socket是并发安全的吗?
Posted 肥肥技术宅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了socket是并发安全的吗?相关的知识,希望对你有一定的参考价值。
为了更好的聊今天的话题,我们先假设一个场景。
我相信我读者大部分都是做互联网应用开发的,可能对游戏的架构不太了解。
我们想象中的游戏架构是下面这样的。

也就是用户客户端直接连接游戏核心逻辑服务器,下面简称GameServer。GameServer主要负责实现各种玩法逻辑。
这当然是能跑起来,实现也很简单。
但这样会有个问题,因为游戏这块蛋糕很大,所以总会遇到很多挺刑的事情。
如果让用户直连GameServer,那相当于把GameServer的ip暴露给了所有人。
不赚钱还好,一旦游戏赚钱,就会遇到各种攻击。
你猜《羊了个羊》最火的时候为啥老是崩溃?
假设一个游戏服务器能承载4k玩家,一旦服务器遭受直接攻击,那4k玩家都会被影响。
这攻击的是服务器吗?这明明攻击的是老板的钱包。
<br>
所以很多时候不会让用户直连GameServer。
而是在前面加入一层网关层,下面简称gateway。类似这样。
GameServer就躲在了gateway背后,用户只能得到gateway的IP。
然后将大概每100个用户放在一个gateway里,这样如果真被攻击,就算gateway崩了,受影响的也就那100个玩家。
由于大部分游戏都使用TCP做开发,所以下面提到的连接,如果没有特别说明,那都是指TCP连接。
那么问题来了。
假设有100个用户连gateway,那gateway跟GameServer之间也会是 100个连接吗?
当然不会,gateway跟GameServer之间的连接数会远小于100。
因为这100个用户不会一直需要收发消息,总有空闲的时候,完全可以让多个用户复用同一条连接,将数据打包一起发送给GameServer,这样单个连接的利用率也高了,GameServer 也不再需要同时维持太多连接,可以节省了不少资源,这样就可以多服务几个大怨种金主。
我们知道,要对网络连接写数据,就要执行 send(socket_fd, data)。
于是问题就来了。
已知多个用户共用同一条连接。
现在多个用户要发数据,也就是多个用户线程需要写同一个socket_fd。
那么,socket是并发安全的吗?能让这多个线程同时并发写吗?
<br>
写TCP Socket是线程安全的吗?
对于TCP,我们一般使用下面的方式创建socket。
sockfd=socket(AF_INET,SOCK_STREAM, 0))
复制代码返回的sockfd是socket的句柄id,用于在整个操作系统中唯一标识你的socket是哪个,可以理解为socket的身份证id。
创建socket时,操作系统内核会顺带为socket创建一个发送缓冲区和一个接收缓冲区。分别用于在发送和接收数据的时候给暂存一下数据。
写socket的方式有很多,既可以是send,也可以是write。
但不管哪个,最后在内核里都会走到 tcp_sendmsg() 函数下。
// net/ipv4/tcp.c
int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t size)
// 加锁
lock_sock(sk);
// ... 拷贝到发送缓冲区的相关操作
// 解锁
release_sock(sk);
复制代码在tcp_sendmsg的目的就是将要发送的数据放入到TCP的发送缓冲区中,此时并没有所谓的发送数据出去,函数就返回了,内核后续再根据实际情况异步发送。
从tcp_sendmsg的代码中可以看到,在对socket的缓冲区执行写操作的时候,linux内核已经自动帮我们加好了锁,也就是说,是线程安全的。
所以可以多线程不加锁并发写入数据吗?
不能。
问题的关键在于锁的粒度。
但我们知道TCP有三大特点,面向连接,可靠的,基于字节流的协议。
问题就出在这个"基于字节流",它是个源源不断的二进制数据流,无边界。来多少就发多少,但是能发多少,得看你的发送缓冲区还剩多少空间。
举个例子,假设A线程想发123数据包,B线程想发456数据包。
A和B线程同时执行send(),A先抢到锁,此时发送缓冲区就剩1个数据包的位置,那发了"1",然后发送缓冲区满了,A线程退出(非阻塞),当发送缓冲区腾出位置后,此时AB再次同时争抢,这次被B先抢到了,B发了"4"之后缓冲区又满了,不得不退出。
重复这样多次争抢之后,原本的数据内容都被打乱了,变成了142356。因为数据123是个整体,456又是个整体,像现在这样数据被打乱的话,接收方就算收到了数据也没办法正常解析。
也就是说锁的粒度其实是每次"写操作",但每次写操作并不保证能把消息写完整。
那么问题就来了,那是不是我在写整个完整消息之前加个锁,整个消息都写完之后再解锁,这样就好了?
