技术解读:现代化工具链在大规模 C++ 项目中的运用
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术解读:现代化工具链在大规模 C++ 项目中的运用相关的知识,希望对你有一定的参考价值。
编者按:C++ 语言与编译器一直都在持续演进,出现了许多令人振奋的新特性,同时还有许多新特性在孵化阶。除此之外,还有许多小更改以提高运行效率与编程效率。本文整理自全球 C++ 及系统软件技术大会上的精彩分享,接下来由作者带我们了解 C++ 项目的实践工作等具体内容,全文整理如下:
介绍
C++ 是一门有着长久历史并依然持续活跃的语言。C++ 最新标准已经到了 C++23。Clang/LLVM、GCC 与 MSVC 等三大编译器都保持着非常频繁的更新。除此之外的各个相关生态也都保持着持续更新与跟进。但遗憾的是,目前看到积极更近 C++新标准与 C++新工具链的都主要以国外项目为主。国内虽然对 C++ 新标准也非常关注,但大多以爱好者个人为主,缺乏真实项目的跟进与实践
本文以现代化工具链作为线索,介绍我们实际工作中的大型 C++ 项目中现代化工具链的实践以及结果。
对于 C++ 项目,特别是大型的 C++项目而言,常常会有以下几个特点(或痛点):
- 项目高度自治 – 自主决定编译器版本、语言标准
- 高度业务导向 – 少关注、不关注编译器和语言标准
- 先发劣势 – 丧失应用新技术、新特性的能力
- 沉疴难起 – 编译器版本、语言标准、库依赖被锁死
许多 C++ 项目都是高度自治且业务导向的,这导致一个公司内部的 C++ 项目的编译器版本和语言标准五花八门,想统一非常困难。同时由于日常开发主要更关心业务,时间一长背上了技术债,再想用新标准与新工具链的成本就更高了。一来二去,编译器、语言标准与库依赖就被锁死了。
同时对于业务来说,切换编译器也会有很多问题与挑战:
- 修复更严格编译器检查的问题
- 修复不同编译器行为差异的问题
- 修复语言标准、编译器行为改变的问题 – 完善测试
- 二进制依赖、ABI兼容问题 – 全源码编译/服务化
- 性能压测、调优
这里的许多问题哪怕对于有许多年经验的 C++工程师而言可能都算是难题,因为这些问题其实本质上是比语言层更低一层的问题,属于工具链级别的问题。所以大家觉得棘手是很正常的,这个时候就需要专业的编译器团队了。
在我们的工作中,少数编译器造成的程序行为变化问题需要完善的测试集,极少数编译器切换造成的问题在产线上暴露出来 – 本质是业务/库代码的 bug,绝大多数问题在构建、运行、压测阶段暴露并得到修复。
这里我们简单介绍下我们在实际工作中遇到的案例:
业务1(规模5M)
- 业务本身10+仓库;三方依赖50+,其中大部分源代码依赖,部分二进制依赖。
- 二进制依赖、ABI兼容问题 – 0.5人月;编译器切换、CI、CD – 1.5人月;性能分析调优 – 1人月。
业务2(规模7M)
- 二方/三方依赖 30+,二进制依赖。
- 编译器切换改造 – 2 人月;性能压测调优 – 1 人月。
业务3(规模3M)
- 二方/三方依赖 100+,多为二进制依赖。
- 二进制依赖、ABI 兼容问题 – 预估 2 人年。
在切换工具链之后,用户们能得到什么呢?
- 更短的编译时间
- 更好的运行时性能
- 更好的编译、静态、运行时检查
- 更多优化技术 – ThinLTO、AutoFDO、Bolt 等
- 更新的语言特性支持 – C++20 协程、C++20 Module 等
- 持续性更新升级 – 良性循环
其中更短的编译时间本身就是 clang 的一个特性,从 gcc 切换到 clang 就会得到很不错的编译加速。同时运行时性能也一直是编译器的目标。而各种各样的静态与运行时检查也是编译器/工具链开发的一个长期主线。另外更新的工具链也会带来更多的优化技术与语言特性支持,这里我们后面会重点介绍。最后是我们可以得到一个长期持续性更新升级的良性循环,这一点也是非常重要和有价值的。
优化技术简介
ThinLTO
传统的编译流程如下图所示

