最强面试题整理第一弹:Python 基础面试题(附答案)
Posted Rocky0429
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最强面试题整理第一弹:Python 基础面试题(附答案)相关的知识,希望对你有一定的参考价值。
大家好呀,我是 Rocky0429。
Python 面试的时候,会涉及到很多的八股文,我结合自己的经验,整理Python 最强面试题。
Python 最强面试题主要包括以下几方面:
- Python 基础(已完成)
- Python 进阶
- Python 后台开发
- 爬虫
- 机器学习
对每道面试题会附带详细的答案,无论是准备面试还是自己学习,这份面试题绝对值得你去看,去学习。
1、什么是 Python?
Python 是一种编程语言,它有对象、模块、线程、异常处理和自动内存管理,可以加入其他语言的对比。
Python 是一种解释型语言,Python 在代码运行之前不需要解释。
Python 是动态类型语言,在声明变量时,不需要说明变量的类型。
Python 适合面向对象的编程,因为它支持通过组合与继承的方式定义类。
在 Python 语言中,函数是第一类对象。
Python 代码编写快,但是运行速度比编译型语言通常要慢。
Python 用途广泛,常被用走"胶水语言",可帮助其他语言和组件改善运行状况。
使用 Python,程序员可以专注于算法和数据结构的设计,而不用处理底层的细节。
2、赋值、浅拷贝和深拷贝的区别?
(1) 赋值
在 Python 中,对象的赋值就是简单的对象引用,这点和 C++不同,如下所示:
a = [1,2,"hello",['python', 'C++']]
b = a
在上述情况下,a 和 b 是一样的,他们指向同一片内存,b 不过是 a 的别名,是引用。
我们可以使用 b is a 去判断,返回 True,表明他们地址相同,内容相同,也可以使用 id() 函数来查
看两个列表的地址是否相同。
赋值操作(包括对象作为参数、返回值)不会开辟新的内存空间,它只是复制了对象的引用。也就是说除了 b 这个名字之外,没有其他的内存开销。修改了 a,也就影响了 b,同理,修改了 b,也就影响了 a。
(2) 浅拷贝
浅拷贝会创建新对象,其内容非原对象本身的引用,而是原对象内第一层对象的引用。
浅拷贝有三种形式:切片操作、工厂函数、copy 模块中的 copy 函数。
比如上述的列表 a,切片操作:b = a[:] 或者 b = [x for x in a];
工厂函数:b = list(a);
copy 函数:b = copy.copy(a);
浅拷贝产生的列表 b 不再是列表 a 了,使用 is 判断可以发现他们不是同一个对象,使用 id 查看,他们也不指向同一片内存空间。但是当我们使用 id(x) for x in a 和 id(x) for x in b 来查看 a 和 b 中元素的地址时,可以看到二者包含的元素的地址是相同的。
在这种情况下,列表 a 和 b 是不同的对象,修改列表 b 理论上不会影响到列表 a。
但是要注意的是,浅拷贝之所以称之为浅拷贝,是它仅仅只拷贝了一层,在列表 a 中有一个嵌套的 list,如果我们修改了它,情况就不一样了。
比如:a[3].append(‘java’),查看列表 b,会发现列表 b 也发生了变化,这是因为,我们修改了嵌套的 list,修改外层元素,会修改它的引用,让它们指向别的位置,修改嵌套列表中的元素,列表的地址并未发生变化,指向的都是用一个位置。
(3) 深拷贝
深拷贝只有一种形式,copy 模块中的 deepcopy() 函数。
深拷贝和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。因此,它的时间和空间开销要高。
同样的对列表 a,如果使用 b = copy.deepcopy(a),再修改列表 b 将不会影响到列表 a,即使嵌套的列表具有更深的层次,也不会产生任何影响,因为深拷贝拷贝出来的对象根本就是一个全新的对象,不再与原来的对象有任何的关联。
(4) 注意点
对于非容器类型,如数字、字符,以及其他的“原子”类型,没有拷贝一说,产生的都是原对象的引用。
如果元组变量值包含原子类型对象,即使采用了深拷贝,也只能得到浅拷贝。
3、init 和__new__的区别?
当我们使用「类名()」创建对象的时候,Python 解释器会帮我们做两件事情:第一件是为对象在内存分配空间,第二件是为对象进行初始化。「分配空间」是__new__ 方法,初始化是__init__方法。
new 方法在内部其实做了两件时期:第一件事是为「对象分配空间」,第二件事是「把对象的引用返回给 Python 解释器」。当 Python 的解释器拿到了对象的引用之后,就会把对象的引用传递给 init 的第一个参数 self,init 拿到对象的引用之后,就可以在方法的内部,针对对象来定义实例属性。
之所以要学习 new 方法,就是因为需要对分配空间的方法进行改造,改造的目的就是为了当使用「类名()」创建对象的时候,无论执行多少次,在内存中永远只会创造出一个对象的实例,这样就可以达到单例设计模式的目的。
4、Python 的变量、对象以及引用?
