基于神经网络的帧内预测和变换核选择
Posted Dillon2015
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于神经网络的帧内预测和变换核选择相关的知识,希望对你有一定的参考价值。
本文来自JVET-T0073提案《neural network-based intra prediction with transform selection in VVC》
简介
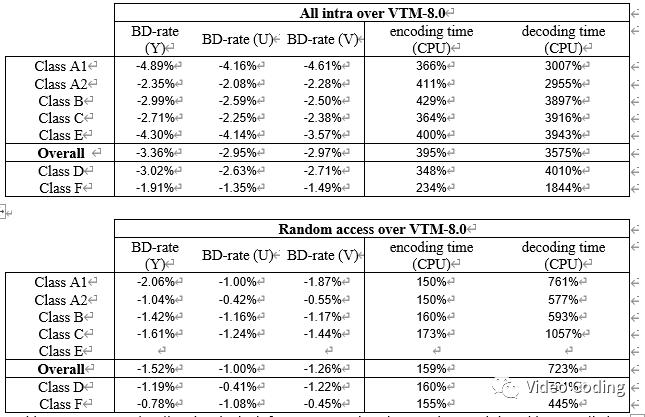
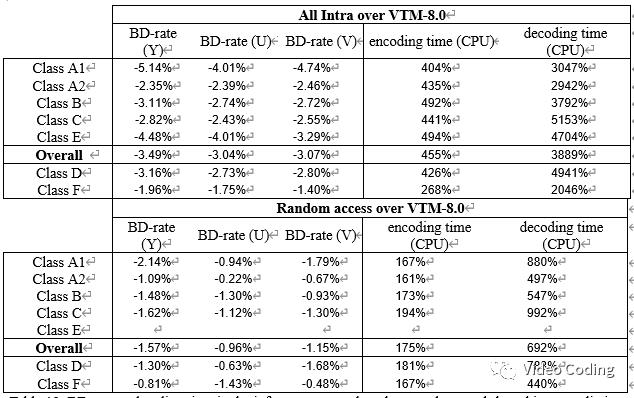
文中提出利用神经网络使用左侧和上方参考像素直接生成预测块,以及预测使用LFNST时的变换核索引和是否需要转置。在VTM-8.0上,all intra配置下YUV的BD-Rate分别为-3.36%,-2.95%,-2.97%,编解码时间分别是395%和3575%,random access配置下YUV的BD-Rate分别为-1.52%,-1.00%,-1.26%,编解码时间分别是159%和723%。
整体框架
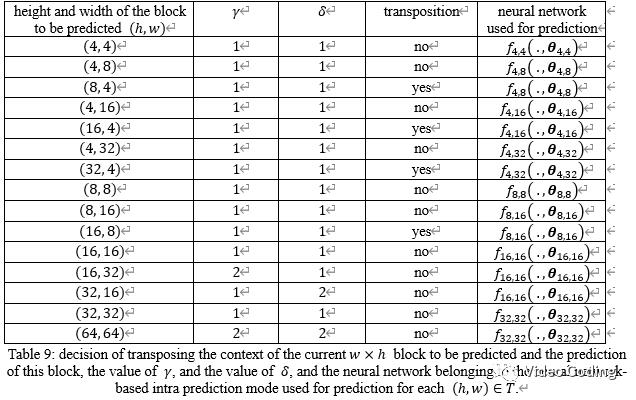
针对不同尺寸块一共训练了8个模型,4x4,8x4,16x4,32x4, 8x8,16x8,16x16,32x32。
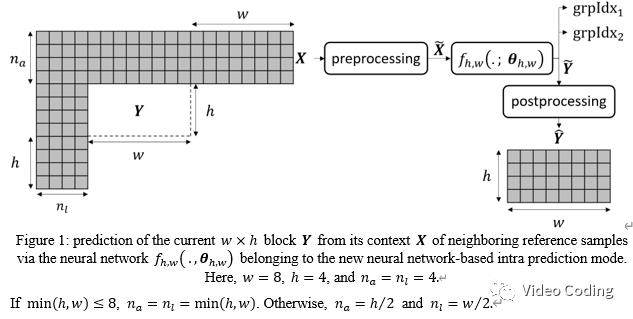
使用模型对块wxh的处理过程用 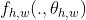 表示,
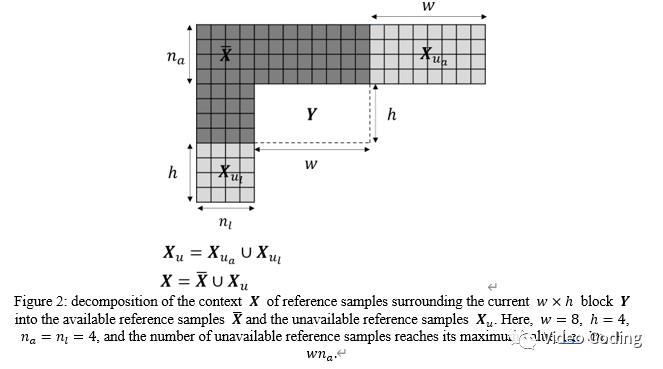
表示, 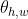 表示模型参数。对于给定的wxh块Y,其相邻像素用X统一表示如Fig.1所示,X包括Y上方的
表示模型参数。对于给定的wxh块Y,其相邻像素用X统一表示如Fig.1所示,X包括Y上方的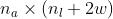 像素和左侧的
