金融特征计算平台
Posted yueguanghaidao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了金融特征计算平台相关的知识,希望对你有一定的参考价值。
金融特征计算平台
前段时间一直在做内部的特征平台,这不还有部门发的PR稿-滴滴金服风控升级:上线特征计算平台 已沉淀5000+特征,也算是给自己的交代了,今天主要
介绍一下该计算平台,以及沉淀下来的东西。
背景
金融的核心是风控,风控的核心是数据与特征。如何让数仓人员加工出来的特征可视化,分级管理?在成千上万的特征里,模型人员如何能找到高价值、预测性强的特征?找到了特征,如何方便的提取特征?
以上就是我们当初遇到的痛点,特征计算平台主要也就是解决下面几个问题
- 特征分级管理
- 特征价值计算、分布计算
- 特征提取平台
功能
首先看下面向用户的特征侦查效果,达到了特征分级管理、特征可搜索、特征价值度、分箱明细

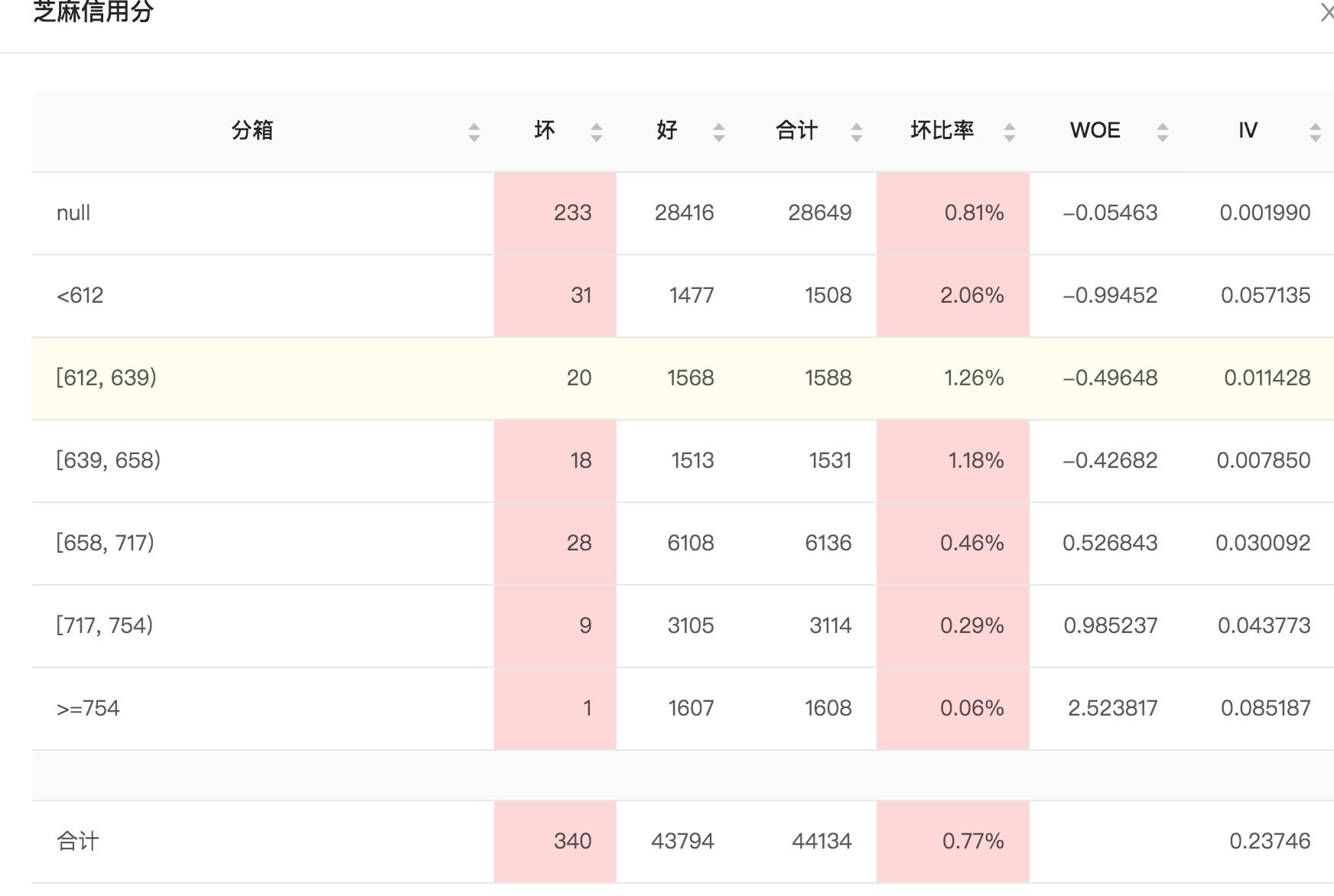
我们可以看下芝麻信用分的分箱结果(一次样本)
样本提取功能中,用户上传样本用户、选择需要的特征,创建提取任务,如下

样本提取关键是标签不能泄露,用户提供的样本会提供当时时间的列,需要从近一年的数据中查找,计算压力还是蛮大的,需要做优化,这个后面会提到。
细节
IV值计算
评分卡领域使用最多的衡量变量预测能力的指标一般都用IV值(Information Value) ,即信息价值(信息量)。
计算IV值,需要先对变量进行分箱,大家使用最多的还是最优分箱,这个资料也挺多,大家可以搜索一下。
我用Spark写了一个简洁版本(https://github.com/Skycrab/spark-ext,仅供参考
- 连续变量暴力计算IV最优解(单调、数量是否合适、区间是否显著)
- 离散变量合并(数量过少合并、不显著合并)
def continuous(spark: SparkSession, df: DataFrame): Unit =
val df2= spark.sql("select * from woe where last_7_days_online_num is null")
df2.show(2,false)
// 连续性变量
val woeBinning = new WoeBinning()
.setInputCol("last_7_days_online_num")
.setOutputCol("last_7_days_online_num_woe")
.setLabelCol("is_bad")
.setContinuous(true)
val woeModel = woeBinning.fit(df)
val result = woeModel.transform(df)
println(woeModel.labelWoeIv.label.toList)
println(woeModel.labelWoeIv.woeIvGroup)
result.show()
spring-boot-rest
后端使用的spring-boot rest框架,熟悉我的都清楚,我之前写了好几年的Python,但自从来了大数据领域,现在主力开发语言都是Java/Scala了,可以说我已经叛变了,_。语言只是工具,也建议大家不要把自己绑定在一个语言,一个平台上,跳出来看看,世界多姿多彩。
我把一些好的实践抽出来了,大家可以参考https://github.com/Skycrab/fairy
- swagger Api支持
- application/problem+json响应
- Mdc TraceId支持
- Boot Admin支持
- 未完待续…
样本提取
我们的样本提取是通过Spark实现的,用户提交任务后,会拼装成SQL,让Spark去执行。这边的难点就是数据量太大,用户提取近1000+个特征,底层可能涉及几十张表,每张表需要过滤近一年的数据,基本算是千亿级别了。
其实SQL倒是都很简单,如
select
t1.uid,
t1.is_bad, --is_bad
t2.last_6_month_lifeservice_no1_second_category,
t3.last_1_year_no1_first_category
from
(
select
date_add(sq_date,-if(pmod(datediff(sq_date,'1919-12-28'),7)=0,7,pmod(datediff(sq_date,'1919-12-28'),7))) as last_week_align, --上周日
uid,
sq_date, --sq_date
is_bad --is_bad
from test_data0315c
)t1
left outer join
(
select