首先把结论抛出来:
-
变量是到内存空间的一个指针,也就是拥有指向对象连接的空间;
-
对象是一块内存,表示它们所代表的值;
-
引用就是自动形成的从变量到对象的指针。
以下是具体解释:
在 Python 中使用变量的时候不需要提前声明变量及其类型,变量还是会正常工作。在 Python 中,这个是以一种非常流畅的方式完成,下面以 a = 1 为例我们来看一下它到底是个什么情况。
首先是怎么知道创建了变量:对于变量 a,或者说是变量名 a,当程序第一次给它赋值的时候就创建了它,其实真实情况是 Python 在代码运行之前就先去检测变量名,我们不去具体深究这些,你只需要当作是「最开始的赋值创建了变量」。
再者是怎么知道变量是什么类型:其实这个很多人都没有搞清楚,「类型」这个概念不是存在于变量中,而是存在于对象中。变量本身就是通用的,它只是恰巧在某个时间点上引用了当时的特定对象而已。就比如说在表达式中,我们用的那个变量会立马被它当时所引用的特定对象所替代。
上面这个是动态语言明显区别于静态语言的地方,其实对于刚开始来说,如果你适应将「变量」和「对象」分开,动态类型你也就可以很容易理解了。
我们还是以 a = 1 为例,其实从上面的讲述中,我们很容易的可以发现对于 a = 1 这个赋值语句 Python 是如何去执行它的:创建一个代表值 1 的对象 --> 创建一个变量 a --> 将变量 a 和对象 1 连接。 下面我用一个图来更清晰的表示一下:

由上图我们可以看出,变量 a 其实变成了对象 1 的一个引用。如果你学过指针的话,你就会发现在内部「变量其实就是到对象内存空间的一个指针」。
同样还是上图,我们还可以看出在 Python 中「引用」是从变量到对象的连接,它就是一种关系,在内存中以指针的形式实现。
另外,我也打包成 PDF 方便阅读。
5、创建百万级实例如何节省内存?
可以定义类的 slot 属性,用它来声明实例属性的列表,可以用来减少内存空间的目的。
具体解释:
首先,我们先定义一个普通的 User 类:
class User1:
def __init__(self, id, name, sex, status):
self.id = id
self.name = name
self.sex = sex
self.status = status
然后再定义一个带 slot 的类:
class User2:
__slots__ = ['id', 'name', 'sex', 'status']
def __init__(self, id, name, sex, status):
self.id = id
self.name = name
self.sex = sex
self.status = status
接下来创建两个类的实例:
u1 = User1('01', 'rocky', '男', 1)
u2 = User1('02', 'leey', '男', 1)
我们已经知道 u1 比 u2 使用的内存多,我们可以这样来想,一定是 u1 比 u2 多了某些属性,我们分别来看一下 u1 和 u2 的属性:
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'id', 'name', 'sex', 'status']
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', 'id', 'name', 'sex', 'status']
乍一看好像差别不大,我们下面具体来看一下差别在哪:
set(dir(u1)) - set(dir(u2))
通过做集合的差集,我们得到 u1 和 u2 在属性上的具体差别:
'__weakref__', '__dict__'
在我们不使用弱引用的时候,weakref 并不占用多少内存,那最终这个锅就要 dict 来背了。
下面我们来看一下 dict:
u1.__dict__
输出结果如下所示:
'id': '01', 'name': 'rocky', 'sex': '男', 'status': 1
输出一个字典,在它内部我们发现了刚刚在类里定义的属性,这个字典就是为了实例动态绑定属性的一个字典,我们怎么动态绑定呢?比如我们现在没有 u1.level 这个属性,那么我们可以为它动态绑定一个 level 属性,比如 u1.level = 10,然后我们再来考察这个字典:
u1.__dict__
现在输出的结果为:
'id': '01', 'name': 'rocky', 'sex': '男', 'status': 1, 'level': 10
这样看到 level 进入到这个字典中。
这样一个动态绑定属性的特性,其实是以牺牲内存为代价的,因为这个 dict 它本身是占用内存的,接下来我们来验证这件事情:
import sys
sys.getsizeof(u1.__dict__)
我们用 sys 模块下的 getsizeof 方法,它可以得到一个对象使用的内存:
112
我们可以看到这个字典占用了 112 的字节。反观 u2,它没有了 dict 这个属性,我们想给它添加一个属性,也是被拒绝的。
u2.level = 10
显示的结果如下所示:
AttributeError: 'User2' object has no attribute 'level'
6、Python 里面如何生成随机数?
在 Python 中用于生成随机数的模块是 random,在使用前需要 import. 如下例子可以酌情列举:
random.random():生成一个 0-1 之间的随机浮点数
random.uniform(a, b):生成[a,b]之间的浮点数
random.randint(a, b):生成[a,b]之间的整数
random.randrange(a, b, step):在指定的集合[a,b)中,以 step 为基数随机取一个数
random.choice(sequence):从特定序列中随机取一个元素,这里的序列可以是字符串,列表,元组等。
7、Python 是强语言类型还是弱语言类型?
Python 是强类型的动态脚本语言。
强类型:不允许不同类型相加。
动态:不使用显示数据类型声明,且确定一个变量的类型是在第一次给它赋值的时候。
脚本语言:一般也是解释型语言,运行代码只需要一个解释器,不需要编译。
8、谈一下什么是解释性语言,什么是编译性语言?
