Linux模拟实现简易版bash
Posted 夜 默
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux模拟实现简易版bash相关的知识,希望对你有一定的参考价值。
✨个人主页: Yohifo
🎉所属专栏: Linux学习之旅
🎊每篇一句: 图片来源
🎃操作环境: CentOS 7.6 阿里云远程服务器
- Good judgment comes from experience, and a lot of that comes from bad judgment.
- 好的判断力来自经验,其中很多来自糟糕的判断力。

文章目录
🌇前言
Linux 系统主要分为 内核(kernel) 和 外壳(shell),普通用户是无法接触到内核的,因此实际在进行操作时是在和外壳程序打交道,在 shell 外壳之上存在 命令行解释器(bash),负责接收并执行用户输入的指令,本文模拟实现的就是一个 简易版命令行解释器

🏙️正文
1、bash本质
在模拟实现前,先得了解 bash 的本质
bash 也是一个进程,并且是不断运行中的进程
证明:常显示的命令输入提示符就是 bash 不断打印输出的结果

输入指令后,bash 会创建子进程,并进行程序替换
证明:运行自己写的程序后,可以看到当前进程的 父进程 为 bash

此时可以断定神秘的 bash 就是一个运行中的进程,因为进程间具有独立性,因此可以同时存在多个 bash,这也是多用户登录 Linux 可以同时使用 bash 的重要原因
系统自带的 bash 是一个庞然大物,我们只需根据其本质,实现一个简易版 bash 就行了

图片源自知乎《Linux内核有多少行源代码?》
2、需求分析
bash 需要帮我们完成命令解释+程序替换的任务,因此它至少要具备以下功能:
- 接收指令(字符串)
- 对指令进行分割,构成有效信息
- 创建子进程,执行进程替换
- 子进程运行结束后,父进程回收僵尸进程
- 输入特殊指令时的处理
进程相关知识都已经在前面介绍过了,本文着重介绍的是其他步骤及细节
3、基本框架
抛开指令接收、切割、替换时的细节,简易版 bash 代码基本框架如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <string.h>
#include <assert.h>
//指令分割函数
void split(char* argv[ARGV_SIZE], char* ps)
int main()
//这是一个始终运行的程序:bash
while(1)
//打印提示符
printf("[User@myBash default]$ "); //可以自定义,跟着标准走
fflush(stdout); //手动清空缓冲区
//读取指令
//指令分割
//子进程进行程序替换
pid_t id = fork();
if(id == 0)
//直接执行程序替换,这里使用 execvp
execvp(); //具体细节先忽略
exit(168); //替换失败后返回,这个值可以自定义 [0, 255]
//父进程等待子进程终止,回收僵尸进程
int status = 0;
waitpid(id, &status, 0); //在等待队列中阻塞
if(WIFEXITED(status))
//假如程序替换失败
//关于打印的错误信息:也可以自定义,格式跟着标准走
if(WEXITSTATUS(status) == 168)
printf("%s: Error - %s\\n", argv[0], "The directive is not yet defined");
else //如果子进程被异常终止,打印相关信息
printf("process run fail! [code_dump]:%d [exit_signal]:%d\\n", (status >> 7) & 1, status & 0x7F); //子进程异常终止的情况
return 0;
这只是简易版 bash 的基本框架,其他细节将会在后续补充完整
4、核心内容
核心内容主要为 读取、切割、替换 这三部分,逐一实现,首先从指令读取开始

4.1、指令读取
读取指令前,首先要清楚待读取命令可能有多长
- 常见命令如
ls -a -l长度不超过10 - 为了避免极端情况,这里预设命令最大长度为
1024 - 使用数组进行指令存储(缓冲区)
#define COM_SIZE 1024
char command[COM_SIZE]; //缓冲区
得到缓冲区后,就得考虑什么是指令?如何读取指令?
Linux中的大部分指令由指令 [选项]构成,在指令和[选择]间有空格- 常规的
scanf无法正常读取指令,因为空格会触发输入缓冲区刷新 - 这里主要使用
fgets逐行读取,可以读取到空格
//读取指令
//因为有空格,所以需要逐行读取
fgets(command, COM_SIZE, stdin);
assert(command); //不能输入空指令
(void)command; //防止在 Release 版本中出错
command[strlen(command) - 1] = '\\0'; //将最后一个字符 \\n 变成 \\0
注意: 可能存在读取失败的情况,assert 断言解决;因为 fgets 也会把最后的 '\\n' 读进去,为了避免出错,手动置为 '\\0'
4.2、指令分割
获得指令后,就需要将指令进行分割
就像伐木后需要再次分割利用一样,指令也需要经过分割才能利用~

