为什么许多人吐槽C++11,那些语法值得我们学习呢?
Posted 终为nullptr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么许多人吐槽C++11,那些语法值得我们学习呢?相关的知识,希望对你有一定的参考价值。
致前行的人:
人生像攀登一座山,而找寻出路,却是一种学习的过程,我们应当在这过程中,学习稳定冷静,学习如何从慌乱中找到生机。

目录
1.C++11简介
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了
C++98称为C++11之前的最新C++标准名称。不过由于C++03(TC1)主要是对C++98标准中的漏洞
进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。
从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。相比C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多,所以我们要作为一个重点去学习。C++11增加的语法特性非常篇幅非常多,我们这里没办法一一讲解,所以本节课程主要讲解实际中比较实用的语法。
2.统一的列表初始化
2.1 {}初始化
在C++98中,标准允许使用花括号对数组或者结构体元素进行统一的列表初始值设定。比如:
struct Point
int _x;
int _y;
;
int main()
int array1[] = 1, 2, 3, 4, 5 ;
int array2[5] = 0 ;
Point p = 1, 2 ;
return 0;
C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自
定义的类型,使用初始化列表时,可添加等号(=),也可不添加。
struct Point
int _x;
int _y;
;
int main()
int x1 = 1;
int x2 2 ;
int array1[] 1, 2, 3, 4, 5 ;
int array2[5] 0 ;
Point p 1, 2 ;
// C++11中列表初始化也可以适用于new表达式中
int* pa = new int[4] 0 ;
return 0;
创建对象时也可以使用列表初始化方式调用构造函数初始化:
class Date
public:
Date(int year, int month, int day)
:_year(year)
, _month(month)
, _day(day)
cout << "Date(int year, int month, int day)" << endl;
private:
int _year;
int _month;
int _day;
;
int main()
Date d1(2022, 1, 1); // old style
// C++11支持的列表初始化,这里会调用构造函数初始化
Date d2 2022, 1, 2 ;
Date d3 = 2022, 1, 3 ;
return 0;
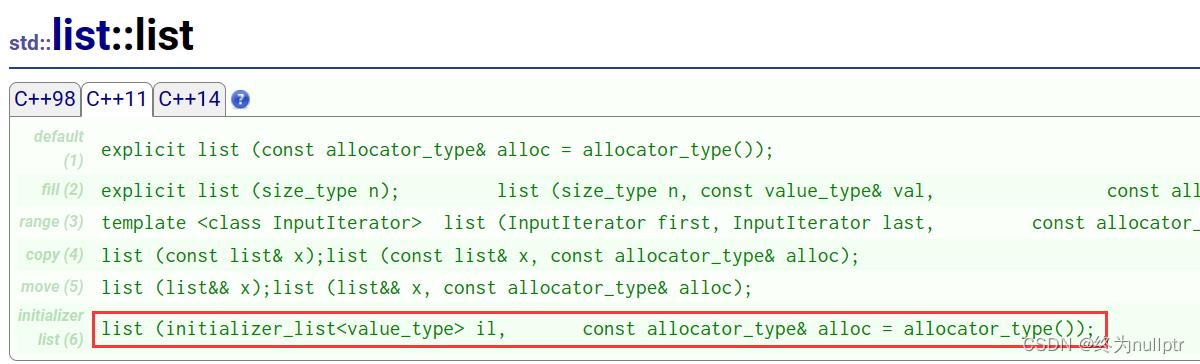
 2.2 std::initializer_list
2.2 std::initializer_list
std::initializer_list是什么类型:
int main()
// the type of il is an initializer_list
auto il = 10, 20, 30 ;
cout << typeid(il).name() << endl;
return 0;

std::initializer_list使用场景:
std::initializer_list一般是作为构造函数的参数,C++11对STL中的不少容器就增加
std::initializer_list作为参数的构造函数,这样初始化容器对象就更方便了。也可以作为operator=
的参数,这样就可以用大括号赋值。
例如:
int main()
vector<int> v1 = 1,2,3,4,5 ;
vector<int> v2 1,2,3,4,5 ;
list<int> l1 1,2 ;
map<string, string> dict = "string","字符串", "sort","排序" ;
return 0;
3. 声明
3.1 auto
在C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局
部的变量默认就是自动存储类型,所以auto就没什么价值了。C++11中废弃auto原来的用法,将
其用于实现自动类型推断,这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初
始化值的类型。
int main()
map<string, int> m;
auto it1 = m.begin();
cout << typeid(it1).name() << endl;
return 0;
运行截图:

3.2 decltype
关键字decltype将变量的类型声明为表达式指定的类型。
// decltype的一些使用使用场景
template<class T1, class T2>
void F(T1 t1, T2 t2)
decltype(t1 * t2) ret;
cout << typeid(ret).name() << endl;
int main()
const int x = 1;
double y = 2.2;
decltype(x * y) ret; // ret的类型是double
decltype(&x) p; // p的类型是int*
cout << typeid(ret).name() << endl;
cout << typeid(p).name() << endl;
F(1, 'a');
return 0;
运行截图:

3.3nullptr
由于C++中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示
整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif4 范围for循环
容器支持迭代器之后,编译器自动识别范围for,替换为迭代器进行遍历:
int main()
vector<int> v 1,2,3,4,5 ;
for (auto& e: v)
cout << e << " ";
cout << endl;
return 0;
运行截图:

5.STL中一些变化
在C++11更新之后,对C++STL进行了修改,包括增加了一些容器和对原来存在的容器新增了新的接口函数。
新容器:
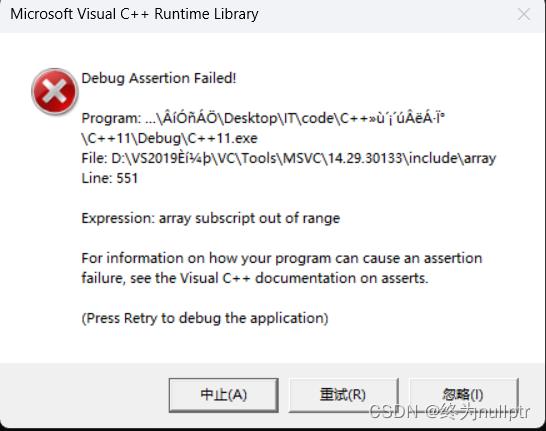
1.array:是针对C语言中数组越界检查不严格所出的,C语言数组越界检查是抽查,而array数组越界严格检查,当出现越界读或者越界写的时候就会抛异常:
int main()
array<int, 10> a;
a[10]; //越界读
a[10] = 0 ; //越界写
return 0;
运行截图:
容器中的一些新方法
如果我们再细细去看会发现基本每个容器中都增加了一些C++11的方法,但是其实很多都是用得
比较少的。比如提供了cbegin和cend方法返回const迭代器等等,但是实际意义不大,因为begin和end也是可以返回const迭代器的,这些都是属于锦上添花的操作。
实际上C++11更新后,容器中增加的新方法最有用的插入接口函数的右值引用版本:
但是这些接口到底意义在哪?网上都说他们能提高效率,他们是如何提高效率的?
请看下面的右值引用和移动语义章节的讲解。另外emplace还涉及模板的可变参数,也需要再继
续深入学习后面章节的知识。
6 右值引用和移动语义
6.1 左值引用和右值引用
传统的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以从现在开始我们
之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
什么是左值?什么是左值引用?
左值是一个表示数据的表达式(如变量名或解引用的指针),可以获取它的地址,并且可以给它进行赋值,左值可以出现在赋值符号的左边,右值不能出现在左边。定义时const修饰的左值,不能给它赋值,但是可以取它的地址,左值引用就是给左值取别名。
int main()
//以下的p b c *p都是左值:
int* p = new int(0);
int b = 1;
const int c = 1;
//以下几个是对上面左值的引用:
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pValue = *p;
return 0;
什么是右值?什么是右值引用?
右值也是一个表示数据的表达式,如字面常量,表达式返回值,函数返回值(这个不能是左值引用返回)等等。右值可以出现在赋值符号的右边,但是不能出现在赋值符号的左边,右值不能取地址(右值是不能够被修改的)。右值引用就是对右值取别名。
int main()
double x = 1.1;
double y = 2.2;
//以下几个是常见的右值:
10;
x + y;
fmin(x, y);
//以下几个都是对右值的引用:
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
return 0;
需要注意的右值是不能取地址的,但是给右值取别名之后,会导致右值被存储到特定位置,且可
以取到该位置的地址,也就是说例如:不能取字面量10的地址,但是rr1引用后,rr1就具有了左值属性,可以对rr1取地址,也可以修改rr1。如果不想rr1被修改,可以用const int&& rr1 去引用,是不是感觉很神奇,这个了解一下,实际中右值引用的使用场景并不在于此,这个特性也不重要。
int main()
double x = 1.1, y = 2.2;
int&& rr1 = 10;
const double&& rr2 = x + y;
rr1++;
rr2++; //err
return 0;
运行截图:
6.2 左值引用与右值引用比较
左值引用总结:
1.左值引用只能引用左值,不能引用右值
2.但是const左值既可以引用左值,也可以引用右值
int main()
//左值只能引用左值,不能引用右值
int a = 10;
int& ra1 = a;
//int& ra2 = 10; //err,因为10是左值
//const左值既可以引用左值也可以引用右值
const int& ra3 = 10;
const int& ra4 = a;
return 0;
右值引用总结:
1.右值引用只能引用右值,不能引用左值
2.右值可以引用move后的左值
int main()
//右值引用只能引用右值,不能引用左值
int&& r1 = 10;
int a = 10;
//int&& r2 = a; // error C2440: “初始化”: 无法从“int”转换为“int &&”
//右值引用可以引用move以后的左值
int&& r3 = move(a);
return 0;
6.3 右值引用使用场景和意义
前面我们可以看到左值引用既可以引用左值和又可以引用右值,那为什么C++11还要提出右值引
用呢?是不是画蛇添足呢?下面我们来看看左值引用的短板,右值引用是如何补齐这个短板的!
namespace ns
class string
public:
typedef char* iterator;
iterator begin()
return _str;
iterator end()
return _str + _size;
string(const char* str = "")
:_size(strlen(str)),
_capacity(_size)
cout << "string(char* str)" << endl;
_str = new char[_capacity + 1];
strcpy(_str, str);
void swap(string& s)
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
string(const string&s)
:_str(nullptr)
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str);
swap(tmp);
string& operator=(const string& s)
cout << "string& operator=(string s) -- 深拷贝" << endl;
string tmp(s);
swap(tmp);
return *this;
~string()
delete[] _str;
_str = nullptr;
char& operator[](size_t pos)
return _str[pos];
void reserve(size_t n)
if (n > _capacity)
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
void push_back(char ch)
if (_size >= _capacity)
int newCapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newCapacity);
_str[_size] = ch;
++_size;
_str[_size] = '\\0';
string& operator+=(char ch)
push_back(ch);
return *this;
const char* c_str() const
return _str;
private:
char* _str;
int _size;
int _capacity;
;
左值引用的使用场景:
做参数和做返回值都可以提高效率。
void func1(ns::string& s)
int main()
ns::string s1("hello world");
func1(s1);
// string operator+=(char ch) 传值返回存在深拷贝
// string& operator+=(char ch) 传左值引用没有拷贝提高了效率
s1 += '!';
return 0;
左值引用的短板:
但是当函数返回对象是一个局部变量,出了函数作用域就不存在了,就不能使用左值引用返回,
只能传值返回。
例如:在下面这个函数整数转字符串中,只能传值返回,传值返回则至少会存在一次拷贝构造(编译器优化后的结果)
ns::string to_string(int value)
bool flag = true;
if (value < 0)
flag = false;
value = -value;
string str;
while (value > 0)
int x = value % 10;
value /= 10;
str += ('0' + x);
if (flag == false)
str += '-';
reverse(str.begin(), str.end());
return str;
int main()
ns::string str = ns::to_string(1234);
return 0;


当函数返回的是一个局部对象,出了函数作用域就不存在了,把这种值称为将亡值,不能用左值引用返回,针对这种问题右值引用就可以解决:
解决方式:增加移动构造,移动构造的本质是将参数右值的资源窃取过来,占位己有,那么就不用做深拷贝了,所以它叫移动构造,就是窃取别人的资源构造自己。
//移动构造
string(string&& s)
:_str(nullptr),
_size(0),
_capacity(0)
cout << "string(string&& s) -- 移动语义" << endl;
swap(s);
再运行时,就没有调用深拷贝的拷贝构造,而是调用了移动构造,移动构造中没有开辟新空间。拷贝数据,所以效率提高了
运行截图:

不仅仅有移动构造,还有移动赋值:
//移动赋值:
string& operator=(string&& s)
cout << "string& operator=(string&& s) -- 移动语义" << endl;
swap(s);
return *this;
运行截图:

这里运行后,我们看到调用了一次移动构造和一次移动赋值。因为如果是用一个已经存在的对象
接收,编译器就没办法优化了。ns::to_string函数中会先用str生成构造生成一个临时对象,但是
我们可以看到,编译器很聪明的在这里把str识别成了右值,调用了移动构造。然后在把这个临时
对象做为ns::to_string函数调用的返回值赋值给str,这里调用的移动赋值。
6.4 右值引用引用左值及其一些更深入的使用场景分析
按照语法,右值引用只能引用右值,但右值引用一定不能引用左值吗?因为:有些场景下,可能
真的需要用右值去引用左值实现移动语义。当需要用右值引用引用一个左值时,可以通过move
函数将左值转化为右值。C++11中,std::move()函数位于utility头文件中,该函数名字具有迷惑性,它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义。
int main()
ns::string s1("hello world");
//s1是左值,调用拷贝构造
ns::string s2(s1);
//当把s1 move处理之后,会被当成右值调用移动构造
ns::string s3(move(s1));
return 0;
注:一般不建议这样使用,因为调用移动构造是将s1的资源换给s3了,s1被置空了,如图所示:

STL容器插入接口函数也增加了右值引用版本:
如图所示:


int main()
list<ns::string>lt;
ns::string s1("111111");
//调用拷贝构造:
lt.push_back(s1);
//调用移动构造:
lt.push_back(ns::string("222222"));
//调用移动构造:
lt.push_back("333333");
return 0;
运行截图:

模拟实现list的右值引用版本的插入:
//结点构造
list_node(T&& val)
:_next(nullptr),
_prev(nullptr),
_data(move(val))
;
//push_back:
void push_back(T&& val)
insert(end(), move(val));
//insert:
iterator insert(iterator pos, T&& val)
node* newnode = new node(move(val));
node* cur = pos._pnode;
node* prev = cur->_prev;
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
_size++;
return iterator(newnode);
注:右值在传给下一层的时候,属性变为右值,所以用move以后的左值向下传递
int main()
lt::list<ns::string> lt;
ns::string s1("1111");
// 这里调用的是拷贝构造
lt.push_back(s1);
// 下面调用都是移动构造
lt.push_back("2222");
lt.push_back(std::move(s1));
return 0;
运行截图:

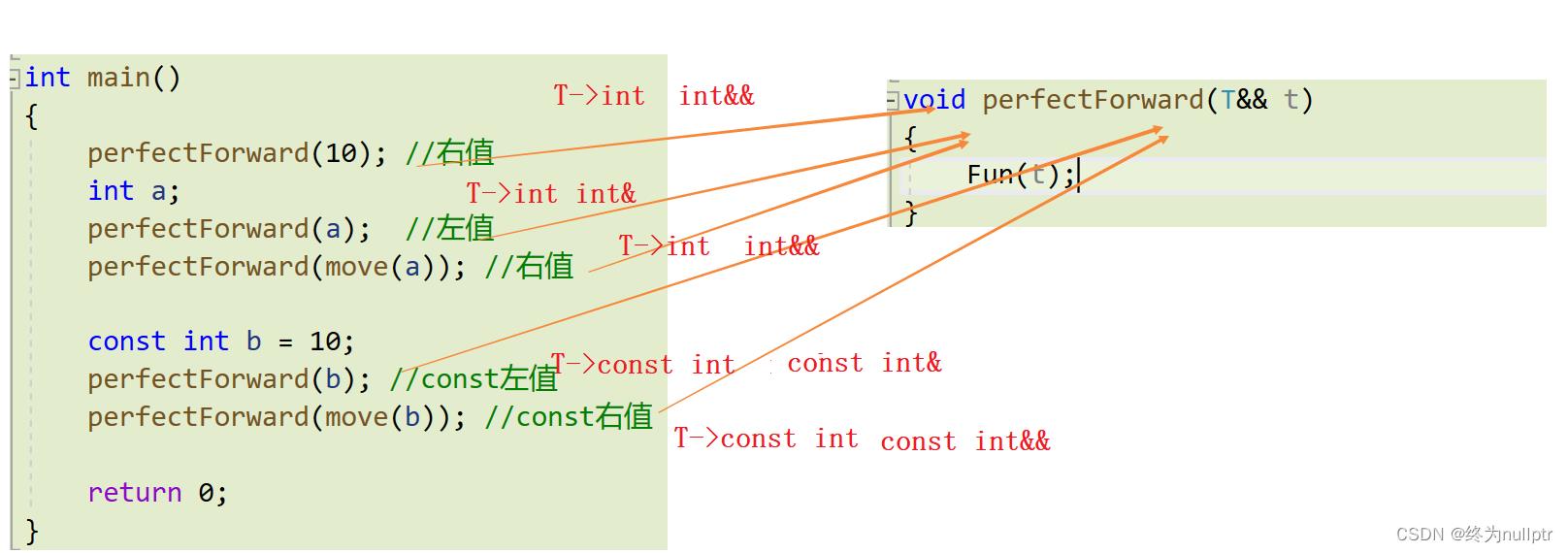
6.5完美转发
模板中的&& 万能引用
模板中的&&不代表右值引用,而是代表万能引用,既能接受左值,又能接受右值
template<class T>
void perfectForward(T&& t)
int main()
perfectForward(10); //右值
int a;
perfectForward(a); //左值
perfectForward(move(a)); //右值
const int b = 10;
perfectForward(b); //const左值
perfectForward(move(b)); //const右值
return 0;
运行截图:

模板中的万能引用只提供了能够同时接受左值和右值的能力,后续在使用的时候都退化为左值属性
void Fun(int&& x) cout << "右值引用" << endl;
void Fun(const int&& x) cout << "const 右值引用" << endl;
template<class T>
void perfectForward(T&& t)
Fun(t);
运行截图:

如何在传递过程中保持它的左值或者右值属性,就需要通过完美转发来解决:
std::forward 完美转发在传参的过程中保留对象原生类型属性
void Fun(int& x) cout << "左值引用" << endl;
void Fun(const int& x) cout << "const 左值引用" << endl;
void Fun(int&& x) cout << "右值引用" << endl;
void Fun(const int&& x) cout << "const 右值引用" << endl;
template<class T>
void perfectForward(T&& t)
//forward<T>在传参的时候保持t的原有属性
Fun(forward<T>(t));
int main()
perfectForward(10); //右值
int a;
perfectForward(a); //左值
perfectForward(move(a)); //右值
const int b = 10;
perfectForward(b); //const左值
perfectForward(move(b)); //const右值
return 0;
运行截图:

通过万能引用就可以解决list中插入的时候右值属性改变的问题:
//结点构造
list_node(T&& val)
:_next(nullptr),
_prev(nullptr),
_data(forward<T>(val))
;
//push_back:
void push_back(T&& val)
insert(end(), forward<T>(val));
//insert:
iterator insert(iterator pos, T&& val)
node* newnode = new node(forward<T>(val));
node* cur = pos._pnode;
node* prev = cur->_prev;
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
_size++;
return iterator(newnode);
注:右值引用也被称为是折叠引用,如图所示:
7.新的类功能
默认成员函数:
原来C++中,有6个默认成员函数,构造函数,析构函数,拷贝构造函数,赋值重载函数,取地址重载和const取地址重载。在C++11中新增了两个默认成员函数,移动构造函数和移动赋值重载函数。
针对移动构造函数和移动赋值重载函数需要注意以下几点:
如果自己没有实现移动构造函数,且没有实现析构函数,拷贝构造,拷贝赋值重载函数中的任意一个,那么编译器默认会生成一个移动构造函数。默认的移动构造函数,对于内置类型会按字节拷贝,自定义类型的成员,看这个成员是否实现了移动构造,如果实现了则调用移动构造,没有实现则调用拷贝构造函数
如果你没有自己实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动赋值。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默认移动赋值跟上面移动构造完全类似)
如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
class Person
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
/*Person(const Person& p)
:_name(p._name)
,_age(p._age)
*/
/*Person& operator=(const Person& p)
if(this != &p)
_name = p._name;
_age = p._age;
return *this;
*/
/*~Person()
*/
private:
ns::string _name;
int _age;
;
int main()
Person s1;
Person s2 = s1;
Person s3 = std::move(s1);
Person s4;
s4 = std::move(s2);
return 0;
运行截图:
 强制生成默认函数的关键字default:
强制生成默认函数的关键字default:
C++11可以让你更好的控制要使用的默认函数。假设你要使用某个默认的函数,但是因为一些原
因这个函数没有默认生成。比如:我们提供了拷贝构造,就不会生成移动构造了,那么我们可以
使用default关键字显示指定移动构造生成。
class Person
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
Person(const Person& p)
:_name(p._name)
, _age(p._age)
Person(Person && p) = default;
private:
ns::string _name;
int _age;
;
int main()
Person s1;
Person s2 = s1;
Person s3 = std::move(s1);
return 0;
运行截图:

禁止生成默认函数的关键字delete:
假设某个类对象不让支持拷贝,该如何实现呢?
思路1:在C++98中,可以将拷贝构造函数声明为私有,外部就不能在调用拷贝构造函数,但是函数内部任然可以调用拷贝构造函数,所以可以将拷贝构造函数只声明不实现,此时调用拷贝构造函数就会有错误:
class A
public:
void func()
A tmp(*this);
A()
~A()
delete[] p;
private:
A(const A&& aa); //只声明不实现
int* p = new int[10];
;
int main()
A aa1;
aa1.func();
A aa2(aa1);
return 0;
运行截图:

思路2:在C++11中,对于这种不想让外面拷贝构造的函数用delete修饰,再调用的时候直接报错
class A
public:
void func()
A tmp(*this);
A()
~A()
delete[] p;
A(const A&& aa) = delete;
private:
int* p = new int[10];
;
int main()
A aa1;
aa1.func();
A aa2(aa1);
return 0;
运行截图:

8.lambda表达式
在C++98中,如果想要对一个数据集合中的元素进行排序,可以使用std::sort方法。
#include <algorithm>
#include <functional>
int main()
int array[] = 4,1,8,5,3,7,0,9,2,6 ;
// 默认按照小于比较,排出来结果是升序
std::sort(array, array + sizeof(array) / sizeof(array[0]));
for (auto& e : array)
cout << e << " ";
cout << "\\n";
// 如果需要降序,需要改变元素的比较规则
std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());
for (auto& e : array)
cout << e << " ";
cout << "\\n";
return 0;
运行截图:

如果待排序元素为自定义类型,需要用户定义排序时的比较规则:
struct Goods
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
;
struct ComparePriceLess
bool operator()(const Goods& gl, const Goods& gr)
return gl._price < gr._price;
;
struct ComparePriceGreater
bool operator()(const Goods& gl, const Goods& gr)
return gl._price > gr._price;
;
int main()
vector<Goods> v = "苹果", 2.1, 5 , "香蕉", 3, 4 , "橙子", 2.2,
3 , "菠萝", 1.5, 4 ;
sort(v.begin(), v.end(), ComparePriceLess());
for (const auto& e : v)
cout << e._name << " " << e._price << " " << e._evaluate << " ";
cout << endl;
cout << endl;
sort(v.begin(), v.end(), ComparePriceGreater());
for (const auto& e : v)
cout << e._name << " " << e._price << " " << e._evaluate << " ";
cout << endl;
cout << endl;
运行截图:

随着C++语法的发展,人们开始觉得上面的写法太复杂了,每次为了实现一个algorithm算法,
都要重新去写一个类,如果每次比较的逻辑不一样,还要去实现多个类,特别是相同类的命名,
这些都给编程者带来了极大的不便。因此,在C++11语法中出现了lambda表达式。
lambda表达式
int main()
vector<Goods> v = "苹果", 2.1, 5 , "香蕉", 3, 4 , "橙子", 2.2,
3 , "菠萝", 1.5, 4 ;
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)
return g1._price < g2._price; );
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)
return g1._price > g2._price; );
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)
return g1._evaluate < g2._evaluate; );
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)
return g1._evaluate > g2._evaluate; );
上述代码就是使用C++11中的lambda表达式来解决,可以看出lambda表达式实际是一个匿名函
数。
8.1lambda表达式语法
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type statement
1. lambda表达式各部分说明
[capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
statement:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
注意:
在lambda函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为
空。因此C++11中最简单的lambda函数为:[]; 该lambda函数不能做任何事情。
int main()
// 最简单的lambda表达式, 该lambda表达式没有任何意义
[] ;
int a = 3, b = 4;
auto add = [] (int x,int y)return x + y; ;
cout << add(a, b) << endl;
//交换两个数:引用捕捉
int x = 20, y = 10;
auto swap = [&x,&y]() mutable
int tmp = x;
x = y;
y = tmp;
;
swap();
cout << "x = " << x << " " << "y = " << y << endl;
//混合捕捉:
auto fun = [=, &y]() return a + y; ;
cout << fun() << endl;
return 0;
运行截图:

通过上述例子可以看出,lambda表达式实际上可以理解为无名函数,该函数无法直接调用,如果想要直接调用,可借助auto将其赋值给一个变量。
2. 捕获列表说明
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式传值还是传引用。
[var]:表示值传递方式捕捉变量var
[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
[&var]:表示引用传递捕捉变量var
[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
[this]:表示值传递方式捕捉当前的this指针
注意:
a. 父作用域指包含lambda函数的语句块,编译器向上查找。
b. 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。
比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量
[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
c. 捕捉列表不允许变量重复传递,否则就会导致编译错误。
比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
d. 在块作用域以外的lambda函数捕捉列表必须为空。
e. 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。
f. lambda表达式之间不能相互赋值,即使看起来类型相同
void (*PF)();
int main()
auto f1 = [] cout << "hello world" << endl; ;
auto f2 = [] cout << "hello world" << endl; ;
//f1 = f2; // 编译失败--->提示找不到operator=()
// 允许使用一个lambda表达式拷贝构造一个新的副本
auto f3(f2);
f3();
// 可以将lambda表达式赋值给相同类型的函数指针
PF = f2;
PF();
return 0;
运行截图:

8.2 函数对象与lambda表达式
函数对象,又称为仿函数,即可以像函数一样使用的对象,就是在类中重载了operator()运算符的函数对象
class Rate
public:
Rate(double rate)
:_rate(rate)
double operator()(double money, int year)
return money * year * _rate;
private:
double _rate;
;
int main()
//函数对象:
double rate = 0.49;
Rate r1(rate);
r1(1000, 2);
//lambda表达式:
auto r2 = [=](double money, int year)->double
return money * rate * year;
;
r2(2000, 3);
return 0;
从使用方式上来看,函数对象与lambda表达式完全一样。
函数对象将rate作为其成员变量,在定义对象时给出初始值即可,lambda表达式通过捕获列表可
以直接将该变量捕获到。
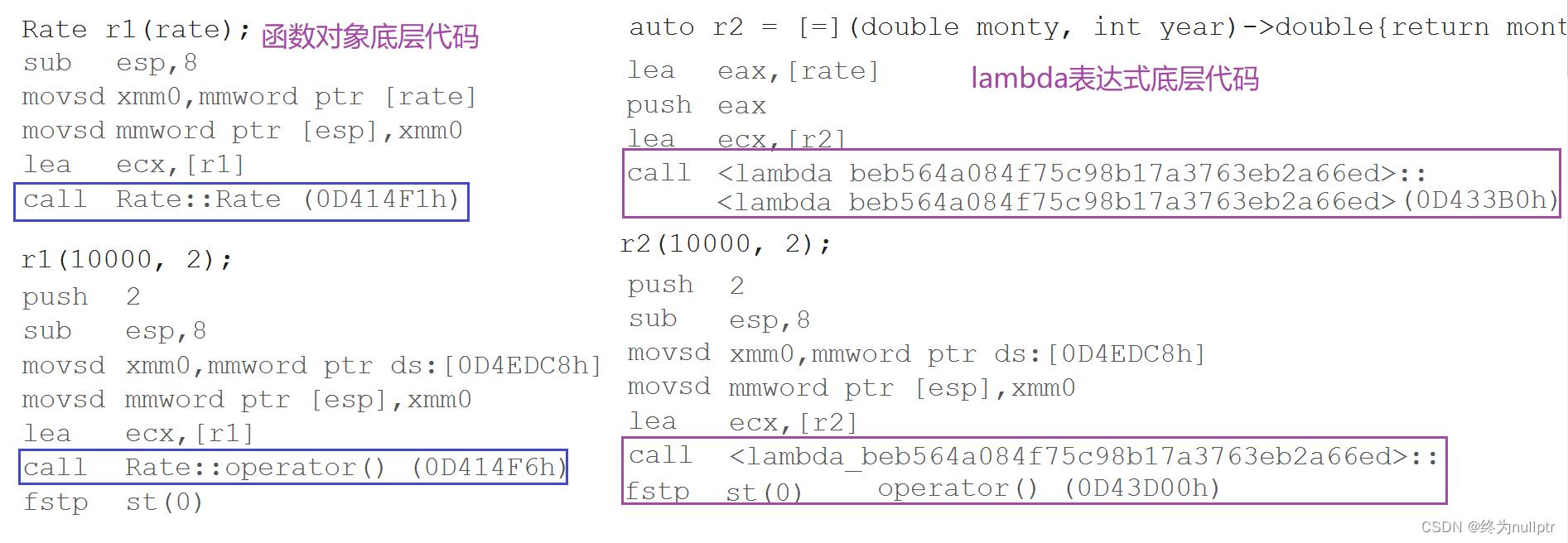
实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如
果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
9.可变参数模板
C++11的新特性可变参数模板能够创建可以接受可变参数的函数模板和类模板,相比C++98/03,类模版和函数模版中只能含固定数量的模版参数,可变模版参数无疑是一个巨大的改进。然而由于可变模版参数比较抽象,使用起来需要一定的技巧,所以这块还是比较晦涩的。
下面是一个基本可变参数的函数模板
// Args是一个模板参数包,args是一个函数形参参数包
// 声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数。
template <class ...Args>
void ShowList(Args... args)
上面的参数args前面有省略号,所以它就是一个可变模版参数,我们把带省略号的参数称为“参数
包”,它里面包含了0到N(N>=0)个模版参数。我们无法直接获取参数包args中的每个参数的,
只能通过展开参数包的方式来获取参数包中的每个参数,这是使用可变模版参数的一个主要特
点,也是最大的难点,即如何展开可变模版参数。由于语法不支持使用args[i]这样方式获取可变
参数,所以我们要用一些奇招来一一获取参数包的值。
递归函数方式展开参数包
// 递归终止函数
void ShowList()
cout << endl;
// 展开函数
template <class T, class ...Args>
void ShowList(T value, Args... args)
cout << value << " ";
ShowList(args...);
int main()
ShowList(1);
ShowList(1, 'A');
ShowList(1, 'A', std::string("sort"));
return 0;
逗号表达式展开参数包
template <class T>
void PrintArg(T t)
cout << t << " ";
//展开函数
template <class ...Args>
void ShowList(Args... args)
int arr[] = (PrintArg(args), 0)... ;
cout << endl;
int main()
ShowList(1);
ShowList(1, 'A');
ShowList(1, 'A', std::string("sort"));
return 0;
STL容器中的empalce相关接口函数:
template <class... Args>
void emplace_back (Args&&... args);可以看到的emplace系列的接口,支持模板的可变参数和万能引用。那么相对insert,emplace系列接口的优势到底在哪里呢?
1.对于内置类型:没有任何区别
#include<list>
int main()
list<int> list1;
list1.push_back(1);
list1.emplace_back(2);
return 0;
2.对于自定义类型:
int main()
list<pair<int, char>>list1;
list1.push_back(make_pair(1, 'a'));
//可以直接将值传过去,直接构造,
//不需要先构造一个临时对象,然后用这个临时对象拷贝构造
list1.emplace_back(2, 'b');
return 0;
下面试一下带有拷贝构造和移动构造的ns:string:
int main()
pair<int, ns::string> kv(20, "sort");
std::list< std::pair<int, ns::string> > mylist;
mylist.emplace_back(kv); // 左值
mylist.emplace_back(make_pair(20, "sort")); // 右值
mylist.emplace_back(10, "sort"); // 构造pair参数包
cout << endl;
mylist.push_back(kv); // 左值
mylist.push_back(make_pair(30, "sort")); // 右值
mylist.push_back( 40, "sort" ); // 右值
return 0;
运行截图:

观察上图可以发现,emplace对于右值系列是直接构造,没有移动语义,当类中没有移动构造的时候,emplce能够大大提高效率!
10.包装器
10.1function包装器
function包装器 也叫作适配器。C++中的function本质是一个类模板,也是一个包装器。 那么我们来看看,我们为什么需要function呢?
//ret = func(x);
// 上面func可能是什么呢?那么func可能是函数名?函数指针?函数对象(仿函数对象)?也有可能
//是lamber表达式对象?所以这些都是可调用的类型!如此丰富的类型,可能会导致模板的效率低下!
//为什么呢?我们继续往下看
template<class F, class T>
T useF(F f, T x)
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
double f(double i)
return i / 2;
struct Functor
double operator()(double d)
return d / 3;
;
int main()
// 函数名
cout << useF(f, 11.11) << endl;
// 函数对象
cout << useF(Functor(), 11.11) << endl;
// lambda表达式
cout << useF([](double d)->double return d / 4; , 11.11) << endl;
return 0;
运行截图:

通过上面的程序验证,我们会发现useF函数模板实例化了三份。 包装器可以很好的解决上面的问题。
std::function在头文件<functional>
// 类模板原型如下
template <class T> function; // undefined
template <class Ret, class... Args>
class function<Ret(Args...)>;
模板参数说明:
Ret: 被调用函数的返回类型
Args…:被调用函数的形参使用方法:
int f(int a, int b)
return a + b;
struct Functor
public:
int operator() (int a, int b)
return a + b;
;
class Plus
public:
static int plusi(int a, int b)
return a + b;
double plusd(double a, double b)
return a + b;
;
int main()
// 函数名(函数指针)
function<int(int, int)> func1 = f;
cout << func1(1, 2) << endl;
// 函数对象
function<int(int, int)> func2 = Functor();
cout << func2(1, 2) << endl;
// lambda表达式
function<int(int, int)> func3 = [](const int a, const int b)
return a + b; ;
cout << func3(1, 2) << endl;
// 类的静态成员函数 --指针
function<int(int, int)> func4 = &Plus::plusi;
cout << func4(1, 2) << endl;
// 类的普通成员函数 --指针
function<double(Plus, double, double)> func5 = &Plus::plusd;
cout << func5(Plus(), 1.1, 2.2) << endl;
return 0;
有了包装器,如何解决模板的效率低下,实例化多份的问题呢?
#include <functional>
template<class F, class T>
T useF(F f, T x)
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
double f(double i)
return i / 2;
struct Functor
double operator()(double d)
return d / 3;
;
int main()
// 函数名
function<double(double)> func1 = f;
cout << useF(func1, 11.11) << endl;
// 函数对象
function<double(double)> func2 = Functor();
cout << useF(func2, 11.11) << endl;
// lambda表达式
function<double(double)> func3 = [](double d)->double return d / 4; ;
cout << useF(func3, 11.11) << endl;
return 0;
运行截图:

包装器的使用场景:oj链接
class Solution
public:
int evalRPN(vector<string>& tokens)
stack<int> st;
map<string,function<int(int,int)>> opFuncMap =
"+",[](int x,int y)->int return x + y; ,
"-",[](int x,int y)->int return x - y; ,
"*",[](int x,int y)->int return x * y; ,
"/",[](int x,int y)->int return x / y; ,
;
for(const auto& str : tokens)
if(opFuncMap.count(str) == 0)
st.push(stoi(str));
else
int right = st.top();
st.pop();
int left = st.top();
st.pop();
st.push(opFuncMap[str](left,right));
return st.top();
;10.2bind
bind函数定义在头文件中,是一个函数模板,它就像一个函数包装器(适配器),接受一个可调用对象(callable object),生成一个新的可调用对象来“适应”原对象的参数列表。一般而言,我们用它可以把一个原本接收N个参数的函数fn,通过绑定一些参数,返回一个接收M个(M可以大于N,但这么做没什么意义)参数的新函数。同时,使用bind函数还可以实现参数顺序调整等操作。
// 原型如下:
template <class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);
// with return type (2)
template <class Ret, class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);可以将bind函数看作是一个通用的函数适配器,它接受一个可调用对象,生成一个新的可调用对
象来“适应”原对象的参数列表。
调用bind的一般形式:auto newCallable = bind(callable,arg_list);
其中,newCallable本身是一个可调用对象,arg_list是一个逗号分隔的参数列表,对应给定的
callable的参数。当我们调用newCallable时,newCallable会调用callable,并传给它arg_list中
的参数。
arg_list中的参数可能包含形如_n的名字,其中n是一个整数,这些参数是“占位符”,表示
newCallable的参数,它们占据了传递给newCallable的参数的“位置”。数值n表示生成的可调用对
象中参数的位置:_1为newCallable的第一个参数,_2为第二个参数,以此类推。
// 使用举例
#include <functional>
int Plus(int a, int b)
return a + b;
class Sub
public:
int sub(int a, int b)
return a - b;
;
int main()
//表示绑定函数plus 参数分别由调用 func1 的第一,二个参数指定
function<int(int, int)> func1 = bind(Plus, placeholders::_1,placeholders::_2);
//auto func1 = bind(Plus, placeholders::_1, placeholders::_2);
//func2的类型为 function<void(int, int, int)> 与func1类型一样
//表示绑定函数 plus 的第一,二为: 1, 2
auto func2 = bind(Plus, 1, 2);
cout << func1(1, 2) << endl;
cout << func2() << endl;
Sub s;
// 绑定成员函数
function<int(int, int)> func3 = bind(&Sub::sub, s,placeholders::_1, placeholders::_2);
// 参数调换顺序
function<int(int, int)> func4 = bind(&Sub::sub, s,placeholders::_2, placeholders::_1);
cout << func3(1, 2) << endl;
cout << func4(1, 2) << endl;
return 0;
组件库设计复盘 + 译文分享
参考技术A 译者前言:
作为一个外包中级UI刚到客户公司(传统制造业大公司)不久的时候主力设计了一套2B的移动的UI组件库规范。
从公司人员结构及使用场境出发。以提高复用性、提高效率、降低用户学习及识别成本为目标导向。产出了使用同一套UI标准的针对设计师的Sketch组件库、针对交互及产品的Axure组件库、针对开发使用的PIX组件库。
经宣讲和意见收集产品和开发推行有一定成果。但仍有不少人吐槽:
1、产品端现状: 吐槽主要集中组件库不能覆盖某些常见的业务场景和需求。因此经理们经常要求我们把市面上不太常规的操作增加至组件库中。
我们的囧境: 由于公司涉及的业务内容较多,我所在的UED部门由于不太能接触到具体业务场景,所以难以甄别经理所要求的组件是否具有复用性。因此我认为组件库团队中需要有项目经验丰富的产品经理作为顾问。
2、开发方面: 逻辑固定不大及展示类小UI组件使用较多(如toast、下拉刷新、),但那些组件间有强逻辑绑定、经常定制化的,例如单选多选弹窗等,因为怕有坑怕麻烦。宁愿自己手写。
我的见解: 对于逻辑比较复杂、变化灵活的组件,有2条道路可以选择:
1是不封装逻辑,完全退化为UI样式封装。只提供样式模型,变换逻辑自己填充。(即使日后进行逻辑封装也要留下自己DIY逻辑的可能性)
2、若要进行逻辑封装,需要对业务场景非常熟悉很有经验的前端工程师思考总结出最常用的场景进来进行。并留出变换逻辑DIY的可能性。
3、设计的方面: 由于这是我直接能亲耳听到的吐槽,所以记录、思考得比较详细,主要有以下方面:
1)组件库难用
我的见解: 这里面有2个客观原因和1个主观原因。
一是互联网泡沫破灭前,先进的设计团队管理经验没有回流到制造业的客观原因。我进来,客户公司的设计团队对Sketch工具并不熟练、设计师比较各自为政,不习惯统一的规范。二是在设计工具市场由于盗版和开源化等,没什么肉。一些组件库工具发展缓慢,造成组件库分享及使用体验不太好。例如蓝湖规范云是在我组件库开始后2个月才开始发布。Sketch弹性组件属性也是组件库计划开始后才发布。
主观原因是组件库的分类组织方式不太符合团队客观状况,由于我上一家公司是外资小团队。我出于避免组件名称歧义及方便开发的目的,对组件和图标使用了英文+BEM命名方式。导致不直观、文案过长。很多设计师找组件、图标不方便。
2)组件库丑
我认怂: 由于我进来做的第一个项目使用了渐变和阴影。跟一位负责工厂及物流应用的经理起了冲突。我了解到客户公司的2B产品除了面对在总部办公的白领外,还面对一大部分的工厂工人。他们的手机状态及网络环境未必比得上总部办公楼。所以在UI设计上我用了简单、老套、减少歧义、降低学习成本、增加复用性的设计原则。在时尚和美观度方面确实考虑较少。现在看来确实有一些组件的设计可以在不影响以上原则的前提下提高一下。
3)组件库限制了我
一些思考: 我在设计组件库的时候留了一些可以样式定制化的插槽。例如,颜色、图标都可以切换。若能熟练运用不至太影响终稿的设计效果。另外,我认为组件库和规范更像工具而非镣铐。若组件不能满足设计要求。可以在规范范围内,对组件进行重组,使之符合场景需求。同时,若有更好,使用场景更广的点子和建议,可以反映到交流群里使之成为规范。被更多人使用。
第一次做大项目,听到很多人不停的吐槽。让我个人产生了一定的迷茫。看了Airbnb官网上的这篇文章。其中一段话使我廓然开朗。
一个全公司使用的设计系统,只有2、3个少数的人来参与,那是不可能民主科学的。必须要让尽可能多的人来参与发表意见。建立健全的反馈讨论社区才是王道。
现分享原文及译文如下,跟同迷茫的小伙伴互励互勉:
Design Language Systems are unique. Some companies create systems for efficiency and reuse, and others make them to express their look and feel. While the goal may differ, all systems have something in common—people need to be able to use and grow them. If we only spend time designing product components, we aren’t designing the invisible human components : the overall relationships between the system and the teams who adopt it.
每个设计语言系统都是独特的。一些公司创造自己的设计语言系统是为了提高效率和复用性,而另一些公司是为了表现他们的形象和理念。尽管目的并不一致,但所有的系统都有一些共通点 —— 都需要被人使用和扩充。如果我们只把时间花在产品概念设计上,就相当于忽略了 无形的人的部分 :设计系统与使用该系统的团队的总体关系。
The system serves people, not the other way around . It’s the designers and engineers, the real customers of design systems, who need to be at the center of our work. With a storied background in this space , Yujin Han and I—Design Manager and Experience Design Lead , respectively —know the challenge of getting teams to contribute. So now we’re asking ourselves, “How might we set teams up for success by helping them incorporate our design language system (DLS) in their daily work?” Here’s how we’re evolving our model to be inclusive and empower teams to engage with the system.
系统服务人员,而非 反过来 。设计师和工程师们是设计系统的真实用户,设计系统的建立应以他们为中心。 在这样的背景下 ,Yujin Han 和我——设计经理及体验设计 负责人 , 各自都 ——意识到要动员整个团队是有一定挑战的。因此我们现在泯心自问“如何帮助他们把设计语言系统(DLS)吸纳到日常工作中,协助团队取得成功呢?”我们通过下面的方法,把设计模型发展的更具 包容性 , 给予团队自主权 去使用我们的系统。
Back in 2016, a team of engineers and designers created the first version of our Design Language System (DLS) with the goals of creating consistent experiences and cross-platform unity . The company was growing and teams were moving fast. People needed a common language to stay in sync .
