机器学习与数据挖掘计算机视觉方法资料汇总(永久更新)
Posted slim1017
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习与数据挖掘计算机视觉方法资料汇总(永久更新)相关的知识,希望对你有一定的参考价值。
感觉这一学期学了挺多各种各样的机器学习方法,好多不经常用都快忘了。把各种方法我觉得讲得比较好的资料记录下来,永久更新。。。
后文提到的主要资料书籍汇总:
Ng CS229:斯坦福Andrew Ng 机器学习课程,网易公开课和coursera 上都有视频;
UFLDL教程:Andrew Ng 深度学习教程:http://deeplearning.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B
《独立成分分析》:作者:AapoHyvarinen周宗潭译
《模式识别 张学工 第三版》
《模式分类 Duda 第二版》
《机器学习实战》
《统计学习方法 李航 2012年》
《The Elements of Statistical Learning:Data Mining, Inference, and Prediction》2009年第二版,作者:Trevor Hastie,Robert Tibshirani,Jerome Friedman
(这本英文可以好好啃啃)
数据分析与降维方法:
PCA(主成分分析)
核心要点:数据预处理,选取协方差矩阵最大K个特征值,降维同时保留大部分信息。
参考资料:Ng CS229 Part11 PCA;UFLDL教程 PCA部分
进阶:kernel PCA等
白化
核心要点:(1)数据的去相关(PCA中的乘以旋转矩阵已经去相关了),(2)所有特征具有相同方差;白化也是常见的预处理步骤。
参考资料:UFLDL教程 白化部分;《独立成分分析》第6章。
LDA(线性判别分析)
核心要点:与PCA类似,但是投影目的不太一样;PCA强调寻找投影方向能保留更多的信息;DA强调投影后类间间距大,类内间距小。
参考资料:《模式识别 张学工 第三版》4.3
FA(Factor Analysis)
核心要点:又比较像PCA,但是它是对概率密度的估计。
参考资料:Ng CS229 Part10(用到了EM算法)
K-L变换(Karhunen-LoèveTransform)
核心要点:这次不是像PCA了,K-L变换包含PCA,当K-L变换中用数据的协方差矩阵作为K-L坐标系的产生矩阵时,就是PCA。
参考资料:《模式识别 张学工 第三版》8.4
MDS(多维尺度分析)
核心要点:样本间的距离关系在低维表示
参考资料:《模式识别 张学工 第三版》8.7; CSDN博客 http://blog.csdn.net/songrotek/article/details/42235097
Manifold Learning(流形学习)
核心要点:降维,最近才开始看,入个门:IsoMap 和 LLE
参考资料:论文 ISOMAP:A Global Geometric Framework for Nonlinear Dimensionality Reduction;论文 LLE-Nonlinear Dimensionality Reduction by Locally Linear Embedding;博客:流形学习综述http://blog.csdn.net/chl033/article/details/6107042 ;UCLA 提供的 matlab code :http://www.math.ucla.edu/~wittman/mani/index.html
。。。好像连接不能用了,但是网上其他地方能找到代码 :http://download.csdn.net/download/bachelor119/1562326 (流形学习的代码都相对挺简单的,代码中大部分都是GUI,只看算法部分就好);相关论文:http://blog.csdn.net/stellar0/article/details/8741623
ICA(独立成分分析)
核心要点:s=Ax;
参考资料:Ng CS229 Part12 ICA
进阶:《独立成分分析》整本。
神经网络降维
核心要点:自编码器降维,受限波尔兹曼机降维
参考资料:论文 :G. E. Hinton:Reducing the Dimensionality of Data with Neural Networks;UFLDL教程 自编码器部分;Theano DeepLearning 教程 自编码器部分。
分类方法:
KNN(最近邻分类器)
核心要点:新样本按与老样本欧氏距离最近表示最相似;
参考资料:《机器学习实战》第2章 ;《模式识别 张学工 第三版》6.1。
贝叶斯方法(朴素贝叶斯,贝叶斯分类器,贝叶斯信念网)
核心要点:贝叶斯公式,通过数据得到已知类别特征的概率,通过贝叶斯公式求出已知特征各类的概率。
参考资料:《机器学习实战》第4章;Ng CS229 Part 4.2;《统计学习方法》第4章。维基百科 https://en.wikipedia.org/wiki/Naive_Bayes_classifier
Logistic 回归
参考资料:Ng CS229 Part 1;《机器学习实战》第5章;《统计学习方法》第6章。
决策树
核心要点:用某种标准(熵增益)来量度哪个特征分类能力更强。
参考资料:《机器学习实战》第3章;《统计学习方法》第5章
Adaboost
(Adaboost,随机森林,SVM这几个都是计算机视觉使用最多的分类器)
核心要点:3个臭皮匠赛过猪哥亮!
参考资料:《机器学习实战》第7章;《统计学习方法》第8章
SVM(支持向量机)
核心要点:
线性支持向量机的优化目标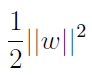 实际上也是正则化,防止过拟合,这也是SVM泛化能力的保障;
实际上也是正则化,防止过拟合,这也是SVM泛化能力的保障;
加上惩罚函数C防止了某些偏离特别大的数据对决策面的过度影响;
加入kernel 把低维数据映射到高维,把低维不可分类变到高维后就可能可分了,但是数据维度高了之后,会引发维数灾变的问题,kernel trick的trick 就在于数据映射到高维去分类,却通过kernel 函数在低维空间计算高维特征的内积(SVM计算过程中只需要计算内积)。
参考资料:比较出名的博客:支持向量机通俗导论(理解SVM的三层境界);《统计学习方法》第7章(我觉得统计学习方法这本书有些章节真心写得很细很细,想入门绝对值得一看);Ng CS229 Part 5;
Mixtures of Gaussians(高斯混合模型)
核心要点:模型本身并没有太多需要理解的地方,但是这个模型的求解用到了著名的机器学习算法EM算法,这个真是得好好看看,对包含隐变量的概率问题经常用到EM算法。另外,05年斯坦福的无人车,视觉感知部分用到了这个模型来判断前方是否为可以通行区域(2分类问题)。
参考资料:Ng CS229 Notes 7a;EM算法是紧接着的 Part 9;
神经网络及深度学习(深度神经网络)
核心要点:多层感知器,自编码器,受限波尔兹曼机,卷积神经网络,RNN,LSTM。关于深度学习,我也写了UFLDL和Theano两个教程的笔记了。
参考资料:UFLDL教程;Theano DeepLearning 教程;这两个看完了可以看看 coursera 上 Hinton 的课:Neural Networks for Machine Learning-Geoffrey Hinton。
其他常见模型:
隐马尔科夫模型,条件随机场
核心要点: 这两个在自然语言处理中用得挺多
参考资料:《统计学习方法》第10,11章
回归模型:
线性回归;局部加权线性回归;岭回归(对参数加上正则化项);Lasso回归;Least Angle Regression;
参考资料:《机器学习实战》第8章;《The Elements of Statistical Learning》第二版(2009年)中回归部分(这本书真心值得读,英文的,慢慢啃)。
以上是关于机器学习与数据挖掘计算机视觉方法资料汇总(永久更新)的主要内容,如果未能解决你的问题,请参考以下文章