为何要分割指令?
- 程序替换时,需要使用
argv表,这张表由指令、选项、NULL构成 - 利用指令间的空格进行分割
如何分割指令?
C语言提供了字符串分割函数strtok,可以直接使用- 当然也可以手动实现分割
指令分割后呢?
- 将分割好的指令段,依次存入
argv表中,供后续程序替换使用 argv表实际为一个指针数组,可以存储字符串
如 command 一样,表 argv 也需要考虑大小,这里设置为 64,实际使用时也就分割为四五个指令段
#define ARGV_SIZE 64
//指令分割
//将连续的指令分割为 argv 表
char* argv[ARGV_SIZE]; //指针数组
split(argv, command);
利用 strtok 实现指令分割函数 split()
#define DEF_CHAR " " //预设分割项,需为字符串
void split(char* argv[ARGV_SIZE], char* ps)
assert(argv && ps);
//调用 C语言 中的 strtok 函数分割字符串
int pos = 0;
argv[pos++] = strtok(ps, DEF_CHAR); //有空格就分割
while(argv[pos++] = strtok(NULL, DEF_CHAR)); //不断分割
argv[pos] = NULL; //确保安全
注意: 指令分割结束后,需要在添加 argv 表结尾 NULL
4.3、程序替换
获得实际可用的 argv 表后,就可以开始子进程程序替换操作了
这里使用的是函数 execvp,理由:
v表示vector,正好和我们的argv表对应p为path,可以根据argv[0](指令),在PATH中寻找该程序并替换
当然也可以使用 execve 系统级替换函数
//子进程进行程序替换
pid_t id = fork();
if(id == 0)
//直接执行程序替换,这里使用 execvp
execvp(argv[0], argv);
exit(168); //替换失败后返回
注意: 程序替换成功后,exit(168) 语句不会执行
4.4、实机演示
将 基本框架 + 核心内容 合并编译后,得到了这样一个程序:
动图Gif

可以看到,bash 的基本雏形已经形成,不过还存在一些不足,比如 ls 命令显示文件无高亮、cd命令无法切换、环境变量无法添加至子进程等,这些问题都可以通过特殊处理避免
5、特殊情况处理
对特殊情况进行处理,使 myBash 更加完善
5.1、ls 显示高亮
系统中的 bash 在面对 ls 等文件显示指令时,不仅会显示内容,还会将特殊文件做颜色高亮处理,比如在我的环境下,可执行文件显示为绿色
实现原理
- 在指令结尾加上
--color=auto语句,即可实现高亮

处理这个问题很简单,在指令分割结束后,判断是否为 ls,如果是,就在 argv 表后尾插入语句 --color=auto 即可
//特殊处理
//颜色高亮处理,识别是否为 ls 指令
if(strcmp(argv[0], "ls") == 0)
int pos = 0;
while(argv[pos++]); //找到尾
argv[pos - 1] = (char*)"--color=auto"; //添加此字段
argv[pos] = NULL; //结新尾

注意:
- 因为
argv表中的元素类型为char*,所以在尾插语句时,需要进行类型转换 - 尾插语句后,需要再次添加结尾,确保安全
5.2、内建命令
内建命令是比较特殊的命令,不同于普通命令直接进行程序替换,内建命令需要进行特殊处理,比如 cd 命令调用系统级接口 chdir 让 父进程(myBash) 进行目录间的移动

资料来源:互联网
5.3、cd
首先实现不同目录间的切换
切换的本质:令当前 bash 移动至另一个目录下,不能直接使用 子进程 ,因为需要移动的是 父进程(bash)
对于当前的 myBash 来说,cd 没有丝毫效果,因为此时 指令会被拆分后交给子进程处理,这个方向本身就是错误的