类似下面这样。
// 伪代码
int safe_send(msg string)
target_len = length(msg)
have_send_len = 0
// 加锁
lock();
// 不断循环直到发完整个完整消息
do
send_len := send(sockfd,msg)
have_send_len = have_send_len + send_len
while(have_send_len < target_len)
// 解锁
unlock();
复制代码这也不行,我们知道加锁这个事情是影响性能的,锁的粒度越小,性能就越好。反之性能就越差。
当我们抢到了锁,使用 send(sockfd,msg) 发送完整数据的时候,如果此时发送缓冲区正好一写就满了,那这个线程就得一直占着这个锁直到整个消息写完。其他线程都在旁边等它解锁,啥事也干不了,焦急难耐想着抢锁。
但凡某个消息体稍微大点,这样的问题就会变得更严重。整个服务的性能也会被这波神仙操作给拖垮。
归根结底还是因为锁的粒度太大了。
有没有更好的方式呢?
其实多个线程抢锁,最后抢到锁的线程才能进行写操作,从本质上来看,就是将所有用户发给GameServer逻辑服务器的消息给串行化了,
那既然是串行化,我完全可以在在业务代码里为每个socket_fd配一个队列来做,将数据在用户态加锁后塞到这个队列里,再单独开一个线程,这个线程的工作就是发送消息给socket_fd。
于是上面的场景就变成了下面这样。
于是在gateway层,多个用户线程同时写消息时,会去争抢某个socket_fd对应的队列,抢到锁之后就写数据到队列。而真正执行 send(sockfd,msg) 的线程其实只有一个。它会从这个队列中取数据,然后不加锁的批量发送数据到 GameServer。
由于加锁后要做的事情很简单,也就塞个队列而已,因此非常快。并且由于执行发送数据的只有单个线程,因此也不会有消息体乱序的问题。
读TCP Socket是线程安全的吗?
在前面有了写socket是线程安全的结论,我们稍微翻一下源码就能发现,读socket其实也是加锁了的,所以并发多线程读socket这件事是线程安全的。
// net/ipv4/tcp.c
int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t len, int nonblock, int flags, int *addr_len)
// 加锁
lock_sock(sk);
// ... 将数据从接收缓冲区拷贝到用户缓冲区
// 释放锁
release_sock(sk);
复制代码但就算是线程安全,也不代表你可以用多个线程并发去读。
因为这个锁,只保证你在读socket 接收缓冲区时,只有一个线程在读,但并不能保证你每次的时候,都能正好读到完整消息体后才返回。
所以虽然并发读不报错,但每个线程拿到的消息肯定都不全,因为锁的粒度并不保证能读完完整消息。
TCP是基于数据流的协议,数据流会源源不断从网卡那送到接收缓冲区。
如果此时接收缓冲区里有两条完整消息,比如 "我是小白"和"点赞在看走一波"。
有两个线程A和B同时并发去读的话,A线程就可能读到“我是 点赞走一波", B线程就可能读到”小白 在看"
两条消息都变得不完整了。
解决方案还是跟读的时候一样,读socket的只能有一个线程,读到了消息之后塞到加锁队列中,再将消息分开给到GameServer的多线程用户逻辑模块中去做处理。
读写UDP Socket是线程安全的吗?
聊完TCP,我们很自然就能想到另外一个传输层协议UDP,那么它是线程安全的吗?
我们平时写代码的时候如果要使用udp发送消息,一般会像下面这样操作。
ssize_t sendto(int sockfd, const void *buf, size_t nbytes, int flags, const struct sockaddr *to, socklen_t addrlen);
复制代码而执行到底层,会到linux内核的udp_sendmsg函数中。
int udp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t len)
if (用到了MSG_MORE的功能)
lock_sock(sk);
// 加入到发送缓冲区中
release_sock(sk);
else
// 不加锁,直接发送消息
复制代码这里我用伪代码改了下,大概的含义就是用到MSG_MORE就加锁,否则不加锁将传入的msg作为一整个数据包直接发送。
首先需要搞清楚,MSG_MORE 是啥。它可以通过上面提到的sendto函数最右边的flags字段进行设置。大概的意思是告诉内核,待会还有其他更多消息要一起发,先别着急发出去。此时内核就会把这份数据先用发送缓冲区缓存起来,待会应用层说ok了,再一起发。
但是,我们一般也用不到 MSG_MORE。
所以我们直接关注另外一个分支,也就是不加锁直接发消息。
那是不是说明走了不加锁的分支时,udp发消息并不是线程安全的?