计算机不能直接理解高级语言,只能直接理解机器语言,所以必须要把高级语言翻译成机器语言,计算机才能执行高级语言编写的程序。
解释性语言在运行程序的时候才会进行翻译。
编译型语言写的程序在执行之前,需要一个专门的编译过程,把程序编译成机器语言(可执行文件)。
9、Python 中有日志吗?怎么使用?
Python 中有日志,Python 自带 logging 模块,调用 logging.basicConfig()方法,配置需要的日志等级和相应的参数,Python 解释器会按照配置的参数生成相应的日志。
补充知识:
Python 的标准日志模块
Python 标准库中提供了 logging 模块供我们使用。在最简单的使用中,默认情况下 logging 将日志打印到屏幕终端,我们可以直接导入 logging 模块,然后调用 debug,info,warn,error 和 critical 等函数来记录日志,默认日志的级别为 warning,级别比 warning 高的日志才会被显示(critical > error > warning > info > debug),「级别」是一个逻辑上的概念,用来区分日志的重要程度。
import logging
logging.debug('debug message')
logging.info("info message")
logging.warn('warn message')
logging.error("error message")
logging.critical('critical message')
上述代码的执行结果如下所示:
WARNING:root:warn message
ERROR:root:error message
CRITICAL:root:critical message
我在上面说过,用 print 的话会产生大量的信息,从而很难从中找到真正有用的信息。而 logging 中将日志分成不同的级别以后,我们在大多数时间只保存级别比较高的日志信息,从而提高了日志的性能和分析速度,这样我们就可以很快速的从一个很大的日志文件里找到错误的信息。
配置日志格式
我们在用 logging 来记录日志之前,先来进行一些简单的配置:
import logging
logging.basicConfig(filename= 'test.log', level= logging.INFO)
logging.debug('debug message')
logging.info("info message")
logging.warn('warn message')
logging.error("error message")
logging.critical('critical message')
运行上面的代码以后,会在当前的目录下新建一个 test.log 的文件,这个文件中存储 info 以及 info 以上级别的日志记录。运行一次的结果如下所示:
INFO:root:info message
WARNING:root:warn message
ERROR:root:error message
CRITICAL:root:critical message
上面的例子中,我是用 basicConfig 对日志进行了简单的配置,其实我们还可以进行更为复杂些的配置,在此之前,我们先来了解一下 logging 中的几个概念:
Logger:日志记录器,是应用程序中可以直接使用的接口。
Handler:日志处理器,用以表明将日志保存到什么地方以及保存多久。
Formatter:格式化,用以配置日志的输出格式。
上述三者的关系是:一个 Logger 使用一个 Handler,一个 Handler 使用一个 Formatter。那么概念我们知道了,该如何去使用它们呢?我们的 logging 中有很多种方式来配置文件,简单的就用上面所说的 basicConfig,对于比较复杂的我们可以将日志的配置保存在一个配置文件中,然后在主程序中使用 fileConfig 读取配置文件。
基本的知识我们知道了,下面我们来做一个小的题目:日志文件保存所有 debug 及其以上级别的日志,每条日志中要有打印日志的时间,日志的级别和日志的内容。请先自己尝试着思考一下,如果你已经思考完毕请继续向下看:
import logging
logging.basicConfig(
level= logging.DEBUG,
format = '%(asctime)s : %(levelname)s : %(message)s',
filename= "test.log"
)
logging.debug('debug message')
logging.info("info message")
logging.warn('warn message')
logging.error("error message")
logging.critical('critical message')
上述代码的一次运行结果如下:
2018-10-19 22:50:35,225 : DEBUG : debug message
2018-10-19 22:50:35,225 : INFO : info message
2018-10-19 22:50:35,225 : WARNING : warn message
2018-10-19 22:50:35,225 : ERROR : error message
2018-10-19 22:50:35,225 : CRITICAL : critical message
我刚刚在上面说过,对于比较复杂的我们可以将日志的配置保存在一个配置文件中,然后在主程序中使用 fileConfig 读取配置文件。下面我们就来看一个典型的日志配置文件(配置文件名为 logging.conf):
[loggers]
keys = root
[handlers]
keys = logfile
[formatters]
keys = generic
[logger_root]
handlers = logfile
[handler_logfile]
class = handlers.TimedRotatingFileHandler
args = ('test.log', 'midnight', 1, 10)
level = DEBUG
formatter = generic
[formatter_generic]
format = %(asctime)s %(levelname)-5.5s [%(name)s:%(lineno)s] %(message)s
在上述的日志配置文件中,首先我们在 [loggers] 中声明了一个叫做 root 的日志记录器(logger),在 [handlers] 中声明了一个叫 logfile 的日志处理器(handler),在 [formatters] 中声明了一个名为 generic 的格式化(formatter)。之后在 [logger_root] 中定义 root 这个日志处理器(logger) 所使用的日志处理器(handler) 是哪个,在 [handler_logfile] 中定义了日志处理器(handler) 输出日志的方式、日志文件的切换时间等。最后在 [formatter_generic] 中定义了日志的格式,包括日志的产生时间,级别、文件名以及行号等信息。
有了上述的配置文件以后,我们就可以在主代码中使用 logging.conf 模块的 fileConfig 函数加载日志配置:
import logging
import logging.config
logging.config.fileConfig('logging.conf')
logging.debug('debug message')
logging.info("info message")
logging.warn('warn message')
logging.error("error message")
logging.critical('critical message')
上述代码的运行一次的结果如下所示:
2018-10-19 23:00:02,809 WARNI [root:8] warn message
2018-10-19 23:00:02,809 ERROR [root:9] error message
2018-10-19 23:00:02,809 CRITI [root:10] critical message
10、Python 是如何进行类型转换的?