特殊情况特殊处理,同 ls 高亮一样,对指令进行识别,如果识别到 cd 命令,就直接调用 chdir 函数令当前进程 myBash 移动至指定目录即可(不必再创建子进程进行替换)
//目录间移动处理
if(strcmp(argv[0], "cd") == 0)
//直接调用接口,然后 continue 不再执行后续代码
if(strcmp(argv[1], "~") == 0)
chdir("/home"); //回到家目录
else if(strcmp(argv[1], "-") == 0)
chdir(getenv("OLDPWD"));
else if(argv[1])
chdir(argv[1]); //argv[1] 中就是路径
continue; //终止此次循环

注意: 如果路径为空,不进行操作;如果路径为 ~,回到家目录;cd - 指令依赖于 OLDPWD 这个环境变量,直接拿来用即可
5.4、export
export 添加环境变量,添加的是父进程 myBash 的环境变量,而非子进程,需要特殊处理
解决方法:
- 先将待添加的环境变量拷贝至缓冲区
- 再从缓冲区中读取,并调用
putenv函数添加至环境变量表
为何不能直接通过 putenv 添加至环境变量表中?
argv[1]中的内容是不断变化的,不能直接使用- 一般用户自定义的环境变量,在
bash中需要用户自己维护 - 最好的方案就是使用缓冲区进行环境变量的拷贝放置,因为缓冲区中的内容不易变
错误体现:直接使用 putenv(argv[1]),导致第一次添加可能成功,但第二次添加后,第一次的环境变量会被覆盖
正确解法是借助缓冲区 myEnv
#define COM_SIZE 1024
#define ARGV_SIZE 64
char myEnv[ARGV_SIZE][COM_SIZE]; //二维数组
int env_pos = 0; //专门维护此缓冲区
注意: 此缓冲区定义在循环之外
char myEnv[COM_SIZE][ARGV_SIZE]; //大小与前面有关
int env_pos = 0; //专门维护缓冲区
//这是一个始终运行的程序:bash
while(1)
//…… 省略部分代码
//环境变量相关
if(strcmp(argv[0], "export") == 0)
if(argv[1])
strcpy(myEnv[env_pos], argv[1]);
putenv(myEnv[env_pos++]);
continue; //一样需要提前结束循环

除了 export 需要特殊处理外,env 查看环境变量表也需要特殊处理,因为此时的 env 查看的是 父进程(myBash) 的环境变量表,因此不需要将指令交给 子进程 处理
//注意:此函数实现于主函数外
void showEnv()
extern char** environ; //使用当前进行的环境变量表
int pos = 0;
for(; environ[pos]; printf("%s\\n", environ[pos++]));
//环境变量表
if(strcmp(argv[0], "env") == 0)
showEnv(); //调用函数,打印父进程的环境变量表
continue; //提前结束本次循环
完善后,env 指令显示的才是正确进程的环境变量表
5.5、echo
echo 命令也属于内建命令,其能实现很多功能,比如:查看环境变量、查看最近一个进程的退出码、输出重定向等,其中前两个实现比较简单,最后一个需要 基础IO 相关知识,后续更新补上
查看环境变量
echo 指令查看环境变量时,指令长这样 echo $环境变量,可以先判断 argv[1][0] 是否为 $,如果是,就直接根据 argv[1][1] 获取环境变量信息并打印即可
代码实现如下
//echo 相关
//只有 echo $ 才做特殊处理(环境变量+退出码)
if(strcmp(argv[0], "echo") == 0 && argv[1][0] == '$')
if(argv[1] && argv[1][0] == '$')
printf("%s\\n", getenv(argv[1] + 1));
continue;

echo 还能查看退出码:echo $?,对上述程序进行改造即可实现
退出码从何而来?
- 很简单,父进程在等待子进程结束后,可以轻而易举的获取其退出码
- 将退出码保存在一个全局变量中,供
echo $?指令使用即可
int exit_code = 0; //保存退出码的全局变量
代码实现:
//echo 相关
//只有 echo $ 才做特殊处理(环境变量+退出码)
if(strcmp(argv[0], "echo") == 0 && argv[1][0] == '$')
if(argv[1] && argv[1][0] == '$')
if(argv[1][1] == '?')
printf("%d\\n", exit_code);
else
printf("%s\\n", getenv(argv[1] + 1));
continue;