编译器在编译 *.c 文件时,只能通过 *.c 及其包含的文件中的信息做优化。
LTO (Linking Time Optimization)技术是在链接时使用程序中所有信息进行优化的技术。但 LTO 会将所有 *.o 文件加载到内存中,消耗非常多的资源。同时 LTO 串行化部分比较多。编译时间很长。落地对环境、技术要求比较高,目前只在 suse 等传统 Linux 厂商中得到应用。
为了解决这个问题,LLVM 实现了 ThinLTO 以降低 LTO 的开销。
GCC WHOPR 的整体架构如图所示。思路是在编译阶段为每个编译单元生成 Summary 信息,之后再根据 Summary 信息对每个编译单元进行优化。

ThinLTO 技术的整体架构如上图所示。都是在编译阶段为每个 *.o 文件生成 Summary 信息,之后在 thin link 阶段根据 Summary 信息对每个 *.o 文件进行优化。

(图/LLVM ThinLTO 与 GCCLTO 在 SPEC cpu 2006 上的性能比较)
使用 GCC LTO 的原因是 GCC 的 LTO 实现相对比较成熟。
从图上可以看出,在性能收益上 ThinLTO 与 LTO 的差距并不大。而 ThinLTO 与 LTO 相比最大的优势是占用的资源极小:

如图为使用 LLVM ThinLTO、LLVM LTO 以及 GCC LTO 链接 Chromium 时的内存消耗走势图。

所以使用 ThinLTO 可以使我们的业务在日常开发中以很小的代价拿到很大的提升。同时开启 ThinLTO 的难度很低,基本只要可以启用 clang 就可以使能 ThinLTO。在我们的实践中,一般开启 ThinLTO 可以拿到 10% 的性能提升。
AutoFDO
AutoFDO 是一个简化 FDO 的使用过程的系统。AutoFDO 会从生产环境收集反馈信息(perf 数据),然后将其应用在编译时。反馈信息是在生产环境的机器上使用 perf 工具对相应硬件事件进行采样得到的。总体来说,一次完整的 AutoFDO 过程如下图可分为 4 步:

- 将编译好的 binary 部署到生产环境或者测试环境, 在正常工作的情况下使用 perf 对当前进程做周期性的采集。
- 将 perf 数据转化成 llvm 可以识别的格式,并将其保存到数据库中。
- 当用户再次编译的时候,数据库会将亲近性最强的profile文件返回给编译器并参与到当前构建中。
- 将编译好的二进制进行归档和发布。
对于业务而言,AutoFDO 的接入有同步和异步两种接入方式:
同步接入:
- 首先编译一个 AutoFDO 不参与的二进制版本。
- 在 benchmark 环境下运行当前二进制并使用perf采集数据。
- 使用 AutoFDO 再次构建一个二进制版本,此二进制为最终发布版本。
异步接入:
- 在客户线上机器进行周期性采集,将采集数据进行合并和保存。
- 构建新版本的时候将对应的数据文件下载, 并参与当前版本的编译。
- 在实际中开启 AutoFDO 可以拿到 2%~5% 的性能提升。
Bolt
Bolt 基于 LLVM 框架的二进制 POST-LINK 优化技术,可以在 PGO/基础进一步优化。
Bolt 应用于其数据中心负载处理,即使数据中心已进行了 PGO(AutoFDO)和 LTO 优化后,BOLT 仍然能够提升其性能。
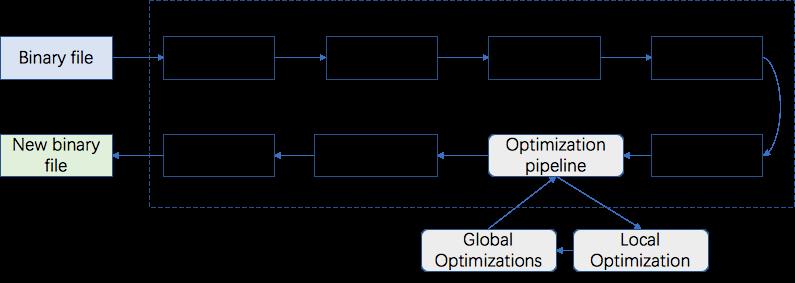
1. Function Discovery:通过 ELF 符号表查找所有函数名字与地址。
2. Read debug info:如果二进制编译时带有 Debug 信息,读取 Debug 信息。
3. Read Profile data:读取 Profile 数据,用于驱动 CFG 上优化。
4. Disassembly:基于LLVM将机器码翻译成保存在内存里的汇编指令。
5. CFG Construction:依据汇编指令构建控制流图(Control-Flow graph)。
6. Optimization pipeline:经过上述操作,汇编指令内部表示形式均含有Profile信息,就可以进行一系列的操作优化:
-
- BasicBlock Reordering
- Function Reordering
- ...
7. Emit and Link Functions:发射优化后代码,重定向函数地址;
8. Rewrite binary file:重写二进制文件。
Bolt 的接入类似 AutoFDO,也需要先收集到 Perf 数据同时使用该数据重新编译。在我们的实践中性能可以提升 8%。
语言特性
这里我们简单介绍下两个 C++ 语言的新特性 Coroutines 与 Modules 来展示更新到现代化工具链后可以使用的 C++ 新特性。
Coroutines
首先可以先简单介绍一下 Coroutines:
- 协程是一个可挂起的函数。
- 支持以同步方式写异步代码。
- C++20 协程是无栈协程。在语义层面不保存调用上下文信息。
- 对比有栈协程
- 两个数量级的切换效率提升。
- 更好的执行 & 切换效率。
- 对比 Callback
- 更简洁的编程模式,避免 Callback hell。
接下来我们以一个简单的例子为例,介绍协程是如何支持以同步方式写异步代码。首先我们先看看同步代码的案例:
这是一个统计多个文件体积的同步代码,应该是非常简单。
接下来我们再看下对应的异步写法:
肉眼可见地,异步写法麻烦了非常多。同时这里还使用到了 std::shared_ptr。但 std::shared_ptr 会有额外的开销。如果用户不想要这个开销的话需要自己实现一个非线程安全的 shared_ptr,还是比较麻烦的。
最后再让我们来看下协程版的代码:
可以看到这个版本的代码与同步代码是非常像的,但这份代码本质上其实是异步代码的。所以我们说:
协程可以让我们用同步方式写异步代码;兼具开发效率和运行效率。
接下来来简单介绍下 C++20 协程的实现:
- C++20 协程是无栈协程,需要编译器介入才能实现。
- 判定协程并搜索相关组件。(Frontend Semantic Analysis)
- 生成代码。(Frontend Code Generation)
- 生成、优化、维护协程桢。(Middle-end)
- C++20 协程只设计了基本语法,并没有加入协程库。
- C++20 协程的目标用户是协程库作者。
- 其他用户应通过协程库使用协程。
同时我们在 GCC 和 Clang 中做了以下工作:
- GCC
- 与社区合作进行协程的支持。
- GCC-10 是第一个支持 C++ 协程特性的 GCC 编译器。
- 仅支持,无优化。
- Clang/LLVM
- 与 Clang/LLVM 社区合作完善 C++ 协程。
- 改善&优化:对称变换、协程逃逸分析和CoroElide优化,协程帧优化(Frame reduction),完善协程调试能力、尾调用优化、Coro Return Value Optimization等。
- 在 Clang/LLVM14 中,coroutine 移出了 experimental namespace。
- Maintaining
最后我们还实现并开源了一个经过双 11 验证的协程库 async_simple:

async_simple
-
- 设计借鉴了 folly 库协程模块。
- 轻量级。
- 包含有栈协程、无栈协程以及 Future/Promise 等异步组件。
- 从真实需求出发。
- 与调度器解藕,用户可以选择合适自己的调度器。
- 经受了工业级 Workload 的考验。
- 开源于:https://github.com/alibaba/async_simple
最后我们来看下我们应用协程后的效果:
- 业务1(1M Loc、35w core)
- 原先为同步逻辑
- 协程化后 Latency 下降 30%
- 超时查询数量大幅下降甚至清零
- 业务2(7M Loc)
- 原先为异步逻辑
- 协程化后 Latency 下降 8%
- 业务3(100K Loc、2.7w core)
- 原先为同步逻辑
- 协程化后 qps 提升 10 倍以上性能
Modules
Modules 是 C++20 的四大重要特性(Coroutines、Ranges、Concepts 以及 Modules)之一。Modules 也是这四大特性中对现在 C++ 生态影响最大的特性。Modules 是 C++20 为复杂、难用、易错、缓慢以及古老的 C++ 项目组织形式提供的现代化解决方案。Modules 可以提供:
- 降低复杂度与出错的机会
- 更好的封装性
- 更快的编译速度
对于降低复杂度而言,我们来看下面这个例子:
在传统的头文件结构中 a.h与 b.h 的 include 顺序可能会导致不同的行为,这一点是非常烦人且易错的。而这个问题在 Modules 中就自然得到解决了。例如下面两段代码是完全等价的:
与
对于封装性,我们以 asio 库中的 asio::string_view 为例进行说明。以下是 asio::string_view 的实现:
该文件的位置是 /asio/detail/string_view.hpp,位于 detail 目录下。同时我们从 asio 的官方文档(链接地址见文末)中也找不到 string_view 的痕迹。所以我们基本可以判断 asio::string_view这个组件在 asio 中是不对外提供的,只在库内部使用,作为在 C++ 标准不够高时的备选。然而使用者们确可能将 asio::string_view作为一个组件单独使用(Examples),这违背了库作者的设计意图。从长远来看,类似的问题可能会导致库用户代码不稳定。因为库作者很可能不会对没有暴露的功能做兼容性保证。
这个问题的本质是头文件的机制根本无法保证封装。用户想拿什么就拿什么。

而 Modules 的机制可以保障用户无法使用我们不让他们使用的东西,极强地增强了封装性:

最后是编译速度的提升,头文件导致编译速度慢的根本原因是每个头文件在每个包含该头文件的源文件中都会被编译一遍,会导致非常多冗余的编译。如果项目中有 n 个头文件和 m 个源文件,且每个头文件都会被每个源文件包含,那么这个项目的编译时间复杂度为 O(n*m)。如果同样的项目由 n 个 Modules 和 m 个源文件,那么这个项目的编译时间复杂度将为 O(n+m)。这会是一个复杂度级别的提升。
我们在 https://github.com/alibaba/async_simple/tree/CXX20Modules 中将 async_simple 库进行了完全 Modules 化,同时测了编译速度的提升:

可以看到编译时间最多可以下降 74%,这意味着 4 倍的编译速度提升。需要主要 async_simple 是一个以模版为主的 header only 库,对于其他库而言编译加速应该更大才对。关于 Modules 对编译加速的分析我们在今年的 CppCon22 中也有介绍(链接地址见文末)。
最后关于 Modules 的进展为:
- 编译器初步开发完成
- 支持 std modules
- 优先内部应用
- 已在 Clang15 中发布
- 探索编译器与构建系统交互 (ing)
总结
最后我们再总结一下,使用现代化工具链带来的好处:
- 更短的编译时间
- 更好的运行时性能
- 更好的编译、静态、运行时检查
- 更多优化技术 – ThinLTO、AutoFDO、Bolt 等
- 更新的语言特性支持 – C++20 协程、C++20 Module 等
- 持续性更新升级 – 良性循环
希望更多的项目可以使用更现代化的工具链。
相关链接:
asio官方文档链接地址:
https://think-async.com/Asio/asio-1.22.1/doc/asio/index.html
CppCon22 链接地址:https://cppcon.digital-medium.co.uk/session/2022/how-much-compilation-speedup-we-will-get-from-c-modules/。
本文为阿里云原创内容,未经允许不得转载。
以上是关于技术解读:现代化工具链在大规模 C++ 项目中的运用的主要内容,如果未能解决你的问题,请参考以下文章