内建函数封装了各种转换函数,可以使用目标类型关键字强制类型转换,进制之间的转换可以用 int(‘str’,base=‘n’)将特定进制的字符串转换为十进制,再用相应的进制转换函数将十进制转换为目标进制。
可以使用内置函数直接转换的有:
list---->tuple tuple(list)
tuple---->list list(tuple)
另外,我也打包成 PDF 方便阅读。
11、Python 中的作用域?
Python 中,一个变量的作用域总是由在代码中被赋值的地方所决定。当 Python 遇到一个变量的话它会按照这的顺序进行搜索:
本地作用域(Local)—>当前作用域被嵌入的本地作用域(Enclosing locals)—>全局/模块作用域
(Global)—>内置作用域(Built-in)。
12、什么是 Python 自省?
Python 自省是 Python 具有的一种能力,使程序员面向对象的语言所写的程序在运行时,能够获得对象的类 Python 型。
Python 是一种解释型语言,为程序员提供了极大的灵活性和控制力。
13、什么是 Python 的命名空间?
命名空间,又名 namesapce,是在很多的编程语言中都会出现的术语,趁着这个题顺便给大家仔细介绍一下。
全局变量 & 局部变量
全局变量和局部变量是我们理解命名空间的开始,我们先来看一段代码:
x = 2
def func():
x = 3
print('func x ---> ',x)
func()
print('out of func x ---> ',x)
这段代码输出的结果如下:
func x ---> 3
out of func x ---> 2
从上述的结果中可以看出,运行 func(),输出的是 func() 里面的变量 x 所引用的对象 3,之后执行的是代码中的最后一行。这里要区分清楚,前一个 x 输出的是函数内部的变量 x,后一个 x 输出的是函数外的变量 x,两个变量互相不影响,在各自的作用域中起作用。
那个只在函数内起作用的变量就叫 “局部变量”,有了 “局部” 就有相应的 “全部”,但是后者听起来有歧义,所以就叫了 “全局”。
x = 2
def func():
global x = 3 #注意此处
print('func x ---> ',x)
func()
print('out of func x ---> ',x)
这段代码中比上段代码多加了一个 global x,这句话的意思是在声明 x 是全局变量,通俗点说就是这个 x 和 函数外的 x 是同一个了,所以结果就成了下面这样:
func x ---> 3
out of func x ---> 3
这样乍一看好像全局变量好强,可以管着函数内外,但是我们还是要注意,全局变量还是谨慎使用的好,因为毕竟内外有别,不要带来混乱。
作用域
作用域,用比较直白的方式来说,就是程序中变量与对象存在关联的那段程序,比如我在上面说的, x = 2 和 x = 3 是在两个不同的作用域中。
通常的,作用域是被分为静态作用域和动态作用域,虽然我们说 Python 是动态语言,但是它的作用域属于静态作用域,即 Python 中的变量的作用域是由该变量所在程序中的位置所决定的。
在 Python 中作用域被划分成四个层级,分别是:local(局部作用域),enclosing(嵌套作用域),global(全局作用域)和 built - in(内建作用域)。对于一个变量,Python 也是按照之前四个层级依次在不用的作用域中查找,我们在上一段代码中,对于变量 x,首先搜索的是函数体内的局部作用域,然后是函数体外的全局作用域,至于这段话具体怎么来理解,请看下面的例子:
def out_func():
x = 2
def in_func():
x = 3
print('in_func x ---> ',x)
in_func()
print('out_func x ---> ',x)
x = 4
out_func()
print('x == ',x)
上述代码运行的结果是:
in_func x ---> 3
out_func x ---> 2
x == 4
仔细观察一下上面的代码和运行的结果,你就会发现变量在不同的范围内进行搜索的规律,是不是感觉这些都是以前被你忽略的呢?