关于 echo 重定向的内容,后面有空再更新
5.6 重定向
2023.3.28 更新,新增重定向内容,修复部分问题
重定向的本质:关闭默认输出/输入流,打开新的文件流,从其中写入/读取数据
重定向的三种情况:
echo 字符串 > 文件向文件中写入数据,写入前会先清空内容echo 字符串 >> 文件向文件中追加数据,追加前不会先清空内容可执行程序 < 文件从文件中读取数据给可执行程序
所以实现重定向的关键在于判断指令中是否含有 >、>>、< 这三个字符,如果有,就具体问题具体分析,完成重定向
具体实现步骤:
- 判断字符串中是否含有目标字符,如果有,就置当前位置为
'\\0‘,其后半部分不参与指令分割 - 后半部分就是文件名,在打开文件时需要使用
- 根据不同的字符,设置不同的标记位,用于判断打开文件的方式(只写、追加、只读)
- 判断是否需要进行重定向,如果需要,在子进程创建后,打开目标文件,并调用
dup2函数进行标准流的替换
关于系统级文件打开函数 open 的更多信息这篇文章中有介绍 《Linux基础IO【文件理解与操作】》
open 函数的打开选项
O_RDONLY //只读
O_WRONLY | O_CREAT | O_TRUNC //只写
O_WRONLY | O_CREAT | O_APPEND //追加
标准流交换函数 dup2
//给参数1传打开文件后的文件描述符,给参数2传递待关闭的标准流
//读取:关闭0号流
//写入、追加:关闭1号流
int dup2(int oldfd, int newfd);
下面是具体代码实现
//在读取指令后,就进行判断:是否需要重定向
//重定向
//在获取指令后进行判断
//如果成立,则获取目标文件名 filename
char *filename = checkDir(command);
//枚举类型,用于判断不同的文件打开方式
enum redir
REDIR_INPUT = 0, //读取
REDIR_OUTPUT, //写入
REDIR_APPEND, //追加
REDIR_NONE //空
redir_type = REDIR_NONE; //创建对象 redir_type,默认为 NONE
//检查是否出现重定向符
char* checkDir(char* command)
//从右往左遍历,遇到 > >> < 就置为 '\\0'
size_t end = strlen(command); //与返回值相匹配
char* ps = command + end; //为了避免出现无符号-1,这里采取错位的方法
while(end != 0)
if(command[end - 1] == '>')
if(command[end - 2] == '>')
command[end - 2] = '\\0';
redir_type = REDIR_APPEND;
return ps;
command[end - 1] = '\\0';
redir_type = REDIR_OUTPUT;
return ps;
else if(command[end - 1] == '<')
command[end - 1] = '\\0';
redir_type = REDIR_INPUT;
return ps;
//如果不是空格,就可以更新 ps指向
if(*(command + end - 1) != ' ')
ps = command + end - 1;
end--;
return NULL; //如果没有重定向符,就返回空
//子进程进行程序替换
pid_t id = fork();
if(id == 0)
//判断是否需要进行重定向
if(redir_type == REDIR_INPUT)
int fd = open(filename, O_RDONLY);
dup2(fd, 0); //更改输入,读取文件 filename
else if(redir_type == REDIR_OUTPUT)
int fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, 0666);
dup2(fd, 1); //写入
else if(redir_type == REDIR_APPEND)
int fd = open(filename, O_WRONLY | O_CREAT | O_APPEND, 0666);
dup2(fd, 1); //追加
//直接执行程序替换,这里使用 execvp
execvp(argv[0], argv);
exit(168); //替换失败后返回
具体效果(A.txt 为空,B.txt 已存在内容,程序 a.out 可以读取字符串并输出):

注意: 当前实现的重定向只是最简单的标准流替换,实际重定向更加复杂
第二天: 利用生产者消费者模型实现傻瓜版匹配机制(不按段位和匹配时间)
前文回顾:
我的Git仓库
目录
第二天: 利用生产者消费者模型实现傻瓜版匹配机制(不按段位和匹配时间)
上次客户端直接调用添加用户的函数,我们今天先增加一点可操作性,如输入 add / remove相关的操作模拟游戏的匹配/退出操作
对客户端client.py 的操作进行完善
以实现 输入相应的id和用户名, 自定义 添加/删除,


//生产者消费者队列
给匹配的服务端增加一个线程(使匹配段位相近,并控制好匹配时长)
需要为线程加锁,保证所有有关队列的操作同一时间只能有一个线程操作
//在任务队列为空时, 利用条件变量,在消费者队列卡住, 直到有新的任务进来唤醒该进程才会继续执行
message_queue.cv.notify_all();
//处理完共享的变量后千万记得解锁,否则进程阻塞效率会很低
设计一下消费者进程