早在2016年,一个工程师及设计师团队创造了第一个版本的DLS,目的是创造 持续一致的体验 以及 多平台统一 。当时公司在扩张,团队的节奏非常快。人们需要一个通用的设计语言来 保持同步 。
Since we released the DLS in 2016, our design organization grew significantly . The system was valuable and in high demand —a wonderful problem to have—but we couldn’t keep up with the amount of requests coming in. New components were being made, but not documented . And files were being shared across teams, but without naming conventions . It was the wild west. We’ve evolved from a single app to a platform that supports multiple businesses—a shift that has us increasingly considering human needs over solely focusing on features. Collaboration across businesses is critical because we don’t want our community to experience chaos while we transform our technology behind the scenes. So, we created a feedback loop to bring everyone together.
自从2016年我们发布了该DLS,我们的设计机构 显著成长 了。这个设计系统非常有价值且人们对它 有很大需求 ——有这样的问题是件好事——但我们 没法跟上 持续增长的大量需求。新的组件做出来了,但没有 文档记录 。文件在团队里到处流传,但没有 命名规则 。混乱得恍如荒野西部。我们从一个单一的发展为一个支持多种业务的平台——一个使我们越来越关注人文需求而非只关注特性的转变。 跨业务 协作非常重要,因为我们不希望团队在幕后改造技术活时让我们的 社区 变得混乱。因此我们创建了反馈 循环 机制把每个人连在一起。
Last year, we tried a critique model so designers across Airbnb could meet together to share product feedback and systems thinking. We called this feedback loop the DLS partnership. It was off to a good start, but when people got busy, attendance dwindled. When we asked people why they stopped coming, they expressed that they were coming out of their own passion , but that it wasn’t required or expected of them .
去年,我们尝试建立了一个发评论的模块以便所有Airbnb的设计师可以聚集在一起分享他们对产品的意见和系统思维。我们把这称为DLS协作者的反馈循环机制。这本来是个很好的开始,但当人们忙起来,参者逐渐减少。当我们问他们为何不来了,他们反映道,他们是 出于热情 而来,但后面发现系统 并不符合他们的需求或期待 。
It was clear that designers wanted dedicated time to participate , and acknowledgement for their participation. Instead, the partnership felt like extra effort , so we researched and developed a few key themes for improving our relationships with teams.
显然,设计师们更希望 花时间参与 ,并通过自己的参与获得认可。而这种 协作 感觉是 额外的负担 。因此,我们研究开发了一些关键主题来 改善 我们与团队的协作模式。
Recognition
认可
What they said: Designers were unclear if leadership backed partnership with our team.
What we did: We sought buy-in from managers, and ensured they would recognize designers for their involvement.
他们这么说:设计师们不清楚他们的领导支不 支持 与我们团队的协作.
我们这么做:我们应该先寻求经理 支持 ,保证他们认可设计师的参与。
Accountability
责任
What they said: While we gave a lot of critique, designers didn’t know what feedback to prioritize and when to turn advice into action .
What we did: We set actionable goals and tracked them so designers knew exactly what to focus on .
他们这么说:当我们给出很多评论,设计师们不知道反馈的 优先级 ,不知道何时把建议 付诸实践 。
我们这么做:我们设置可行的目标并跟踪全过程,因此设计师们能知道应该 关注 什么。
Collaboration
协作
What they said: Designers were eager to work together, and share their results with other teams.
What we did: We started providing opportunities for people to create shared projects and learn from each other.
他们这么说:设计师们 迫切渴望 一起工作,并与团队分享他们的成果。
我们这么做:我们开始提供给设计师创作并分享项目相互学习。
Partnership with designers was key, but getting buy-in from managers would make or break the program . We wanted to shift the collaboration mentality from nice-to-have to necessity . So we brought managers together before we kicked off the program, and asked them to nominate one or two designers on their team to participate. To build excitement, we also asked them to host small celebrations with their team to acknowledge their designers’ new roles.
与设计师之间的合作是关键所在,但从经理们中获得支持是 项目成败的关键 。我们想把合作心态的从“最好能有”变为“ 必须要 ”。因此我们在项目开始前把经理人聚集在一起,并套球他们从各自团队中 提名 一到两位设计师来参与。为了提高兴奋度,我们要求他们举行一个小 庆祝仪式 来 告知 设计师ta将有一个新的角色。
We announced the program launch with an invitation that welcomed partners to collaborate with us. As a design-led organization, we design everything —from emails and platforms to meetings and internal programs. In the fall when the program came to a close, we wrote performance evaluations for each partner so their managers could understand their contributions .
我们宣布项目 启动/落地? 时,向协作者发出合作邀请以欢迎他们。作为一个 主导设计 的组织,我们设计“所有东西”——从邮件到平台、从会议到内部项目。在秋天,当这个项目接近结束时,我们给每一个参与者写了 表现评价 ,确保他们的经理人知道他们作出的 贡献 。
During the kickoff meeting, we asked designers to post ideas and vote on how to improve the design system—such as building a pattern library or researching product theming . This democratic process empowered people to work together on these improvements. The meeting agenda played a big role in the design of the program. Our goal was to help designers make time to work together and apply systems thinking to real projects . We also wanted to provide a space where people could learn from each other. Our agenda broke down into these activities: gratitudes (foster community, inspire reflection) , open forum (create a market for collaboration), stand up ( track progress and unblock work ), heads down time (works on DLS with partners), action items (plan next steps and milestone), and share outs ( give and receive critique on work ).
