conv.weight
# μ
running_mean = branch.bn.running_mean
# σ
running_var = branch.bn.running_var
# BN层权重
gamma = branch.bn.weight
# BN层偏置
beta = branch.bn.bias
# BN层防止除零的参数
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
# 式(3),返回 W'和 b'
return kernel * t, beta - running_mean * gamma / std
def repvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()
return kernel.detach().cpu().numpy(), bias.detach().cpu().numpy(),
RepVGG主体部分构建:
class RepVGG(nn.Module):
def __init__(self, num_blocks, num_classes=1000, width_multiplier=None, override_groups_map=None, deploy=False):
super(RepVGG, self).__init__()
assert len(width_multiplier) == 4
self.deploy = deploy
self.override_groups_map = override_groups_map or dict()
assert 0 not in self.override_groups_map
self.in_planes = min(64, int(64 * width_multiplier[0]))
# 构建RepVGG的各阶段
self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1, deploy=self.deploy)
self.cur_layer_idx = 1
self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
self.gap = nn.AdaptiveAvgPool2d(output_size=1)
# 用于分类的全连接层
self.linear = nn.Linear(int(512 * width_multiplier[3]), num_classes)
def _make_stage(self, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
blocks = []
for stride in strides:
cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
blocks.append(RepVGGBlock(in_channels=self.in_planes, out_channels=planes, kernel_size=3,
stride=stride, padding=1, groups=cur_groups, deploy=self.deploy))
self.in_planes = planes
self.cur_layer_idx += 1
return nn.Sequential(*blocks)
def forward(self, x):
out = self.stage0(x)
out = self.stage1(out)
out = self.stage2(out)
out = self.stage3(out)
out = self.stage4(out)
out = self.gap(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
RepVGG构建用于分类和分割等任务的模型,并返回推理模型:
def whole_model_convert(train_model:torch.nn.Module, deploy_model:torch.nn.Module, save_path=None):
all_weights =
for name, module in train_model.named_modules():
# 条件语句判断不同形式的层
if hasattr(module, 'repvgg_convert'):
# 获得转换后的卷积层权重和偏置
kernel, bias = module.repvgg_convert()
# 加载权重
all_weights[name + '.rbr_reparam.weight'] = kernel
all_weights[name + '.rbr_reparam.bias'] = bias
print('convert RepVGG block')
else:
for p_name, p_tensor in module.named_parameters():
full_name = name + '.' + p_name
if full_name not in all_weights:
all_weights[full_name] = p_tensor.detach().cpu().numpy()
for p_name, p_tensor in module.named_buffers():
full_name = name + '.' + p_name
if full_name not in all_weights:
all_weights[full_name] = p_tensor.cpu().numpy()
# 加载权重
deploy_model.load_state_dict(all_weights)
if save_path is not None:
torch.save(deploy_model.state_dict(), save_path)
return deploy_model
调用
# 1. 构建基于RepVGG的任务模型,如这里构建PSPNet
# 调用流程如下:
###################### 1 ######################
train_backbone = create_RepVGG_B2(deploy=False)
train_backbone.load_state_dict(torch.load('RepVGG-B2-train.pth'))
train_pspnet = build_pspnet(backbone=train_backbone)
segmentation_train(train_pspnet)
###################### 2 ######################
# 2. 构建PSPNet的推理模型
deploy_backbone = create_RepVGG_B2(deploy=True)
deploy_pspnet = build_pspnet(backbone=deploy_backbone)
whole_model_convert(train_pspnet, deploy_pspnet)
segmentation_test(deploy_pspnet)
RepVGG转换成推理模型:
def repvgg_model_convert(model:torch.nn.Module, build_func, save_path=None):
converted_weights =
for name, module in model.named_modules():
if hasattr(module, 'repvgg_convert'):
kernel, bias = module.repvgg_convert()
converted_weights[name + '.rbr_reparam.weight'] = kernel
converted_weights[name + '.rbr_reparam.bias'] = bias
elif isinstance(module, torch.nn.Linear):
converted_weights[name + '.weight'] = module.weight.detach().cpu().numpy()
converted_weights[name + '.bias'] = module.bias.detach().cpu().numpy()
del model
deploy_model = build_func(deploy=True)
for name, param in deploy_model.named_parameters():
print('deploy param: ', name, param.size(), np.mean(converted_weights[name]))
param.data = torch.from_numpy(converted_weights[name]).float()
if save_path is not None:
torch.save(deploy_model.state_dict(), save_path)
return deploy_model
调用
# 构建模型
train_model = create_RepVGG_A0(deploy=False)
# 训练模型
train train_model
# 转换模型
deploy_model = repvgg_convert(train_model, create_RepVGG_A0, save_path='repvgg_deploy.pth')
参考文章与资料推荐:
RepVGG网络简介(强推)
论文阅读 | 轻量级网络之RepVGG_zhangts20的博客
RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大(CVPR-2021)
以上是关于轻量级网络论文精度笔记:《Searching for MobileNetV3》的主要内容,如果未能解决你的问题,请参考以下文章
EfficientDet : 快又准,EfficientNet作者在目标检测领域的移植 CVPR 2020
论文阅读笔记(七十)CVPR2021:Combined Depth Space based Architecture Search For Person Re-identification