命名空间
《维基百科》中说 “命名空间是对作用域的一种特殊的抽象”,在这里我用一个比方来具体说明一下:
比如张三在公司 A,他的工号是 111,李四在公司 B,他的工号也是 111,因为两个人在不同的公司,他们俩的工号可以相同但是不会引起混乱,这里的公司就表示一个独立的命名空间,如果两个人在一个公司的话,他们的工号就不能相同,否则光看工号也不知道到底是谁。
其实上面举的这个例子的特点就是我们使用命名空间的理由,在大型的计算机程序中,往往会出现成百上千的标识符,命名空间提供隐藏区域标识符的机制。通过将逻辑上相关的标识符构成响应的命名空间,可以使整个系统更加的模块化。
我在开头引用的《维基百科》的那句话说 “命名空间是对作用域的一种特殊的抽象”,它其实包含了处于该作用域内的标识符,且它本身也用一个标识符来表示。在 Python 中,命名空间本身的标识符也属于更外层的一个命名空间,所以命名空间也是可以嵌套的,它们共同生活在 “全局命名空间” 下。
简言之,不同的命名空间可以同时存在,但是彼此独立,互不干扰。当然了,命名空间因为其对象的不同也有所区别,可以分为以下几种:
-
1.本地命名空间:模块中有函数或者类的时候,每个函数或者类所定义的命名空间即是本地命名空间,当函数返回结果或者抛出异常的时候,本地命名空间也就结束了。
-
2.全局命名空间:每个模块创建了自己所拥有的全局命名空间,不同模块的全局命名空间彼此独立,不同模块中相同名称的命名空间也会因为模块的不同而不相互干扰。
-
3.内置命名空间:当 Python 运行起来的时候,它们就存在了,内置函数的命名空间都属于内置命名空间,所以我们可以在任何程序中直接运行它们。
程序查询命名空间的时候也有一套顺序,依次按照本地命名空间 ,全局命名空间,内置命名空间。
def fun(like):
name = 'rocky'
print(locals())
fun('python')
访问本地命名空间使用 locals 完成,我们来看一下结果:
'name': 'rocky', 'like': 'python'
从上面的结果中可以看出,命名空间中的数据存储的结构和字典是一样的。可能你已经猜到了,当我们要访问全局命名空间的时候,可以使用 globals。
关于命名空间还有一个生命周期的问题,就是一个命名空间什么时候出现,什么时候消失,这个很好理解,就是哪部分被读入内存,哪部分的命名空间就存在了,比如我们在上面说的,Python 启动,内置命名空间就建立。
14、你所遵循的代码规范是什么?
PEP 8 编码风格
Python 代码从第一眼看上去,给人的感觉就是简洁优美,可读性强,也就是我们日常所说的「高颜值」。一方面是因为 Python 自身的优秀设计,比如统一的锁进,没有多余的符号从而让代码变的更加简洁;另一方面就是因为它有着一套较为统一的编码风格,当然它本身只是编码风格方面的建议而不是强制,相应的在编写 Python 代码的编辑器自动提供 PFP 8 检查,当你编写的代码违反了 PEP 8 规范的时候,会给出警告信息和修正的建议。与此同时,还有专门的检查工具对 Python 的代码风格进行检查。
由上,还是建议在编写 Python 代码的时候都遵循 PEP 8 编码规范,毕竟你以后不可能是只一个人写代码,未来不论是在公司或者某些开源项目中,作为其中的一份子,肯定还是要在风格上向大众看齐的。
PEP 8 编码规范详细的给出了 Python 编码的指导,包括什么对齐啦,包的导入顺序啦,空格和注释啦还有命名习惯等方方面面,并且还有详细的事例。
下面我以「包」的导入为例,看一下 PEP 8 给出的具体编程指导。在 Python 中, import 应该一次只导入一个模块,不同的模块应该独立一行:
import pandas
import numpy
反面例子:
import pandas,numpy
如果想要从一个模块里面导入多个,也可以像下面这样:
from subprocess import Popen, PIPE
import 语句应该处于源码文件的顶部,位于模块注释和文档字符串之后,全局变量和常量之前。在导入不同的库的时候,应该按照以下的顺序分组,各个分组之间以空行分隔:
-
导入标准库模块
-
导入相关第三方库模块
-
导入当前应用程序/库模块
具体事例如下所示:
import os
import time
import psutil
from test import u_test,my_test
Python 中还支持相对导入和绝对导入,在这里还是强推绝对导入。因为绝对导入的可读性更好一些,也不容易出错,即使出错了也会给出更加详细的错误信息。具体如下所示:
from sub_package import tools
from sub_package.tools import msg
当然除了上述以外还有更多对于包的规范的描述,PEP 8 的编码风格指导比较长,并且写的非常详细,所以我就不在这一一介绍了,详细的可以参考 Python 官网上的资料。
pycodestyle 检查代码规范
我在上面说过 PEP 8 只是官方给出的 Python 编码规范,并没有强制要求大家都遵守,但是又由于大家都在用,所以它也就变成了事实上的 Python 代码风格标准,既然都是标准了,那么就应该有工具来检查这个标准,这样可以帮助 Python 小白规范自己的代码,也可以帮助大家在开源或者工作中形成统一的代码风格。
为了达成上述的目的,官方提供了同名的命令行工具来检查 Python 代码是否违反了 PEP 8 规范,并且对违反规范的地方给出了相应的提示信息。
pip install pep8
规范的名字是 PEP 8 ,这个检查代码风格的命令行工具叫 pep8,这个很容易引起大家的困惑,因此 Python 之父建议将 pep8 重新命名为 pycodestyle,下面我们来看一下 pycodestyle 的用法。
