初学hadoop,基于 Hadoop API 和 Java 实现将HDFS的/hadoop/.bashrc文件权限改为rwxr-xr-x
Posted 到底懂不懂啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初学hadoop,基于 Hadoop API 和 Java 实现将HDFS的/hadoop/.bashrc文件权限改为rwxr-xr-x相关的知识,希望对你有一定的参考价值。
希望计网一班的同学能理解
以下是基于 Hadoop API 和 Java 实现更改 HDFS 文件权限的示例代码:
//第一种方法
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.permission.FsAction;
import org.apache.hadoop.fs.permission.FsPermission;
import java.io.IOException;
public class ChangeHdfsFilePermission
public static void main(String[] args) throws IOException
// 定义 HDFS 连接配置
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
// 创建 FileSystem 对象
FileSystem fs = FileSystem.get(conf);
// 定义目标文件路径及权限
Path filePath = new Path("/hadoop/.bashrc");
FsPermission permission = new FsPermission(FsAction.ALL, FsAction.READ_EXECUTE, FsAction.READ_EXECUTE);
// 更改文件权限
fs.setPermissionfs(filePath, permission);
System.out.println(filePath + " 权限更改为:" + permission);
// 关闭 FileSystem 连接
fs.close();
更改权限用setPermission(new Path,new FsPermission)方法,第一个参数表示要更改权限的文件或目录,第二个参数表示文件更改后的权限级别。
在 Hadoop HDFS API 中,FsPermission 是用于表示文件或目录权限的类,它包含以下成员变量:short permission:以八进制表示的文件或目录权限值。FsAction userAction、groupAction、otherAction:分别表示权限属主、组和其他用户所拥有的操作权限。同时,FsPermission 还提供了一些常用的方法来获取、设置文件或目录权限,如:getPermission():返回以“rwxr-xr-x”这种格式表示的权限字符串。getUserAction()、getGroupAction()、getOtherAction():返回对应的权限操作对象。applyUMask(FsPermission umask):根据指定的 UMask 对象将当前权限对象的权限数值与 UMask 的权限数值进行按位与运算,并返回新的权限对象。例如,下面的示例代码展示了如何在HDFS中创建一个目录并设置目录权限:
//第二种方法
// 创建配置对象并获取 HDFS 文件系统实例
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
// 要修改权限的文件路径
Path filePath = new Path("/hadoop/.bashrc");
// 获取该文件的原始权限
FsPermission originalPermission = fs.getFileStatus(filePath).getPermission();
// 设置新的权限
FsPermission newPermission = new FsPermission((short) 0755);
// 修改文件权限
fs.setPermission(filePath, newPermission);
System.out.println("成功将 " + filePath + " 的权限修改为:" + newPermission);
上述示例中,我们首先创建了一个 Configuration 对象以及一个 HDFS 文件系统实例。然后,我们指定要修改权限的文件路径,并使用 getFileStatus 方法查询该文件的原始权限。接着,我们生成一个新的 FsPermission 对象,将要修改的权限值设置为 0755,最后使用 setPermission 方法将新的权限设置给指定的文件。
老师,IDEA如何在本地运行和调试Hadoop程序?
