大数据之kafka消费者
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之kafka消费者相关的知识,希望对你有一定的参考价值。
🍒今天是端午节,先祝大家端午节快乐!上一期我们学习了kafka的broker部分主要介绍了kafka中的副本、kafka文件的存储的原理,以及kafka的高效读写的保证,今天我们来介绍kafka中的消费者原理,对往期内容感兴趣的小伙伴可以参考👇:
- 链接: kafka入门基础.
- 链接: 大数据之kafka生产者原理.
- 链接: 大数据之kafka生产者数据可靠性保障
- 链接: 大数据之kafka Broker的工作流程
🍑消费者作为kafka中最重要的部分,如何从主题中消费数据是我们重点关注的地方,话不多说,让我们开始今日份的学习吧!
本文目录
1. 数据消费方式
通常来说,消费者消费数据的方式有2种,一种是拉取数据的方式,另一种是broker主动推数据。
1.1 pull模式
kafka中,消费者采用的消费数据的方式是拉取数据的模式,主动从broker中拉取数据。(如果broker中没有数据,可能会造成拉取为空的死循环。)
1.2 push模式
push模式是指broker主动向消费者推送数据,但是由于每个消费者的消费速率不太一样,导致推送的速率很难适应所有的消费者。
2. 消费者和消费者组
初学者对于消费者和消费者组的概念容易搞混,本章在这里单独拿出来讲解。
消费者:消费者就是我们所说的consumer,consumer可以消费主题分区的数据,且相互之间互不影响。
消费者组存在的意义: 应用程序需要创建一个消费者对象,订阅kafka的主题并开始接收消息,然后验证消息并保存结果。可是生产者产生消息的速度超过了应用程序验证数据的速度,这个时候该怎么办?这个时候,就需要对消费者进行横向伸缩,有点像多个生产者向同一个主题写入消息一样,我们也可以使用多个消费者从同一个主题读取消息,对消息进行分流,而这多个消费者组成的组就是消费者组。