其实。还是线程安全的,不用lock_sock(sk)加锁,单纯是因为没必要。
开启MSG_MORE时多个线程会同时写到同一个socket_fd对应的发送缓冲区中,然后再统一一起发送到IP层,因此需要有个锁防止出现多个线程将对方写的数据给覆盖掉的问题。而不开启MSG_MORE时,数据则会直接发送给IP层,就没有了上面的烦恼。
再看下udp的接收函数udp_recvmsg,会发现情况也类似,这里就不再赘述。
能否多线程同时并发读或写同一个UDP socket?
在TCP中,线程安全不代表你可以并发地读写同一个socket_fd,因为哪怕内核态中加了lock_sock(sk),这个锁的粒度并不覆盖整个完整消息的多次分批发送,它只保证单次发送的线程安全,所以建议只用一个线程去读写一个socket_fd。
那么问题又来了,那UDP呢?会有一样的问题吗?
我们跟TCP对比下,大家就知道了。
TCP不能用多线程同时读和同时写,是因为它是基于数据流的协议。
那UDP呢?它是基于数据报的协议。
基于数据流和基于数据报有什么区别呢?
基于数据流,意味着发给内核底层的数据就跟水进入水管一样,内核根本不知道什么时候是个头,没有明确的边界。
而基于数据报,可以类比为一件件快递进入传送管道一样,内核很清楚拿到的是几件快递,快递和快递之间边界分明。
那从我们使用的方式来看,应用层通过TCP去发数据,TCP就先把它放到缓冲区中,然后就返回。至于什么时候发数据,发多少数据,发的数据是刚刚应用层传进去的一半还是全部都是不确定的,全看内核的心情。在接收端收的时候也一样。
但UDP就不同,UDP 对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。
无论应用层交给 UDP 多长的报文,UDP 都照样发送,即一次发送一个报文。至于数据包太长,需要分片,那也是IP层的事情,跟UDP没啥关系,大不了效率低一些。而接收方在接收数据报的时候,一次取一个完整的包,不存在TCP常见的半包和粘包问题。
正因为基于数据报和基于字节流的差异,TCP 发送端发 10 次字节流数据,接收端可以分 100 次去取数据,每次取数据的长度可以根据处理能力作调整;但 UDP 发送端发了 10 次数据报,那接收端就要在 10 次收完,且发了多少次,就取多少次,确保每次都是一个完整的数据报。
所以从这个角度来说,UDP写数据报的行为是"原子"的,不存在发一半包或收一半包的问题,要么整个包成功,要么整个包失败。因此多个线程同时读写,也就不会有TCP的问题。
所以,可以多个线程同时读写同一个udp socket。
但就算可以,我依然不建议大家这么做。
为什么不建议使用多线程同时读写同一个UDP socket
udp本身是不可靠的协议,多线程高并发执行发送时,会对系统造成较大压力,这时候丢包是常见的事情。虽然这时候应用层能实现重传逻辑,但重传这件事毕竟是越少越好。因此通常还会希望能有个应用层流量控制的功能,如果是单线程读写的话,就可以在同一个地方对流量实现调控。类似的,实现其他插件功能也会更加方便,比如给某些vip等级的老板更快速的游戏体验啥的(我瞎说的)。
所以正确的做法,还是跟TCP一样,不管外面有多少个线程,还是并发加锁写到一个队列里,然后起一个单独的线程去做发送操作。
总结
- 多线程并发读/写同一个TCP socket是线程安全的,因为TCP socket的读/写操作都上锁了。虽然线程安全,但依然不建议你这么做,因为TCP本身是基于数据流的协议,一份完整的消息数据可能会分开多次去写/读,内核的锁只保证单次读/写socket是线程安全,锁的粒度并不覆盖整个完整消息。因此建议用一个线程去读/写TCP socket。
- 多线程并发读/写同一个UDP socket也是线程安全的,因为UDP socket的读/写操作也都上锁了。UDP写数据报的行为是"原子"的,不存在发一半包或收一半包的问题,要么整个包成功,要么整个包失败。因此多个线程同时读写,也就不会有TCP的问题。虽然如此,但还是建议用一个线程去读/写UDP socket。
最后
上面文章里提到,建议用单线程的方式去读/写socket,但每个socket都配一个线程这件事情,显然有些奢侈,比如线程切换的代价也不小,那这种情况有什么好的解决办法吗?