来源:http://1t.click/aH32
# 前言
# 简介
Maven
Intellij IDEA
环境要求
WordCount
新建项目
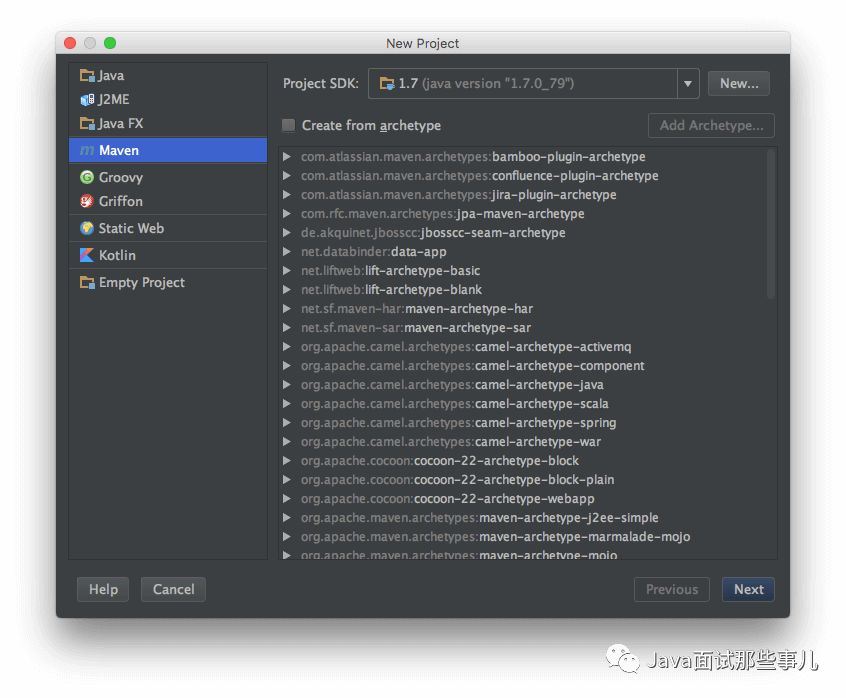
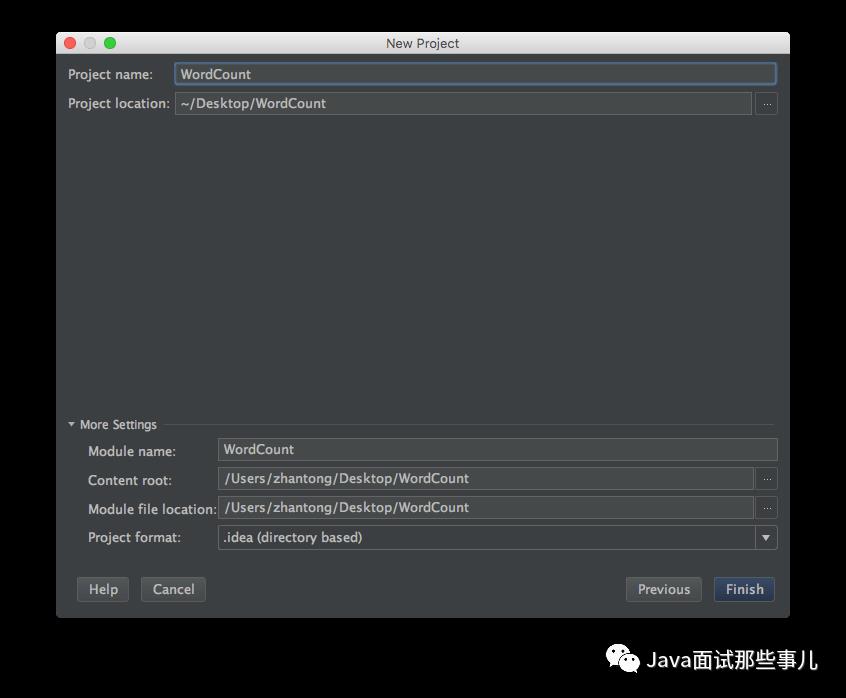
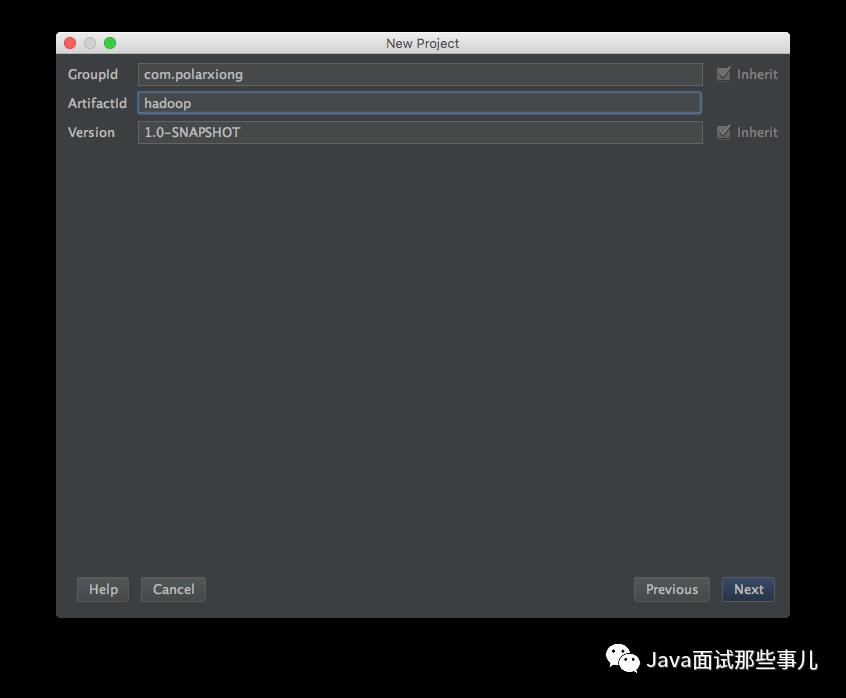
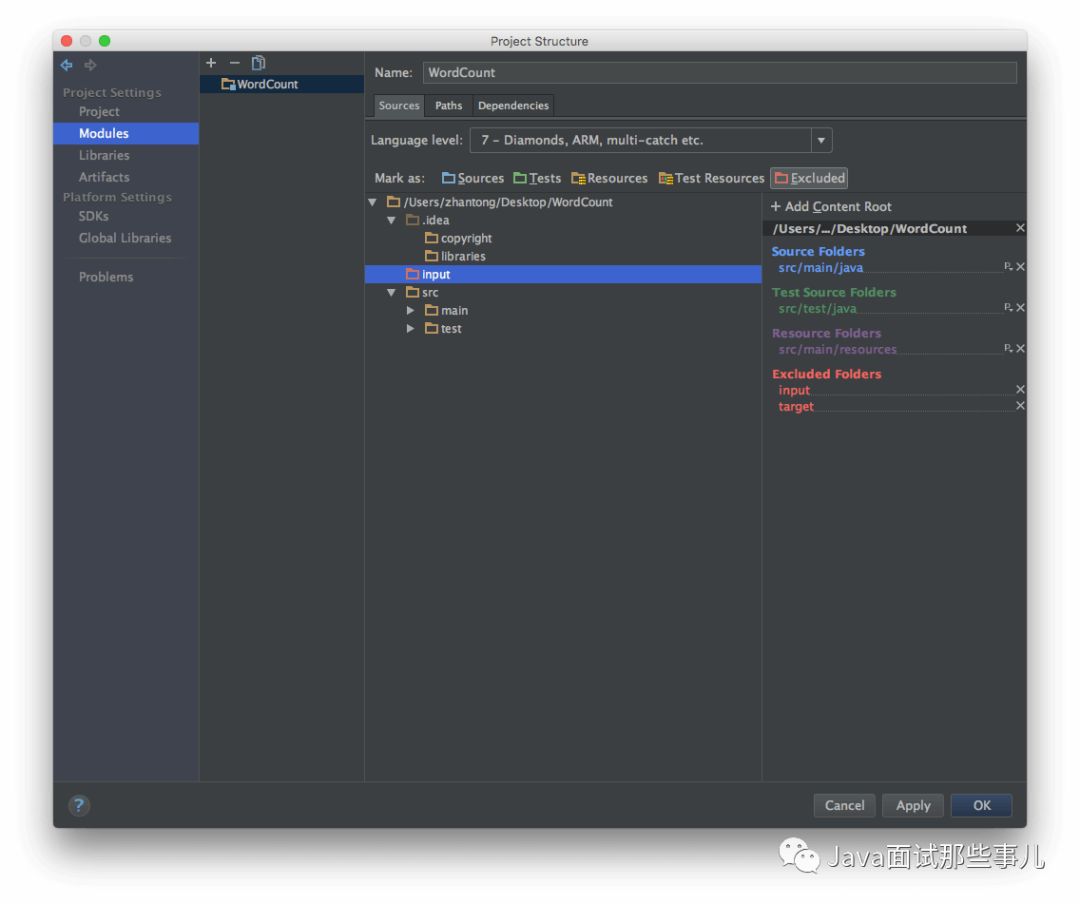
添加源
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.polarxiong</groupId><artifactId>hadoop</artifactId><version>1.0-SNAPSHOT</version></project>在project内尾部添加
<repositories><repository><id>apache</id><url>http://maven.apache.org</url></repository></repositories>
添加依赖