首先通过 pip 安装一下:
pip install pycodestyle
对一个或者多个文件运行 pycodestyle,打印检查报告:

通过 --show-source 显示不符合规范的源码,以便程序员进行修改,具体如下所示:

autopep8 格式化代码
autopep8 能够将 Python 代码自动格式化为 PEP 8 风格,它使用 pycodestyle 工具来决定代码中的哪部分需要被格式化,这能够修复大部分 pycodestyle 工具中报告的排版问题。autopep8 本身也是一个用 Python 写的工具,所以我们还是可以用 pip 直接安装:
pip install autopep8
它的使用方式也很简单,具体如下所示:
autopep8 --in-place test_search.py
上述代码如果不带 --in-place 的话,会将 autopep8 格式化以后的代码直接输出到控制台。我们可以用这种方式检查 autopep8 的修改,使用 --in-place 则会直接将结果保存到源文件中。在这我继续用上面的例子中用到的 py 文件,具体如下所示:
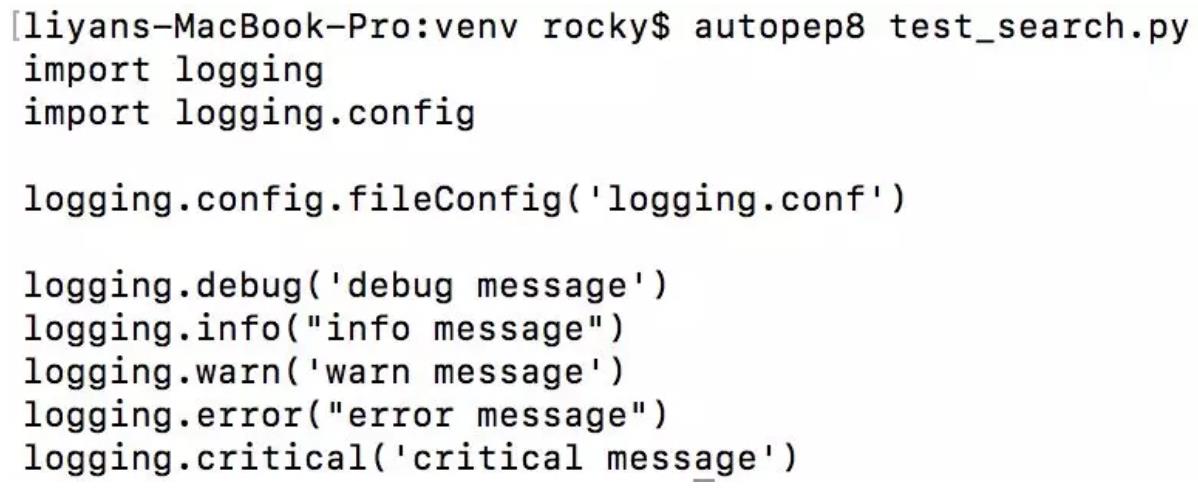
上面的例子中,autopep8 顺利的修复了所有的问题,但是如果你这个时候查看源文件的话,你会发现源文件的内容还是和原来一样,并没有被修改。这个时候我们就要用到 --in-place,加上这个选项将不会有任何输出, autopep8 会直接修改源文件。
autopep8 --in-place test_search.py
15、关于 Python 程序的运行方面,有什么手段能提升性能?
1、使用多进程,充分利用机器的多核性能
2、对于性能影响较大的部分代码,可以使用 C 或 C++ 编写
3、对于 IO 阻塞造成的性能影响,可以使用 IO 多路复用来解决
4、尽量使用 Python 的内建函数
5、尽量使用局部变量
另外,我也打包成 PDF 方便阅读。
16、dict 的 items() 方法与 iteritems() 方法的不同?
items方法将所有的字典以列表方式返回,其中项在返回时没有特殊的顺序
iteritems方法有相似的作用,但是返回一个迭代器对象
17、os.path和sys.path的区别?
os.path是module,包含了各种处理长文件名(路径名)的函数。
sys.path是由目录名构成的列表,Python 从中查找扩展模块( Python 源模块, 编译模块,或者二进制扩展). 启动 Python 时,这个列表从根据内建规则,PYTHONPATH 环境变量的内容, 以及注册表( Windows 系统)等进行初始化。
18、4G 内存怎么读取一个 5G 的数据?
方法一:
通过生成器,分多次读取,每次读取数量相对少的数据(比如 500MB)进行处理,处理结束后
在读取后面的 500MB 的数据。
方法二:
可以通过 linux 命令 split 切割成小文件,然后再对数据进行处理,此方法效率比较高。可以按照行
数切割,可以按照文件大小切割。
在Linux下用split进行文件分割:
模式一:指定分割后文件行数
对与txt文本文件,可以通过指定分割后文件的行数来进行文件分割。
命令:split -l 300 large_file.txt new_file_prefix
模式二:指定分割后文件大小
split -b 10m server.log waynelog
### 19、输入某年某月某日,判断这一天是这一年的第几天?
使用 Python 标准库 datetime
import datetime
def dayofyear():
year = input("请输入年份:")
month = input("请输入月份:")
day = input("请输入天:")
date1 = datetime.date(year=int(year),month=int(month),day=int(day))
date2 = datetime.date(year=int(year),month=1,day=1)
return (date1-date2+1).days
20、说明一下 os.path 和 sys.path 分别代表什么?
os.path 主要是用于对系统路径文件的操作。
sys.path 主要是对 Python 解释器的系统环境参数的操作(动态的改变 Python 解释器搜索路径)。
21、Python 中的 os 模块常见方法?
os.remove() 删除文件
os.rename() 重命名文件
os.walk() 生成目录树下的所有文件
os.chdir() 改变目录
os.mkdir/makedirs 创建目录/多层目录
os.rmdir/removedirs 删除目录/多层目录
os.listdir() 列出指定目录的文件
os.getcwd() 取得当前工作目录
os.chmod() 改变目录权限
os.path.basename() 去掉目录路径,返回文件名
os.path.dirname() 去掉文件名,返回目录路径
os.path.join() 将分离的各部分组合成一个路径名
os.path.split() 返回(dirname(),basename())元组
os.path.splitext() 返回(filename,extension)元组
os.path.getatime\\ctime\\mtime 分别返回最近访问、创建、修改时间
os.path.getsize() 返回文件大小
os.path.exists() 是否存在
os.path.isabs() 是否为绝对路径
os.path.isdir() 是否为目录
os.path.isfile() 是否为文件
22、说一下字典和 json 的区别?