Golang append是并发安全的吗
首发于微信公众号:【码农在新加坡】,欢迎关注。
个人博客网站:Golang append是并发安全的吗
背景
最近开发的时候写了下面这段类似的代码。
func TestAppend() (result []int)
var wg sync.WaitGroup
for i := 0; i < 100; i++
v := i
wg.Add(1)
go func()
// other logic
result = append(result, v)
wg.Done()
()
wg.Wait()
//fmt.Printf("%v\\n", len(result))
return result
就像这样,然后顺利通过测试到达生产环境。然后就出问题了。
预期情况下,len(result) = 100, 但是大多数情况下,这个数据会<=100。因为append这个函数不是并发安全的。也就是不能在多个goroutine里面对同一个slice使用append进行追加。
那么问题出在哪呢?
我们都知道slice是对数组一个连续片段的引用,当slice长度增加的时候,可能底层的数组会被换掉。在换底层数组之前,切片同时被多个goroutine拿到,并执行append操作。那么很多goroutine的append结果会被覆盖,导致n个gouroutine append后,长度小于n。
你以为这是最坏的影响吗,并不是的。数据出bug了是小事,最坏的影响是直接服务直接panic。
append咋还导致服务panic呢?且往下看。
原因分析
要分析这个原因,我们需要了解slice的底层结构。
type slice struct
array unsafe.Pointer
len int
cap int

可以看到,array是一个指向具体数组的指针,len是当前已经使用的长度,使用append的时候会再下一个位置填充数据并且把len加1。不加锁的情况下,由于操作并非原子的,可能两个goroutine同时往同一个位置写数据,就会导致数据覆盖。最终的长度小于实际期待的长度。
问题解决
有两种方案解决这个问题。
方案1
可以给append操作加锁,这样就会保证操作操作的原子性。不会被另一个goroutine打断。
func TestAppendWithLock() (result []int)
var wg sync.WaitGroup
var lock sync.Mutex
for i := 0; i < 100; i++
v := i
wg.Add(1)
go func()
defer wg.Done()
lock.Lock()
result = append(result, v)
lock.Unlock()
()
wg.Wait()
//fmt.Printf("%v\\n", len(result))
return result
方案2
如果slice的长度固定的情况下。可以直接使用make初始化固定长度,并使用下标赋值。
func TestSliceAppend() (result []int)
var wg sync.WaitGroup
result = make([]int, 100)
for i := 0; i < 100; i++
wg.Add(1)
go func(index int)
defer wg.Done()
result[index] = index
(i)
wg.Wait()
//fmt.Printf("%v\\n", len(result))
return result
panic原因
这个panic是概率性的,有非常小的概率会发生,但是在高并发场景下,是必定会发生的。
我们写个循环不停的执行并发append的函数:
func TestAppend() (result []int)
var wg sync.WaitGroup
for i := 0; i < 100; i++
v := i
wg.Add(1)
go func()
// other logic