注:Kafka 消费者从属于消费者群组。一个群组里的消费者订阅的是同一个主题,每个消费者接收主题一部分分区的消息。
2.1 消费者组和消费者的关系
第一种情况,如下图,消费者组1中含有一个消费者1,需要消费主题T1中的数据,消费者1将接受主题T1中4个分区的数据。
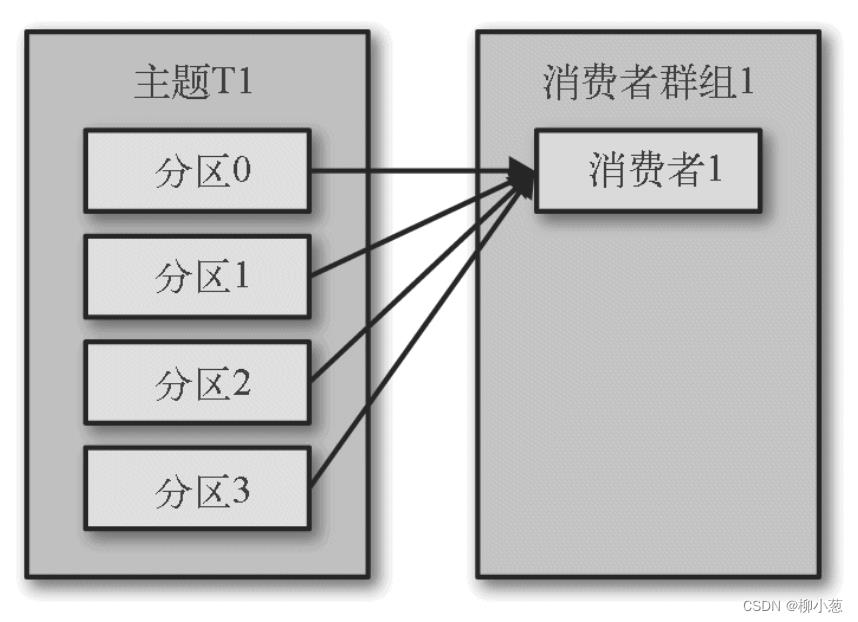
第二种情况,如下图,消费者组1中新增了一个消费者2,需要消费主题T1中的数据,消费者1接受主题T1中0,2分区的数据;消费者2将接受主题T1中1,3分区的数据。

第三种情况,如下图,消费者组1中有4个消费者1,2,3,4,需要消费主题T1中的数据,则每个分区都消费都消费一个主题分区的数据。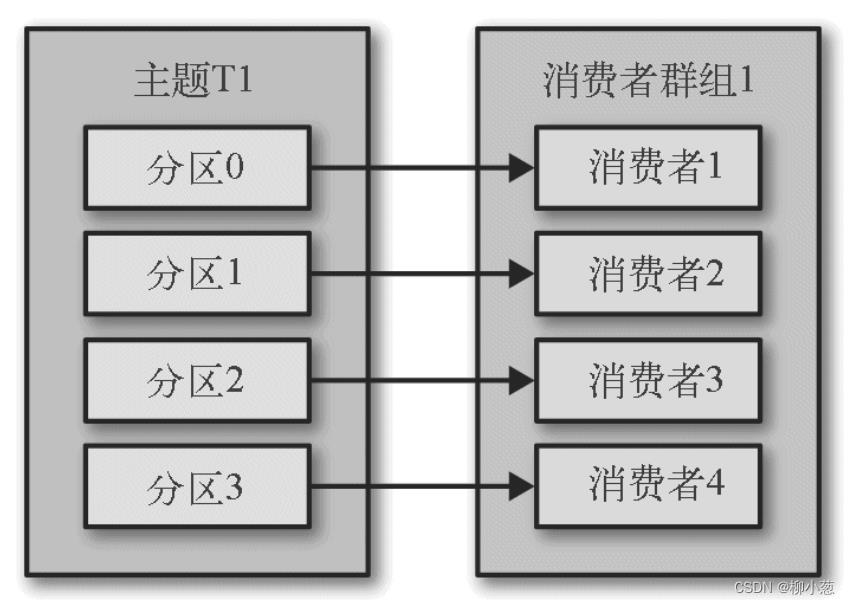
第四种情况,消费者组1中的消费者个数多于主题分区个数,多余的消费者会被闲置。
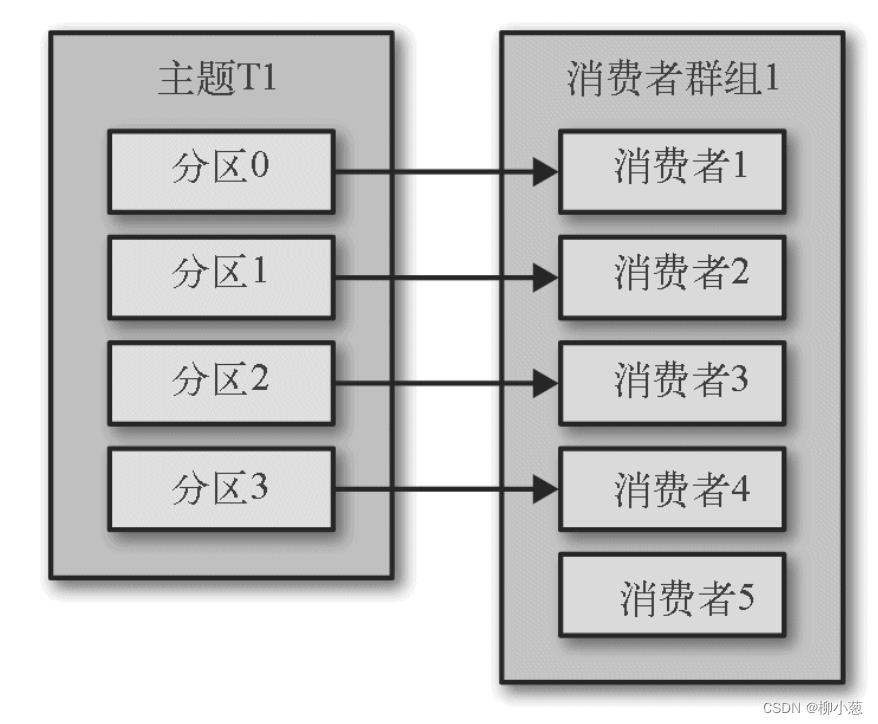
2.2 消费者组和主题的关系
除了通过增加一个消费者组中的消费者个数来横向伸缩单个应用程序外,还经常出现多个应用程序从同一个主题读取数据的情况。这种需求只要保证每个应用程序有自己的消费者群组,就可以让它们获取到主题所有的消息。不同于传统的消息系统,横向伸缩 Kafka 消费者和消费者群组并不会对性能造成负面影响。
如下图,增加了一个消费者组2,虽然他们俩消费同一个主题的数据,但是消费者组2和消费者组1之间没有半毛钱关系,各自独立运行。

总的来说,需要注意以下2点:
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