字典是一种数据结构,json 是一种数据的表现形式,字典的 key 值只要是能 hash 的就行,json 的必须是字符串。
23、什么是可变、不可变类型?
可变不可变指的是内存中的值是否可以被改变,不可变类型指的是对象所在内存块里面的值不可以改变,有数值、字符串、元组;可变类型则是可以改变,主要有列表、字典。
24、存入字典里的数据有没有先后排序?
存入的数据不会自动排序,可以使用 sort 函数对字典进行排序。
25、lambda 表达式格式以及应用场景?
lambda函数就是可以接受任意多个参数(包括可选参数)并且返回单个表达式值得函数。
语法:lambda [arg1 [,arg2,…argn]]:expression
def calc(x,y):
return x*y
将上述一般函数改写为匿名函数:
lambda x,y:x*y
应用
(1) lambda函数比较轻便,即用即仍,适合完成只在一处使用的简单功能。
(2) 匿名函数,一般用来给filter,map这样的函数式编程服务
(3) 作为回调函数,传递给某些应用,比如消息处理。
26、如何理解 Python 中字符串中的\\字符?
1、转义字符
2、路径名中用来连接路径名
3、编写太长代码手动软换行
27、常用的 Python 标准库都有哪些?
os 操作系统、time 时间、random 随机、pymysql 连接数据库、threading 线程、multiprocessing
进程、queue 队列
第三方库:
django、flask、requests、virtualenv、selenium、scrapy、xadmin、celery、re、hashlib、md5
常用的科学计算库:Numpy,Pandas、matplotlib
28、如何在Python中管理内存?
python中的内存管理由Python私有堆空间管理。所有Python对象和数据结构都位于私有堆中。程序员无权访问此私有堆。python解释器负责处理这个问题。
Python对象的堆空间分配由Python的内存管理器完成。核心API提供了一些程序员编写代码的工具。
Python还有一个内置的垃圾收集器,它可以回收所有未使用的内存,并使其可用于堆空间。
29、介绍一下 except 的作用和用法?
except: 捕获所有异常
except:<异常名>: 捕获指定异常
except:<异常名 1, 异常名 2>: 捕获异常 1 或者异常 2
except:<异常名>,<数据>: 捕获指定异常及其附加的数据
except:<异常名 1,异常名 2>:<数据>: 捕获异常名 1 或者异常名 2,及附加的数据
30、在 except 中 return 后还会不会执行 finally 中的代码?怎么抛出自定义异常?
会继续处理 finally 中的代码;
用 raise 方法可以抛出自定义异常。
31、read、readline 和 readlines 的区别?
read:读取整个文件。
readline:读取下一行,使用生成器方法。
readlines:读取整个文件到一个迭代器以供我们遍历。
另外,我也打包成 PDF 方便阅读。
32、range 和 xrange 的区别?
两者用法相同,不同的是 range 返回的结果是一个列表,而 xrange 的结果是一个生成器,前者是直接开辟一块内存空间来保存列表,后者是边循环边使用,只有使用时才会开辟内存空间,所以当列表
很长时,使用 xrange 性能要比 range 好。
33、请简述你对 input()函数的理解?
在 Python3 中,input()获取用户输入,不论用户输入的是什么,获取到的都是字符串类型的。
在 Python2 中有 raw_input()和 input(), raw_input()和 Python3 中的 input()作用是一样的,
input()输入的是什么数据类型的,获取到的就是什么数据类型的。
34、代码中要修改不可变数据会出现什么问题?抛出什么异常?
代码不会正常运行,抛出 TypeError 异常。
35、print 调用 Python 中底层的什么方法?
print 方法默认调用 sys.stdout.write 方法,即往控制台打印字符串。
36、Python 的 sys 模块常用方法
sys.argv 命令行参数 List,第一个元素是程序本身路径
sys.modules.keys() 返回所有已经导入的模块列表
sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback 当前处理的
异常详细信息
sys.exit(n) 退出程序,正常退出时 exit(0) sys.hexversion 获取 Python 解释程序的版本值,16 进制格式如:0x020403F0
sys.version 获取 Python 解释程序的版本信息
sys.maxint 最大的 Int 值
sys.maxunicode 最大的 Unicode 值
sys.modules 返回系统导入的模块字段,key 是模块名,value 是模块
sys.path 返回模块的搜索路径,初始化时使用 PYTHONPATH 环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout 标准输出
sys.stdin 标准输入
sys.stderr 错误输出
sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息
sys.exec_prefix 返回平台独立的 python 文件安装的位置
sys.byteorder 本地字节规则的指示器,big-endian 平台的值是’big’,little-endian 平台的值是
‘little’ sys.copyright 记录 python 版权相关的东西
sys.api_version 解释器的 C 的 API 版本
sys.version_info 元组则提供一个更简单的方法来使你的程序具备 Python 版本要求功能
37、unittest 是什么?