像素和左侧的 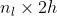 像素。整体流程如Fig.1,X经过预处理后被送入网络,网络输出为
像素。整体流程如Fig.1,X经过预处理后被送入网络,网络输出为 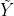 和grpIdx1,gapIdx2, 经过后处理生成Y的预测块
和grpIdx1,gapIdx2, 经过后处理生成Y的预测块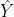 。其中网络输出的grpIdx1,gapIdx2是预测的LFNST变换核索引和是否进行转置操作。
。其中网络输出的grpIdx1,gapIdx2是预测的LFNST变换核索引和是否进行转置操作。
基于神经网络的帧内预测
预处理操作
Fig.1中对X进行的预处理操作包括以下4个步骤:
-
X中的参考像素除以2^(b-8),b表示位深。
-
对可获得的参考像素(已重建)减去均值u。
-
将不可获得的参考像素设为255。
-
如果min(h,w)<=8,上一步得到结果被展平(flattened),这是因为对于min(h,w)<=8的块网络采用全连接处理。如果min(h,w)>8,上一步的结果被分为两个矩形部分,Y上方的参考像素X0和左侧的X1,这是因为网络对于min(h,w)>8的块采用卷积处理。所以如果min(h,w)<=8则预处理后输出的
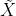 是
是  维向量,否则
维向量,否则 
网络结构
如果min(h,w)<=8,则网络结构是全连接网络,如表1,

对于16x16的块使用卷积网络,且该网络由3个子网络构成,如Fig.3,
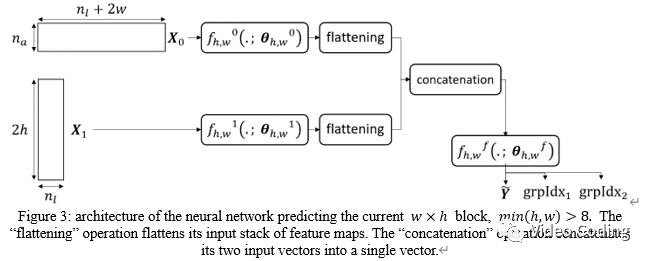
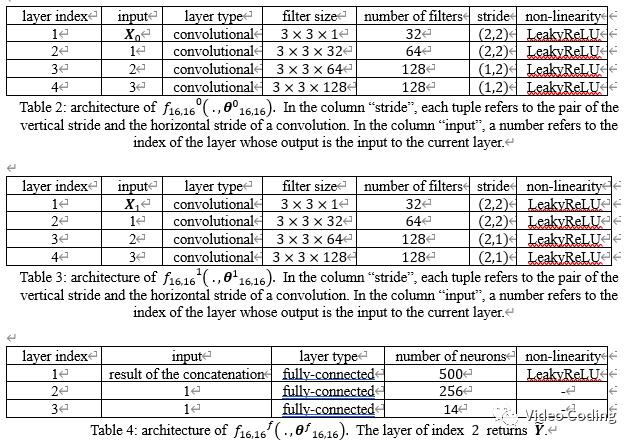
3个子网络的具体结构如表2、3、4,