result = append(result, v)
wg.Done()
()
wg.Wait()
//fmt.Printf("%v\\n", len(result))
return result
func main()
for a := 0; a < 100000; a++
res := TestAppend()
println("len(res):", len(res))
使用循环不停的执行并发append操作。过一段时间你就会发现:
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x108933f]
goroutine 9278997 [running]:
main.TestAppend.func1(0xc00020e050, 0xc0005da040, 0x3)
/Users/left_pocket/concurrency_append/main.go:20 +0x6f
created by main.TestAppend
/Users/left_pocket/concurrency_append/main.go:18 +0xa6
Process finished with exit code 2
的报错。
正是
result = append(result, v)
这一行。
这个报错曾经导致生产环境的service偶尔crash,这个概率非常低。
我们使用*-race*的参数执行函数
go run -race main.go
可以看到DATA RACE的报错。
==================
WARNING: DATA RACE
Read at 0x00c000100000 by goroutine 8:
runtime.growslice()
/Users/left_pocket/go1.14/src/runtime/slice.go:76 +0x0
main.TestAppend.func1()
/Users/left_pocket/src/github.com/left-pocket/go-practice/concurrency_append/main.go:20 +0x179
找到go语言库的代码。
func growslice(et *_type, old slice, cap int) slice //line 76
发现了RACE CONDITION。
使用goland的debug模式继续分析。
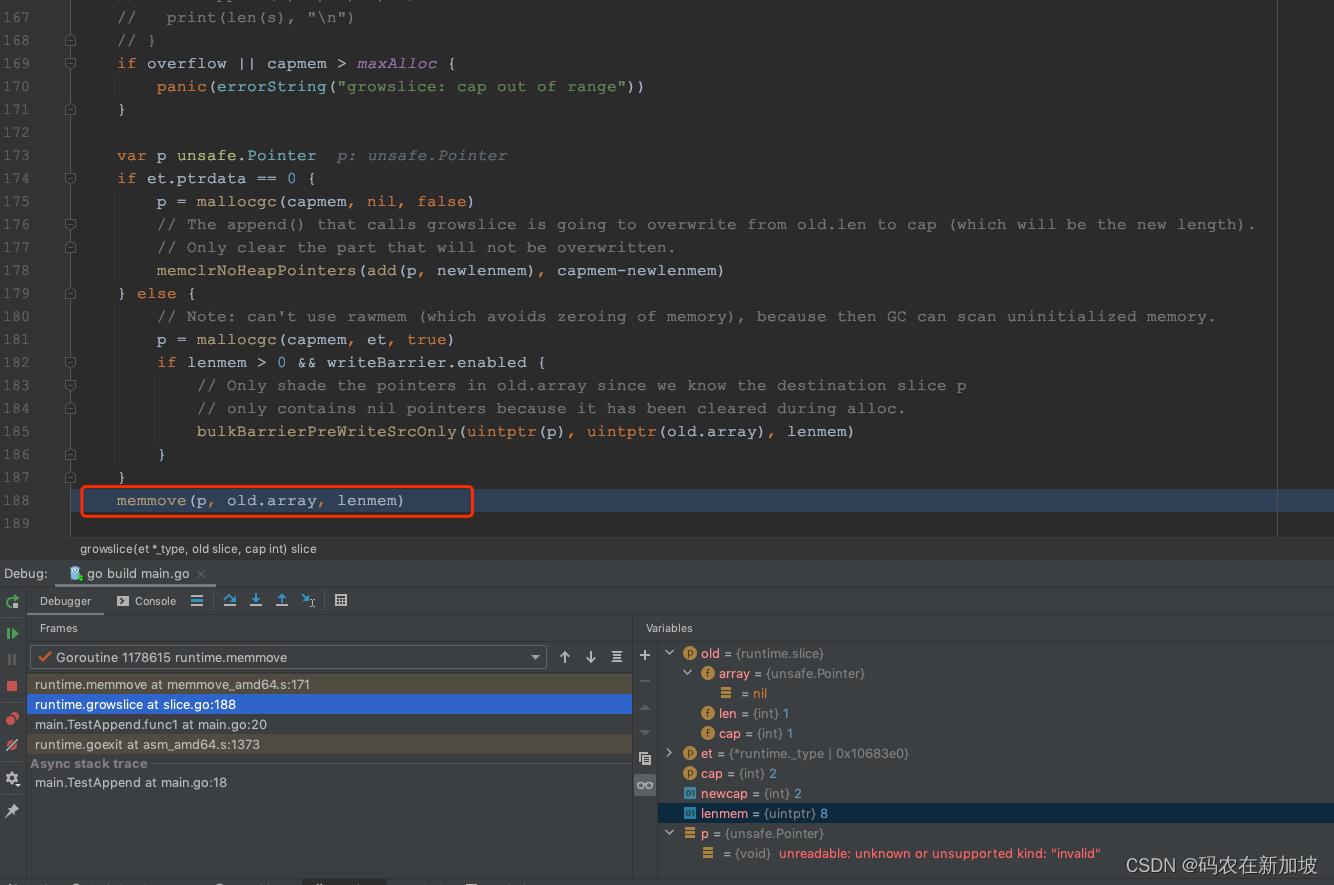
发现是在growslice函数里面调用memmove的时候发生了panic。可以确认是在slice扩容的过程中panic。
也就是恰好在append扩容的时候,两个goroutine同时进行memmove。
可以在TestAppend里面加一行代码,预先分配容量,来间接验证是扩容会产生panic。
func TestAppend() (result []int)
var wg sync.WaitGroup
result = make([]int, 0, 100) //set capacity first, will not add capacity anymore
for i := 0; i < 100; i++
v := i
wg.Add(1)
go func()
defer wg.Done()
result = append(result, v)
()
wg.Wait()
return result
如果调用前初始化了capacity,就不会导致panic。
总结
Golang append并不是并发安全的,我相信使用过Golang的同学大部分都是知道的,但是他有概率会导致服务crash,这才是更大的风险。
<全文完>
欢迎关注我的微信公众号:【码农在新加坡】,有更多好的技术分享。
个人博客网站:Golang append是并发安全的吗
以上是关于socket是并发安全的吗?的主要内容,如果未能解决你的问题,请参考以下文章