在 启动 会议中,我们要求设计师po出自己的想法并投票选出完善设计系统的方法——例如建立一个 样式库 或 研究产品课题 。这个民主的进程允许人们合作起来改进系统。这种会议议程是我们项目的一个重要环节。我们的目标是帮助设计师抽出时间来共同工作,并 将系统思维应用到实际项目中 。同时我们也希望提供一个空间以供人们互相学习。我们的 议程可以分解为 以下的活动: 致谢(激励团队,激发反馈) 、 开放式讨论 (创造一个合作的大环境)、确立( 跟踪进度,扫清障碍 )、埋头苦干(与搭档一起着手干好DLS)、行动项目(计划下一步行动及里程碑)、分享( 给予并接受工作评价 )。
Each week, we’d ask our partners if they had feedback to improve the meetings. For example, partners wanted to know if other teams were working on similar challenges, so collaborative open forums were born. By prototyping meetings in real time, we were able to adapt to people’s needs. We wanted the meetings to be productive , but more importantly, we hoped to foster relationships . With fun project team names like Fabric and Tapioca, a bi-weekly batch of bubble tea, and occasional balloons, we designed a cheerful, welcoming environmen t.
每周,我们都会询问合作者是否有提高会议效果的反馈意见。例如,合作者希望知道其他团队是否有类似的挑战,为此诞生了 协同开放讨论会 。通过即时 简易 会议,我们能够适应人们的需求。我们希望会议 成果累累 ,但更重要的是我们希望 促进关系 。通过(取)一些有趣的团队名字,例如“Fabric”和“Tapioca”,两周一批的气泡茶和随性的气球装饰,我们设计了一种 活跃温暖的氛围 。
In addition to the partner meetings, we piloted co-design sprints. For two weeks, a product designer and system designer sat side-by-side to co-create a new filter sidebar so our guests can more easily find homes and experiences. The sprint included a debrief with the product research team , and user testing by the end of the first week.
除了伙伴会议,我们主导了合作设计冲刺活动。每2周,一位产品设计师和一位DLS设计师会排排坐,一起协同创作出一个新的筛选侧栏,以让我们的顾客更容易找到“民宿”和“体验”服务。这个冲刺活动包括 向产品研究团队报告 以及第一周结束前的用户测试。
There were also daily desk critiques with managers. This allowed designers to receive nearly real time feedback, and to keep moving things forward . In the second week, the product-and-system pair presented their work to their respective teams together, and received guidance from engineering, data science, and content strategy. As a result of the co-design sprint and support from additional teams, the pattern was updated in the product and submitted to our DLS component template for all teams to use.
同时我们每天会与经理人们有一个 面对面的评论会 。这让设计师们可以几乎即时地接收到反馈,并 推进进程 。第二周,“产品-系统”搭档会一起向各自的团队展示他们的工作成果,同时接受工程师、数据研究员、内容策划人的指导意见。作为协同设计冲刺的努力以及其他团队的支持的结果,产出的样式会被更新并 提交到 我们的DLS 组件模板 中,以供全部团队使用。
Tracking outcomes helps us prove the program’s value. Another early, powerful outcome of the program was the improvement of our selection patterns . Lesar Stepputat, an Experience Designer on Airbnb’s Payments team, was already working to improve drop down selection states on his team. Through our program, he ambitiously scaled his impact to improve the pattern across the entire Airbnb product.
追踪产出 能帮助我们验证这个项目的价值。另一个早期强有力的产出是我们的 选择组件样式 的 改进 。Lesar Stepputat,Airbnb支付团队的一位体验设计师,已经在着手改进团队 下拉选择状态 组件了。通过我们的项目,他雄心勃勃地在调整Airbnb全线产品样式方面 扩大自己的影响力 。
One of our success metrics of the partnership was attendance. While the first version of the program had fallen to just a few people attending meetings , our efforts resulted in an average of 60-70% of partners regularly participating. We also created a survey to collect open-ended feedback . Over half of the dozen respondents highly recommend the program. The survey also showed that the program cultivated strong relationships in the community. One partner even noted that ‘this has been the single most effective change brought to the DLS in a year and a half’.
出席率是我们成功的伙伴关系 指标 之一。虽然项目的初期只选定了少数人会 参与到会议中 ,但经过我们的努力后合作伙伴的常规参与率平均数达到了60%-70%。同时我们创建了一个问卷调查,收集 开放式的反馈意见 , 超过半数 的被访者 高度评价 这个项目。这个调查也表明,本次项目在社区中的员工中建立了强有力的合作关系。一位成员甚至写到“这是一年半以来DLS 最有效的转变 。”
While the initial positive response was a strong start, we also found areas for improvement . One thing we consistently heard from the partners was a desire for the DLS team to develop an openness to feedback when sharing work, and for feedback to be shared earlier in the process .
尽管 最初的 积极反馈是个很好的开始,我们仍找到其他 提升空间 。我们长期收到伙伴反馈,希望DLS能建设一个 开放平台 ,以便他们分享作品或在 项目早期阶段收集反馈意见 。
Now,*** we’re iterating to evolve*** the partnership.
现在我们 正在逐步促进 伙伴关系。
Through this process, we learned that with an inclusive mindset , we can effectively build partnerships that results in a healthy community and actionable outcomes .
通过这个流程,我们学习到: 保持包容的心态 ,我们可以有效地建立伙伴关系,最终可建立健康的社区关系及 可行的产出 。
For a robust design system to work, a company needs a mature culture that empowers people develop the system together. Without this, designers may feel like the system is limiting or blocking their creativity. Our intent is to continue to support teams as they build a sustainable design system community together.
一个 充满活力的 设计系统的运作,要求公司有 成熟的企业文化 ,允许员工共同拓展系统。 否则,设计师将认为这套系统是在限制或阻碍他们的创意。 我们的 初衷 是持续的支持整个团队来共同建立 可持续的 设计系统社区。
一个有机的共同体
Creating and maintaining a design system is like planting a tree—it has to be nurtured and cared for to reap the benefits. The seed of our design system has been planted, and now our teams are working together to maintain and grow it. Our new way of working gives people recognition , facilitates trust , and creates strong partnerships. By committing to learn from each other and measure progress together, we’re able to provide a better experience for our teams, and for the entire Airbnb community.
创造及维持一个设计系统就 像是植树——必须要呵护和滋养才能收获到好处。 我们设计系统的种子已经种下,现在我们的团队正共同协作来维护及壮大它。我们的新工作方式给予人们 肯定 , 促进信任 ,形成紧密的合作关系。通过一起 参与 相互学习及衡量进度。我们能为团队及整个Airbnb社区提供更好的体验。
以上是关于为什么许多人吐槽C++11,那些语法值得我们学习呢?的主要内容,如果未能解决你的问题,请参考以下文章