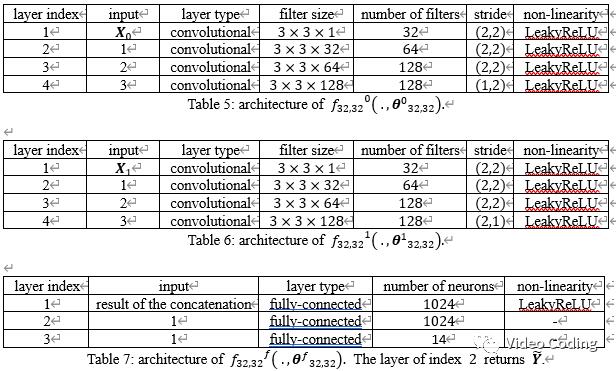
对于32x32的块也使用卷积网络,且该网络也由3个子网络构成,如Fig.3,各子网络的结构如表5、6、7,
后处理操作
Fig.1中的后处理操作包括将输入reshape为wxh尺寸,加上可获取的参考像素的均值u,然后乘以2^(b-8),
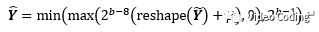
LFNST选择
如Fig.1,网络模型的输出还包含grpIdx1,gapIdx2。根据grpIdx1,gapIdx2可以选择LFNST的变换核和是否对变换系数进行转置,如表8。

模型传输
亮度块的模型标志位传输
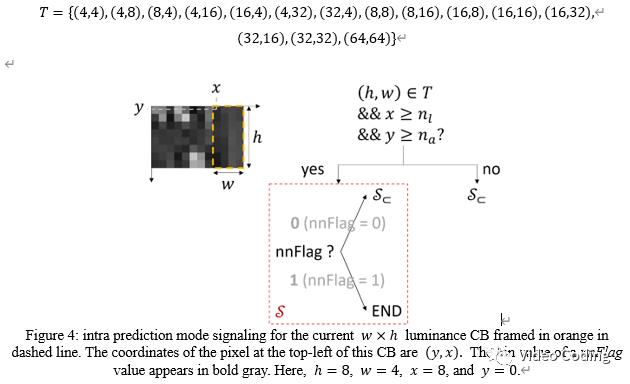
VVC码流中通过nnFlag标志位表示帧内预测是否使用神经网络。如果亮度块wxh的尺寸满足T且参考像素未超出图像边界则码流中会传输nnFlag标志位,否则只使用传统帧内预测模式。
色度块的模型标志位传输
如果色度块对应的亮度块使用神经网络进行帧内预测,且色度块的尺寸满足T,则DM用于表示色度块是否使用神经网络,否则DM还是表示PLANAR模式。
上下文信息传输
在神经网络处理流程中,预处理阶段可能会垂直下采样、水平下采样、转置等,这些上下文信息规定如下,
LFNST的预测编码
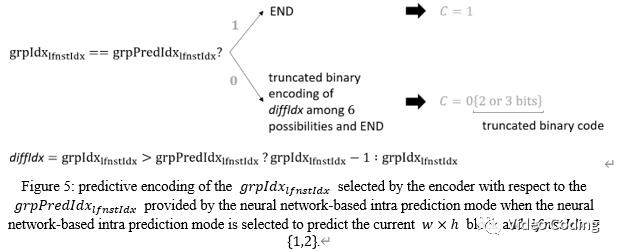
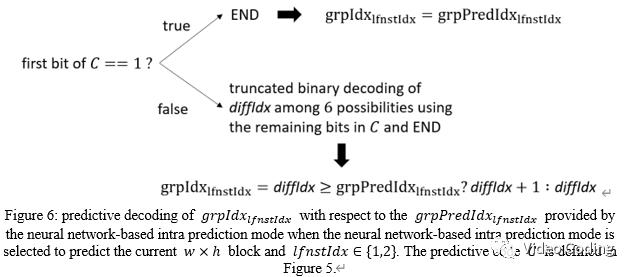
grpIdx可以采用预测编码,编码端和解码端分别如Fig.5和Fig.6,
实验结果
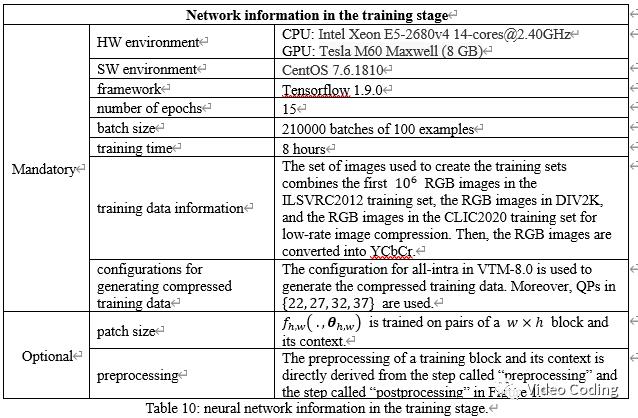
模型训练细节如表10,
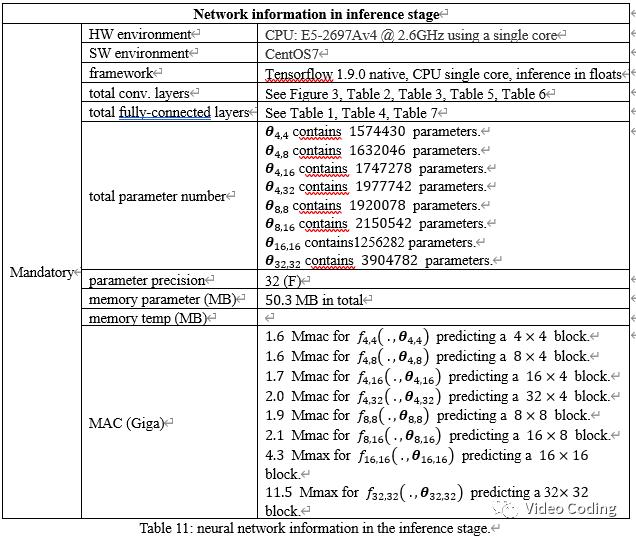
模型推导如表11,
实验结果如下,
加上LFNST参数的预测编码后结果为,
感兴趣的请关注微信公众号Video Coding

以上是关于基于神经网络的帧内预测和变换核选择的主要内容,如果未能解决你的问题,请参考以下文章