在 Python 中,unittest 是 Python 中的单元测试框架。它拥有支持共享搭建、自动测试、在测试
中暂停代码、将不同测试迭代成一组等的功能。
38、模块和包是什么?
在 Python 中,模块是搭建程序的一种方式。每一个 Python 代码文件都是一个模块,并可以引用
其他的模块,比如对象和属性。
一个包含许多 Python 代码的文件夹是一个包。一个包可以包含模块和子文件夹。
39、什么是正则的贪婪匹配?
>>>re.search('ab*c', 'abcaxc')
<_sre.SRE_Match object; span=(0, 3), match='abc'>
>>>re.search('ab\\D+c', 'abcaxc')
<_sre.SRE_Match object; span=(0, 6), match='abcaxc'>
贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。
非贪婪匹配:就是匹配到结果就好,就少的匹配字符。
另外,我也打包成 PDF 方便阅读。
40、常用字符串格式化哪几种?
% 格式化字符串操作符
print 'hello %s and %s' % ('df', 'another df')
字典形式的字符串格式化方法
print 'hello %(first)s and %(second)s' % 'first': 'df', 'second': 'another df'
字符串格式化(format)
(1) 使用位置参数
位置参数不受顺序约束,且可以为,参数索引从0开始,format里填写对应的参数值。
>>> msg = "my name is , and age is "
>>> msg.format("hqs",22)
'my name is hqs, and age is 22'
(2) 使用关键字参数
关键字参数值要对得上,可用字典当关键字参数传入值,字典前加**即可
>>> hash = 'name':'john' , 'age': 23
>>> msg = 'my name is name, and age is age'
>>> msg.format(**hash)
'my name is john,and age is 23'
(3) 填充与格式化
:[填充字符][对齐方式 <^>][宽度]
>>> '0:*<10'.format(10) # 左对齐
'10********'
41、面向对象深度优先和广度优先是什么?
在子类继承多个父类时,属性查找方式分深度优先和广度优先两种。
当类是经典类时,多继承情况下,在要查找属性不存在时,会按照深度优先方式查找下去。
当类是新式类时,多继承情况下,在要查找属性不存在时,会按照广度优先方式查找下去。
42、“一行代码实现 xx”类题目
(1) 一行代码实现 1 - 100 的和
可以利用 sum() 函数。

(2) 一行代码实现数值交换
不用二话,直接换。

(3) 一行代码求奇偶数
使用列表推导式。

(4) 一行代码展开列表
使用列表推导式,稍微复杂一点,注意顺序。

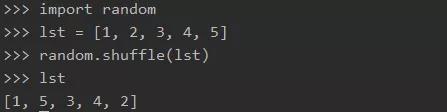
(5) 一行代码打乱列表
用到 random 的 shuffle。
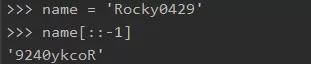
(6) 一行代码反转字符串
使用切片。
(7) 一行代码查看目录下所有文件
使用 os 的 listdir。

(8) 一行代码去除字符串间的空格
法 1 replace 函数。

法 2 join & split 函数。

(9) 一行代码实现字符串整数列表变成整数列表
使用 list & map & lambda。

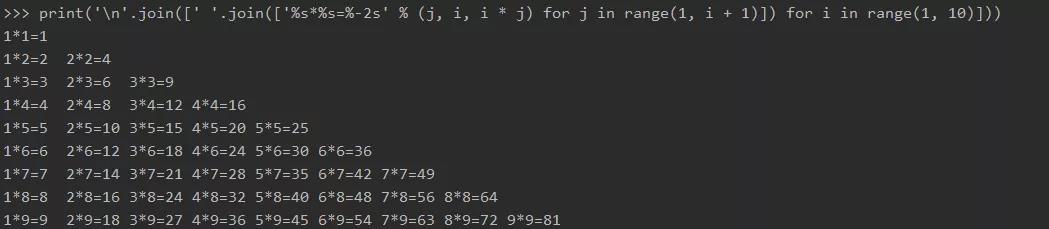
(10) 一行代码删除列表中重复的值
使用 list & set。
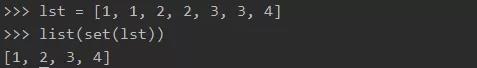
**(11) 一行代码实现 9 * 9 乘法表
稍稍复杂的列表推导式,耐心点就行,一点点的搞…
(12) 一行代码找出两个列表中相同的元素
使用 set 和 &。

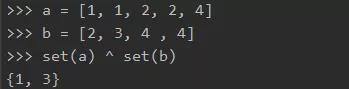
(13) 一行代码找出两个列表中不同的元素
使用 set 和 ^。
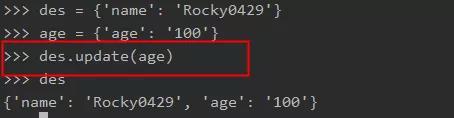
(14)一行代码合并两个字典
使用 Update 函数。
(15) 一行代码实现字典键从小到大排序
使用 sort 函数。

如果觉得有问题,欢迎评论,顺便一键三连!
以上是关于最强面试题整理第一弹:Python 基础面试题(附答案)的主要内容,如果未能解决你的问题,请参考以下文章