3. 消费者的工作流程
3.1 消费者消费的大致流程

这里介绍一下,producer向集群的每一个leader发送数据,一批一批的发送,然后follower主动向leader同步数据,然后消费者和消费者组主动拉取数据进行消费,一个消费者或者消费者组可以消费多个分区的数据,消费数据的位置信息由offset进行存储,offset保存在系统主题consumer_offsets中(旧版本offset是维护在zookeeper中)。
3.2 消费者组的初始化流程
这里先介绍一个概念:
- coordinator:辅助实现消费者组的初始化和分区的分配。(每一个brokder中都有一个coordinator)
c o o r d i n a t o r 节 点 选 择 = g r o u p i d 的 h a s h c o d e 值 coordinator节点选择 = groupid的hashcode值 % 50(__consumer_offsets的分区数量) coordinator节点选择=groupid的hashcode值
例如: groupid的hashcode值 = 1,1% 50 = 1,那么__consumer_offsets 主题的1号分区,在哪个broker上,就选择这个节点的coordinator作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset。
消费者的消费流程如下,我们来详细解释一下:

- 我们通过 groupid的hashcode值与consumer_offsets 的主题数取余,可以获取确定的 coordinator来辅助消费者组的初始化和分区的分配。比如我们这里选择了broker1的 coordinator。
- 消费者组中所有的consumer向coordinator发送加入组的请求。