concat_ws('-',year,month,day) as align_date,
uid, --inner uid
last_6_month_lifeservice_no1_second_category, --最近六个月生活服务下最常用二级位置类
....
from t1
where concat_ws('-',year,month,day) between '2018-04-05' and '2019-04-04'
and date_format(concat_ws('-', year, month, day), 'u')=7
)t2
on (t1.uid=t2.uid and t1.last_week_align=t2.align_date)
left outer join
(
select
concat_ws('-',year,month,day) as align_date,
uid, --inner uid
last_1_year_no1_first_category, --最近一年第一常用位置一级类型
...
from t2
where concat_ws('-',year,month,day) between '2018-04-05' and '2019-04-04'
and date_format(concat_ws('-', year, month, day), 'u')=7
)t3
on (t1.uid=t3.uid and t1.last_week_align=t3.align_date)
其实我们可以看到,所有的样本都来自于第一张样本表,只要把第一张表下推到下面所有的表,通过map join即可以优化,改写后的SQL如下
set spark.sql.autoBroadcastJoinThreshold=52428800
cache table cta
as
select
date_add(sq_date,-if(pmod(datediff(sq_date,'1919-12-28'),7)=0,7,pmod(datediff(sq_date,'1919-12-28'),7))) as last_week_align, --上周日
uid,
sq_date, --sq_date
is_bad --is_bad
from test_data0315c
select
t1.uid,
t1.is_bad, --is_bad
t2.last_6_month_lifeservice_no1_second_category,
t3.last_1_year_no1_first_category
from
(cta)t1
left outer join
(
select
concat_ws('-',year,month,day) as align_date,
uid, --inner uid
last_6_month_lifeservice_no1_second_category, --最近六个月生活服务下最常用二级位置类
....
from t1
where concat_ws('-',year,month,day) between '2018-04-05' and '2019-04-04' b
inner join cta a on(b.uid=a.uid and concat_ws('-',year,month,day)=a.last_week_align)
and date_format(concat_ws('-', year, month, day), 'u')=7
)t2
on (t1.uid=t2.uid and t1.last_week_align=t2.align_date)
left outer join
(
select
concat_ws('-',year,month,day) as align_date,
uid, --inner uid
last_1_year_no1_first_category, --最近一年第一常用位置一级类型
...
from t2
where concat_ws('-',year,month,day) between '2018-04-05' and '2019-04-04' b
inner join cta a on(b.uid=a.uid and concat_ws('-',year,month,day)=a.last_week_align)
and date_format(concat_ws('-', year, month, day), 'u')=7
)t3
on (t1.uid=t3.uid and t1.last_week_align=t3.align_date)
展望
最近很多的数据中台、AI中台,真正落地还比较困难,新事物的认可都是需要时间的。也希望我们能借助中台力量,让金融插上无限想象的翅膀。
以上是关于金融特征计算平台的主要内容,如果未能解决你的问题,请参考以下文章