设计一下生产者进程
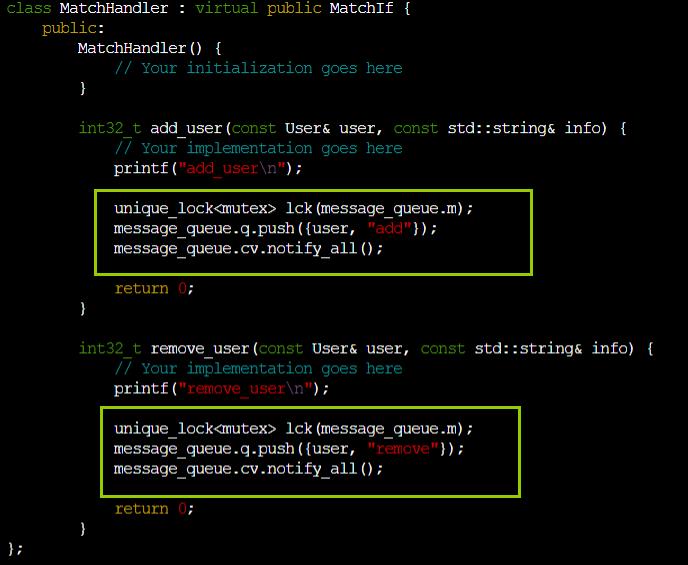
设计一下匹配池(傻瓜版)
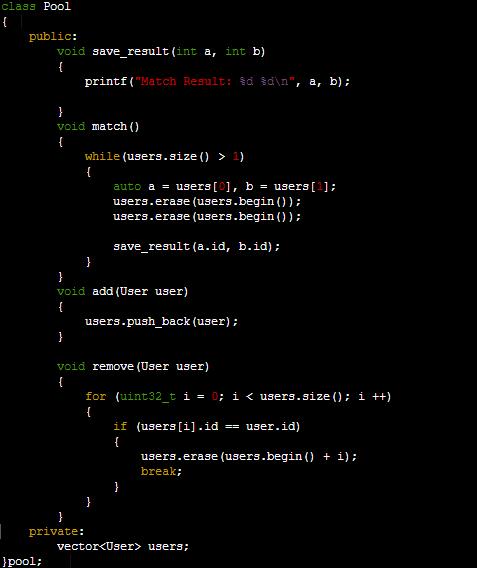
具体改动参见commit:
因为用到了进程,编译完链接的时候记得加上 -pthread
g++ -c main.cpp
g++ *.o -o main -lthrift -pthread
效果
由此,我们实现了一个傻瓜版匹配机制!!(一旦匹配池出现两名玩家,就把他们匹配到一块)

第二天: 利用生产者消费者模型实现傻瓜版匹配机制(不按段位和匹配时间)
前文回顾:
 https://blog.csdn.net/qq_39391544/article/details/120585704
https://blog.csdn.net/qq_39391544/article/details/120585704我的Git仓库
 https://git.acwing.com/knight/thrift_lesson/-/tree/master
https://git.acwing.com/knight/thrift_lesson/-/tree/master目录
第二天: 利用生产者消费者模型实现傻瓜版匹配机制(不按段位和匹配时间)
上次客户端直接调用添加用户的函数,我们今天先增加一点可操作性,如输入 add / remove相关的操作模拟游戏的匹配/退出操作
对客户端client.py 的操作进行完善
以实现 输入相应的id和用户名, 自定义 添加/删除,
//生产者消费者队列
给匹配的服务端增加一个线程(使匹配段位相近,并控制好匹配时长)
需要为线程加锁,保证所有有关队列的操作同一时间只能有一个线程操作
//在任务队列为空时, 利用条件变量,在消费者队列卡住, 直到有新的任务进来唤醒该进程才会继续执行
message_queue.cv.notify_all();//处理完共享的变量后千万记得解锁,否则进程阻塞效率会很低
设计一下消费者进程
设计一下生产者进程
设计一下匹配池(傻瓜版)
具体改动参见commit:
因为用到了进程,编译完链接的时候记得加上 -pthread
g++ -c main.cpp
g++ *.o -o main -lthrift -pthread效果
由此,我们实现了一个傻瓜版匹配机制!!(一旦匹配池出现两名玩家,就把他们匹配到一块)