- coordinator会将组中的一个consumer随机选出来作为leader。
- coordinator会将消费的topic数据发送给选出来的leader消费者。
- leader会制定组内每一个消费者的消费计划。
- 制定完计划后将计划发送给coordinator。
- coordinator再把计划分享给其他的consumer。
注:这个过程中每个消费者都会和coordinator保持心跳默认3s(定期联系),上限是45s,如果45s内没有联系到该消费者,那么 coordinator会认为该消费者出现故障,将它移除,并触发再平衡;或者消费者处理数据的时间过长(5分钟以上)那么也会触发再平衡。
3.3 消费者组的详细流程
上面介绍完了消费者初始化的流程,接下来就是消费者详细消费数据的流程:
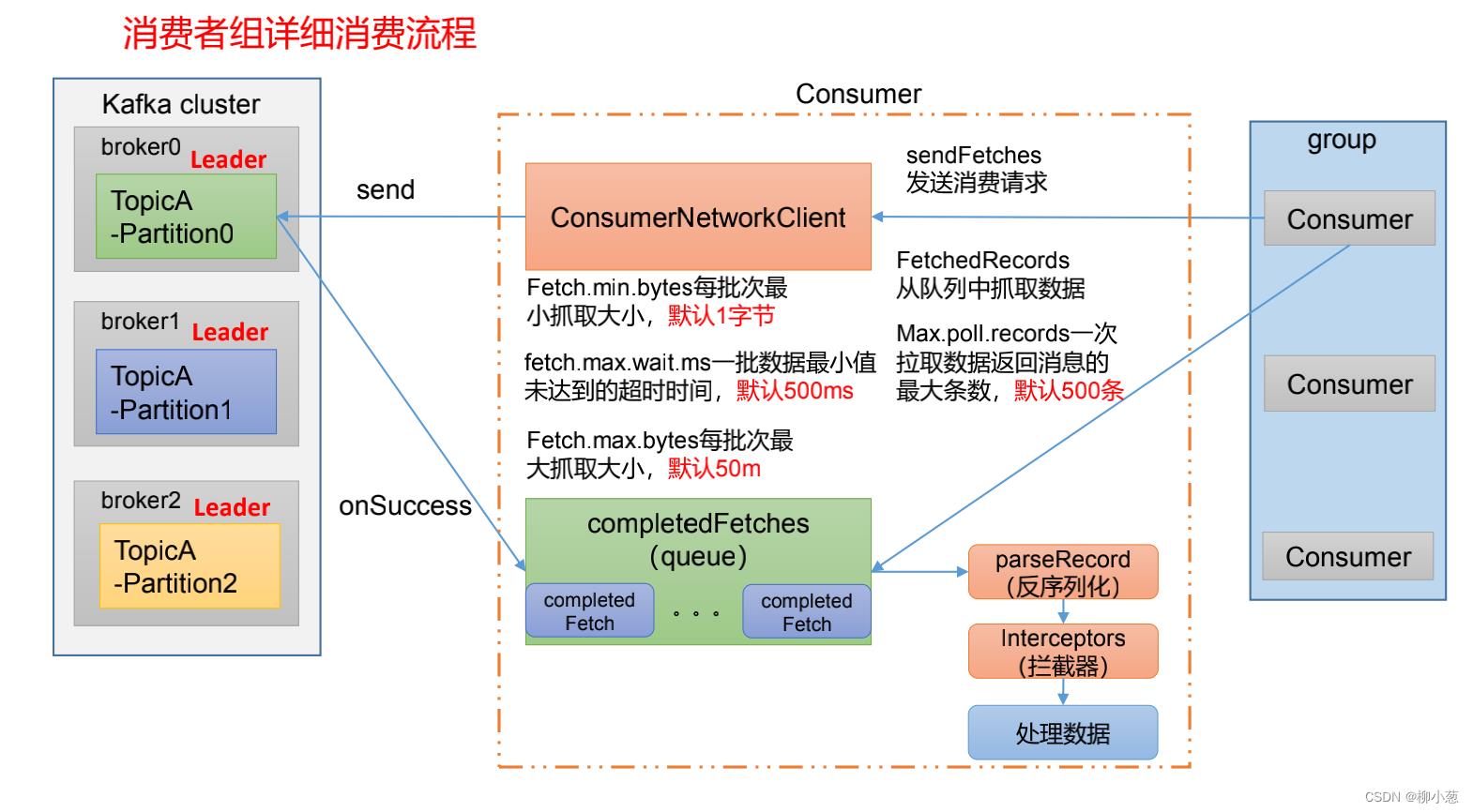
左侧是kafka对应的集群,右侧是我们对应的消费者组,中间是消费者与集群的网络连接。
- 首先调用sendfetches方法发送消费者请求
- 请求中有三个参数:Fetch.min.bytes每批次最小抓取大小,默认1字节;fetch.max.wait.ms一批数据最小值未达到的超时时间,默认500ms;Fetch.max.bytes每批次最大抓取大小,默认50m
- 准备完参数后,向集群发送send请求,会通过回调方法completedFetches将这一批数据拉取过来,以队列的方式存储在消费者网络中,而消费者会以Max.poll.records一次拉取数据返回消息的最大条数,默认500条,过程中会进行反序列化和拦截器处理。
4. 参考资料
-《尚硅谷大数据技术之 Kafka》
-《kafka权威指南》
以上是关于大数据之kafka消费者的主要内容,如果未能解决你的问题,请参考以下文章