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-core</artifactId><version>1.2.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.2</version></dependency></dependencies>这里hadoop-core的version一般为1.2.1,hadoop-common的version可以依照你的实际需要来。
XML
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.polarxiong</groupId><artifactId>hadoop</artifactId><version>1.0-SNAPSHOT</version><repositories><repository><id>apache</id><url>http://maven.apache.org</url></repository></repositories><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-core</artifactId><version>1.2.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.2</version></dependency></dependencies></project>
WordCount
import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCount {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}public static class IntSumReducerextends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}
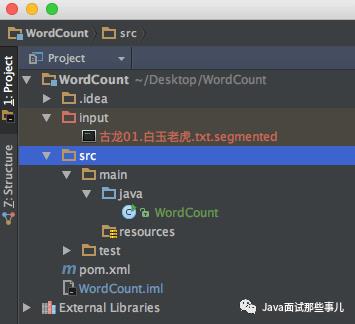
配置输入文件
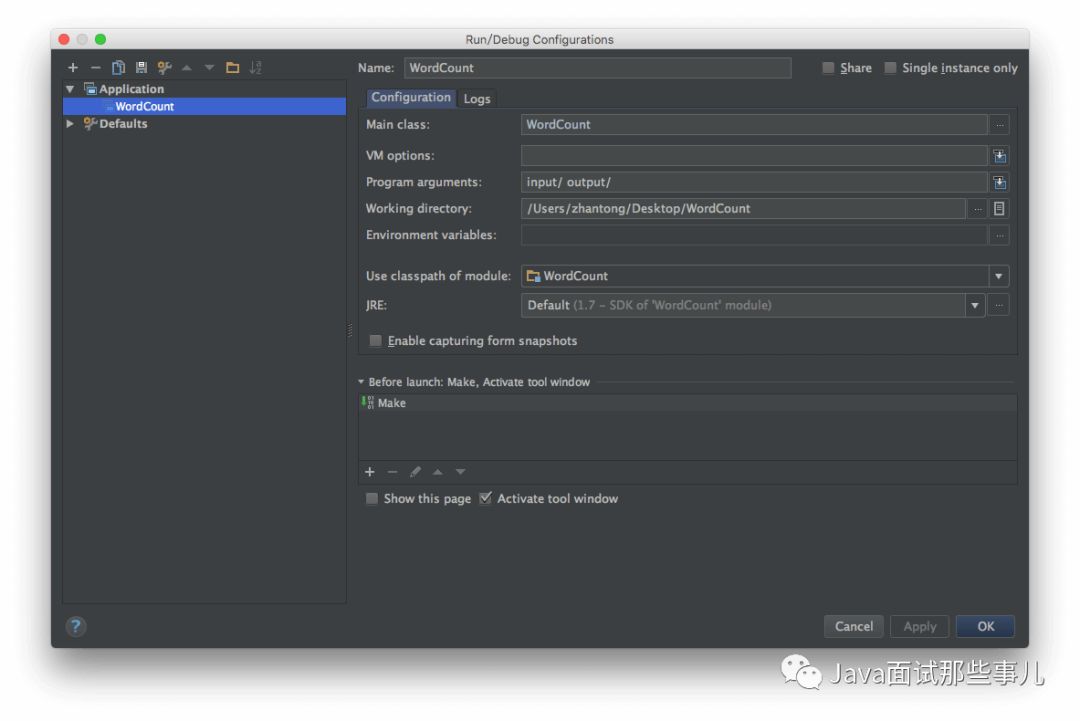
运行
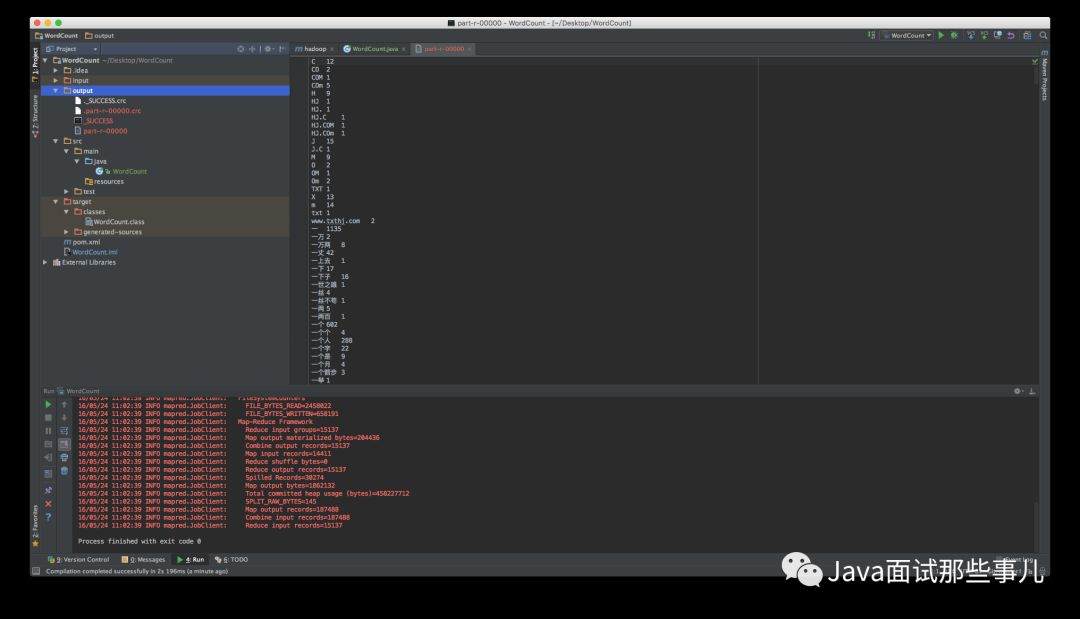
调试
<code class="language-plain hljs" style="background:transparent;word-spacing:normal;line-height:inherit;border:0px;display:inline;"><span style="font-family:'Comic Sans MS';font-size:14px;">ERROR security.UserGroupInformation: PriviledgedActionException as ...<span class="line-numbers-rows" style="letter-spacing:-1px;border-right:1px solid rgb(153,153,153);"><span style="display:block;"></span></span></span></code>
这是因为当前用户没有权限来设置路径权限(Linux无此问题),一个解决方法是给hadoop打补丁,参考Failed to set permissions of path: mp ,因为这里使用的Maven,此方法不太适合。另一个方法是将当前用户设置为超级管理员(“计算机管理”,“本地用户和组”中设置),或以超级管理员登录运行此程序。
# 小结
同时,分享一份Java面试资料给大家,覆盖了算法题目、常见面试题、JVM、锁、高并发、反射、Spring原理、微服务、Zookeeper、数据库、数据结构等等
以上是关于初学hadoop,基于 Hadoop API 和 Java 实现将HDFS的/hadoop/.bashrc文件权限改为rwxr-xr-x的主要内容,如果未能解决你的问题,请参考以下文章