Flink集群搭建
Posted QYHuiiQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink集群搭建相关的知识,希望对你有一定的参考价值。
- 前置Hadoop2.7.5集群搭建:
https://blog.csdn.net/QYHuiiQ/article/details/123055389
- 集群角色分配
| Hostname | IP | Role |
| hadoop01 | 192.168.126.132 | JobManager |
| hadoop02 | 192.168.126.133 | TaskManager |
| hadoop03 | 192.168.126.134 | TaskManager |
- 下载flink
https://archive.apache.org/dist/flink/flink-1.13.0/

将压缩包上传服务器并解压:
[root@hadoop01 wyh]# tar -zxvf flink-1.13.0-bin-scala_2.12.tgz

- 配置JobManager节点
[root@hadoop01 conf]# pwd
/usr/local/wyh/flink-1.13.0/conf
[root@hadoop01 conf]# vi flink-conf.yaml
#将下面的配置修改为JobManager的主机名
jobmanager.rpc.address: hadoop01- 配置TaskManager节点
[root@hadoop01 conf]# pwd
/usr/local/wyh/flink-1.13.0/conf
[root@hadoop01 conf]# vi workers
[root@hadoop01 conf]# cat workers
hadoop02
hadoop03
- 将hadoop01上的flink包分发至hadoop02和haddop03机器上
[root@hadoop01 wyh]# scp -r flink-1.13.0/ hadoop02:$PWD
[root@hadoop01 wyh]# scp -r flink-1.13.0/ hadoop03:$PWD
- 启动flink集群
[root@hadoop01 bin]# pwd
/usr/local/wyh/flink-1.13.0/bin
[root@hadoop01 bin]# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop01.
Starting taskexecutor daemon on host hadoop02.
Starting taskexecutor daemon on host hadoop03.
- 启动后查看三台机器上的进程

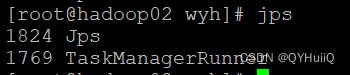
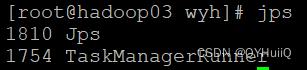
访问Web:

默认情况下每个TaskManager的任务槽是1,这里我们有两个TaskManager。
停掉flinnk集群。
[root@hadoop01 bin]# pwd
/usr/local/wyh/flink-1.13.0/bin
[root@hadoop01 bin]# ./stop-cluster.sh
然后我们尝试用Yarn模式启动集群,前提是要启动Hadoop。
- 启动Hadoop集群
[root@hadoop01 hadoop-2.7.5]# pwd
/usr/local/wyh/hadoop-2.7.5
[root@hadoop01 hadoop-2.7.5]# start-all.sh
- 以Yarn模式启动Flink集群
[root@hadoop01 bin]# ./yarn-session.sh -nm test-yarn
#此处nm参数后面跟的是自定义的命名空间启动成功:
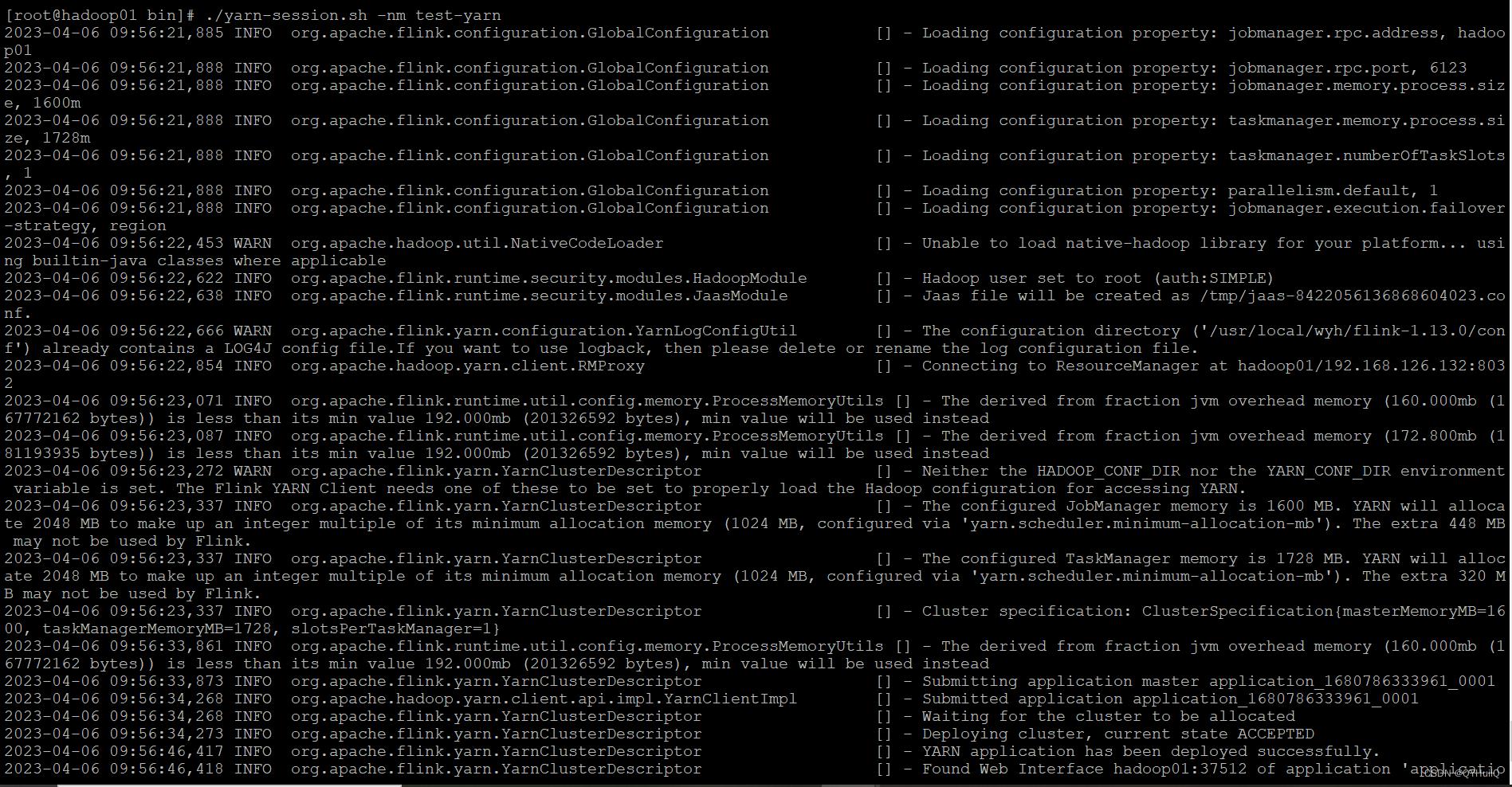
 访问UI:
访问UI:

Flink1.8 集群搭建完全指南(1):Hadoop伪分布式
参考技术A Flink是目前在国内非常流行的大数据的计算框架,其设计理念可以完美的实现数据的批流计算一体化。Flink的集群,如果要使用到JobManager的HA,以及Yarn的资源调度的话,整体的部署过程还是比较复杂的。本系列文章将完整介绍Hadoop,Kerberos,SASL,Yarn,以及Flink集群的搭建过程,一步步完成整个系统环境的部署。Hadoop的HDFS在Flink中用作JobManager的HA,Yarn可以用于Flink任务的资源调度,因此是必不可少的。下面我们先搭建好一个Hadoop的集群。
对于一些不熟悉Hadoop集群的搭建的同学,我们先来看下伪分布式集群的搭建,可以快速的熟悉简化的配置过程,以及Hadoop的各配置文件等。
以下是我用于部署该服务的机器:
在伪分布式集群中,所有的服务都在同一节点启动,但它们之间也同样通过ssh的方式访问,所以需要配置ssh免密码登录,配置的方式如下:
测试以下命令,成功跳转即可:
在集群搭建完成后,可以运行Hadoop的示例任务,检查集群是否能够正常工作,命令如下:
该程序会打印PI的值,则执行成功。在Yarn的Web页面,可以看到有一个成功的Application。
下一节我们会介绍Hadoop的分布式集群,Kerberos和SASL等的部署。
以上是关于Flink集群搭建的主要内容,如果未能解决你的问题,请参考以下文章